
- 1NLP--文本丶语义匹配方法概述详解_文本语义匹配
- 2复权算法详解与代码实现细节解析(tgw)——量化数据中台系列(六)_复权因子的计算方法?
- 32021最新 使用阿里云邮件推送服务架设自己邮件验证与推送体系_sendcloud邮箱可以配置到第三方客户端使用吗
- 4NLP学习路径(八):情感分析技术_对情感分析的研究目前主要集中在
- 5如何选择向量数据库|Weaviate Cloud v.s. Zilliz Cloud_向量库如何选择
- 6利用MATLAB求解非线性优化问题---fgoalattain函数详解及应用案例_matlab fgoalattain函数
- 7清华团队研发大模型对齐技术UltraLM,登顶斯坦福Alpaca-Eval开源模型榜单
- 8LLM - 大语言模型的指令微调(Instruction Tuning) 概述
- 9第8章 微服务架构设计 【4、微服务的分解和组合模式有哪些】_原子服务和聚合服务
- 10一款Linux、数据库、Redis、MongoDB统一管理平台,有点牛逼了!
Redis内存回收策略_避免redis内存不足故障
赞
踩
Redis内存回收策略
很多同学了解了Redis的好处之后,于是把任何数据都往Redis中放,如果使用不合理很容易导致数据超过Redis的内存,这种情况会出现什么问题呢?
-
Redis中有很多无效的缓存,这些缓存数据会降低数据IO的性能,因为不同的数据类型时间复杂度算法不同,数据越多可能会造成性能下降。
-
随着系统的运行,redis的数据越来越多,会导致物理内存不足。通过使用虚拟内存(VM),将很少访问的数据交换到磁盘上,腾出内存空间的方法来解决物理内存不足的情况。虽然能够解决物理内存不足导致的问题,但是由于这部分数据是存储在磁盘上,如果在高并发场景中,频繁访问虚拟内存空间会严重降低系统性能。
所以遇到这类问题的时候,我们一般有几种方法:
-
对每个存储到redis中的key设置过期时间,这个根据实际业务场景来决定。否则,再大的内存都会随着系统运行被消耗完。
-
增加内存。
-
使用内存淘汰策略。
1. 设置Redis能够使用的最大内存
在实际生产环境中,服务器不仅仅只有Redis,为了避免Redis内存使用过多对其他程序造成影响,我们一般会设置最大内存。
Redis默认的最大内存 maxmemory=0 ,表示不限制Redis内存的使用。我们可以修改 redis.conf 文件,设置Redis最大使用的内存。
# 单位为byte
maxmemory <bytes> 2147483648(2G)
- 1
- 2
如何查看当前Redis最大内存设置呢,进入到Redis-Cli控制台,输入下面这个命令。
config get maxmemory
- 1
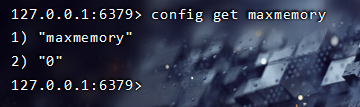
当Redis中存储的内存超过maxmemory时,会怎么样呢?下面我们做一个实验
