
- 1初阳破晓 新岁新生丨Hello,2024
- 2YOLOv9改进 添加三分支注意力机制TripletAttention
- 3KubeSphere——常用应用UI可视化部署实战(2)_kubespray ui
- 4DSPE-PEG2K-定制多肽序列_peg连接多肽
- 5绝对干货,直接收藏 | 3D 可视化入门:渲染管线原理与实践
- 6Android Studio安装_android studio安装包
- 7深度学习之 TensorRT_tensorrt bias
- 8华为鸿蒙OS发布!方舟支持混合编译,终将可替换安卓?_目前鸿蒙2.0 是混合的系统吗
- 9RocketMQ源码解析之消息发送(二)_rocketmq body 字节数组转对象
- 10Leetcode算法Java全解答--73. 矩阵置零_if matrix[i,j]==0是啥意思
SLAM学习笔记(十九)开源3D激光SLAM总结大全——Cartographer3D,LOAM,Lego-LOAM,LIO-SAM,LVI-SAM,Livox-LOAM的原理解析及区别_cartographer需要imu吗
赞
踩
本文为我在浙江省北大信研院-智能计算中心-情感智能机器人实验室-科技委员会所做的一个分享汇报,现在我把它搬运到博客中。
由于参与分享汇报的同事有许多是做其他方向的机器人工程师(包括硬件、控制等各方面并不是专门做SLAM的工程师),加上汇报的内容较多,因此在分享中我尽量使用简介的口语,而不出现复杂的公式。所以本文面向的是3D-slam方向的初学者,不涉及到源码解析。内容在整理中参考了许多链接,将放在最后。
在文章结束后,我会把原PPT放在最后面,需要者自取。
另外打个广告,在slam方向或者强化学习导航方向有实习意愿的,请发送简历至zkyy828@163.com,谢谢。
内容比较多,放一个目录,感兴趣的朋友可以只看对应位置。
注:很荣幸能受到中山大学博士后戚玉华老师和阿木实验室邀请,于11月18日在B站直播间做了一期线上分享,并且加入了LIO-Mapping,LINS,FAST-LIO等内容。有兴趣的同学可以关注 直播回放 | 三维激光SLAM原理及开源方案对比
目录
从2D到3D——Cartographer (ICRA2016)
LOAM:Lidar Odometry and Mapping in Real-time
LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain .
LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping
LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
从2D到3D——Cartographer (ICRA2016)
介绍
- Cartographer是由谷歌于2016年开源的一个支持ROS的室内SLAM库,并在截至目前为止,仍然处于不断的更新维护之中。
- 特点:代码极为工程,多态、继承、层层封装的十分完善。提供了方便的接口,便于接入IMU、(单/多线)雷达、里程计、甚至为二维码辅助等视觉识别方式也预留了接口(Landmark)。
- 根据其代码的结构设计来看,显然是由一个大型的研发团队集中研发,而非少数科研人员的demo型代码。
“明显不是搞科研的玩儿法,就是奔着产品去的。算法需要的计算资源少,而且因为依赖很少,因此几乎可以直接应用在一个产品级的嵌入式系统上。以前学术界出来的开源2D/3D SLAM算法不少,但能几乎直接拿来就用在产品上的,恕我孤陋寡闻还真想不出来。因此,我认为进入相关领域SLAM算法的门槛被显著降低了。” ——知乎 梅卡曼德机器人创始人 邵天兰
2D-3D建图比较
Cartographer支持2D和3D激光雷达的输入,实现机器人定位,并构建栅格地图。

2D-SLAM:基于2D栅格地图,可以直接用于导航。 使用方法: 1.直接使用Ros的Move_base等方式。 2. 导航代码中订阅/map消息, (data部分为一维数组,根据height和width可恢复地图图像。-1为未知,0~100依次增加表示被占据概率增大)

3D-SLAM:基于hybridGrid,译为混合概率地图,我理解为3D栅格地图。 明确:RViz 仅显示3D混合概率网格的2D 投影(以灰度形式)。该地图难以直接使用。
开源代码特点
- Cartographer的理论部分,被发表在《Real-Time Loop Closure in 2D LIDAR SLAM》中(ICRA 2016),其中仅包含2D部分。3D部分目前未见任何发表。
- 由于开源者只提供了使用手册,而没有提供关于此项目的设计思路和开发文档,由于实现的非常工程,给阅读者造成了很大不便——可以定位其核心部分的处理代码,结合论文分析思路。但一涉及到各种数据的处理、通信,则很容易淹没在各种复杂的定义和跳转关系中找不到出口。
- 其主要用到的库:1.线性代数库Eigen3,2.用来读取配置文件中的参数库Lua,3.谷歌开源的非线性最小二乘优化库Ceres,4.Google开源的很流行的跨平台通信库Protobuf
- 分为Cartographer和Cartographer_ros, 后者为前者基于ros的接口,换言之,Ros在其中的作用仅为面向用户,算法本身不以ros传输数据,而是以Protobuf进行各个进程之间的数据编码,再进行通信。
地图设计
- Cartographer的地图(map)以子地图(submap)的形式组成。
- 分为前端和后端。 前端:根据帧间匹配算法(scan-match),实时根据激光(scan)来推测累积的scan相对于submap的位姿。 后端:检测回环(发现在已到达的位置附近),修正各个submap之间的位姿。
- 根据代码可以判断,2D和3D基于的是同一套思路,但是在实现上有一定区别。 接下来结合2D和3D部分,对比介绍实现定位和建图的方法。
在介绍定位和建图思路之前,先介绍一下地图的更新方式:

