
- 12023年1000个优秀Github项目盘点_github实战项目
- 2墨者——内部文件上传系统漏洞分析溯源 内部文件上传系统漏洞分析溯源_墨者内部文件上传
- 3Audified 假日捆绑销售和DW Enhancer 的价格变化_dw价格
- 4解决微信小程序页面数量限制问题的6种方法
- 5企业CIO_ciozj
- 6解决问题 ModuleNotFoundError: No module named sklearn_from sklearn.model_selection import train_test_spl
- 7SwiftUI ArkUI 对比分析_arkui swiftui
- 8重磅亲测!ChatGPT是否产生了自我意识?
- 9【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)_大模型 sft dpo区别
- 10LTP--linux稳定性测试 linux性能测试 ltp压力测试 ---IBM 的 linux test project_ltp最新版压测linux
清华团队研发大模型对齐技术UltraLM,登顶斯坦福Alpaca-Eval开源模型榜单
赞
踩

最近,UltraLM-13B 在斯坦福大学 Alpaca-Eval 榜单中位列开源模型榜首,是唯一一个得分在 80 以上的开源模型。
ChatGPT之后,开源社区内复现追赶 ChatGPT 的工作成为了整个领域最热的研究点。其中,对齐(Alignment)技术是最重要的环节之一,来自斯坦福大学、伯克利、微软、Meta、Stability.AI 等多个机构都争相推出相关的模型和方法(如Alpaca、Vicuna、WizardLM 等等)。
清华的一个团队在探索对齐技术的过程中发现,训练出具有基本指令理解和追随能力的模型本身难度不高,但训练出可以针对各类指令都能给出高质量、有信息量和逻辑性回复的模型则十分困难。团队通过可扩展多样性(Scalable Diverse)的方法来大规模构造指令数据 UltraChat,并且在此之上开发了 UltraLM 对话语言模型。