-
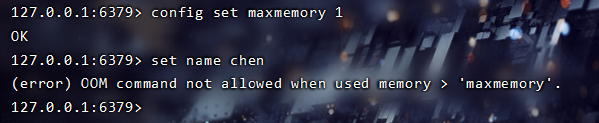
在redis-cli控制台输入下面这个命令,把最大内存设置为1个字节。
config set maxmemory 1- 1
-
通过下面的命令存储一个string类型的数据
set name chen- 1
-
此时,控制台会得到下面这个错误信息
(error) OOM command not allowed when used memory > 'maxmemory'.- 1
2. 使用内存淘汰策略释放内存
设置了maxmemory的选项,redis内存使用达到上限。可以通过设置LRU算法来删除部分key,释放空间。默认是按照过期时间的,如果set时候没有加上过期时间就会导致数据写满maxmemory。
Redis中提供了一种内存淘汰策略,当内存不足时,Redis会根据相应的淘汰规则对key数据进行淘汰。Redis一共提供了8种淘汰策略,默认的策略为noeviction,当内存使用达到阈值的时候,所有申请内存的命令会报错。
-
volatile-lru,针对设置了过期时间的key,使用lru算法进行淘汰。
-
allkeys-lru,针对所有key使用lru算法进行淘汰。
-
volatile-lfu,针对设置了过期时间的key,使用lfu算法进行淘汰。
-
allkeys-lfu,针对所有key使用lfu算法进行淘汰。
-
volatile-random,从所有设置了过期时间的key中使用随机淘汰的方式进行淘汰。
-
allkeys-random,针对所有的key使用随机淘汰机制进行淘汰。
-
volatile-ttl,删除生存时间最近的一个键。
-
noeviction,不删除键,值返回错误。
前缀为volatile-和allkeys-的区别在于二者选择要清除的键时的字典不同,volatile-前缀的策略代表从redisDb中的expire字典中选择键进行清除;allkeys-开头的策略代表从dict字典中选择键进行清除。
内存淘汰算法的具体工作原理是:
-
客户端执行一条新命令,导致数据库需要增加数据(比如set key value)
-
Redis会检查内存使用,如果内存使用超过 maxmemory,就会按照置换策略删除一些 key
-
新的命令执行成功
3. 了解LRU算法
LRU是Least Recently Used的缩写,也就是表示最近很少使用,也可以理解成最久没有使用。也就是说当内存不够的时候,每次添加一条数据,都需要抛弃一条最久时间没有使用的旧数据。
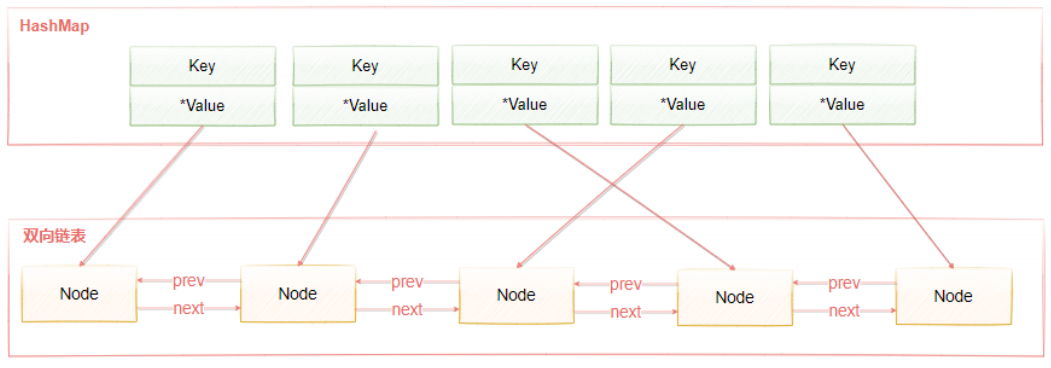
标准的LRU算法为了降低查找和删除元素的时间复杂度,一般采用Hash表和双向链表结合的数据结构,hash表可以赋予链表快速查找到某个key是否存在链表中,同时可以快速删除、添加节点,如下图所示:
