
- 1聊聊十大网络安全上市公司,看F5拥有强大安全基因
- 2BERT模型原理的详细介绍
- 31、kibana常用es命令_kibana 访问es的常用命令
- 4pytorch12:GPU加速模型训练
- 5amd显卡测试大风车软件md,肉眼可见的撕裂 AMD将推出FreeSync2 HDR测试工具
- 6用Python实现自动向ChatGPT(GPT3.5)提问并获取回答 v2.0_python使用chatgpt自动化脚本输入prompt
- 7Vue 0基础学习路线(27)—— 图解深度详述vue路由的懒加载的使用及原理和深入原理原生js探究静态加载和懒加载、合并打包 - 把组件按组分块及详细案例(附详细案例代码解析过程及版本迭代过程)_vue路由懒加载 流程图
- 8RabbitMQ 安装及管理_rabbitmq 安装management
- 9爱人民币(iRMB)就不会 EMO 了?| ICCV-2023: 结合 CNN 和 Transformer 的倒残差移动模块设计_irbm倒残差
- 10thinkphp 3.2.3 - Route.class.php 解析(路由匹配)
【NLP实战】基于Bert和双向LSTM的情感分类【上篇】_bert-lstm
赞
踩
前言
最近自己找了个实验做,写了很多实验记录和方法,现在我将它们整理成文章,希望能对不熟悉NLP的伙伴们起到些许帮助。如有疑问请及时联系作者。
相关代码已同步至github(2024.1.23):issey_Kaggle/Bert_BiLSTM
本文代码(Notebook)已公布至kaggle:Sentiment Classification Based on BERT and LSTM | Kaggle
博主page:issey的博客 - 愿无岁月可回首
本系列文章中不会说明环境和包如何安装,这些应该是最基础的东西,可以自己边查边安装。
许多函数用法等在代码里有详细解释,但还是希望各位去看它们的官方文档,我的代码还有很多可以改进的方法,需要的函数等在官方文档都有说明。
简介
本系列将带领大家从数据获取、数据清洗、模型构建、训练,观察loss变化,调整超参数再次训练,并最后进行评估整一个过程。我们将获取一份公开竞赛中文数据,并一步步实验,到最后,我们的评估可以达到排行榜13位的位置。但重要的不是排名,而是我们能在其中学到很多。
本系列将分为三篇文章,分别是:
- 上篇:数据获取,数据分割与数据清洗
- 中篇:模型构建,改进pytorch结构,开始第一次训练
- 下篇:测试与评估,绘图与过拟合,超参数调整
本文为该系列第一篇文章,在本文中,我们将一同观察原始数据,进行数据清洗。样本是很重要的一个部分,学会观察样本并剔除一些符合特殊条件的样本,对模型在学习时有很大的帮助。
数据获取与提取
竞赛官网:疫情期间网民情绪识别 竞赛 - DataFountain
关于kaggle如何下载数据,本文不再赘述。
为了把数据分割也作为我们实验的一部分,假设我们现在拿到的nCoV_100k_train.labled.csv就是我们爬取到的原始数据。
先来看看我们用到的数据长什么样。
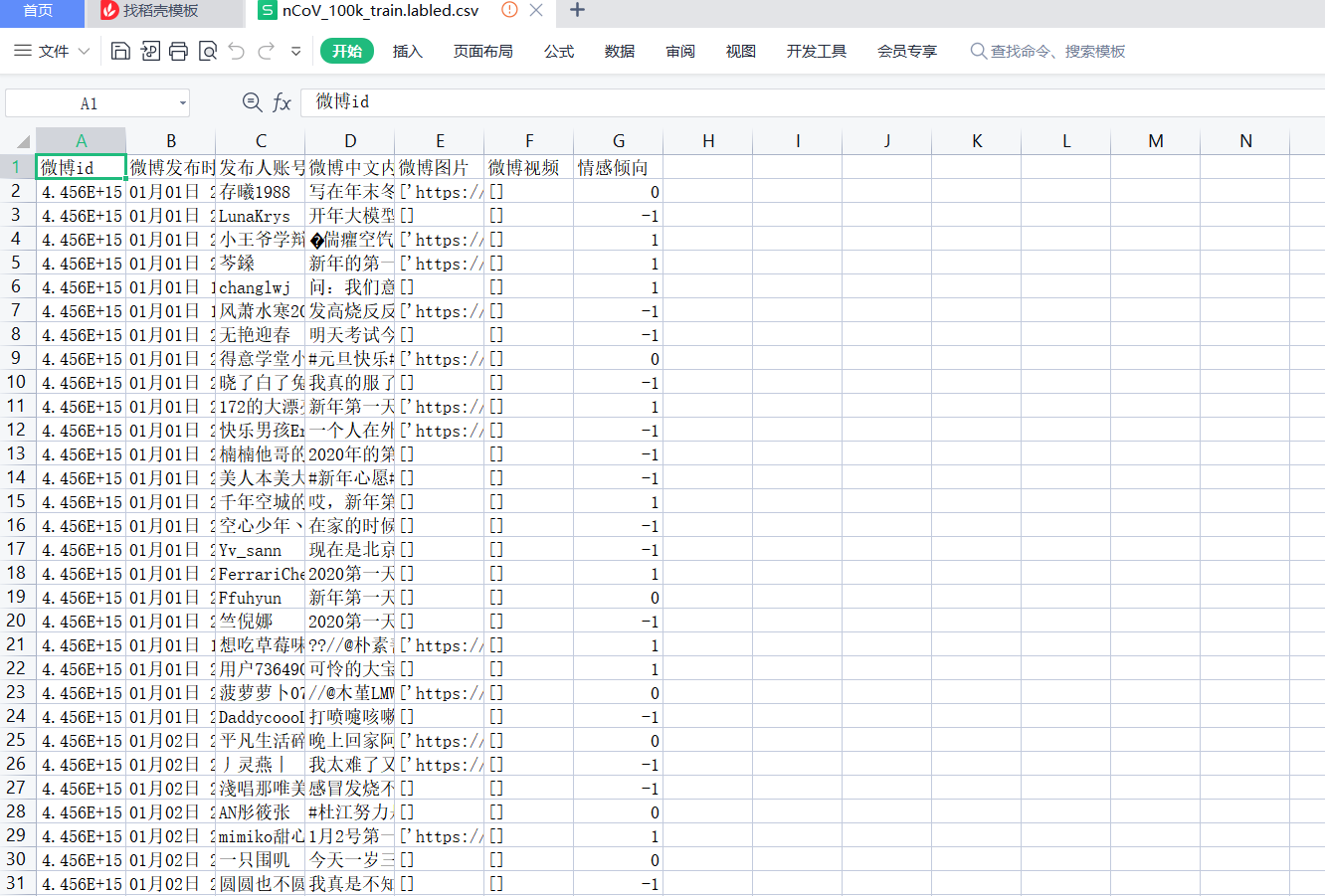
思考:
- 我们只需要text和情感倾向的列,其他列都不需要。
- 分割数据时,训练集:测试集:验证集 = 6:2:2。这只是博主自己选择的比例,各位可以自行调整。
编写代码。这部分比较简单,就不一步步运行了,但是各位应该逐行运行观察变化,写文章不能像jupyter notebook那样一行行运行,为了方便起见,文章涉及的代码都将以块状给出。但是运行实际上很多都是逐行调整的。
数据获取.py
import pandas as pd
from sklearn.model_selection import train_test_split
# todo: 读取数据
df = pd.read_csv('./data/archive/nCoV_100k_train.labled.csv')
print(df)