以方格代表地图块,内部存储数据用来表示被占据的概率。 发出一束激光,打到一个障碍物点,被打到的称为hit点,中间连线上的空区域,称为miss点。 2d和3d都是存储的这样的地图。3d相当于是3维的栅格地图。
宏观上:多次观测到,提升其概率。 问题是,如何用公式表达这个“多次观测”来实现“概率提升”?
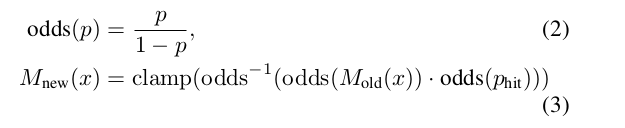
- p表示占据概率,当p=0.5时,概率比值odds=1,表示占据和空闲各占一半。odds^-1表示函数逆运算。
- p_hit=0.55代表该位置被激光打到一次的概率,第一次观测会被直接赋值。
- M(x)表示地图中x位置处的概率值。
举例:
- 初始时刻,栅格未知状态,激光第一次打到了位置x处,M(x)概率更新为0.55。
- 随后,激光第二次重复打到了同一个位置: odd(p_hit)=0.55/(1-0.55)=1.22, odds(M_old(x))=odds(0.55)=1.22 odd(p_hit)和odds(M_old(x))相乘为1.484,再求函数逆运算,恢复出更新后的M_new(x)=0.597。
- 实际代码中,采用了多种工程技巧加速运算。包括:映射到整数范围,预计算,查表等方法,此处不深入展开了。
匹配方法
- 介绍完地图的形式,回到2D和3D的前端:
- Cartographer采用的是scan-map的匹配方法。
- scan-scan: 这个意味着利用两帧激光数据(每帧激光束的数目相同),计算二者之间的变换。典型方法:ICP。
- scan-map: 利用一帧激光数据和地图数据,找到激光数据在地图中的位置。
- map-map: 利用一个子地图数据,在一个更大的地图中找到它合适的位置。
不管是2D还是3D,首先要有一个初始的位姿,在此基础上进行优化:
- 有IMU,则采纳其角速度积分作为初始姿态。不信任IMU任何加速度信息。
- 有里程计,则采纳里程计的线速度积分作为初始平移。
- 二者都没有,根据之前的运动做一个匀速的假设。
可以看出,cartographer的多传感器融合是一个松耦合,主要依赖激光来定位。IMU和里程计数据并没有被构建到真正优化的目标函数中。
一阶段解算
在得到了初始位姿以后,初始位姿要经过第一阶段解算:CSM(Correlation Scan Match 相关扫描匹配)——构建似然场。即对原先的地图map进行一个高斯模糊,让它膨胀一些,然后把激光scan在一个搜索窗口内暴力匹配,计算得分。
注意,这里有两个问题:
1.得分怎么算?
如果scan的点落在障碍物模糊区域内,落的越多,得分越高。
2.地图不是无限大的吗,你怎么保证在搜索窗口里就能找到位姿呢?
因为有初始位姿。误差肯定在一个范围内而不会马上发散到很远,所以可以在一个位姿的窗口内,对位姿进行暴力匹配搜索。(初始位姿估计中,里程计数据不会突然激增;imu的加速度信息会漂移,但是算法对于imu加速度数据选择直接丢弃不看;而根据之前位姿匀速假设也不会飘走)
这时候我们就要考虑,什么是位姿?位置+姿态。
对于2Dslam而言,有三个变量,x,y,yaw角。 对于3Dslam而言,有x,y,z,roll,pitch,yaw六个变量。
- 2dslam中,采用三层循环,(最外层为θ,减小sin和cos的频繁计算),对x,y,θ在给定大小的搜索窗口内进行穷举,计算最高得分的x,y,θ作为一阶段解算的输出位姿。
- 3dslam中,采用六层循环,对x,y,z,roll,pitch,yaw六个变量在搜索窗口内穷举,计算得分最高的作为一阶段解算输出位姿。 很显然,3d-slam的这种方式对于计算资源依赖较大,复杂度达到O(n^6)级别。因此3d-slam的CSM方法,作为一个配置选项,默认是不开启的。当然如果用户机器比较牛逼,也可以选择开启。
二阶段解算
我们可以看出,第一阶段CSM解算中,位姿在其中是一个离散的变量,通过暴力枚举获得输出结果;
但是暴力枚举也是存在分辨率的,例如:如果角度步长设为1度,但如果刚好真正的角度是5.5度,那么CSM只能搜索到5或6度,而无法进一步细化,逐步累积将会造成误差。 因此,引入第二阶段位姿解算:非线性优化。
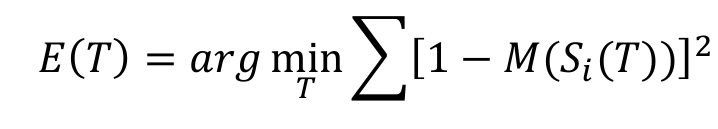
Si(T)表示把激光数据S用位姿T进行转换,M(x)表示得到坐标x的地图占用概率。思路:S代表了激光击中障碍物,将激光点在机器人坐标系下的位置,经过T转换到世界坐标系下以后,应该尽可能的落在已有地图的障碍物上。
第二阶段的位姿求解,显然位姿在其中是一个连续的变量,通过梯度下降的方法求解目标函数。由于地图是离散的,因此需要对地图进行插值处理,使地图也变成一个可以求导的连续变量,这样才能优化前述目标函数。

线性插值:已知数据 (x0, y0) 与 (x1, y1),要计算 [x0, x1] 区间内某一位置 x 在直线上的y值;
双线性插值本质上就是在两个方向上做线性插值。
双三次插值:更加复杂的插值方式,它能创造出比双线性插值更平滑的图像边缘。使用最近16个点插值。
Cartographer用的应该是这一种 并且采用Ceres自带的双三插值器。
阅读比较了代码,我判断2D和3D对于此部分内容基本相同。
- 2D:三个误差项:位姿转换误差+ 旋转惩罚+平移惩罚 ,后二者限制了旋转和平移的修改不能距离初始位姿太大。
- 3D:四个误差项:低分辨率位姿转换误差+ 高分辨率位姿转换误差+旋转惩罚+平移惩罚。低分辨率位姿转换误差权重低于高分辨率。
- 旋转和平移的权重也可以在配置文件中调参。
后端
Cartographer在后端主要寻找回环,并根据建立的约束对所有的sumap进行统一优化。
回环检测目的是:检测当前位置是否曾经来过,即采用当前scan在历史中搜索,确认是否匹配。
为什么要有回环检测呢?原因有二:1. 已有地图时位姿初始化,不知道当前帧初始位姿,也就不清楚在地图中哪个位置,无法做定位。 2.有累积误差,仅靠前端递推,不进行修正的话,地图很容易变形。
因此接下来我们探讨两个问题:1.如何检测回环。2.检测回环后该怎么做。
如何检测回环
检测回环和前端的思路也比较相似,先通过穷举暴力匹配,再通过优化精细修正。
但是,前端的暴力穷举,是在有个初始位姿的基础上在一个小窗口内穷举。
后端重定位,没有初始位姿了,暴力匹配的范围变成了整个地图。 因此必须采用算法加速处理。:多分辨率地图+分枝定界操作。
假设有一帧激光:

蓝色代表障碍物:

在高分辨率的地图上,四个点命中3个;
在低分辨率的地图上,四个点全部命中。
激光在低分辨率的地图上匹配情况: 代表得分的上界 (再往精细展开,匹配得分只能更低,不能更高)
在高分辨率的地图上匹配情况: 代表得分的下界( 再往粗略缩放,匹配得分只能更高,不会更低)
分支定界:
- 先把整个地图中的一个区域展开到底(最高分辨率),得到一个匹配分数(得分下界);
- 然后把其他区域不展开,算匹配分数。(得分上界)
- 如果低分辨率区域的得分上界,还没有已展开到底的高分辨率区域的下界高,这个低分辨率区域就不再展开了,统统丢掉不要。

