
- 1KSS-ICP: 基于形状分析技术的点云配准方法_kss-icp代码复现
- 2【ChatGLM】本地版ChatGPT ?6G显存即可轻松使用 !ChatGLM-6B 清华开源模型本地部署教程_chatgml
- 3Spring-Cloud-Gateway之代码注入漏洞及解决_spring cloud gateway未授权访问漏洞
- 4SFT实战微调Gemma_微调gemma 7b
- 524、【数组】旋转矩阵(C++版)_旋转矩阵c++
- 6第十四届蓝桥杯全国软件和信息技术专业人才大赛(Web 应用开发)_isbn 转换与生成 蓝桥杯
- 7[C++] opencv - HoughCircles(霍夫圆查找)函数介绍和使用场景_opencv houghcircles
- 8Python吴恩达深度学习作业22 -- Emoji表情情感分类器_深度学习emoji分类csdn
- 9深度学习之全面了解网络架构
- 10JavaSE(十二):注解_java书里面12章实验的注解
【吴恩达】prompt engineering(原则 迭代 文本概括 推断、订餐机器人)
赞
踩
简介 Introduction
- 基础的LLM训练的模型,问法国的首都什么,可能会将答案预测为“法国最大的城市是什么,法国的人口是多少”
- 许多 LLMs 的研究和实践的动力正在指令调整的 LLMs 上。指令调整的 LLMs 已经被训练来遵循指令。因此,如果你问它,“法国的首都是什么?”,它更有可能输出“法国的首都是巴黎”。指令调整的 LLMs 的训练通常是从已经训练好的基本 LLMs 开始,该模型已经在大量文本数据上进行了训练。然后,使用输入是指令、输出是其应该返回的结果的数据集来对其进行微调,要求它遵循这些指令。然后通常使用一种称为 RLHF(reinforcement learning from human feedback,人类反馈强化学习)的技术进行进一步改进,使系统更能够有帮助地遵循指令。
一、Prompt 的构建原则 Guidelines
1. 清晰、具体的指令
策略一:使用分隔符清晰地表示输入的不同部分,分隔符可以是:```,“”,<>,<tag>,<\tag>等
你可以使用任何明显的标点符号将特定的文本部分与提示的其余部分分开。这可以是任何可以使模型明确知道这是一个单独部分的标记。使用分隔符是一种可以避免提示注入的有用技术。提示注入是指如果用户将某些输入添加到提示中,则可能会向模型提供与你想要执行的操作相冲突的指令,从而使其遵循冲突的指令而不是执行您想要的操作。即,输入里面可能包含其他指令,会覆盖掉你的指令。对此,使用分隔符是一个不错的策略。
以下是一个例子,我们给出一段话并要求 GPT 进行总结,在该示例中我们使用 ```来作为分隔符
text = f"""
你应该提供尽可能清晰、具体的指示,以表达你希望模型执行的任务。\
这将引导模型朝向所需的输出,并降低收到无关或不正确响应的可能性。\
不要将写清晰的提示与写简短的提示混淆。\
在许多情况下,更长的提示可以为模型提供更多的清晰度和上下文信息,从而导致更详细和相关的输出。
"""
# 需要总结的文本内容
prompt = f"""
把用三个反引号括起来的文本总结成一句话。
```{text}```
"""
# 指令内容,使用 ```来分隔指令和待总结的内容
response = get_completion(prompt)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
策略二:要求一个结构化的输出,可以是 Json、HTML 等格式
第二个策略是要求生成一个结构化的输出,这可以使模型的输出更容易被我们解析,例如,你可以在 Python 中将其读入字典或列表中。。
在以下示例中,我们要求 GPT 生成三本书的标题、作者和类别,并要求 GPT 以 Json 的格式返回给我们,为便于解析,我们指定了 Json 的键。
prompt = f"""
请生成包括书名、作者和类别的三本虚构书籍清单,\
并以 JSON 格式提供,其中包含以下键:book_id、title、author、genre。
"""
response = get_completion(prompt)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
策略三:要求模型检查是否满足条件
如果任务做出的假设不一定满足,我们可以告诉模型先检查这些假设,如果不满足,指示并停止执行。你还可以考虑潜在的边缘情况以及模型应该如何处理它们,以避免意外的错误或结果。
在如下示例中,我们将分别给模型两段文本,分别是制作茶的步骤以及一段没有明确步骤的文本。我们将要求模型判断其是否包含一系列指令,如果包含则按照给定格式重新编写指令,不包含则回答未提供步骤。
# 有步骤的文本 text_1 = f""" 泡一杯茶很容易。首先,需要把水烧开。\ 在等待期间,拿一个杯子并把茶包放进去。\ 一旦水足够热,就把它倒在茶包上。\ 等待一会儿,让茶叶浸泡。几分钟后,取出茶包。\ 如果你愿意,可以加一些糖或牛奶调味。\ 就这样,你可以享受一杯美味的茶了。 """ prompt = f""" 您将获得由三个引号括起来的文本。\ 如果它包含一系列的指令,则需要按照以下格式重新编写这些指令: 第一步 - ... 第二步 - … … 第N步 - … 如果文本中不包含一系列的指令,则直接写“未提供步骤”。" \"\"\"{text_1}\"\"\" """ response = get_completion(prompt) print("Text 1 的总结:") print(response) Text 1 的总结: 第一步 - 把水烧开。 第二步 - 拿一个杯子并把茶包放进去。 第三步 - 把烧开的水倒在茶包上。 第四步 - 等待几分钟,让茶叶浸泡。 第五步 - 取出茶包。 第六步 - 如果你愿意,可以加一些糖或牛奶调味。 第七步 - 就这样,你可以享受一杯美味的茶了。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
策略四:提供少量示例
