- 1一位工作了10年的C++程序员总结出这些忠告_c++十年经验
- 2Struts2学习笔记(十二) 类型转换(Type Conversion)(下)
- 3(赠源码)Java+springboot+MYSQL社区外卖系统小程序70047- 计算机毕业设计项目选题推荐
- 4docker容器获取宿主机ip地址_宿主机的ip地址
- 5【Python】如何写一个拼写纠错器_import re from collections import counter def word
- 6基于共享矩阵的线性秘密共享方案原理、构造与代码实现_def generate_secret_shares(secret_vector, num_shar
- 7探索Manticore Search:开源全文搜索引擎的强大功能
- 8adb常用命令整理_adb 启动服务
- 9[论文笔记] [2003] A Neural Probabilistic Language Model_bengio论文神经网络语言模型
- 10NLP【自然语言处理】技术路线
【自然语言处理 | Language Models】Language Models 常见算法介绍合集(三)_mbart
赞
踩
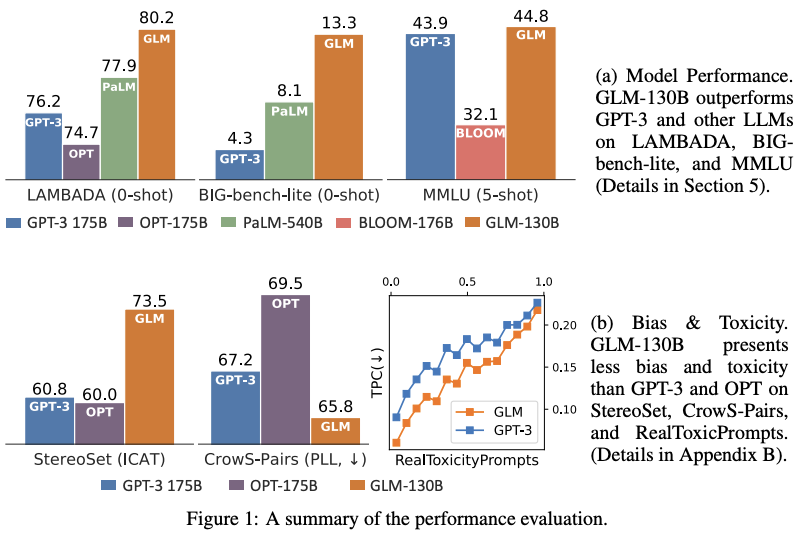
一、BLOOM
BLOOM 是一个仅解码器的 Transformer 语言模型,在 ROOTS 语料库上进行训练,该数据集包含 46 种自然语言和 13 种编程语言(总共 59 种)的数百个源。
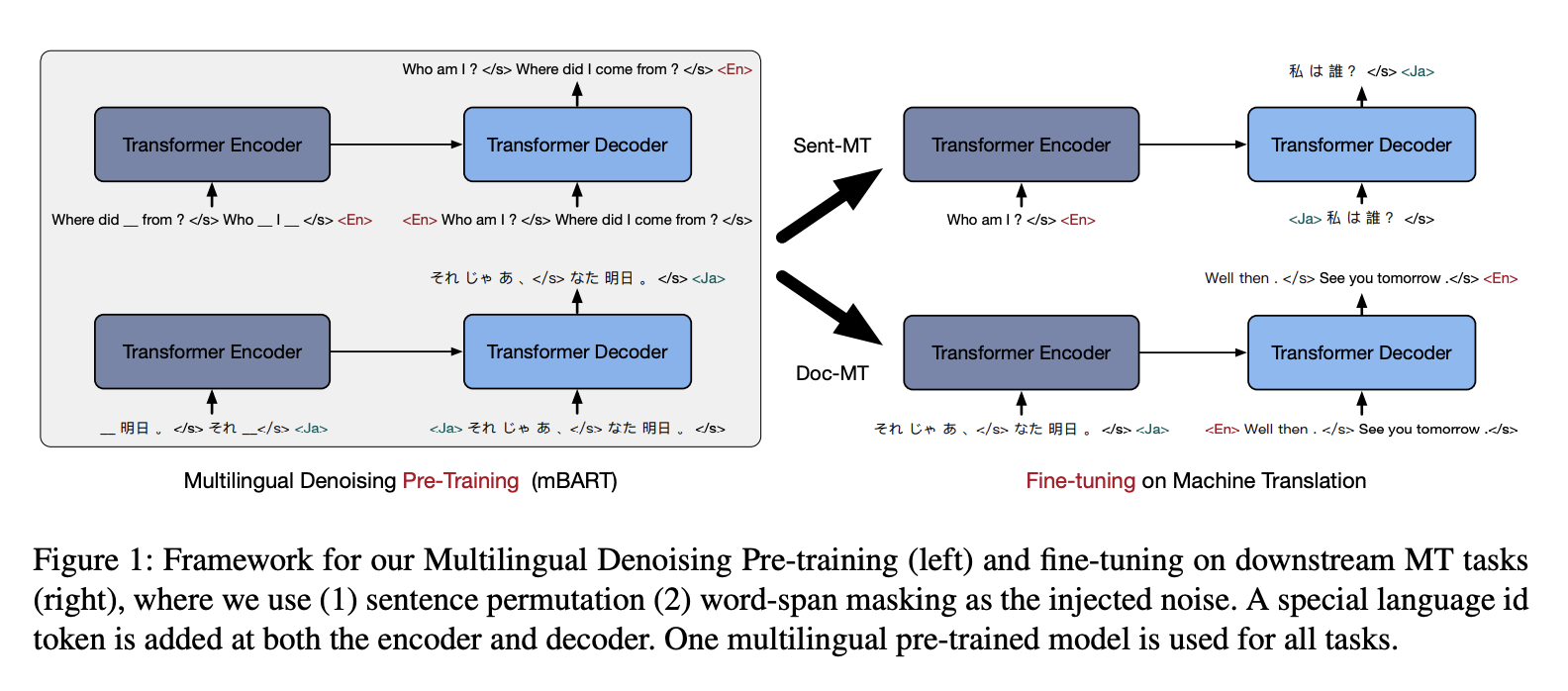
二、mBART
mBART 是一种序列到序列去噪自动编码器,使用 BART 目标在多种语言的大规模单语语料库上进行了预训练。 通过屏蔽短语和排列句子对输入文本进行噪声处理,并学习单个 Transformer 模型来恢复文本。 