左图四个命中3个,得分75; 右图四个命中2个,得分50; 那么激光打在子区域A的可能性就要大于B,因此B就无需继续展开成更精细的地图了。
- 2D-slam的思路比较简单 前端:小范围内穷举+非线性优化方法修正位姿。 回环检测:大范围内穷举(利用分支定界加速) +非线性优化修正位姿。
- 3D-slam有所不同。 前端的暴力匹配方法,是直接6层循环暴力枚举的,因此配置文件中默认不开启,而是在初始通过IMU、里程计等预测位姿基础上,直接非线性优化修正位姿。 如果回环检测仍然是:大范围内6个循环穷举+分支定界的话,小范围都嫌慢,大范围更别提。 直接对位姿非线性优化? 1.没有初值,会算到猴年马月。2.会落入局部最优值。
这块没有论文发表,是我个人的理解,可能在细节上不够准确,这段比较复杂,仅供参考。(欢迎纠错,有错误我将立即更正)
- 首先,Cartographer3D用IMU确定重力方向,让要匹配的点云的Z轴方向和重力方向对齐。(Cartographer3D必须使用IMU) 这样之后就无需搜索roll和pitch两个方向的旋转,仅暴力搜索沿z轴旋转的yaw角方向即可。这样暴力匹配的范围,就从x,y,z,roll,pitch,yaw 六个维度降为x,y,z,yaw四个维度。
- 相比2Dslam是把点云投影到地图,计算匹配。3d-slam在yaw角搜索维度上,不是直接对庞大的点云进行旋转匹配的,而是通过直方图匹配,设定阈值,先过滤了大量的不匹配yaw角之后,再暴力搜索x,y,z(仍然用分支定界加速)。

1.首先,在z轴方向对点云切成n个片; 2.对每个切片中的点,求解质心; 3.计算每个点,与质心连线,和x轴所成的角度,并依据角度排序。

之后: 1. A点作为参考点:计算AB和x轴的夹角,映射到直方图。 相当于:把点云分类,分成size个类, 分类标准为当前点B与参考点A连线AB和x轴的夹角。 2.再计算一下质心到AB的夹角OBA,作为直方图中这个点对应的权重。
B点被映射到某一个分类中,分类依据为AB和X的夹角;(AB代表“参考点与当前点”,当参考点B距离A很远时,参考点则会被重新选择) B在此分类中的权重,由角OBA的大小决定(变换至-90~90度,主要是想看垂直程度)。

我们可以知道,一圈360度激光,求质心实际就是激光发射器的位置, OB和AB的夹角越垂直,证明一束激光OB,更接近垂直的打到了AB构成的障碍物平面上,反射强度更高,更可信。越不垂直,说明激光OB以侧面的形式打到平面AB上,探测误差可能更大。
回到原先问题上: 刚刚准备在yaw,x,y,z四个维度对当前点云在地图中暴力搜索一个位置初值; 提取直方图的目的,相当于是对当前点云进行一个降维,提取特征。 根据直方图中提取的特征(根据切片上每个点与参考点的直线AB与x轴的夹角分成n个类,类的值是OBA的大小), 和历史数据进行匹配,筛选掉一批不够阈值的yaw角。
- 2d-slam在yaw角的搜索上,是直接枚举yaw角,投影点云,判断点云和地图匹配程度。
- 3d-slam则是先根据当前时刻的点云,通过直方图的形式计算一个特征,然后枚举依次yaw角,对特征进行旋转,然后和历史特征进行匹配,筛掉一批yaw角,拿剩下的yaw角再进行yaw,x,y,z维度的枚举。
细节问题:
二维激光点云或者三维点云,拥有xy或xyz三个坐标。因此点云可以被旋转。但是一个抽象的特征怎么进行旋转?
答:直方图横坐标代表AB和机器人坐标系x轴的夹角,如果对点云进行旋转,也就代表了对这个夹角进行了旋转。旋转点云,对应其实也就是对整个直方图的横坐标向右平移。其实旋转的本质上仍然是点云。
因此整个流程为:
1.把当前时刻的点云直方图进行旋转,代表得到一系列的候选直方图;
2.候选直方图和地图中各个位置的点云直方图进行匹配,计算余弦距离。(直方图可以用一个向量表示,向量的余弦距离就是向量的夹角。)
3.筛掉未达阈值的候选直方图,其对应的yaw角直接丢掉,不进行x,y,z三个方向上的展开。
4.达到阈值的yaw角,进入深层循环:对点云进行xyz三个方向的平移,和三维栅格地图计算匹配得分,仍然遵循分支定界,计算上界和下界。(仅有高、低两个分辨率)
补充理解(仅供参考):
1.为什么yaw角上的特征不满足,这个候选位姿就可以丢掉,就不需要再展开x,y,z了?
因为特征的匹配方法对距离不敏感。 特征主要依赖角OBA,以及AB和X轴的夹角。 在BO的延长线上任意一点,对应的特征都完全相同。
2.在直方图匹配中,需要对当前时刻点云提取直方图特征,并和历史地图匹配。然而只有点云才能提取直方图,而Cartographer3D使用的是三维栅格地图。历史地图中的点云从哪里来?
- 根据源码我推测,程序在各个submap中的每个位姿节点里存放了特征直方图。
- Cartographer可以三维建图,但是是以rosbag的形式把传感器数据保存下来,再把地图以二进制文件pbstream保存以后,离线调用assets_writer_backpack_3d.launch文件,需要同时提供传感器数据bag和地图pbstream文件,才能离线三维建图。 (关于这点,详见SLAM学习笔记(十八)3D激光SLAM——Cartographer第一视角点云可视化配置与使用方法(最新) )
- 因此,我推测代码内部应该把历史点云丢掉了,因此离线点云建图除了需要已经建好栅格地图文件以外,还需要才需要提供原始传感器数据(包含每一时刻获取的点云)。 如果想要获取真正的三维栅格地图,应该需要定位并且修改源码,找到数据在代码中的存储位置,把submap中的三维栅格地图从protobuf数据流中修改并解析出来。

检测到回环后该怎么做: 优化问题
回顾:在Cartographer前端中,不断维护的是scan和submap之间的位姿。整个的map是由一个个submap组成的。


回顾:重定位中的位姿
两个问题:
1. 前端后端均采用了暴力枚举的方式,这样做是否科学?(虽然各自以不同方式加速,但是感觉暴力搜索并不是一个聪明的做法)
2.导入一个已知地图,机器人出现在该地图的某个区域,初始位置未知,随后很快确定了自己的位置,在这个重定位的计算过程中,机器人的位姿变化,到底是离散的,还是连续的?
离散:从一个位置跳变到另一个位置; 连续:从一个位置,逐渐平滑的过渡到另一个位置。
假设现在有一个如下的曲线图:

我们可以构成三点共识:
1. 已有地图不是无限大的,所以位姿的解空间范围有限;
2.机器人真正的位置处,激光和地图匹配得分最高;
3.实际的曲线可能有着很多的局部最优值。然而,一个局部最优值所在位置,往往和机器人真正的位置天壤地别。