即在要求模型执行实际任务之前,提供给它少量成功执行任务的示例。
例如,在以下的示例中,我们告诉模型其任务是以一致的风格回答问题,并先给它一个孩子和一个祖父之间的对话的例子。孩子说,“教我耐心”,祖父用这些隐喻回答。因此,由于我们已经告诉模型要以一致的语气回答,现在我们说“教我韧性”,由于模型已经有了这个少样本示例,它将以类似的语气回答下一个任务。
prompt = f"""
你的任务是以一致的风格回答问题。
<孩子>: 教我耐心。
<祖父母>: 挖出最深峡谷的河流源于一处不起眼的泉眼;最宏伟的交响乐从单一的音符开始;最复杂的挂毯以一根孤独的线开始编织。
<孩子>: 教我韧性。
"""
response = get_completion(prompt)
print(response)
# 如下
<祖父母>: 韧性就像是一棵树,它需要经历风吹雨打、寒冬酷暑,才能成长得更加坚强。在生活中,我们也需要经历各种挫折和困难,才能锻炼出韧性。记住,不要轻易放弃,坚持下去,你会发现自己变得更加坚强。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2. 给模型时间思考
- 策略一:指定完成任务所需的步骤
text = f""" 在一个迷人的村庄里,兄妹杰克和吉尔出发去一个山顶井里打水。\ 他们一边唱着欢乐的歌,一边往上爬,\ 然而不幸降临——杰克绊了一块石头,从山上滚了下来,吉尔紧随其后。\ 虽然略有些摔伤,但他们还是回到了温馨的家中。\ 尽管出了这样的意外,他们的冒险精神依然没有减弱,继续充满愉悦地探索。 """ # example 1 prompt_1 = f""" 执行以下操作: 1-用一句话概括下面用三个反引号括起来的文本。 2-将摘要翻译成法语。 3-在法语摘要中列出每个人名。 4-输出一个 JSON 对象,其中包含以下键:French_summary,num_names。 请用换行符分隔您的答案。 Text: ```{text}``` """ response = get_completion(prompt_1) print("prompt 1:") print(response) prompt 1: 1-兄妹在山顶井里打水时发生意外,但仍然保持冒险精神。 2-Dans un charmant village, les frère et sœur Jack et Jill partent chercher de l'eau dans un puits au sommet de la montagne. Malheureusement, Jack trébuche sur une pierre et tombe de la montagne, suivi de près par Jill. Bien qu'ils soient légèrement blessés, ils retournent chez eux chaleureusement. Malgré cet accident, leur esprit d'aventure ne diminue pas et ils continuent à explorer joyeusement. 3-Jack, Jill 4-{ "French_summary": "Dans un charmant village, les frère et sœur Jack et Jill partent chercher de l'eau dans un puits au sommet de la montagne. Malheureusement, Jack trébuche sur une pierre et tombe de la montagne, suivi de près par Jill. Bien qu'ils soient légèrement blessés, ils retournent chez eux chaleureusement. Malgré cet accident, leur esprit d'aventure ne diminue pas et ils continuent à explorer joyeusement.", "num_names": 2 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
减少模型的幻觉问题:
- 编写合理的prompt
- 先要求模型找到文本中的任何相关引用,然后要求它使用这些引用来回答问题,这种追溯源文档的方法通常对减少幻觉非常有帮助。
二、如何迭代优化 Prompt Itrative
1. 从产品说明说生成产品描述
# 示例:产品说明书 fact_sheet_chair = """ 概述 美丽的中世纪风格办公家具系列的一部分,包括文件柜、办公桌、书柜、会议桌等。 多种外壳颜色和底座涂层可选。 可选塑料前后靠背装饰(SWC-100)或10种面料和6种皮革的全面装饰(SWC-110)。 底座涂层选项为:不锈钢、哑光黑色、光泽白色或铬。 椅子可带或不带扶手。 适用于家庭或商业场所。 符合合同使用资格。 结构 五个轮子的塑料涂层铝底座。 气动椅子调节,方便升降。 尺寸 宽度53厘米|20.87英寸 深度51厘米|20.08英寸 高度80厘米|31.50英寸 座椅高度44厘米|17.32英寸 座椅深度41厘米|16.14英寸 选项 软地板或硬地板滚轮选项。 两种座椅泡沫密度可选:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。 无扶手或8个位置PU扶手。 材料 外壳底座滑动件 改性尼龙PA6/PA66涂层的铸铝。 外壳厚度:10毫米。 座椅 HD36泡沫 原产国 意大利 """ # 提示:基于说明书创建营销描述 prompt = f""" 你的任务是帮助营销团队基于技术说明书创建一个产品的营销描述。 根据```标记的技术说明书中提供的信息,编写一个产品描述。 技术说明: ```{fact_sheet_chair}``` """ response = get_completion(prompt) print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 可以限制生成的文本字数
- 可以添加“侧重产品的材料描述”等描述重点语言
