
- 1分布式操作系统的价值和意义
- 2面试刷题11-9_查询从6.1开始到现在每天的评论数量,评论大于1000的数量
- 3HCIP-AI-Ascend Developer V1.0 华为认证高级工程师课程章节测试题+结课测试题(HCIP-AI-Ascend Developer V1.0模拟考试题)汇总_hcip-harmonyos应用开发高级工程师v1.0模拟考试
- 4torch.optim.lr_scheduler--学习率调整总结_torch.optim.lr_scheduler.linearlr
- 5nltk_data无法下载或无法使用问题的解决方案之一_[nltk_data] error loading tokenizers: package 'tok
- 6QML 布局:网格布局(GridLayout)_qml grid layout
- 7前端——11.列表标签_前端ul
- 8CSS 媒体查询 @media【详解】_css媒体查询 @media
- 9BERT为什么是NLP的革新者_为什么nlp采用bert而不用图神经网络
- 10小波包变换方法概述
图-文多模态,大模型,预训练_多模态图文
赞
踩
参考老师的无敌课程
多模态任务是指需要同时处理两种或多种不同类型的数据(如图像、文本、音频等)的任务。例如,图像描述(image captioning)就是一种典型的多模态任务,它需要根据给定的图像生成相应的文本描述。多模态任务在人工智能领域具有重要的意义和应用价值,因为它们可以模拟人类在日常生活中处理多种信息源的能力。