采用随机梯度上升,则大概率落入局部最优值。
因此,必须把整个解空间全都搜索完一遍,才能知道哪个区域上界最高,再从这个区域出发优化,找到真正的最优得分。——采用多分辨率地图,分区域枚举,确定最优解在绿色范围内,再从绿色范围内出发,非线性优化,梯度上升,找到真正的位置。
回答上面的问题:
1.暴力搜索是否科学?从传统求解角度来说,是的。否则会落入局部最优值。但是目前有人也用深度学习的方式去做,主要集中在视觉SLAM中,因为相对于只有距离特征的点云,图像有更多的特征。
2.在重定位过程中位姿变化,是先离散搜索区域,再连续精准确定。
LOAM:Lidar Odometry and Mapping in Real-time
介绍
- LOAM为清华自动化本科毕业的Zhang Ji博士在CMU读博期间,于2014年在RSS期刊发表的关于三维激光传感器的SLAM算法。
- 它和Cartographer完全不是同一个思路。
1.Cartographer主要解决室内问题,LOAM室内外都可以,但是没有回环检测。
2.Cartographer的3D部分,更像是2D的扩展:即用2D的思路去做3D的事情。而LOAM则主要解决3D问题,其核心思路难以解决2D问题。
3.从代码风格来看,我认为它属于——学院派。根据其开源代码来看,和Cartographer令人望而生畏的代码量完全不是一个层次。当然这也解释了,为什么基于LOAM的衍生算法众多,但基于Cartographer的衍生算法却鲜有所闻。
那么,代码少,时间老,就证明它不行吗?作为一个7年前的算法,至今在自动驾驶数据集KITTI上的Odometry模块的激光SLAM排行榜上,仍然霸占榜一。
什么,是KITTI数据集
2011年,Andreas Geiger(KIT,德国卡尔斯鲁厄理工学院)、Philip Lenz(KIT)、Raquel Urtasun(TTIC,美国丰田工业大学芝加哥分校)三位年轻人发现,阻碍视觉感知系统在自动驾驶领域应用的主要原因之一,是缺乏合适的benchmark。而现有的数据集无论是在数据量,还是采集环境上都与实际需求相差甚远。于是他们利用自己的自动驾驶平台,建立起庞大的基于真实场景下的数据集,以此推动计算机视觉和机器人算法在自动驾驶领域的发展。这便是KITTI数据集的诞生背景。

KITTI数据采集平台:1个惯性导航系统,1个64线3D激光雷达, 2个灰度摄像机,2个彩色摄像机,以及4个光学镜头。
- KITTI数据集主要有以下Benchmark:road(用于道路分割),semantics(用于语义分割),object(2D、3D和鸟瞰三种视角,用于目标检测),depth(用于视觉深度评估),stereo(用于双目立体视觉和三维重建),flow(用于光流预测),tracking(用于目标跟踪),odometry(里程计)
- 里程计数据集地址:http://www.cvlibs.net/datasets/kitti/eval_odometry.php 数据集中包含了22个立体视觉序列以无损png的形式保存,
- 另外还提供了velodyne64线激光雷达数据。评估标准:平移误差(百分比),旋转度数(度每米)。

前三名:
1. SOFT2:萨格勒布大学电气工程与计算学院采用的方法,未发表论文,使用的是双目视觉;
2.V-LOAM:基于LOAM的改进版本,同时使用了激光-视觉数据进行融合,也是LOAM作者Zhang Ji于ICRA2015所发,但代码未开源。
3.LOAM:本节所述方法。
框架

Point Cloud Registration:点云不是同一时刻获取的,每一个帧点云,其中的每一个点,都是不同时刻获取的,因此把它进行运动补偿: 获取每个点的时间戳,位姿插值,把点云先投影到同一时刻;提取特征点。
Lidar Odometry: 估计两帧点云之间的位姿变换,获得两个时刻之间的相对位姿,频率较高 10Hz
Lidar Mapping: 建图模块,把连续10帧的点云数据和整个地图匹配,获得世界坐标系下的位姿,频率较低 1Hz。
Transform Intergration:实时利用世界坐标系下的位姿和两个时刻之间的相对位姿,更新各个时刻世界坐标系下的位姿
特征点
回顾:Cartographer使用栅格地图,地图中存储着占据概率,通过把点云投影到栅格地图,计算匹配得分,找到最合适的投影,作为位姿变换。
但是,LOAM使用的是点云地图,那么点云投影后,进行匹配的就还是点云地图。 两堆点云,如何匹配?
传统方法,使用ICP方法,即默认两堆点云中最近的点是匹配点,构建矩阵进行奇异值分解,得到变换矩阵后投影点云,然后再次寻找匹配点,重新计算投影……直至收敛。
然而,对SLAM算法而言,要求同步定位和建图。这样随便根据距离选匹配点,计算太复杂,可能算来算去都不收敛,压根就不能实时,计算量实在是太大了。
LOAM作者决定对点云提取特征,然后根据稀疏的特征来计算位姿变换。 作者决定提取两种特征点:平面点和边缘点。
那么,如何区分这两种点?
作者引入了一种计算方法——曲率。
计算曲率听起来是一个很麻烦的事情,在高等数学中,一条曲线的曲率以如下公式进行计算:
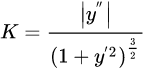
但事实上作者并不是这样算的。他直接利用激光的每条扫瞄线中,一个点前后各五个点,计算平均值到该点的距离。


平面点:在三维空间中处于平滑平面上的点,其和周围点的大小差距不大,曲率较低,平滑度较低。
边缘点:在三维空间中处于尖锐边缘上的点,其和周围点的大小差距较大,曲率较高,平滑度较高。
作者对整个扫描进行分段,分四段,每段各取2个边缘点和4个平面点。在确定了边缘点和平面点后,两帧点云将根据这两种特征点进行运动估计。
边缘点匹配方法:

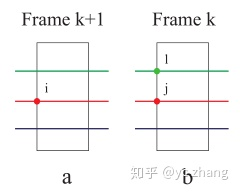
红、绿、蓝代表多线激光雷达的扫描线; 在第k+1帧中,边缘点i处在红色的扫瞄线上;
在第k帧中,红线上的边缘点j和i更近,在相邻绿线上再找到一个最近的边缘点l,那么l和j构成一个边缘。 因此,对边缘特征点来说,优化的目标就是,i到直线lj的距离最近。
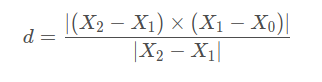
向量叉乘的模长,代表平行四边形的面积; 除以底,代表平行四边形的高; 也就是点到直线的距离。
平面点匹配方法:
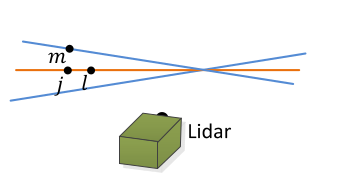
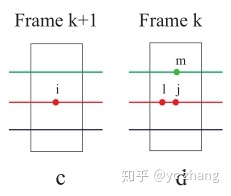
红、绿、蓝代表多线激光雷达的扫描线; 在第k+1帧中,平面点i处在红色的扫瞄线上; 在第k帧中,红线上的平面点j和i更近,在同线上再找到一个附近的平面点l,在相邻绿线上再找到一个最近的平面点m,那么lmj构成一个平面。 因此,对平面特征点来说,优化的目标就是,i到平面mlj的距离最近。
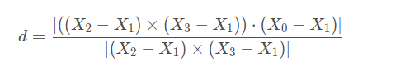
分子:三维物体的体积; 分母:地面构成的平行四边形的面积; 高=体积/面积 也就是点到平面的距离。
运动估计
- 在确定了两个优化目标:边缘点到边缘线的距离、平面点到平面的距离以后,就可以对特征点进行旋转,构建目标函数,通过非线性优化的方式进行梯度下降求解了。
- 作者论文中使用的求解方法是列文伯格-马尔夸特算法(LM),又叫阻尼牛顿法,可以避免求解中遇到的非奇异和病态问题。
有趣却无用的细节:作者发表时的源代码,和目前流传的代码并不相同(源代码可能由于后续维护和其他商业原因下架)。其声称使用了LM算法,但实际上在代码中被人发现用的是比较简单的高斯牛顿法(也许重要内容没有开源,也许是这样论文看起来更复杂),使用的是OpenCV自带的solve函数迭代求解增量,轮子是自己造的。 目前流传的代码为ALOAM,代码简介,易于学习。主要是后人对其工程代码进行了改进,使用了和Cartographer一样的Ceres库,直接用求解器,省去了对雅可比矩阵的手工推导,因此代码简洁了不少。
到目前为止,根据特征点,计算了相邻两个时刻点云之间的位姿变换。然而,我们希望得到的是世界坐标系下的位姿。
是否可以直接从第1帧开始,逐步递推,得到每个时刻点云之间的位姿变换呢?
毫无疑问,这样会把误差越累积越大,就好比只用轮式里程计递推定位一样。
LOAM虽然没有回环检测(不能发现自己到了相同的位置),但这并不代表它仅靠前端递推。 LOAM在建图部分,采用map-map的匹配方法,用连续10帧的激光点云数据,和10立方米之内的地图做一个匹配。
也就是说,在第25帧的位姿,不是从0帧-1帧,1帧-2帧……一直递推到第25帧的。而是10~20帧之间构建的点云地图和全局地图匹配得到的第20帧位姿开始递推,从20~21,21~22……直到第25帧。
地图构建和全局位姿
- 建图部分采用map-map的匹配,仍然是基于边缘点和平面点,投影点云,计算点到直线和点到平面的距离。
- 里程计的匹配,是用两帧点云数据;
- 建图的匹配,是用10帧点云数据,和10立方米范围内的整个地图匹配。
- 特征点增加了10倍!
前端寻找边缘线和平面,使用的是最近临的方法。