# 只要text和标签
df = df[['微博中文内容', '情感倾向']]
df = df.rename(columns={'微博中文内容': 'text', '情感倾向': 'label'})
print(df)
# todo: 分割数据集,储存.0.6/0.2/0.2
train, test = train_test_split(df, test_size=0.2)
train, val = train_test_split(train, test_size=0.25)
print(train)
print(test)
print(val)
train.to_csv('./data/archive/train.csv', index=None)
val.to_csv('./data/archive/val.csv', index=None)
test.to_csv('./data/archive/test.csv', index=None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结束后,这三个文件就是我们需要的文件。
数据清洗
我的清洗思路来源于这篇:Emotion analysis and Classification using LSTM 93% | Kaggle
该部分需要的库:
- seaborn:一个适合数据分析的绘图库,需要matplotlib作为前置库
读取数据,查看数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# todo:读取数据
df_train = pd.read_csv('./data/archive/train.csv')
df_test = pd.read_csv('./data/archive/test.csv')
df_val = pd.read_csv('./data/archive/val.csv')
# 输出前5行
print(df_train.head())
print(df_train.shape)
print(df_test.head())
print(df_test.shape)
print(df_val.head())
print(df_val.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出:

清洗训练集
观察数据分布
# todo: 清洗Train
# 观察数据是否平衡
print(df_train.label.value_counts())
print(df_train.label.value_counts() / df_train.shape[0] * 100)
plt.figure(figsize=(8, 4))
sns.countplot(x='label', data=df_train)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
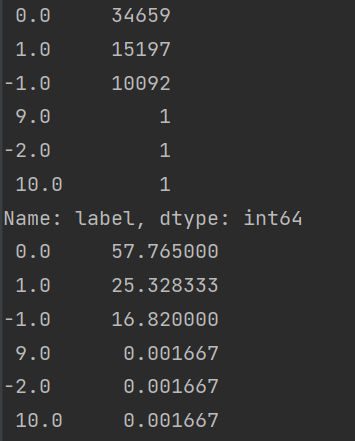
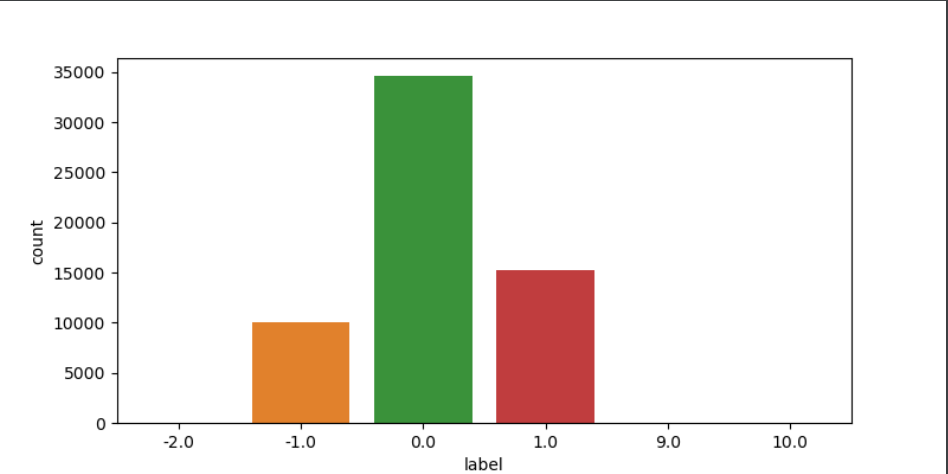
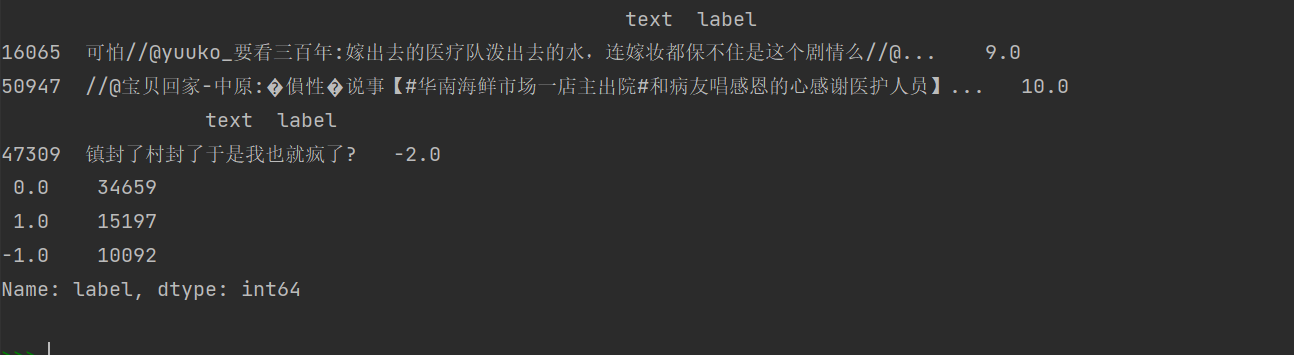
可以发现,-2.0,9.0,10.0都只有一个样本,当作异常数据处理,我选择直接丢掉不要。
另外,这个样本分布略微存在分布不平衡imbalance的情况,至于要不要用smote等方法过采样,暂时先不进行讨论,我们暂时保持数据不变。
print(df_train[df_train.label > 5.0])
print(df_train[(df_train.label < -1.1)])
# 丢掉异常数据
df_train.drop(df_train[(df_train.label < -1.1) | (df_train.label > 5)].index, inplace=True, axis=0)