近年来,随着深度学习技术的发展,多模态任务取得了显著的进步。特别是VIT(Vision Transformer)和CLIP(Contrastive Language–Image Pre-training)这两种基于Transformer模型的方法,极大地推动了多模态研究的发展。相比于传统的基于CNN(Convolutional Neural Network)的方法,Transformer能够对不同模态的数据进行统一建模,包括参数共享和特征融合。这极大地降低了多模态任务的复杂性和计算成本。
图-文任务是指需要同时处理图像和文本数据的任务,如图像描述、图像检索(image retrieval)、视觉问答(visual question answering)等。就图-文任务而言,ViLT首先使用Transformer移除了任务中目标检测模块,参照VIT将多模态任务更加优雅地解决。随后学术界就如何解决多模态任务,进行了不断地探究。网络结构也进行一系列变化,其中,单塔模型使用一个Transformer对图像,文本进行特征抽取;双塔模型则使用两个对应网络进行特征抽取;最近也逐步展现出统一的模型结构,即网络参数共享,可根据任务不同选择合适的模块进行解决。

参考: ViLT,多模态串讲上, 多模态串讲下,albef与blip的高集成库(LAVIS)
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision (ICML 2021)
突出贡献: 在Image-Text对齐过程中,移除了目标检测。
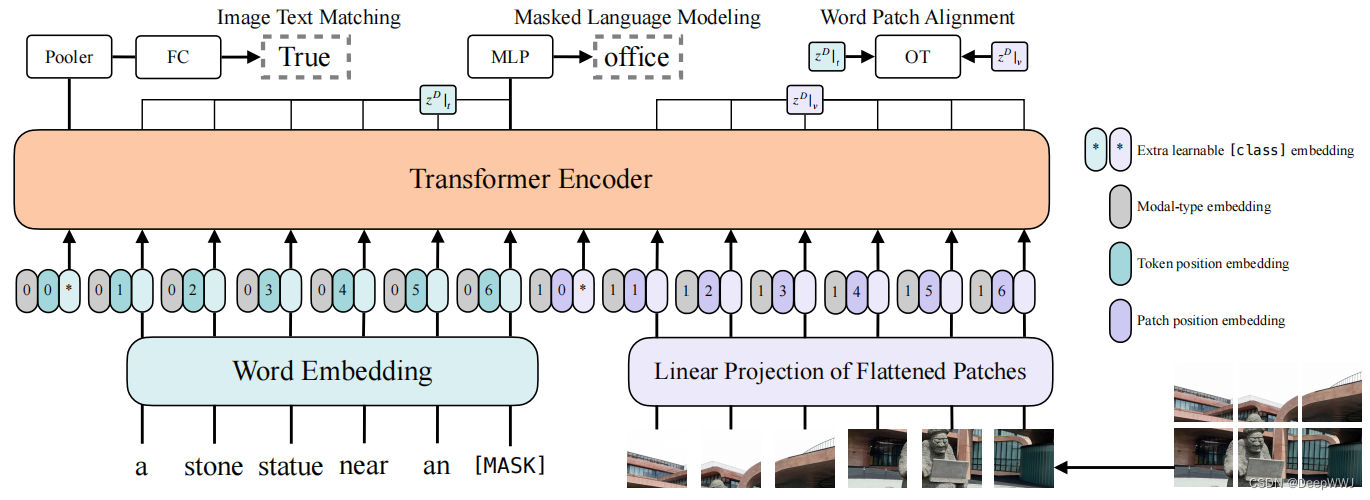
算法流程:
- 首先使用Word Embedding对文本编码得到 E t E_t Et,使用Linear Projection对图像块进行编码得到 E i E_{i} Ei。并且在两个头部分别加入分类token。
- 随后向文本编码与图像编码中,加入位置编码 E p E_p Ep与模块编码 E m E_m Em,分别提供位置信息与属于哪个模态信息。
- 将
E
t
E_t
Et与
E
i
E_i
Ei拼接,得到最终输入序列
E
i
n
E_{in}
Ein。
(4) E i n E_{in} Ein输入到Transformer Encoder中进行信息计算交互。
损失函数:
- Image Text Matching: 训练中,会人为创造一些不匹配的image和text,然后选取序列头部的token来判断图文是否匹配。
- Masked Language Model: BERT的目标函数,随机mask一些单词,然后使用多模态信息进行预测。
- Word Patch Aligment:保证word的特征分布与image的特征分布一致。