后端则不同,使用的是特征点周围的点云簇,通过主成分分析(求解协方差矩阵的特征值和特征向量)确定边缘线和平面。

gif图像来自于robinvista的博客-LOAM论文和程序代码的解读
红色箭头代表特征值方向。
特征值两长一短,则是平面,短的那个作为平面的法向量。
特征值两短一长,则是边缘,长的那个作为边缘的方向向量。
三个向量相交于几何中心,由此确定边缘线和平面。
其他内容与前端相同。在确定了点和线、线和面以后,构建目标函数,非线性优化。
优缺点
LOAM的优点是:
1.提出了新颖的特征提取方式。
2.根据时间戳,对旋转的雷达采集时间不一致进行运动补偿。
3.融合了scan to scan(里程计部分) map to map(建图部分)的思想。
LOAM的缺点也很明显:
1.没有回环检测。(发表时间较早,比谷歌Cartographer要早两年)
2.不能处理大规模的旋转变换。
作为一个14年提出的算法,为什么能一直占据Kitti的榜首呢?之后的算法就都不如它吗?
我的看法:
- 首先,kitti中odometry指的是里程计,里程计不等同于定位,里程计的评价指标为每100m误差多少米——LOAM在0.55%左右。
- 而有回环检测的算法,则发现回环时会修正全局轨迹,取得更高的结果。而Kitti中并非所有序列都有回环。
- 其次,Kitti数据集中累积的公里数大概为39km左右,由汽车采集,也没有大范围的旋转运动。有些算法在其他数据集上比它要好,有的算法比它更快,有的算法结合了更多的信息,例如GPS等,Kitti数据集中并未提供(是作为GT的,而不是传感器数据)。
LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain .
介绍
Lego-LOAM是TiXiao Shan发表在IROS2018的文章,文章叫:可变地形下的轻量级和地面优化的雷达里程计与建图。
其是以LOAM为框架衍生出的新算法,主要在于两点提升:轻量级 和 地面优化。
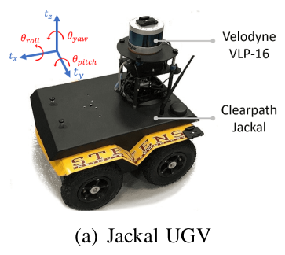
使用的是加拿大clearpath公司的 Jackal小车(吐槽:这一款价格比较昂贵,很多paper里面都是用这种小车,国内价格约为15~19万,根据代理商不同价格不同。要是有人想读博或者读研还不确定的,看到实验室有这个样子的小车,就从了吧,愿意十几万买这样一个小车的,要么有钱,其他设备和学生补助充足,要么已经有很多的技术积累了,才舍得买)
框架

- Segmentation:对点云进行分割,分割为地面和非地面区域;
- Feature Extraction:基于分割后的点,和LOAM类似的算法提取出边缘点和平面点;
- Lidar Odometry:基于提取的特征点,scan-to-scan推算两帧激光之间的相对位姿变换(使用两次LM优化),频率较高(10Hz);
- Lidar Mapping: scan-to-map,构建全局地图,获得世界坐标系下的位姿,频率较低(2Hz);
- Transform Intergration:与LOAM相同,实时利用世界坐标系下的位姿和两个时刻之间的相对位姿,更新各个时刻世界坐标系下的位姿
LOAM存在的问题
没有回环检测(前述已经说过) ;
计算时间复杂度较高,基于三维空间中的位姿进行优化;
户外可能受到各种噪声影响,例如树上摇晃的树叶,地上的杂草。而这些点未必会重复出现在前后两帧激光中。而错误的特征点将会影响位姿精度。
LOAM需要提取平面点和边缘点,由于车体上下颠簸,竖直维度提取的平面点很容易造成误差。
因此Lego-LOAM的contribution:1.着重于解决一些非城市化道路或非平整道路上LOAM存在的问题。2.轻量化,改进算法,使其在TX2上也可以实时运行。
分割
分割部分首先把点云投影到一张距离图像中:
以16线激光雷达为例,其竖直方向为16根,因此竖直方向的分辨率为16;其水平方向角度分辨率为0.2度,因此水平方向分辨率为360/0.2=1800,即构建一张1800*16的距离图像,其中每个像素的值为对应点云到传感器的欧几里得距离。
区分地面点和非地面点:

要求激光雷达安装平行于地面。(找到朝下的第一组雷达中的每个点,找到相邻组中同一水平索引的点。其俯仰角变化在一定范围内,则为同一平面。)
为什么要提取地面点?
就算车体颠簸,路面基本在相邻帧之间变化是不大的。
总体思路就是:先利用提取的地面平面点,调整z,roll,pitch;再利用地面上竖直的边缘点,调整x,y,yaw;不仅更准确了,还实际缩小了优化的规模。(类似于把一个O(n^6)的问题变成了两个O(n^3)的问题。)
特征点提取
在提取特征点之前,对点云进行一个聚类操作:低于30个数据点的类别就当成噪声处理,这样保存下来的点就是一些相对比较静态的物体了。