df_train.reset_index(inplace=True, drop=True)
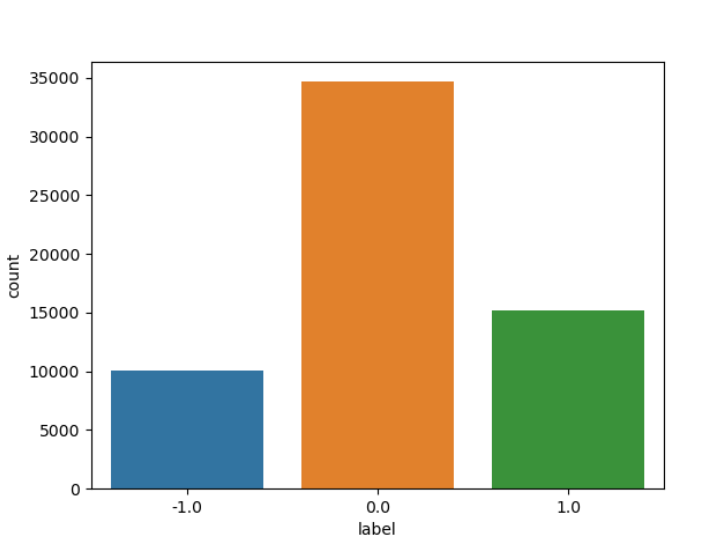
print(df_train.label.value_counts())
sns.countplot(x='label', data=df_train)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
去除空数据
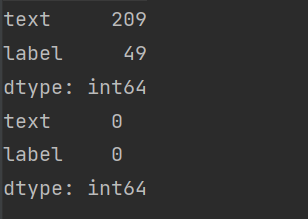
# 观察是否有空行
print(df_train.isnull().sum())
# 删除空行数据
df_train.dropna(axis=0, how='any', inplace=True)
df_train.reset_index(inplace=True, drop=True)
print(df_train.isnull().sum())
- 1
- 2
- 3
- 4
- 5
- 6
去除重复数据
# 查看重复数据
print(df_train.duplicated().sum())
# print(df_train[df_train.duplicated()==True])
# 删除重复数据
index = df_train[df_train.duplicated() == True].index
df_train.drop(index, axis=0, inplace=True)
df_train.reset_index(inplace=True, drop=True)
print(df_train.duplicated().sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后我们还需要去除text一样但是label不一样的数据。
# 我们还需要关心的重复数据是text一样但是label不一样的数据。
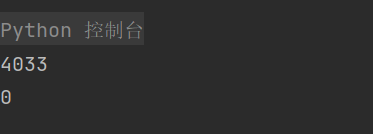
print(df_train['text'].duplicated().sum())
print(df_train[df_train['text'].duplicated() == True])
# 查看例子
print(df_train[df_train['text'] == df_train.iloc[856]['text']])
print(df_train[df_train['text'] == df_train.iloc[3096]['text']])
- 1
- 2
- 3
- 4
- 5
- 6

# 去掉text一样但是label不一样的数据
index = df_train[df_train['text'].duplicated() == True].index
df_train.drop(index, axis=0, inplace=True)
df_train.reset_index(inplace=True, drop=True)
# 检查
print(df_train['text'].duplicated().sum()) # 0
- 1
- 2
- 3
- 4
- 5
- 6
关于去除停用词
去不去除停用词和构建word embedding选择的方法有关,去查了一下,使用Bert构建时,不需要去除停用词处理,否则还会丢失上下文。于是这里没有进一步去除停用词。

关于特殊符号
观察我们现在的数据:

很容易发现里面有特殊字符。
待会儿用到的bert,它会用到一个中文字典,这个字典是它自己有的,如果出现字典里没有的字符,它会自动替换成[UNK],所以不用管。
储存清洗后的数据集
df_train.to_csv('./data/archive/train_clean.csv', index=None)
- 1
清洗测试集
整体步骤和清洗训练集的一样。这里为了巩固处理思路,自己还是详细做一遍吧。
观察数据分布