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (NeurIPS 2021)
突出贡献: (1)将Language model劈成两半,并且在多模态融合前首先进行image-text对齐。(2)使用Momentum Model作为‘老师网络’来缓解噪声数据的影响 (one-hot可能存在偏差,Momentum Model可以引入soft-label)。
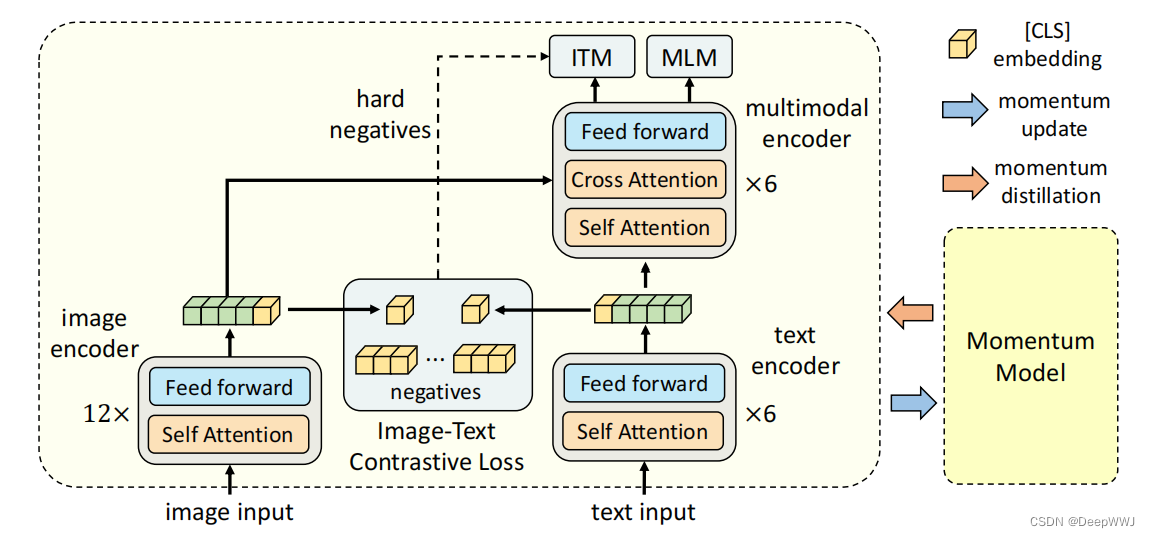
算法流程:
- 模型包括一个image encoder与一个BERT,并且将BERT对半劈开,分别进行文本特征提取(text encoder)与多模态融合(multimodal encoder)。
- image输入到image encoder(12层)提取特征,文本输入text encoder(6层)提取特征。
- 得到的文本与图像特征输入到multimodal encoder进行多模态融合。
损失函数:
- Image-Text Contrastive loss: 使用对比损失来约束image与text的特征,positive靠近,negative远离。
- Image-Text Matching(ITM): 选取对比计算中的hard negative,要求网络计算其是否匹配,赋予网络具有挑战的任务。
- Masked Language Modeling(MLM): BERT的预训练函数。