右图为聚类处理后的点云,红色部分被分割为地面点。
对前述形成的16*1800的距离图像,水平分成若干个子图像(sub-image),对每一个子图像都进行特征提取操作:
依旧是和LOAM中相同的边缘点和平面点评判标准,根据曲率c,区分边缘点和平面点。
之后,要划分两个大集合:
- 每一行中,选取有最大c值的N_Fme(40个)边缘点,要求不得属于地面点, 组成集合F_me;
- 每一行中,选取有最小c值的N_Fmp(80个)平面点,组成集合F_mp;
之后,再从F_me和F_mp中,划分两个小集合:
- n_fe(2个)边缘点;
- n_fp(4个)平面点,要求是地面点。

图片展示了大集合和小集合的区别。
运动估计
雷达里程计部分,要根据两帧点云,确定相对的位姿变换:
- 从t时刻的小集合中,选取边缘点,和t-1时刻的大集合中的边缘点,构建点到线的关系,构建方法和LOAM一致。
- 从t时刻的小集合中,选取平面点,和t-1时刻的大集合中的地面点,构建点到面的关系,构建方法和LOAM一致。
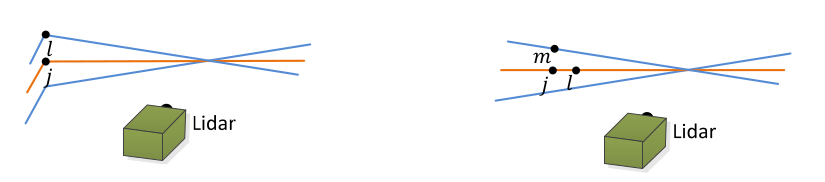
构建了目标函数以后,仍然采用LOAM中的列文伯格-马尔夸特优化算法,但是分了两阶段,第一阶段计算竖直维度的z,roll,pitch。(根据地面的平面点来优化)
第二阶段计算水平维度的x,y,yaw,根据边缘点来优化。 两次LM优化得到相同的精度,实验计算时间减少35%。
放一张图:yaw角就是绕垂直于上方的转轴旋转的角。机器人里,一般让正前方是x,左侧是y,头顶上方是z轴。(和下面图示的不一致,但是yaw角都是绕头顶的轴旋转的角,也叫“航向角”)
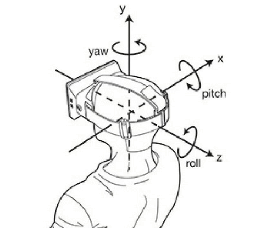
地图构建和全局位姿
与LOAM一致,Lego-LOAM同样也是采用了一快一慢两个部分,快的Lidar Odometry 10Hz来计算相对变换,慢的Lidar Mapping 2Hz来计算世界坐标系下的位姿。相当于10Hz在2Hz的基础上递推。
Lego-LOAM不再存储所有的传感器点云数据,而是只存储特征点集(前述的大集合)。
LOAM采取的是map-to-map的优化,最近的十帧点云与10立方米内的全局地图进行匹配,主成分分析,构建点到线、点到面的误差;
Lego-LOAM采取的是scan-to-map的优化,scan为当前帧点云中的特征点集;map有两种取法:第一种,和LOAM中一致,10立方米;第二种,选一组时间上相近的特征点云,构建图优化问题。当前时刻的特征点云作为观测数据,当前位姿作为优化节点。
使用的优化库:不再是谷歌公司的Ceres,而是因子图优化库gtstam。
回环检测
回顾:Cartographer中的回环检测:激光点云投影到栅格地图,暴力搜索全局地图,分支定界加速,确定初值以后用非线性优化精修;
Lego-LOAM中加入了回环检测,是单独用一个线程运行的。
流程:
第一步,寻找历史位姿:1.与当前位姿的距离上最近。2.与当前位姿间隔时间较长。(这样才是回环)
第二步,把历史位姿作为候选,用ICP算法迭代,修正位姿。
我们可以看出:1.相比Cartographer,Lego-LOAM的回环检测就是一个简单的回环检测,其默认偏移较小。如果偏移较大,就不能修正了。2.不具备重定位功能。因为这种算法的前提是需要知道自己的大致位置,和历史中附近的位置进行匹配,修正位姿。
不足之处
Lego-LOAM有一个显著的缺陷——依赖地面。
如果用无人机,那么就难以确定地面了。 当然论文作者提到,对于无人机,则不提取地面点,直接就像LOAM中那样正常提取边缘点和平面点。但是我认为这样算法的核心优势就丢掉了。
保存的点云地图是稀疏的特征点地图,这也是此类算法的通病,地图有什么用?——可以用来辅助定位,却不能用来辅助路径规划。
引申:点云地图该怎么用
这个问题准确的来说,应该叫“点云地图应该怎么用来路径规划”。 由于在导航任务中,定位、决策往往分为了两个不同的模块。定位部分不用考虑“我该怎么走”,决策部分不用考虑“我走到了哪里”。 所以在三维重建(3D Rescontruction)中,“定位”用来辅助“建图”;在SLAM中,“建图”用来辅助“定位”。因此构建的点云地图,对于定位模块够用了,但对于决策模块则不能使用。
目前,业界基本是属于三种思路: 1.构建稠密点云地图,构建八叉树地图,滤除地面信息,取中间高度; 2.语义SLAM,构建物体级别的地图。(需要深度学习参与) 3.构建稀疏点云地图计算位姿,然后根据传感器数据,实时进行点云地图与栅格地图的更新,之后稀疏点云地图用来定位,栅格地图用来规划。
LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping
介绍
LIO-SAM是TixiaoShan在2020年IROS发表的Lego-LOAM续作。 实际上也是Lego-LOAM的扩展版本,添加了IMU预积分因子和GPS因子。

使用了三种设备进行实验。
框架

- 使用关键帧Keyframe,使用关键帧进行匹配,丢掉了关键帧之间的帧。(阈值设置为1m和10度)
- 四种因子:
- 橙色:IMU预积分因子;
- 绿色:雷达里程计因子,激光“关键帧” 和 “之前的N个关键帧构成的体素地图” 进行匹配
- 黄色:GPS因子: 当估计位姿的方差大于GPS位置方差时加入
- 黑色:回环检测因子,由关键帧和候选关键帧相邻的2m+1个关键帧帧图匹配得到
预积分因子
这部分是VIO领域的内容。我一直没有时间总结,之后更新完,会放一个链接在这里。
简单说一下吧:
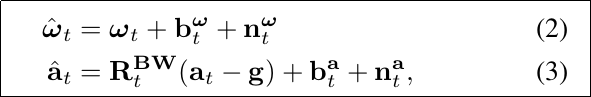
(2)~(3) :IMU可以测量自身的加速度和角速度,但一般认为其测量数据包括了两大噪声:随机游走噪声 b + 高斯白噪声n。B表示body坐标系,即imu坐标系;W表示世界坐标系,R^BW表示了从世界坐标系转换至IMU坐标系;
(4)~(6) 分别表示t + ∆t 时间内,IMU的速度、位移和旋转; 注意,并非直接用原始数据积分,而是减去了随机游走b和高斯白噪声n。 bias未知,该变量也参与优化;
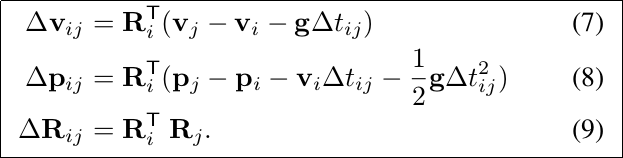
(7)~(8)为i到j时刻的预积分,即把它作为两时刻位姿的一个约束,参与整体的图优化过程。
雷达里程计因子
雷达里程计部分主要得到两帧之间的位姿变换; 方法基本与LOAM或Lego-LOAM的一致。
区别:仅用关键帧和之前n+1个关键帧中的特征集合构成地图,进行匹配,构建点到线、点到面的约束; (原先是使用帧到帧的匹配)
关于这点,该方法应该没有使用Lego-LOAM的提取地面特征的方式,因为在实验部分,采用手持建图、轮船水面建图,可能不适合Lego-LOAM该方式。
GPS因子
收到一个GPS测量,即将其转换到笛卡尔坐标系下,构建一个新的约束;
时间戳不同步问题: 插值解决;
当估计的位置的协方差大于GPS位置协方差时,才插入一个约束因子。