# 观察数据是否平衡
print(df_test.label.value_counts())
print(df_test.label.value_counts() / df_test.shape[0] * 100)
plt.figure(figsize=(8, 4))
sns.countplot(x='label', data=df_test)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
输出就不放了,放个图。
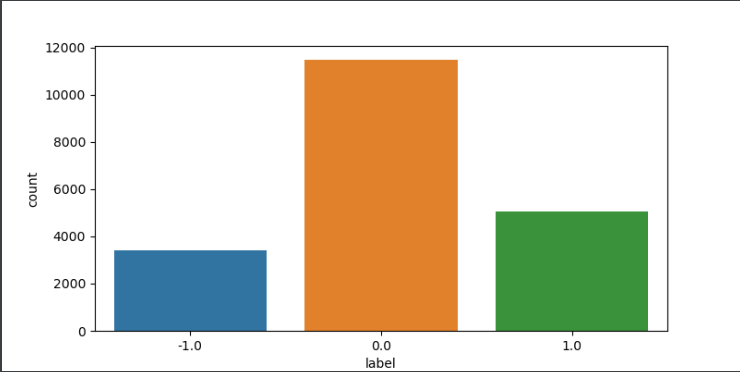
没有特殊label,不用进行去除的操作。
哦对,执行时可以把上面清洗train的代码注释了,用不着重新跑。
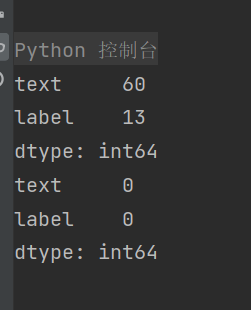
去除空数据
# 观察是否有空行
print(df_test.isnull().sum())
# 删除空行数据
df_test.dropna(axis=0, how='any', inplace=True)
df_test.reset_index(inplace=True, drop=True)
print(df_test.isnull().sum())
- 1
- 2
- 3
- 4
- 5
- 6
去除重复数据(并储存)
# 查看重复数据
print(df_test.duplicated().sum())
# print(df_test[df_test.duplicated()==True])
# 删除重复数据
index = df_test[df_test.duplicated() == True].index
df_test.drop(index, axis=0, inplace=True)
df_test.reset_index(inplace=True, drop=True)
print(df_test.duplicated().sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
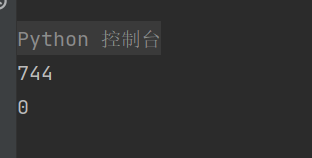
# 重复数据是text一样但是label不一样的数据。
print(df_test['text'].duplicated().sum())
print(df_test[df_test['text'].duplicated() == True])
# 查看例子
# print(df_test[df_test['text'] == df_test.iloc[2046]['text']])
# print(df_test[df_test['text'] == df_test.iloc[3132]['text']])
# 去掉text一样但是label不一样的数据
index = df_test[df_test['text'].duplicated() == True].index
df_test.drop(index, axis=0, inplace=True)
df_test.reset_index(inplace=True, drop=True)
# 检查
print(df_test['text'].duplicated().sum()) # 0
# print(df_test)
# 检查形状与编号
print(df_test.tail())
print(df_test.shape)
df_test.to_csv('./data/archive/test_clean.csv', index=None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

有的注释可以打开自己看着调。
清洗验证集
观察数据分布
# 观察数据是否平衡
print(df_val.label.value_counts())
print(df_val.label.value_counts() / df_val.shape[0] * 100)