- Momentum Model(参考MOCO): 拷贝自原有模型,其参数移动平均更新的很慢: P m o m e n t u m = m ∗ P m o m e n t u m + ( 1 − m ) ∗ P o r i g i n a l P_{momentum}=m * P_{momentum} + (1-m) * P_{original} Pmomentum=m∗Pmomentum+(1−m)∗Poriginal,模型会使用KL损失来约束原有网络与Momentum Model的输出。
VLMo - General-purpose Multimodal Pre-training (NeurIPS 2022)
突出贡献: 灵活!既不是单塔模型(擅长图文推理),也不是双塔模型(擅长图文检索),而是使用共享参数提取图像文本特征,然后训练几个专家,这样选择不同的专家就能解决不同的任务,专家就是网络中的不同Feed Forward。
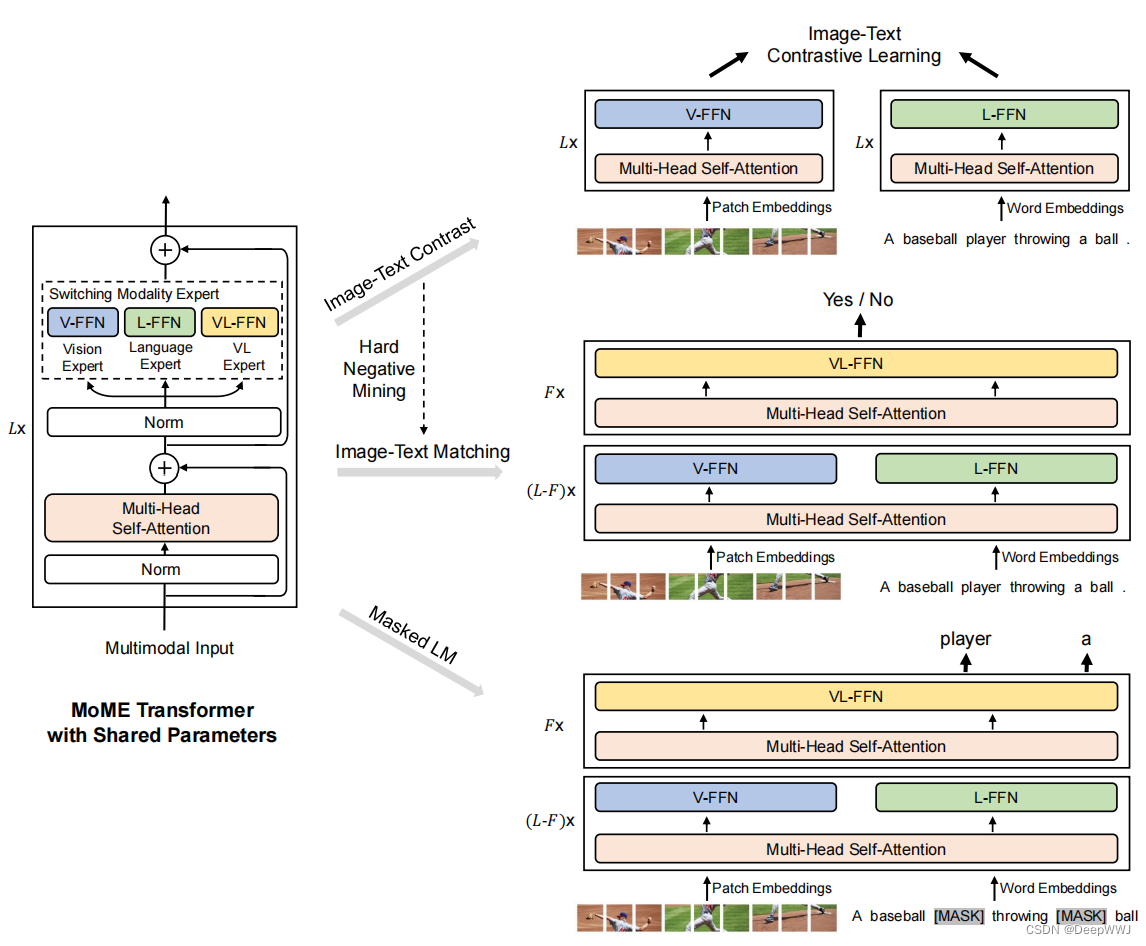
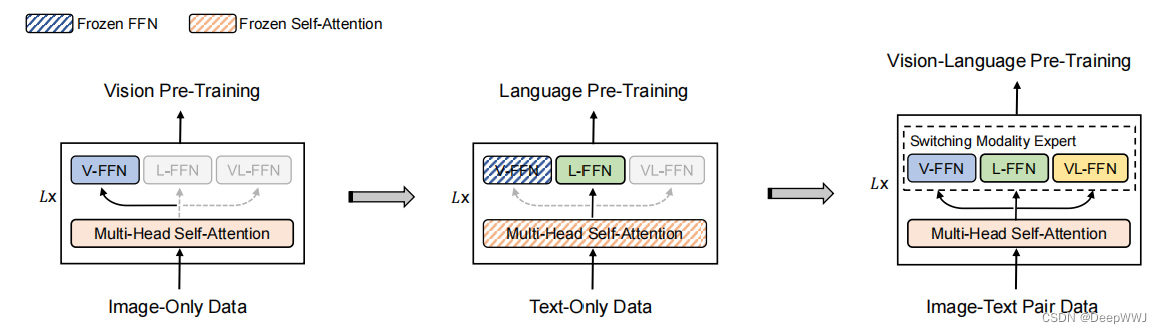
算法流程:
- 首先预训练vision。具体来说mask调图像块,然后使用BEiT进行重建,训练V-FFN作为视觉专家。
- 其次训练language。冻结V-FFN与共享self-attention参数,使用文本训练语言专家L-FFN。(视觉参数直接在文本上使用)