2. 生成表格描述
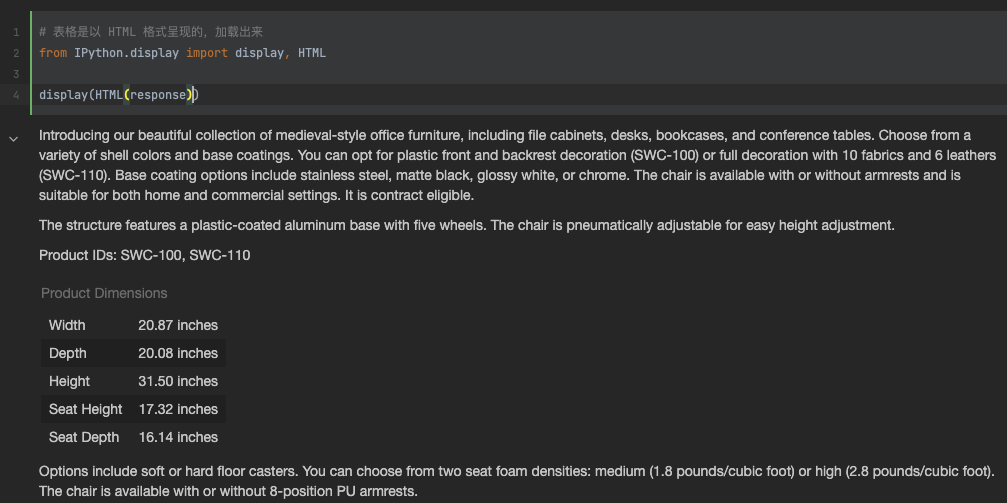
# 要求它抽取信息并组织成表格,并指定表格的列、表名和格式 prompt = f""" 您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。 根据```标记的技术说明书中提供的信息,编写一个产品描述。 该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。 在描述末尾,包括技术规格中每个7个字符的产品ID。 在描述之后,包括一个表格,提供产品的尺寸。表格应该有两列。第一列包括尺寸的名称。第二列只包括英寸的测量值。 给表格命名为“产品尺寸”。 将所有内容格式化为可用于网站的HTML格式。将描述放在<div>元素中。 技术规格:```{fact_sheet_chair}``` """ response = get_completion(prompt) print(response) # 表格是以 HTML 格式呈现的,加载出来 from IPython.display import display, HTML display(HTML(response))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
可以看到在notebook的显示结果:
三、文本总结 Summarizing
# 1. 文本摘要 prompt = f""" 你的任务是从电子商务网站上生成一个产品评论的简短摘要。 请对三个反引号之间的评论文本进行概括,最多30个词汇。 评论: ```{prod_review_zh}``` """ response = get_completion(prompt) print(response) # 2. 关键信息提取 prompt = f""" 你的任务是从电子商务网站上的产品评论中提取相关信息。 请从以下三个反引号之间的评论文本中提取产品运输相关的信息,最多30个词汇。 评论: ```{prod_review_zh}``` """ response = get_completion(prompt) print(response) # 3. 多条评论文本处理 reviews = [review_1, review_2, review_3, review_4] for i in range(len(reviews)): prompt = f""" Your task is to generate a short summary of a product \ review from an ecommerce site. Summarize the review below, delimited by triple \ backticks in at most 20 words. Review: ```{reviews[i]}``` """ response = get_completion(prompt) print(i, response, "\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
四、文本推断 Inferring
# 一个prompt包含多个操作要求 prompt = f""" 从评论文本中识别以下项目: - 情绪(正面或负面) - 审稿人是否表达了愤怒?(是或否) - 评论者购买的物品 - 制造该物品的公司 评论用三个反引号分隔。将您的响应格式化为 JSON 对象,以 “Sentiment”、“Anger”、“Item” 和 “Brand” 作为键。 如果信息不存在,请使用 “未知” 作为值。 让你的回应尽可能简短。 将 Anger 值格式化为布尔值。 评论文本: ```{lamp_review_zh}``` """ response = get_completion(prompt) print(response) # response { "Sentiment": "正面", "Anger": false, "Item": "卧室灯", "Brand": "Lumina" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
也可以做文本的多主题提取:
# 中文
prompt = f"""
确定以下给定文本中讨论的五个主题。
每个主题用1-2个单词概括。
输出时用逗号分割每个主题。
给定文本: ```{story_zh}```
"""
response = get_completion(prompt)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
为特定主题做提醒
# 中文
prompt = f"""
判断主题列表中的每一项是否是给定文本中的一个话题,
以列表的形式给出答案,每个主题用 0 或 1。
主题列表:a, b, c, d, e
给定文本: ```{story_zh}```
"""
response = get_completion(prompt)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五、文本转换 Transforming
1. 通用翻译器