与其他机器翻译预训练方法不同,mBART 预训练完整的自回归 Seq2Seq 模型。 mBART 针对所有语言进行一次训练,提供一组参数,可以在监督和无监督设置中针对任何语言对进行微调,而无需任何特定于任务或特定于语言的修改或初始化方案。
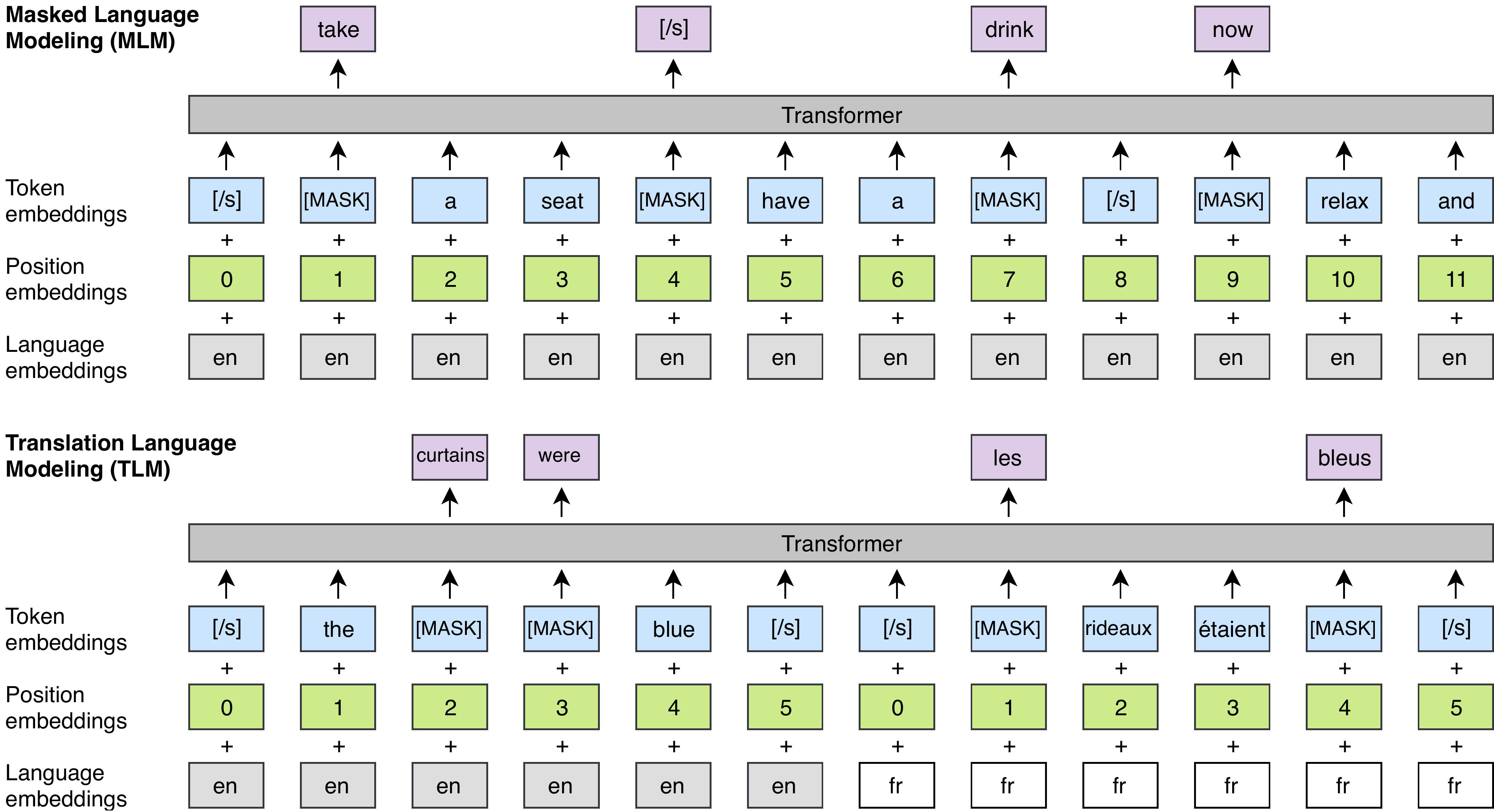
三、XLM
XLM 是一种基于 Transformer 的架构,使用以下三种语言建模目标之一进行预训练:
因果语言建模 - 对给定句子中前面的单词的单词的概率进行建模。
Masked Language Modeling - BERT 的屏蔽语言建模目标。
翻译语言建模 - 用于改进跨语言预训练的(新)翻译语言建模目标。
作者发现 CLM 和 MLM 方法都提供了强大的跨语言特征,可用于预训练模型。
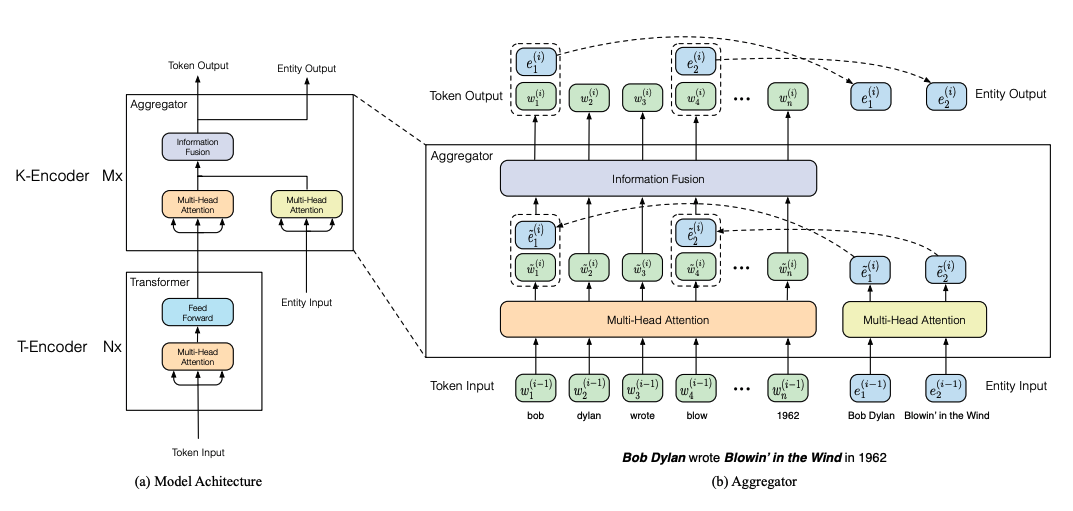
四、ERNIE