plt.figure(figsize=(8, 4))
sns.countplot(x='label', data=df_val)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
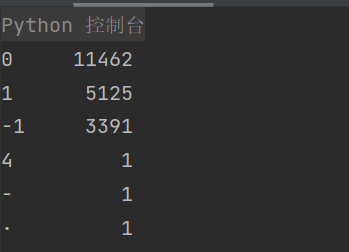
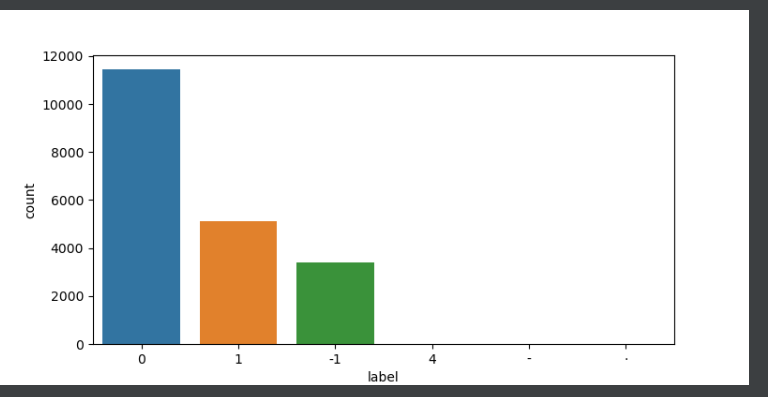
有三个取值我们需要剔除。
# 丢掉异常数据
df_val.drop(df_val[(df_val.label == '4') |
(df_val.label == '-') |
(df_val.label == '·')].index, inplace=True, axis=0)
df_val.reset_index(inplace=True, drop=True)
print(df_val.label.value_counts())
sns.countplot(x='label', data=df_val)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
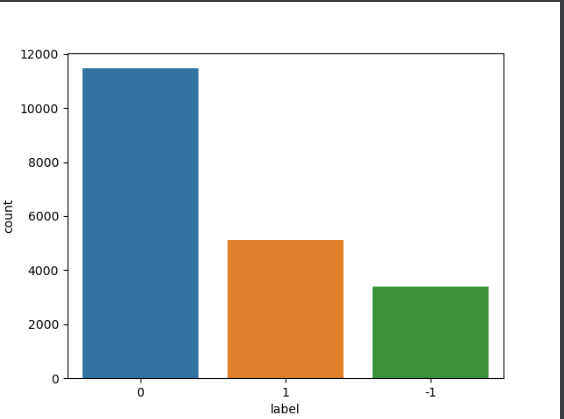
去除空行
# 观察是否有空行
print(df_val.isnull().sum())
# 删除空行数据
df_val.dropna(axis=0, how='any', inplace=True)
df_val.reset_index(inplace=True, drop=True)
print(df_val.isnull().sum())
- 1
- 2
- 3
- 4
- 5
- 6
去除重复数据(并储存)
# 查看重复数据
print(df_val.duplicated().sum())
# print(df_val[df_val.duplicated()==True])
# 删除重复数据
index = df_val[df_val.duplicated() == True].index
df_val.drop(index, axis=0, inplace=True)
df_val.reset_index(inplace=True, drop=True)
print(df_val.duplicated().sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
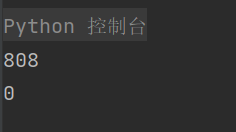
# 重复数据是text一样但是label不一样的数据。
print(df_val['text'].duplicated().sum())
# print(df_val[df_val['text'].duplicated() == True])
# 查看例子
# print(df_val[df_val['text'] == df_val.iloc[1817]['text']])
# print(df_val[df_val['text'] == df_val.iloc[2029]['text']])
# 去掉text一样但是label不一样的数据
index = df_val[df_val['text'].duplicated() == True].index
df_val.drop(index, axis=0, inplace=True)
df_val.reset_index(inplace=True, drop=True)
# 检查
print(df_val['text'].duplicated().sum()) # 0
# print(df_val)
# 检查形状与编号
print(df_val.tail())
print(df_val.shape)
df_val.to_csv('./data/archive/val_clean.csv', index=None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