def get_completion(prompt, model="gpt-3.5-turbo", temperature=0): messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=temperature, # 值越低则输出文本随机性越低 ) return response.choices[0].message["content"] user_messages = [ "La performance du système est plus lente que d'habitude.", # System performance is slower than normal "Mi monitor tiene píxeles que no se iluminan.", # My monitor has pixels that are not lighting "Il mio mouse non funziona", # My mouse is not working "Mój klawisz Ctrl jest zepsuty", # My keyboard has a broken control key "我的屏幕在闪烁" # My screen is flashing ] for issue in user_messages: time.sleep(20) prompt = f"告诉我以下文本是什么语种,直接输出语种,如法语,无需输出标点符号: ```{issue}```" lang = get_completion(prompt) print(f"原始消息 ({lang}): {issue}\n") prompt = f""" 将以下消息分别翻译成英文和中文,并写成 中文翻译:xxx 英文翻译:yyy 的格式: ```{issue}``` """ response = get_completion(prompt) print(response, "\n=========================================")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2. 文本翻译+拼写纠错+风格调整+格式转换
def get_completion(prompt, model="gpt-3.5-turbo", temperature=0): ''' prompt: 对应的提示 model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4 temperature: 温度系数 ''' messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=temperature, # 模型输出的温度系数,控制输出的随机程度 ) # 调用 OpenAI 的 ChatCompletion 接口 return response.choices[0].message["content"] text = f""" Got this for my daughter for her birthday cuz she keeps taking \ mine from my room. Yes, adults also like pandas too. She takes \ it everywhere with her, and it's super soft and cute. One of the \ ears is a bit lower than the other, and I don't think that was \ designed to be asymmetrical. It's a bit small for what I paid for it \ though. I think there might be other options that are bigger for \ the same price. It arrived a day earlier than expected, so I got \ to play with it myself before I gave it to my daughter. """ from IPython.display import display, Markdown prompt = f""" 针对以下三个反引号之间的英文评论文本, 首先进行拼写及语法纠错, 然后将其转化成中文, 再将其转化成优质淘宝评论的风格,从各种角度出发,分别说明产品的优点与缺点,并进行总结。 润色一下描述,使评论更具有吸引力。 输出结果格式为: 【优点】xxx 【缺点】xxx 【总结】xxx 注意,只需填写xxx部分,并分段输出。 将结果输出成Markdown格式。 ```{text}``` """ response = get_completion(prompt) display(Markdown(response))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

六、文本扩展 Expanding
这里的sentiment情感先对文本推理得到。
prompt = f"""
你是一位客户服务的AI助手。
你的任务是给一位重要客户发送邮件回复。
根据客户通过“```”分隔的评价,生成回复以感谢客户的评价。提醒模型使用评价中的具体细节
用简明而专业的语气写信。
作为“AI客户代理”签署电子邮件。
客户评论:
```{review}```
评论情感:{sentiment}
"""
response = get_completion(prompt)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
七、聊天机器人 Chatbot
1. 设置系统消息