Github链接:
https://github.com/thunlp/UltraChat
Huggingface链接:
https://huggingface.co/openbmb/UltraLM-13b
榜单链接:
https://tatsu-lab.github.io/alpaca_eval/

斯坦福Alpaca Eval榜单介绍
AlpacaEval 是斯坦福大学发布的用于自动评估大语言模型的排行榜,它包括了从测评数据集、模型回答生成,到自动评估的完整评测流程,目前榜单已经包含了来自全球各个机构的多个代表性模型。具体而言,该排行榜主要评估大模型遵从指令的能力以及回答质量,其中排行榜所使用的数据集共计 805 条指令,集成了来自于 Self-instruct,Open Assistant, Vicuna 等项目发布的测评数据。排行榜的具体指标计算方式为使用 GPT-4 自动评估当前模型的回答与 Text-Davinci-003 的回答,统计当前模型的胜率。
AlpacaEval 的实验表明,榜单所采用的 GPT-4 评估与人类标注结果的皮尔逊相关系数达到 94%,说明该评估方式可靠性较高。同时,研究人员对评估的成本也做了一定的分析,说明了当前评估方式大幅降低了人工评估所花费的经济成本和时间成本。斯坦福大学团队曾经发表指令微调语言模型的代表性工作之一 Alpaca,在 GitHub 上获得超过 25000 星标。
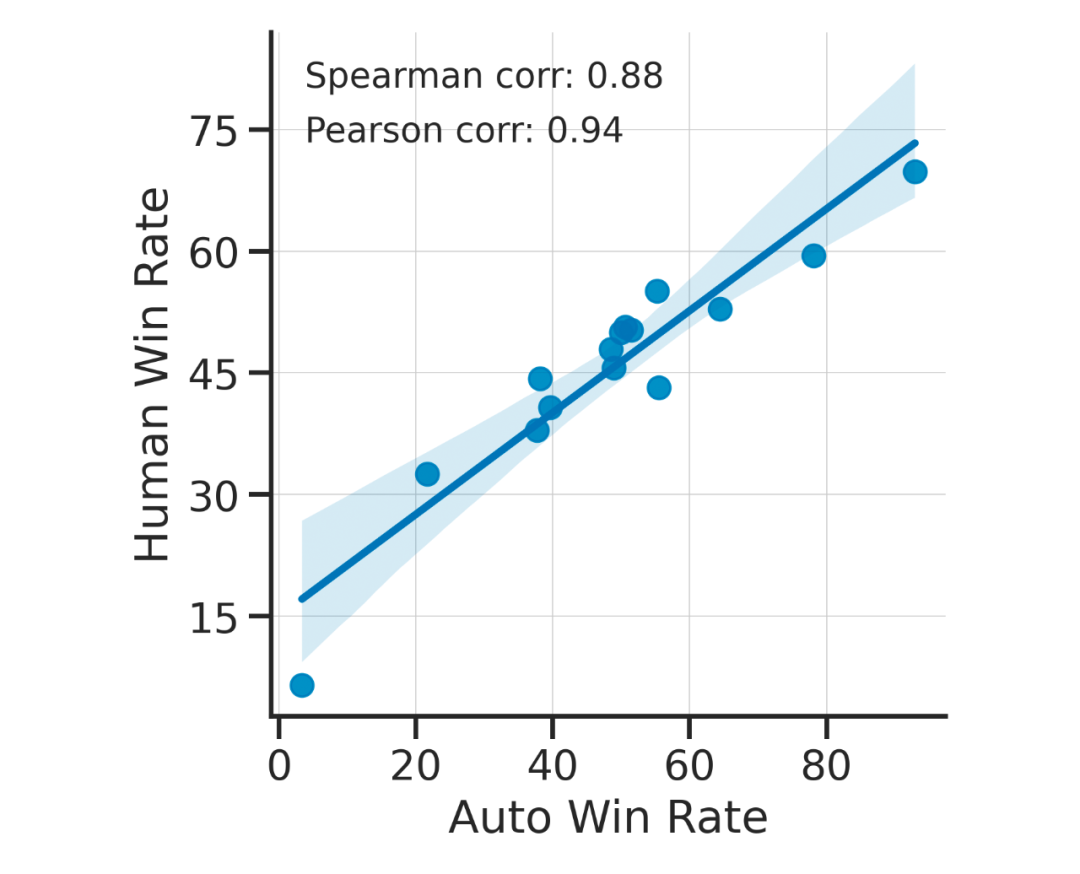
▲ Alpaca Eval自动化评测和人类专家高度吻合

榜单情况