双向链表的查找时间复杂度是O(n),删除和插入是O(1),借助HashMap结构,可以使得查找的时间复杂度变成O(1)
Hash表用来查询在链表中的数据位置,链表负责数据的插入,当新数据插入到链表头部时有两种情况。
-
链表满了,把链表尾部的数据丢弃掉,新加入的缓存直接加入到链表头中。
-
当链表中的某个缓存被命中时,直接把数据移到链表头部,原本在头节点的缓存就向链表尾部移动
这样,经过多次Cache操作之后,最近被命中的缓存,都会存在链表头部的方向,没有命中的,都会在链表尾部方向,当需要替换内容时,由于链表尾部是最少被命中的,我们只需要淘汰链表尾部的数据即可。
4. Redis中的LRU算法
实际上,Redis使用的LRU算法其实是一种不可靠的LRU算法,它实际淘汰的键并不一定是真正最少使用的数据,它的工作机制是:
-
随机采集淘汰的key,每次随机选出5个key
-
然后淘汰这5个key中最少使用的key
这5个key是默认的个数,具体的数值可以在redis.conf中配置;
maxmemory-samples 5
- 1
当近似LRU算法取值越大的时候就会越接近真实的LRU算法,因为取值越大获取的数据越完整,淘汰中的数据就更加接近最少使用的数据。这里其实涉及一个权衡问题,
如果需要在所有的数据中搜索最符合条件的数据,那么一定会增加系统的开销,Redis是单线程的,所以耗时的操作会谨慎一些。
为了在一定成本内实现相对的LRU,早期的Redis版本是基于采样的LRU,也就是放弃了从所有数据中搜索解改为采样空间搜索最优解。Redis3.0版本之后,Redis作者对于基于采样的LRU进行了一些优化:
-
Redis中维护一个大小为16的候选池,当第一次随机选取采用数据时,会把数据放入到候选池中,并且候选池中的数据会更具时间进行排序。
-
当第二次以后选取数据时,只有小于候选池内最小时间的才会被放进候选池。
-
当候选池的数据满了之后,那么时间最大的key就会被挤出候选池。当执行淘汰时,直接从候选池中选取最近访问时间小的key进行淘汰。
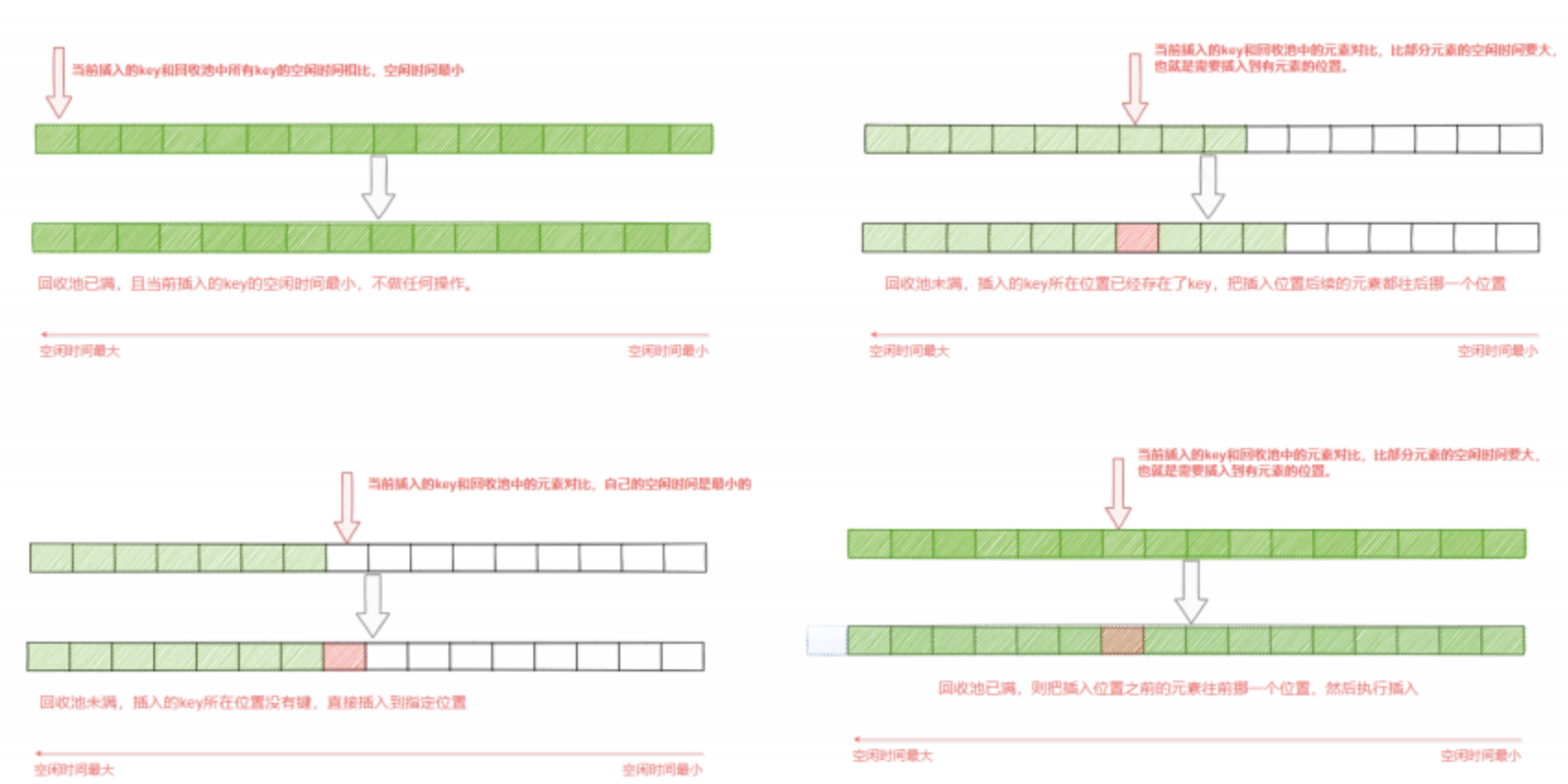
如下图所示,首先从目标字典中采集出maxmemory-samples个键,缓存在一个samples数组中,然后从samples数组中一个个取出来,和回收池中以后的键进行键的空闲时间,从而更新回收池。
在更新过程中,首先利用遍历找到的每个键的实际插入位置x,然后根据不同情况进行处理。
-
回收池满了,并且当前插入的key的空闲时间最小(也就是回收池中的所有key都比当前插入的key的空闲时间都要大),则不作任何操作。
-
回收池未满,并且插入的位置x没有键,则直接插入即可
-
回收池未满,且插入的位置x原本已经存在要淘汰的键,则把第x个以后的元素都往后挪一个位置,然后再执行插入操作。
-
回收池满了,将当前第x个以前的元素往前挪一个位置(实际就是淘汰了),然后执行插入操作。