import openai openai.api_key = "" def get_completion(prompt, model="gpt-3.5-turbo"): messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0, # 控制模型输出的随机程度 ) return response.choices[0].message["content"] # message: 消息列表 def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0): response = openai.ChatCompletion.create( model=model, messages=messages, temperature=temperature, # 控制模型输出的随机程度 ) # print(str(response.choices[0].message)) return response.choices[0].message["content"] # 设置系统消息, 在不让请求本身成为对话的一部分的情况下,引导助手并指导其回应。 messages = [ {'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'}, {'role':'user', 'content':'tell me a joke'}, {'role':'assistant', 'content':'Why did the chicken cross the road'}, {'role':'user', 'content':'I don\'t know'} ] response = get_completion_from_messages(messages, temperature=1) print(response) ''' response = get_completion_from_messages(messages, temperature=1) print(response) ''' # example2 messages = [ {'role':'system', 'content':'You are friendly chatbot.'}, {'role':'user', 'content':'Hi, my name is Isa'} ] response = get_completion_from_messages(messages, temperature=1) print(response) # Hello Isa! How can I assist you today? # example3: 不知道名字 messages = [ {'role':'system', 'content':'你是个友好的聊天机器人。'}, {'role':'user', 'content':'好,你能提醒我,我的名字是什么吗?'} ] response = get_completion_from_messages(messages, temperature=1) print(response) # 抱歉,我不知道您的名字,因为我们是虚拟的聊天机器人和现实生活中的人类在不同的世界中。 # example4: 知道名字,提供了上下文 # 中文 messages = [ {'role':'system', 'content':'你是个友好的聊天机器人。'}, {'role':'user', 'content':'Hi, 我是Isa'}, {'role':'assistant', 'content': "Hi Isa! 很高兴认识你。今天有什么可以帮到你的吗?"}, {'role':'user', 'content':'是的,你可以提醒我, 我的名字是什么?'} ] response = get_completion_from_messages(messages, temperature=1) print(response) # 当然可以!你的名字是Isa。记得了吗?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
可以看到上面example2中gpt会用友好机器人口吻呼叫你名字问好。
2. 订餐机器人
- 任务:订餐机器人,自动收集用户信息,接受比萨店的订单
- 通过下面定义的
collect_messages函数收集用户信息,加入到一个上下文列表中,每次调用模型时使用该上下文(菜单信息也在上下文中)。模型的响应也会被添加到上下文中,所以模型消息和用户消息都被添加到上下文中,因此上下文逐渐变长。 !pip install panel,panel这个库方便GUI可视化界面展示
def collect_messages(_): prompt = inp.value_input inp.value = '' context.append({'role':'user', 'content':f"{prompt}"}) response = get_completion_from_messages(context) context.append({'role':'assistant', 'content':f"{response}"}) panels.append( pn.Row('User:', pn.pane.Markdown(prompt, width=600))) panels.append( pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'}))) return pn.Column(*panels) import panel as pn # GUI pn.extension() panels = [] # collect display context = [ {'role':'system', 'content':""" You are OrderBot, an automated service to collect orders for a pizza restaurant. \ You first greet the customer, then collects the order, \ and then asks if it's a pickup or delivery. \ You wait to collect the entire order, then summarize it and check for a final \ time if the customer wants to add anything else. \ If it's a delivery, you ask for an address. \ Finally you collect the payment.