我们可以看到,红色框住的部分,GPS并不是一直插入进去的。
回环检测因子
该方法使用的回环检测方法,应该和Lego-LOAM中的一致; 搜索当前位置15m内的最近历史位置,使用该历史位置的前后分别12个关键帧的特征,和当前匹配,构建约束。

总结
- 该方法使用多传感器融合的方法,利用因子图优化,计算位姿;
- 可以把节点(位姿)理解成一个待求解的变量;各种传感器数据构建的约束当成一个方程组; 通过不断加入各种因子,相当于给方程组中加入更多的方程,联合来求解最小二乘问题。
- 可以看出,回环检测部分基本和Lego-LOAM的特点一致,即不具备重定位能力(该方法前提是需要知道自己的大致位置,和历史中附近的位置进行匹配
LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
介绍
- LVI-SAM为Lego-LOAM和LIO-SAM作者Tixiao Shan的最新工作,发表在ICRA 2021上。 代码也是4月下旬才刚刚开源。
- 提出了一个基于图优化的多传感器融合框架,具有多个子系统: 视觉惯性子系统(VIS) 和 雷达惯性子系统 (LIS); 单目+雷达+imu融合
- 鲁棒性:任一子系统失效,不会导致整个系统挂掉。
现有方法的不足
- 基于激光的方法,在结构比较简单的环境里,容易失效——因为特征只有一个简单的“距离”信息;
- 基于视觉的方法,容易受到光照改变、快速运动导致的图像模糊等问题; 所以,一般会加入IMU传感器——但IMU具有bias,其估计的并不是很准。
视觉-惯性里程计的著名工作——Vins-mono(香港科技大学沈劭劼团队于2018年发表在IEEE Transactions on Robotics上的工作,可以利用单目的视觉和IMU实现融合)可以达到非常好的效果,但是其需要一个初始化过程来估计:相机到IMU的外参,IMU的bias,重力向量的方向和尺度,相机到世界坐标系下的外参等……(非线性系统需要基于初值来不断优化)
简单的说: 单目相机无法观测实际尺度,因此就无法和具有实际尺度的IMU数据进行融合,必须经过一个初始化过程让二者联系在一起。Vins-mono在初始静止或匀速运动时,IMU没有加速度,初始化会失败,进而导致后续其他问题——这也是单目视觉惯性里程计的通病。 前述的激光SLAM大多在回环检测上存在问题(除Cartographer的暴力搜索以外),也就是说:给定一个地图,在没有历史轨迹的基础上,回环检测并不能确定自己在哪里。
框架概述

LVI-SAM使用了两个子系统,视觉惯性系统(VIS)和雷达惯性系统(LIS):
1.视觉惯性系统用雷达惯性系统来初始化;——用LIS计算的位姿,作为VIS的初始优化值;
2.VIS中需要根据图像计算特征的深度,可以利用雷达的测量数据来辅助优化;
3. LIS计算两个点云位姿变换的优化初值,同样也可以用VIS的视觉估计来计算;
4. 回环检测可以用视觉信息确定初值,再用雷达数据优化。
视觉-惯性框架

视觉-惯性框架(VIS)基本上采用Vins-mono的思路,但是区别有三:
1.初始化位姿和IMU的初始bias直接由雷达-惯性框架来估计(前述 vins-mono缺陷)
2.特征像素的深度,从雷达数据中获取;(vins-mono是通过三角测量计算,不够准确)
3.检测失效:
- 当图像的特征点数目太少——无法确定匹配关系;
- 当vins-mono失效时——发现估计出的IMU偏置bias很大;
- 一旦检测到失效,立即用雷达-惯性框架的结果重新对视觉-惯性框架进行初始化。
问题:特征像素的深度,如何从雷达中获取?

a) 把视觉特征点和雷达点云,投影到归一化相机球体坐标系下,找到像素点最近的三个雷达点云,从而确立关联深度。 b) 周围的三个点如果自身差距太大(超过2m),则丢弃不要。
雷达-惯性框架
我们对LIS和LIO-SAM的框架做个对比:



回环检测
LVI所采用的回环检测,与大多数视觉SLAM所采取的回环检测方法相同,为词袋模型。 这一点我以前做过总结:SLAM14讲学习笔记(八)回环检测
最初被用在信息检索领域:一句话是由单词组成的;通过各个单词出现的次数,可以得到一句话的向量。比较各个文档的向量,就可以比较文档的相似程度。
视觉SLAM用图像作为“文档”,用图像的特征点的描述子作为“单词”,计算各个图像的向量,比较相似程度。 可以看出这种方式是一种简单朴素的方式,因此许多工作集中于用深度学习来比较相似程度。
但与Lego-LOAM,LIO-LOAM等工作相比,显然这种方式可以在地图数据库中找到回环,而无需当前运动的历史轨迹。
固态激光雷达livox-loam
介绍
其实关于固态雷达的内容,本来我们目前的机器人——四足机器人萝卜是要用多线机械雷达的,固态雷达是另外一个组的仿人机器人叫爱瑟尔的在用。不过既然开始调研工作了,就一起看了。
Livox-loam为香港大学于2019年开源的工作,其主要由两篇论文组成:
- Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV 这篇主要讲算法前端和后端,针对于LOAM的改进方法;
- A fast, complete, point cloud based loop closure for LiDAR odometry and mapping 这篇主要讲算法使用的回环检测方法 ;
- 两篇文章共享同一个github开源链接。
固态雷达和机械雷达的区别
机械雷达:通过机械方式改变扫描方向;类似于一个激光笔,放在电机上旋转;十六线雷达,就是依次改变扫描的角度和高度,进行旋转。
固态雷达:通过阵列干涉改变扫描方向。类似于一个激光笔自己不动,改变激光射出的方向和角度。
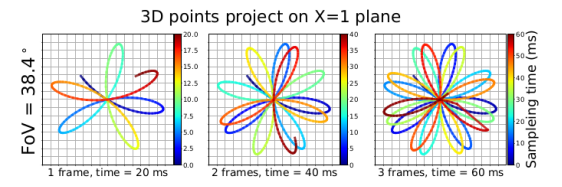
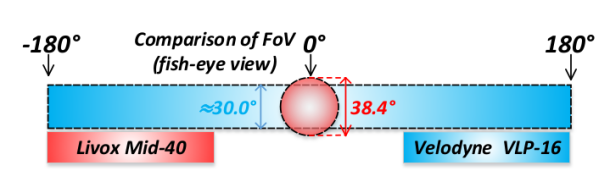
左图为固态雷达的扫描轨迹线,可以看出,它是很杂乱的。
右图为固态雷达和多线雷达的视野对比。其实多线雷达也不是一条线一条线挨个扫的,看看velodyne的说明书就知道,它是上下跳着扫的,可能因为一些工艺的原因吧。这点我不是专业人士,我就不乱讲了。
筛掉不好的点
livox-loam依然采用和LOAM一样的方式,选取边缘点和平面点。但是它和LOAM最大区别就是,在选取候选的特征点时,变得更加“小心”了。
四大原则:
1.接近视角边缘的点不要。说白了就是射线和x轴夹角大于17度的就不选。