目前,来自 OpenAI 和 Anthropic 的闭源模型 GPT-4, Claude 和 ChatGPT 仍然处于前三名,其中 GPT-4 的得分达到 95.28%,遥遥领先其他模型。但在开源模型中,UltraLM 13B 位居榜首,也是唯一一个得分在 80 以上的开源模型,超越第二名开源模型多达 5.33 分。Huggingface OpenLLM 榜单中位列榜首的 Falcon-40B Instruct 表现不佳,只得到了 45% 左右的得分。而来自微软的 WizardLM,来自加州大学伯克利分校的 Vicuna 模型都取得了较好的效果。
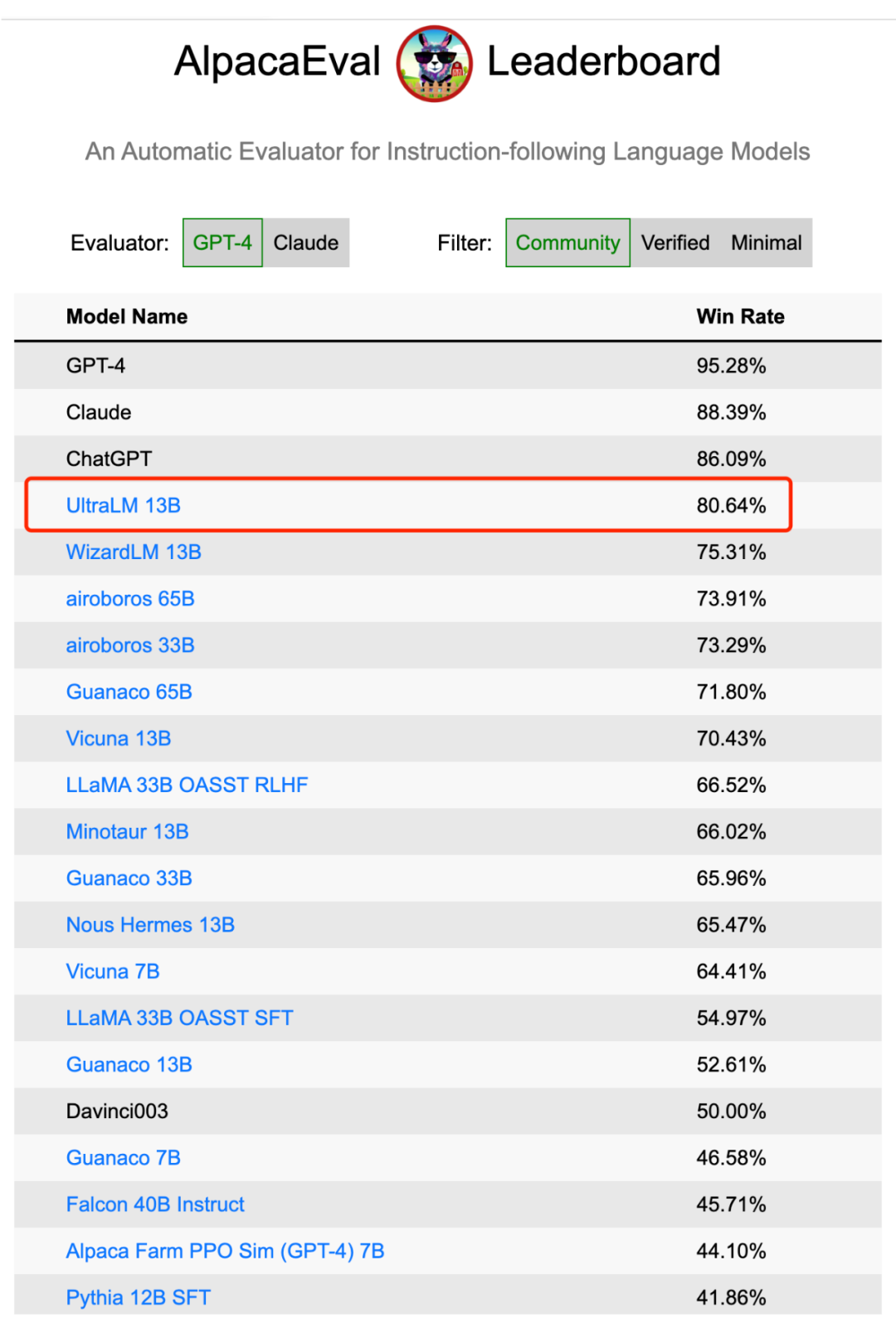
▲ 斯坦福大学Alpaca Eval榜单情况

关于UltraLM和UltraChat
UltraLM-13B 是一个在 UltraChat 数据上训练而来的大语言模型,它具有丰富的世界知识和超强的指令理解和跟随能力,能对各类问题/指令给出很有信息量的回复。
作为 UltraLM 的能力来源,UltraChat 由清华大学、面壁智能、知乎等机构组成的 OpenBMB 团队构建,这是一个大规模、高质量、高度多样化的多轮指令数据,包含了 150 余万条多轮指令数据。
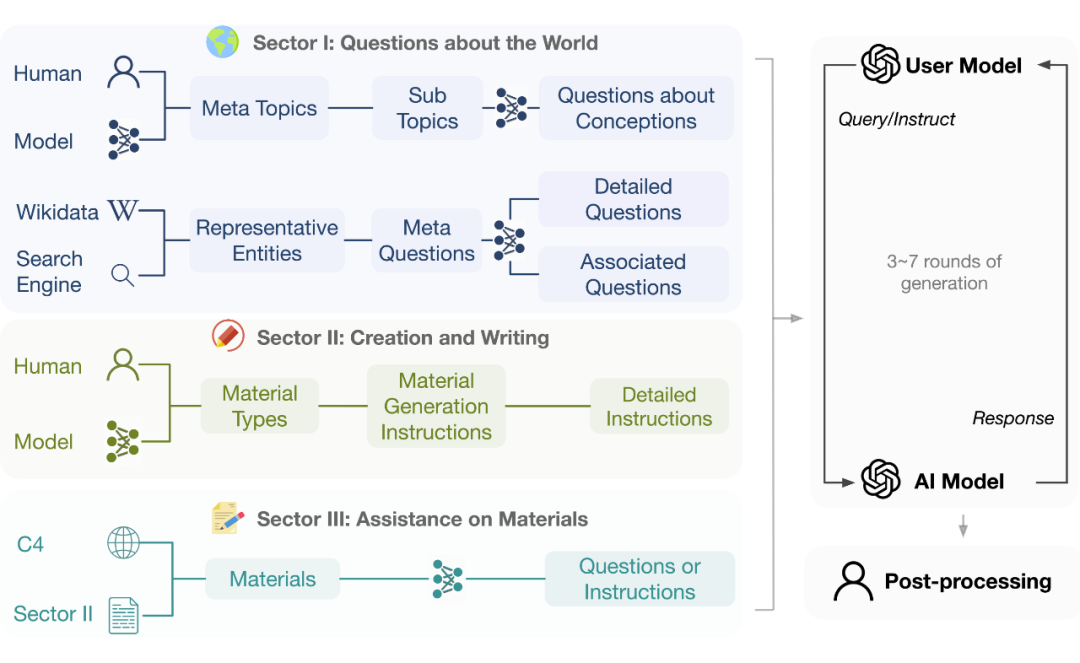
▲ UltraChat构建框架
UltraChat 秉承“可扩展多样化(Scalable Diverse)”的原则,即并非通过少量样本的选取来达到多样化的目的,而是设计方法论使得多样化数据可以大规模扩展。UltraChat 设计了三个模块来涵盖人类与机器可能交互的范式:信息获取、条件信息创造、信息转换,并且对用户模型进行了个性化建模。
在他们的文本多样化统计(Lexical Diversity)中,UltraChat 在 150 万条数据规模的情况下达到了 74.3 的得分,而此前公开数据的多样性得分最高仅有 67.1。

▲ UltraChat数据分布
3.1 模型训练