总结
到此为止,我们已经清洗好了数据。让我们来看看在本次清洗时,忽略了哪些在其他实验中可以继续改进的地方:
- 本次清洗没有去除停用词,因为使用
bert时去除停用词可能会丢失上下文。 - 本次清洗没有去除特殊字符,因为
bert会自动将未知字符转化为[UKN]。 - 本次没有对样本进行
过采样/欠采样来解决imbalance问题,这个问题留到评估模型后再考虑要不要讨论。
下一篇文章中,我们将会使用Pytorch搭建Bert和双向LSTM实现多分类。
代码汇总
数据清洗.py
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# todo:读取数据
df_train = pd.read_csv('./data/archive/train.csv')
df_test = pd.read_csv('./data/archive/test.csv')
df_val = pd.read_csv('./data/archive/val.csv')
# 输出前5行
# print(df_train.head())
# print(df_train.shape)
# print(df_test.head())
# print(df_test.shape)
# print(df_val.head())
# print(df_val.shape)
# todo: 清洗Train
# 观察数据是否平衡
# print(df_train.label.value_counts())
# print(df_train.label.value_counts() / df_train.shape[0] * 100)
# plt.figure(figsize=(8, 4))
# sns.countplot(x='label', data=df_train)
# plt.show()
# print(df_train[df_train.label > 5.0])
# print(df_train[(df_train.label < -1.1)])
# 丢掉异常数据
df_train.drop(df_train[(df_train.label < -1.1) | (df_train.label > 5)].index, inplace=True, axis=0)
df_train.reset_index(inplace=True, drop=True)
# print(df_train.label.value_counts())
# sns.countplot(x='label', data=df_train)
# plt.show()
# 观察是否有空行
# print(df_train.isnull().sum())
# 删除空行数据
df_train.dropna(axis=0, how='any', inplace=True)
df_train.reset_index(inplace=True, drop=True)
# print(df_train.isnull().sum())
# 查看重复数据
# print(df_train.duplicated().sum())
# print(df_train[df_train.duplicated()==True])
# 删除重复数据
index = df_train[df_train.duplicated() == True].index
df_train.drop(index, axis=0, inplace=True)
df_train.reset_index(inplace=True, drop=True)