2.反射强度太大或者太小的点不要。
![]()
![]()
R是目标反射率,D是点云到光心的距离。
目标反射率可以由雷达直接获得。
- 反射率高,距离近,则认为反射强度大:会对雷达硬件的信号接收电路产生冲击,从而影响这个点的精度
- 反射率低,距离远,则认为反射强度小:信噪比低,不可信。
3.和平面夹角很小的点不要
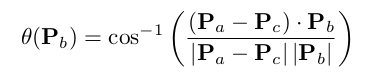
4.部分被遮挡的点不要
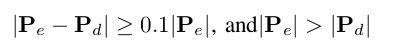

选取特征点(边缘点,平面点)的方式和LOAM中一致(根据曲率),
还另外多一种选取方式: 利用反射强度信息: 如果相邻点的反射强度区别很大,也认为是一个边缘点。
位姿的迭代估计
计算位姿的目标函数,与LOAM中的一致,为点到线的距离(从边缘点中选点),点到面的距离(从平面点中选点),也采用协方差矩阵特征值的方式,提取边缘线和平面。
值的注意的是,固态激光雷达虽然是不动的,但是绝对不意味着所有点都像相机一样是同时获取的。
因此,每个点都是基于不同时间戳的。如果本身雷达自身处于运动状态,就会导致运动畸变。 算法采取了两种方式:线性插值和分段处理。
- 分段处理即为把一帧数据,分成三段,分开并行匹配处理。(其实本质上也没有解决时间戳的问题)
- 线性插值为把两个时刻的位姿做一个插值,然后把每个点都插值找到位姿,投影到正确的位置。(类似LOAM的方式)

实验结果发现线性插值效果不太好,会有重影,因为遵循的是一帧激光之间是匀速运动的这个假设。实际上在运动畸变的去除上,一般采用IMU或者里程计来确定激光雷达在旋转一周时的位姿变换(当然固态雷达这里对应的是一帧数据,因为固态雷达是不转的)。
外点和动态点的过滤
算法采用一种比较朴素的方式过滤外点和动态点:
- 先用特征直接匹配一下,计算出相对位姿,然后投影点云;
- 然后比较投影后的点云与地图,去除掉太大的点,当成外点(outliers)或动态点(dynamic objects)。
- 然后用剩下的点做继续匹配,进行优化迭代。
回环检测
Livox-loam的回环检测部分被单独列为一篇文章。
其和上面提到的LVI-LOAM的回环检测方式类似,都是使用视觉SLAM中的“词袋模型”来进行匹配。 对所有的关键帧提取特征,然后在回环检测阶段,把当前的特征和关键帧的特征进行比对,确立对应关系。
问题是:LVI-LOAM中是利用图像来提取特征的,(比如提取图像的各种类型的特征点),但是在livox-LOAM中并没有用到相机,那么对点云是如何提取抽象的“特征”用以依次匹配的呢?
其提取的特征,是基于2D直方图。
回忆:Cartographer3D中也是提取了特征直方图,不过和此处的不一致。
- 此处先把空间按照xyz的坐标,分成多个cell,然后把点云的点放到cell当中。然后对cell,计算其中各个点的位置均值和方差。

- 采用增量平均的方式,每到达一个点就用如下公式更新,避免重复计算。(强化学习中也是这样处理的)

- 在每个Cell得到了方差矩阵后,也是采用LOAM中类似的方式,对各个cell中协方差矩阵特征值分解,判断是平面,还是边缘。

接下来就是核心内容:计算一帧对应的直方图,把这个直方图当作关键帧的特征。 之后将基于所有帧的直方图,比较相似性,建立匹配关系,确定回环。
直方图如何确定呢?
- 首先,根据特征向量(线的特征向量就是方向,面的特征向量就是法向量),利用前述得到的R进行旋转;
- 然后记录旋转后的特征向量的pitch和yaw两个角,以3度为分辨率,统计数目,以直方图的形式保存。

- 计算各个直方图的相似性
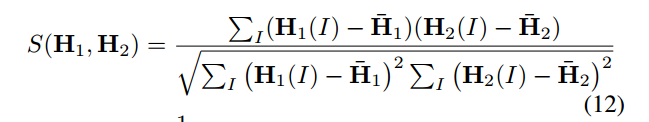
这个公式叫归一化互相关(NCC)。基本就是视觉slam中的内容。利用此公式,建立阈值,确定回环。
确定回环之后,之后的优化内容则依旧是利用图优化方法,建立约束,优化各个位姿节点。 注意:用到的库为Ceres(和Cartographer、LOAM相同。LOAM的续作均为因子图优化库gtsam)
参考链接
loam:
https://blog.csdn.net/robinvista/article/details/104379087
LOAM笔记及A-LOAM源码阅读 - WellP.C - 博客园
lego-loam:
激光雷达SLAM算法大全 - 知乎
LeGO-LOAM:轻量级地面优化的建图_try_again_later的博客-CSDN博客
LeGO-LOAM论文翻译(内容精简)_wykxwyc的博客-CSDN博客
lego-loam 同步构建2d栅格导航地图 - it610.com
lego-loam代码分析(1)-地面提取和点云类聚_jiajiading的博客-CSDN博客
LeGO-LOAM回环检测_Zlp19970106的博客-CSDN博客
cartographer 3D:
cartographer 3D scan matching 理解 - 达达MFZ - 博客园
Cartographer源码阅读3D-回环计算-分支定界_yeluohanchan的博客-CSDN博客
Cartographer-[2]-系统参数配置说明 | EpsilonJohn's Blog
lio-sam:
lvi-sam:
视觉雷达imu的多传感器融合定位和建图系统LVI-SAM论文阅读 - 知乎
论文笔记_S2D.66_ICRA_2021_LVI-SAM: 紧耦合的激光视觉惯导SLAM系统_惊鸿一博-CSDN博客
livox-loam:
激光SLAM | 基于固态雷达的里程计:Loam Livox - 知乎
【泡泡图灵智库】Loam livox:一种用于小视场角激光雷达的快速、鲁棒、高精度的激光雷达里程计和建图包_扫描
PPT




























































































其他SLAM相关内容详见:微鉴道长SLAM学习笔记(目录)
本人目前在研究院从事基于强化学习的导航决策和基于SLAM的导航定位,有相关问题,欢迎留言探讨。
毕竟本人水平有限,如果内容有误,感谢指正!