ERNIE 是一个基于 Transformer 的模型,由两个堆叠模块组成:1)文本编码器和 2)知识编码器,负责将额外的面向标记的知识信息集成到文本信息中。 该层由堆叠聚合器组成,旨在对令牌和实体进行编码以及融合它们的异构特征。 为了通过知识整合这一层增强表示,ERNIE 采用了一种特殊的预训练任务 - 它涉及随机屏蔽令牌实体对齐并训练模型以基于对齐令牌预测所有相应实体(又名去噪实体自动编码器) 。
五、CodeBERT
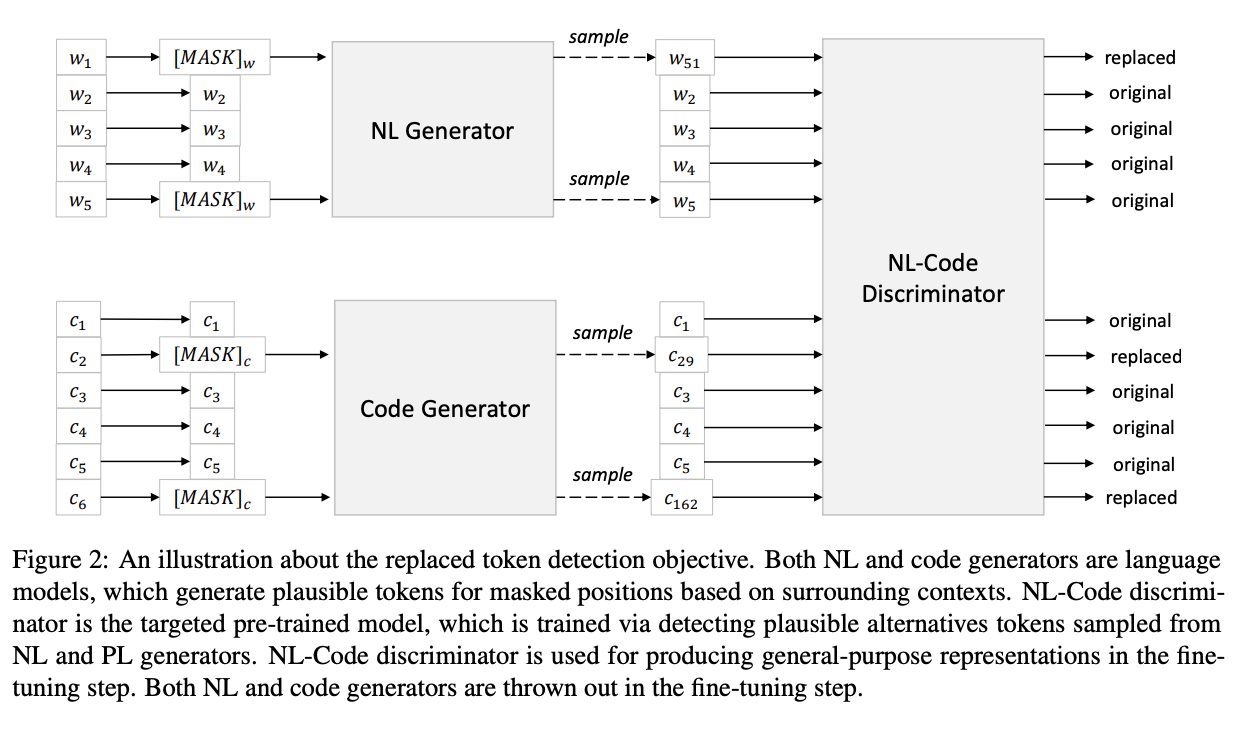
CodeBERT 是编程语言 (PL) 和自然语言 (NL) 的双模预训练模型。 CodeBERT 学习支持下游 NL-PL 应用程序的通用表示,例如自然语言代码搜索、代码文档生成等。CodeBERT 采用基于 Transformer 的神经架构开发,并使用混合目标函数进行训练,该目标函数结合了预训练 替换令牌检测的训练任务,即检测从生成器中采样的合理替代方案。 