
- 1String中null变为"null"字符串的问题_将string中的null转为“”
- 2【高效能人士的七个习惯】 第二部分 个人的成功:从依赖到独立(史蒂芬·柯维)...
- 3【Java基础】对比Vector、ArrayList、LinkedList有何区别?_java vector与数组的区别
- 4ubuntu 如何使用阿里云盘_ubunut 如何挂载阿里云盘
- 5caused by: java.lang.ClassNotFoundException: org.springframework.transaction.ReactiveTransactionMana
- 6【编程技术】低代码开发的入门到精通_低代码开发学习
- 7fastboot 详解_fastboot 位于 系统包 那个位置
- 8Android 获取签名公钥 和 公钥私钥加解密_android 获取app 公钥 数字格式
- 9效率神器,边看网页边问ChatGPT!神级ChatGPT插件(浏览器扩展)推荐!_sider 原理
- 10反编译微信小程序,可导出uniapp或taro项目_微信小程序反编译uniapp
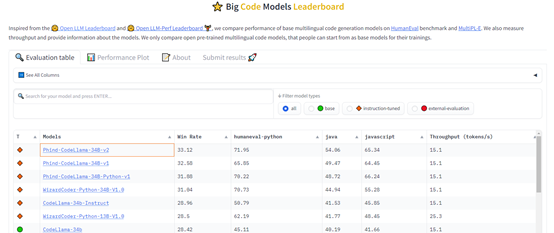
支持中文,性能超GPT-4!笑脸排名第一的纯代码模型
赞
踩
生成式AI代码开发平台Phind在官网发布了最新V7版本,性能方面超越GPT-4,运行效率提升了5倍,并且支持中文和16K超长上下文。
据悉,Phind V7是基于Phind的开源代码模型CodeLlama-34B V2,以及700亿个高质量代码和推理问题进行了额外精调。
CodeLlama-34B V2在huggingface(笑脸)的代码大模型排行榜中位居第一名,这也是首个击败GPT-4的开源代码项目。
无需注册,免费在线测试地址:https://www.phind.com/
开源地址:https://huggingface.co/Phind/Phind-CodeLlama-34B-v2
Phind V7专业代码开发平台
Phind V7在HumanEval上的测试分数达到74.7%,成功超越了GPT-4在今年3月份的官方技术报告中公布的67%的成绩。
但Phind发现,HumanEval的评分并不能准确地反映出大模型的实用性。
Phind将多个版本部署到自家服务平台后,收集到了大量反馈信息,发现其模型在大多数真实问题上的表现与GPT-4相当甚至更好。
许多在其Discord社区的用户已经开始只使用Phind的产品,尽管他们也订阅了GPT-4。
除了性能超强之外,运行速度是Phind V7的一大技术亮点,通过在NVIDIA的新型TensorRT-LLM库上运行模型,Phind成功实现了比GPT-4快5倍的运行速度,达到每秒处理100 tokens。
另一个优点是Phind支持多达16k tokens的上下文。目前,Phind允许用户输入最多12k tokens,剩余的4k tokens用于网络结果。
Phind V7精通Python、C/C++、TypeScript、Java等主流编程语言,使用界面也简单直观,直接输入你的编程问题就能返回代码。
例如,我们直接输入中文提示:用python写一个吃豆游戏的代码。
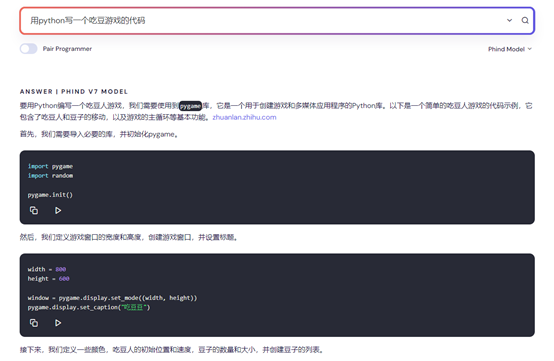
Phind返回的注释也都是中文,如果点击三角按钮可以直接在replit中运行非常方便。
支持多轮深度对话,继续发问,游戏中的吃豆人和豆子是如何运动的?
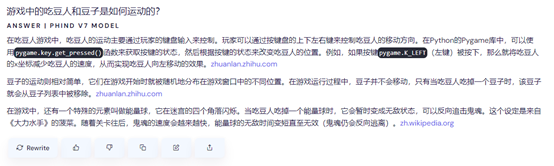
Phind在对文本回答时,会标注引用的原出处,用户点击网站可以直接跳转。
CodeLlama-34B V2
CodeLlama-34B V2代码模型使用了80,000个高质量编程问题和解决方案的专有数据集进行微调。这个数据集的技术特点在于,采用的是指令-答案对的格式,而非常见的代码补全示例,使得在结构上与HumanEval有明显的区别。
此外,Phind还将 OpenAI 的去污方法应用在数据集中,以确保结果准确有效并且没有发现受污染的示例。
方法是:1)对于每个评估示例,随机抽取了三个 50 个字符的子字符串,如果少于 50 个字符,则使用整个示例。
2)如果任何采样的子字符串是已处理的训练示例的子字符串,则识别为匹配。
在训练过程中,Phind使用了DeepSpeed ZeRO 3和Flash Attention 2技术,并使用了32个A100-80GB的GPU,仅在三小时内就完成了序列长度为4096的模型训练。
经常编程的小伙伴们可以试试该模型,生成、审核、注释、改错样样精通,是降本增效的利器。

本文素材来源Phind官网,如有侵权请联系删除