这样做的目的是能够选出最真实的最少被访问的key,能够正确淘汰不常使用的key。因为在Redis3.0之前是随机选取样本,这样的方式很有可能不是真正意义上的最少访问的key。
LRU算法有一个弊端,加入一个key值访问频率很低,但是最近一次被访问到了,那LRU会认为它是热点数据,不会被淘汰。同样,经常被访问的数据,最近一段时间没有被访问,这样会导致这些数据被淘汰掉,导致误判而淘汰掉热点数据,于是在Redis 4.0中,新加了一种LFU算法。
5. LFU算法
LFU(Least Frequently Used),表示最近最少使用,它和key的使用次数有关,其思想是:根据key最近被访问的频率进行淘汰,比较少访问的key优先淘汰,反之则保留。
LRU的原理是使用计数器来对key进行排序,每次key被访问时,计数器会增大,当计数器越大,意味着当前key的访问越频繁,也就是意味着它是热点数据。 它很好的解决了LRU算法的缺陷:一个很久没有被访问的key,偶尔被访问一次,导致被误认为是热点数据的问题。
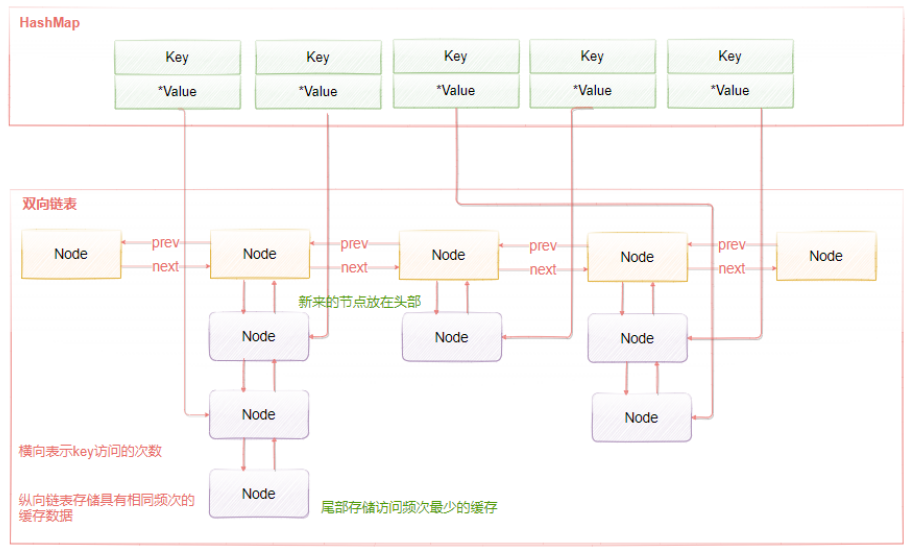
LFU的实现原理如下图所示,LFU维护了两个链表,横向组成的链表用来存储访问频率,每个访问频率的节点下存储另外一个具有相同访问频率的缓存数据。具体的工作原理是:
-
当添加元素时,找到相同访问频次的节点,然后添加到该节点的数据链表的头部。如果该数据链表满了,则移除链表尾部的节点
-
当获取元素或者修改元素是,都会增加对应key的访问频次,并把当前节点移动到下一个频次节点。
添加元素时,访问频率默认为1,随着访问次数的增加,频率不断递增。而当前被访问的元素也会随着频率增加进行移动。
6. 手写简陋版LRU算法
按照LRU的思想进行编码,通过hashmap提高查询速度。
每次获取节点的时候,将节点位置移到链表头部;
添加节点的时候,首先判断当前有无该节点,如果有的话重新赋值然后将节点移到至头部;
如果没有的话则先判断当前链表容量是否充足,不足的话将尾部的节点删除,在将节点添加至链表头部。
public class LRUCache { private Node head; private Node tail; private final HashMap<String, Node> nodeHashMap; private int capacity; //容量 //初始化 public LRUCache(int capacity) { this.capacity = capacity; nodeHashMap = new HashMap<>(); tail = new Node(); head = new Node(); head.next = tail; tail.prev = head; } //移除节点 private void removeNode(Node