# print(df_train.duplicated().sum())
# 我们还需要关心的重复数据是text一样但是label不一样的数据。
# print(df_train['text'].duplicated().sum())
# print(df_train[df_train['text'].duplicated() == True])
# 查看例子
# print(df_train[df_train['text'] == df_train.iloc[856]['text']])
# print(df_train[df_train['text'] == df_train.iloc[3096]['text']])
# 去掉text一样但是label不一样的数据
index = df_train[df_train['text'].duplicated() == True].index
df_train.drop(index, axis=0, inplace=True)
df_train.reset_index(inplace=True, drop=True)
# 检查
# print(df_train['text'].duplicated().sum()) # 0
# print(df_train)
# 检查形状与编号
print("======train-clean======")
print(df_train.tail())
print(df_train.shape)
df_train.to_csv('./data/archive/train_clean.csv', index=None)
# todo: 清洗test
# 观察数据是否平衡
# print(df_test.label.value_counts())
# print(df_test.label.value_counts() / df_test.shape[0] * 100)
# plt.figure(figsize=(8, 4))
# sns.countplot(x='label', data=df_test)
# plt.show()
# 观察是否有空行
# print(df_test.isnull().sum())
# 删除空行数据
df_test.dropna(axis=0, how='any', inplace=True)
df_test.reset_index(inplace=True, drop=True)
# print(df_test.isnull().sum())
# 查看重复数据
# print(df_test.duplicated().sum())
# print(df_test[df_test.duplicated()==True])
# 删除重复数据
index = df_test[df_test.duplicated() == True].index
df_test.drop(index, axis=0, inplace=True)
df_test.reset_index(inplace=True, drop=True)
# print(df_test.duplicated().sum())
# 重复数据是text一样但是label不一样的数据。
# print(df_test['text'].duplicated().sum())
# print(df_test[df_test['text'].duplicated() == True])
# 查看例子
# print(df_test[df_test['text'] == df_test.iloc[2046]['text']])
# print(df_test[df_test['text'] == df_test.iloc[3132]['text']])
# 去掉text一样但是label不一样的数据
index = df_test[df_test['text'].duplicated() == True].index
df_test.drop(index, axis=0, inplace=True)
df_test.reset_index(inplace=True, drop=True)
# 检查
# print(df_test['text'].duplicated().sum()) # 0
# print(df_test)
# 检查形状与编号
print("======test-clean======")
