
热门标签
热门文章
- 1Grounded-SAM(最强Zero-Shot视觉应用):本地部署及各个模块的全网最详细使用教程!_grounded sam 本地部署
- 2ELK5.5.0 集群部署以及体验使用插件X-pack
- 3Mac之NVM|通过brew安装、更新、卸载、重新安装nvm_brew 安装nvm
- 4uniapp tab切换【可滚动视图】
- 5基于 ElasticSearch 实现站内全文搜索,写得太好了!
- 6网络基础 利用vnc viewer访问在vmware虚拟机上的linux
- 7机器学习lgbm时间序列预测实战
- 8java 实体类校验_实体类的验证
- 92023年12月上旬大模型新动向集锦
- 10.NET Apache Spark做基于商品推荐系统如此简单_spark商品推荐
当前位置: article > 正文
bert做文本摘要_BERT之后的模型有哪些?
作者:weixin_40725706 | 2024-03-31 08:40:51
赞
踩
bart和pegasus
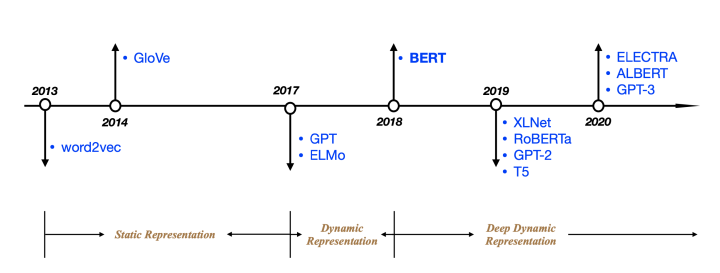
这是一篇总结性笔记,对NLP中预训练模型BERT之后的预训练模型进行总结,包括它的特点和主要改进。如果笔者有使用过的,也会给出使用的“手感”体会。注:文中的每个术语都给出了中文翻译和原英文表述,方便大家进行中英文阅读和偶尔装逼之用。
接上一篇文章继续写!上一篇文章链接如下:
Chanl Wei:BERT的前世今生(一)zhuanlan.zhihu.com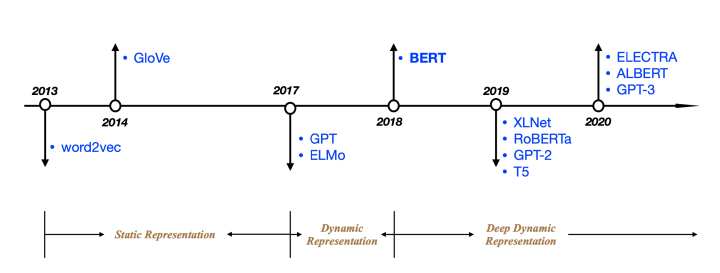
总纲
先给出一个列表,BERT之后的模型有哪些,不是很全,只列出我看过论文或用过的:
- BERT-wwm
- XLNET
- ALBERT
- RoBERTa
- ELECTRA
- BART
- PEGASUS
之后还有关于GPT-n,T5以及很多当前被用于实际项目的中文模型的使用,不过不打算直接加在文章后面了,太长了,如果有需要,后面会再更新的,手打这么多文字还是很累人的。这篇文章的阅读大约需要20-30分钟,如果没时间阅读的话,建议先收藏点赞,然后后面再仔细阅读,因为是笔记类的文章,常读常新。
BERT-wwm
WWM,Whole Word Mask。这是一个技巧或者思想,在很多文章中都有使用,这里把它列出来,是因为中文预训练模型中引入了该思想,获得了比较好的结果,如ERINE 。
在原本的BERT中,使用了wordpiece分词方法,所以一个单词如:apple,经过tokenizer分词后变为ap + ##p + ##le,而mask预测时,会随机选取其中的某一个或几个进行预测,所以会出现一个完整的单词被部分预测的问题,所以后面出现了WWM预测的思路,也就是每次预测都对整个单词进行预测,如上文中的,同时预测“ap + ##p + ##le” 三个[MASK]. 在中文中则是N-gram预测。
WWM方法进行预测时,每次会对整个单词进行预测。
XLNET
XLNET刚出来的时候,还是火爆一时的,但很快就被后面的浪花挤上了沙滩。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/343966
推荐阅读
相关标签