- 训练vision-language专家VF-FFN。将网络都打开,输入图像-文本对来训练所有专家。
损失函数:
- Image-Text Contrast: 打开V-FFN与L-FFN,模型转化为CLIP,擅长处理图文检索的任务
- Image-Text Matching:打开V-FFN与L-FFN,VL-FFN,模型转化为ALBEF,变为双塔结构,擅长处理图文推理任务。
- Masked LM: 打开V-FFN与L-FFN,VL-FFN是,使用BERT的的预训练函数(完形填空)训练模型。
突出贡献: (ALBEF的后续) 灵活!出发点与VLMo一致,都是着重解决image-text任务中模型复杂的问题。另外对存在噪声的数据进行了caption filter筛选,得到了更好的数据对。
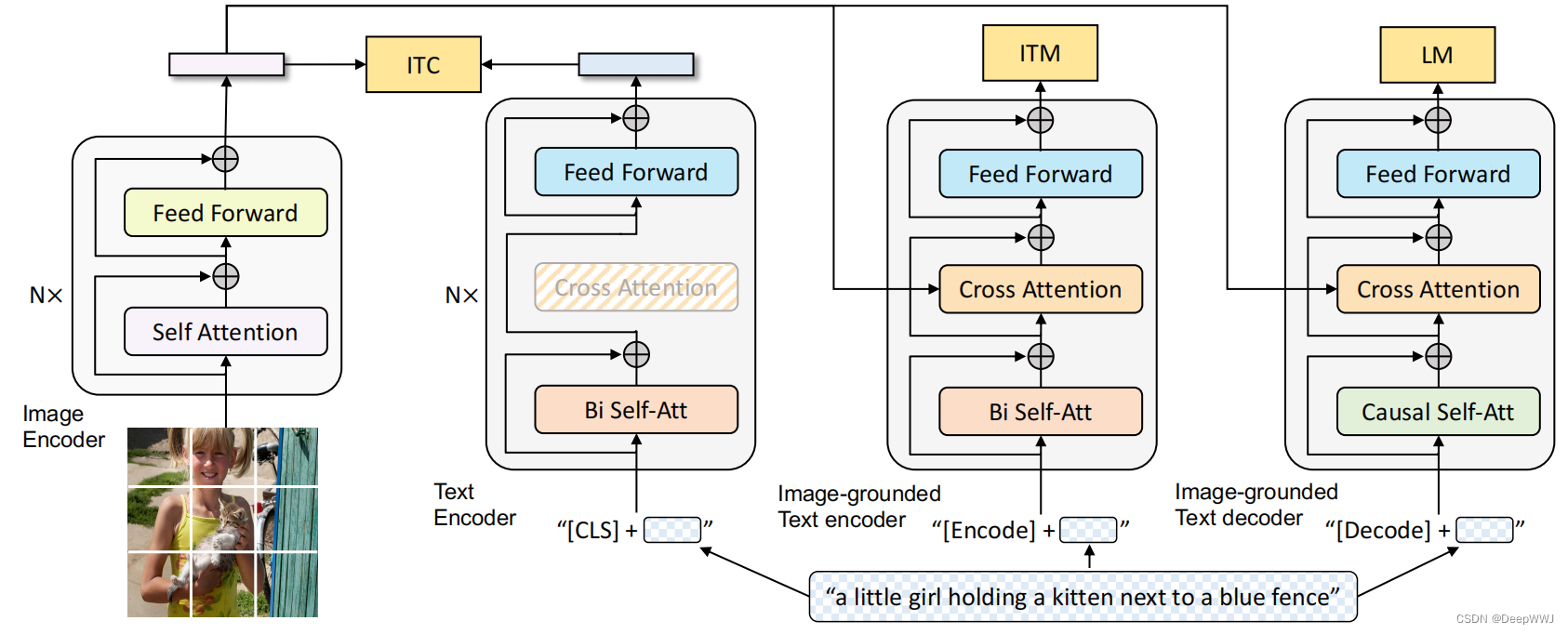
算法流程:
- 模型中Text Encoder;Image-grounded Text Encoder 与 Image-grounded Text decoder共享参数,与VLMo一致。
- 图像使用一个标准的Image Encoder来提取特征,text部分使用针对不同的任务来打开或关闭模型组件参数。
损失函数:
- 与ALBEF损失函数类似,知识MLM换成了LM(预测下一个词)。
Caption Filter模块
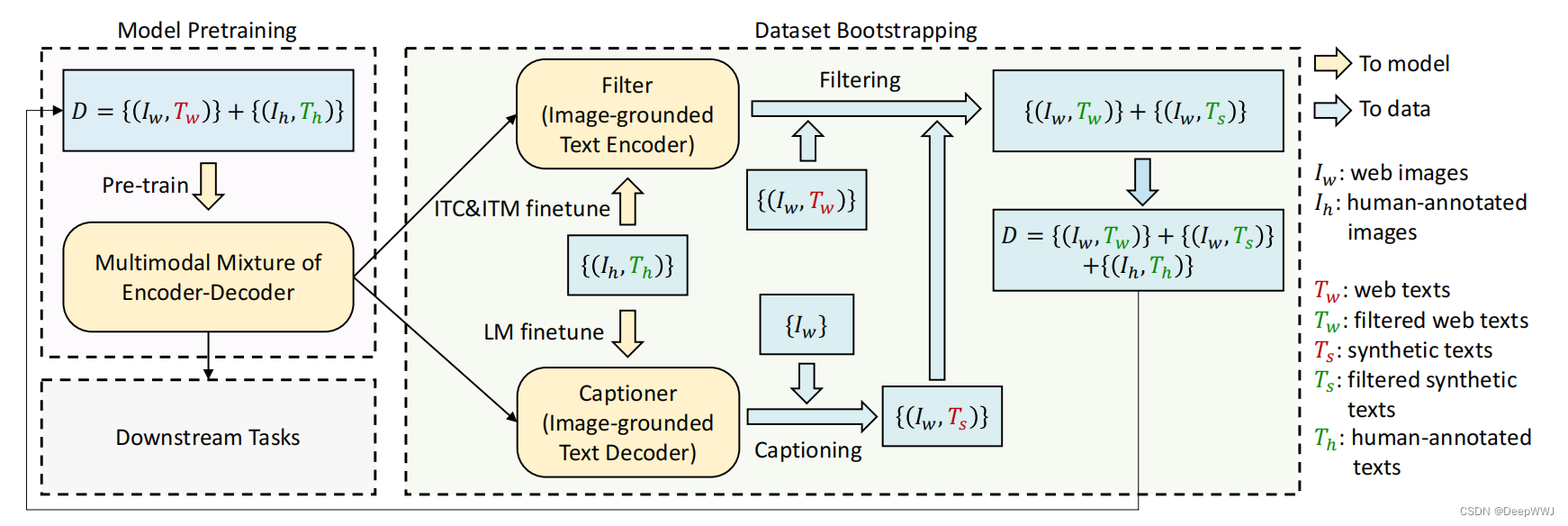