node) { //判断是否为头节点还是为节点 if (node == tail) { tail = tail.prev; tail.next = null; } else if (node == head) { head = head.next; head.prev = null; } else { node.prev.next = node.next; node.next.prev = node.prev; } } //添加节点到头部 private void addNodeToHead(Node node) { node.next = head.next; head.next.prev = node; node.prev = head; head.next = node; } //将节点移动至头节点 private void moveNodeToHead(Node node) { removeNode(node); addNodeToHead(node); } //获取节点 public String get(String key) { //从map获取,o1 Node node = nodeHashMap.get(key); if (node == null) { return null; } //刷新当前key的位置 moveNodeToHead(node); return node.value; } //添加节点 public void put(String key, String value) { Node node = nodeHashMap.get(key); if (node == null) { //如果不存在,则添加到链表 if (nodeHashMap.size() >= capacity) { //大于容量,则需要移除老的数据 removeNode(tail); //移除尾部节点(tail节点是属于要被淘汰数据) nodeHashMap.remove(tail.key); //从hashmap中移除 } node = new Node(key, value); nodeHashMap.put(key, node); addNodeToHead(node); } else { //重新赋值 node.value = value; //移动位置到头部 moveNodeToHead(node); } } class Node { private String key; private String value; Node prev; Node next; public Node() { } public Node(String key, String value) { this.key = key; this.value = value; } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95