\ Make sure to clarify all options, extras and sizes to uniquely \ identify the item from the menu.\ You respond in a short, very conversational friendly style. \ The menu includes \ pepperoni pizza 12.95, 10.00, 7.00 \ cheese pizza 10.95, 9.25, 6.50 \ eggplant pizza 11.95, 9.75, 6.75 \ fries 4.50, 3.50 \ greek salad 7.25 \ Toppings: \ extra cheese 2.00, \ mushrooms 1.50 \ sausage 3.00 \ canadian bacon 3.50 \ AI sauce 1.50 \ peppers 1.00 \ Drinks: \ coke 3.00, 2.00, 1.00 \ sprite 3.00, 2.00, 1.00 \ bottled water 5.00 \ """} ] # accumulate messages inp = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…') button_conversation = pn.widgets.Button(name="Chat!") interactive_conversation = pn.bind(collect_messages, button_conversation) dashboard = pn.Column( inp, pn.Row(button_conversation), pn.panel(interactive_conversation, loading_indicator=True, height=300), )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
3. 中文版本
# 中文 import panel as pn # GUI pn.extension() panels = [] # collect display context = [{'role':'system', 'content':""" 你是订餐机器人,为披萨餐厅自动收集订单信息。 你要首先问候顾客。然后等待用户回复收集订单信息。收集完信息需确认顾客是否还需要添加其他内容。 最后需要询问是否自取或外送,如果是外送,你要询问地址。 最后告诉顾客订单总金额,并送上祝福。 请确保明确所有选项、附加项和尺寸,以便从菜单中识别出该项唯一的内容。 你的回应应该以简短、非常随意和友好的风格呈现。 菜单包括: 菜品: 意式辣香肠披萨(大、中、小) 12.95、10.00、7.00 芝士披萨(大、中、小) 10.95、9.25、6.50 茄子披萨(大、中、小) 11.95、9.75、6.75 薯条(大、小) 4.50、3.50 希腊沙拉 7.25 配料: 奶酪 2.00 蘑菇 1.50 香肠 3.00 加拿大熏肉 3.50 AI酱 1.50 辣椒 1.00 饮料: 可乐(大、中、小) 3.00、2.00、1.00 雪碧(大、中、小) 3.00、2.00、1.00 瓶装水 5.00 """} ] # accumulate messages inp = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…') button_conversation = pn.widgets.Button(name="Chat!") interactive_conversation = pn.bind(collect_messages, button_conversation) dashboard = pn.Column( inp, pn.Row(button_conversation), pn.panel(interactive_conversation, loading_indicator=True, height=300), ) dashboard # 在jupyter notebook中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
交互界面如图:

4. 追加一个系统消息
- 追加系统消息:订单的json摘要,列出每个项目的价格,字段应包括1)披萨,包括尺寸,2)配料列表,3)饮料列表,4)辅菜列表,包括尺寸,最后是总价格。这里也可以在这里使用用户消息,不一定是系统消息。
- 使用了一个较低的temperature,因为对于这些类型的任务,我们希望输出相对可预测。
messages = context.copy() messages.append( {'role':'system', 'content':'创建上一个食品订单的 json 摘要。\ 逐项列出每件商品的价格,字段应该是 1) 披萨,包括大小 2) 配料列表 3) 饮料列表,包括大小 4) 配菜列表包括大小 5) 总价'}, ) response = get_completion_from_messages(messages, temperature=0) print(response) # 如下: 当然!以下是您的订单摘要: 1) 披萨: - 意式辣香肠披萨(中) - 10.00 - 芝士披萨(小) - 6.50 2) 配料: - 奶酪 - 2.00 - 蘑菇 - 1.50 3) 饮料: - 可乐(中) - 2.00 4) 配菜: - 薯条(小) - 3.50 总价:25.50 请问还有其他需要添加的吗?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