- 收集网络上噪声数据( I w I_w Iw, T w T_w Tw),以及人工标注的数据( I h I_h Ih, T h T_h Th)
- 使用( I h I_h Ih, T h T_h Th)数据以及IT,ITM,LM损失函数训练Filter
- 使用Filter过滤( I w I_w Iw, T w T_w Tw),并且使用Caption生成新数据( I w I_w Iw, T s T_s Ts)。
- 最终将人工标注数据+过滤后的网络数据+生成的caption数据共同训练模型。
CoCa: Contrastive Captioners are Image-Text Foundation Models
突出贡献: (ALBEF的后续) 大力出奇迹!!!
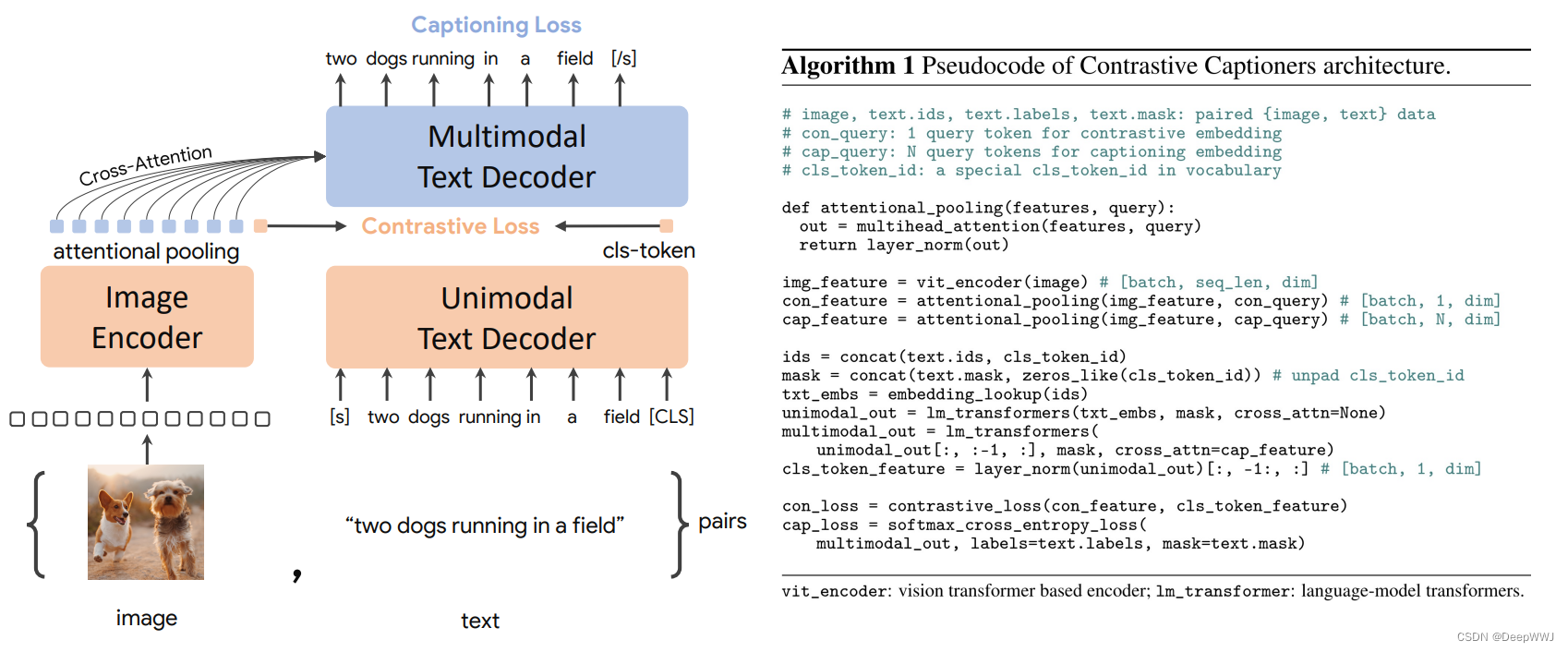
Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks (CVPR 2023)
突出贡献: 大一统!!!损失函数统一为mask loss; 网络统一为Multiway Transformer(开关可控)。
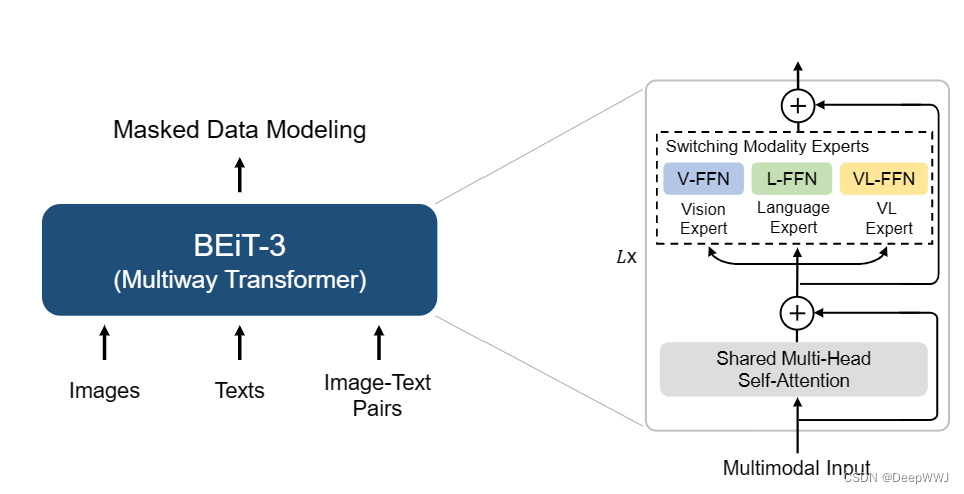
将图像作为单词(image as a foreign language),所有都是NLP!!!,VLMo负责框架统一,Mask model负责损失统一。