print(df_test.tail())
print(df_test.shape)
df_test.to_csv('./data/archive/test_clean.csv', index=None)
# todo: 清洗验证集
# 观察数据是否平衡
# print(df_val.label.value_counts())
# print(df_val.label.value_counts() / df_val.shape[0] * 100)
# plt.figure(figsize=(8, 4))
# sns.countplot(x='label', data=df_val)
# plt.show()
# 丢掉异常数据
df_val.drop(df_val[(df_val.label == '4') |
(df_val.label == '-') |
(df_val.label == '·')].index, inplace=True, axis=0)
df_val.reset_index(inplace=True, drop=True)
# print(df_val.label.value_counts())
# sns.countplot(x='label', data=df_val)
# plt.show()
# 观察是否有空行
# print(df_val.isnull().sum())
# 删除空行数据
df_val.dropna(axis=0, how='any', inplace=True)
df_val.reset_index(inplace=True, drop=True)
# print(df_val.isnull().sum())
# 查看重复数据
# print(df_val.duplicated().sum())
# print(df_val[df_val.duplicated()==True])
# 删除重复数据
index = df_val[df_val.duplicated() == True].index
df_val.drop(index, axis=0, inplace=True)
df_val.reset_index(inplace=True, drop=True)
# print(df_val.duplicated().sum())
# 重复数据是text一样但是label不一样的数据。
print(df_val['text'].duplicated().sum())
# print(df_val[df_val['text'].duplicated() == True])
# 查看例子
# print(df_val[df_val['text'] == df_val.iloc[1817]['text']])
# print(df_val[df_val['text'] == df_val.iloc[2029]['text']])
# 去掉text一样但是label不一样的数据
index = df_val[df_val['text'].duplicated() == True].index
df_val.drop(index, axis=0, inplace=True)
df_val.reset_index(inplace=True, drop=True)
# 检查
print(df_val['text'].duplicated().sum()) # 0
# print(df_val)
# 检查形状与编号
print("======val-clean======")
print(df_val.tail())
print(df_val.shape)
df_val.to_csv('./data/archive/val_clean.csv', index=None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160