UltraLM 直接采用监督指令微调的方式对 LLaMA 进行全参数微调。对于 UltraChat 中的每一组多轮对话,将其分割成长度不超过 2048 的片段,遮蔽模型回答部分并计算该部分损失进行训练。该训练方式使得模型能够获得当前用户输入及对话历史作为上下文进行生成,有效保证了多轮对话的连贯性。
不同于 Vicuna 等模型,在训练过程中,UltraLM 不内嵌系统提示,以使得它可以被更灵活地定制化。
3.2 其他评测
除了在 AlpacaEval 评测集上进行评估外,他们还自己构建了一个指令评测集,该评测集包含了 80 条 Vicuna 测试集,以及其他 300 条由 GPT-4 生成的不同领域不同难度的指令,涵盖了对常识知识、世界知识、专业知识、数学及推理能力和创作能力的测试。
在该测评集上,他们同样使用 GPT-4 对 UltraLM 和基线模型进行相对打分比较。其中,他们显式地要求 GPT-4 优先考虑模型回复的正确性,再评估涵盖的信息量。同时,为了应对模型回复的先后顺序带来的影响,对每一个指令,他们随机指定模型回复的顺序。
下图显示,UltraLM 的回复与其他模型相比,胜率最高可以达 98%(vs Dolly-12B),同时分别以 9% 和 28% 的胜率优势超越了之前的最好开源模型 Vicuna 和 WizardLM。
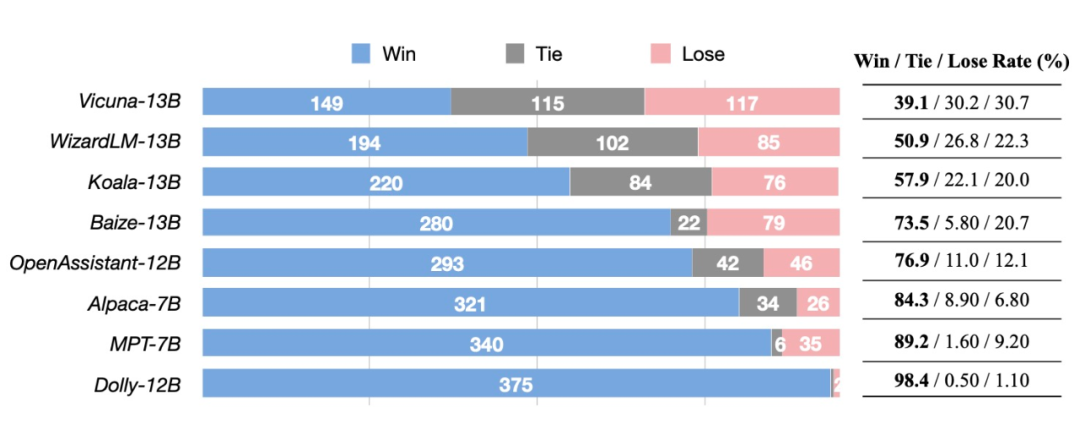
▲ UltraLM与其他模型的对比评测
在上述的测试中,UltraLM 与其他模型都使用了各自的定制化系统提示来增强模型回复的质量。团队发现,尽管 UltraLM 在训练过程中并未使用系统提示,在测试过程中系统提示对于模型回复质量的提升仍有重要作用。
尽管 UltraLM 在评测中领先其他开源模型,可以对多种形式的指令和问题给出符合人类价值观且有信息量的回复,但它仍然具有幻觉等大模型常有问题,团队表示,期待与开源社区的朋友们一起推动大模型对齐技术的发展,继续推出更加强大的模型。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