这使得能够利用 NL-PL 对的双峰数据和单峰数据,前者为模型训练提供输入标记,而后者有助于学习更好的生成器。
六、Flan-T5
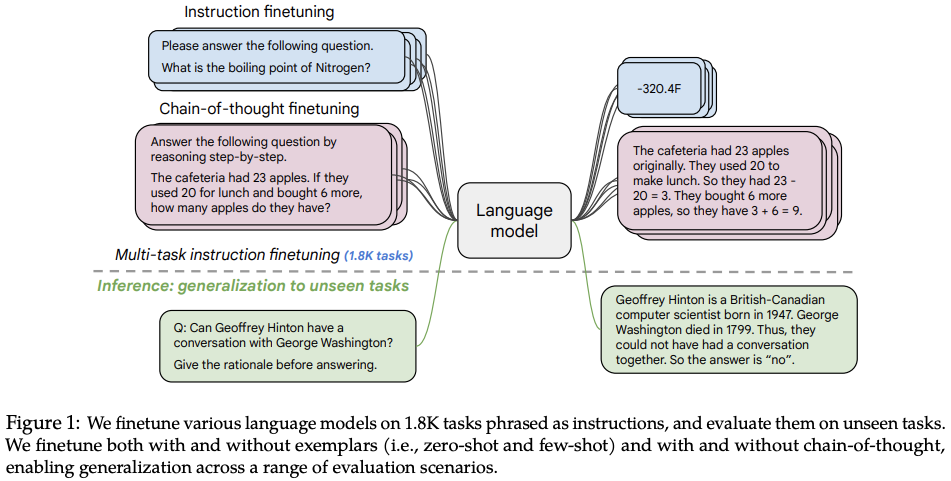
Flan-T5 是 T5(文本到文本传输转换器语言模型)的指令微调版本。
七、Universal Language Model Fine-tuning
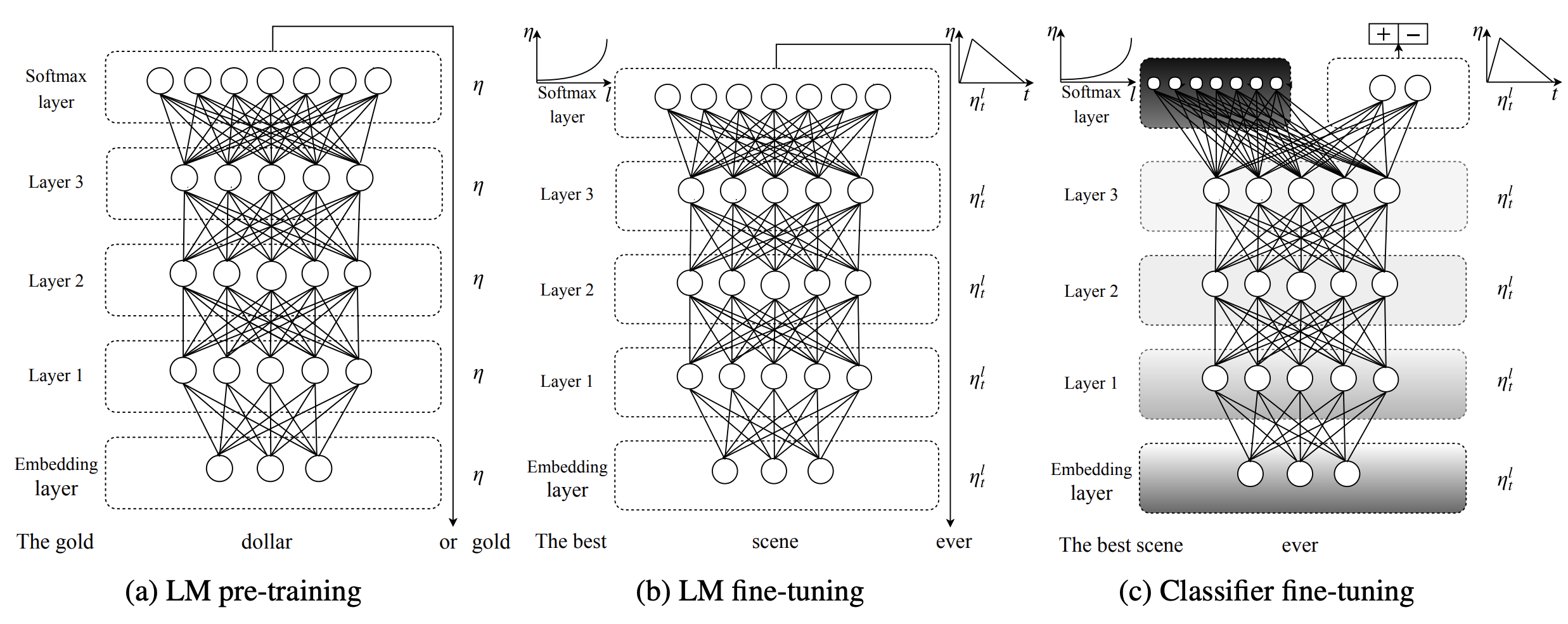
通用语言模型微调(ULMFiT)是一种可应用于 NLP 任务的架构和迁移学习方法。 它涉及一个 3 层 AWD-LSTM 架构来表示。 训练包括三个步骤:1)基于维基百科的文本进行通用语言模型预训练,2)在目标任务上微调语言模型,3)在目标任务上微调分类器。
由于不同层捕获不同类型的信息,因此使用判别性微调对它们进行不同程度的微调。 使用倾斜三角学习率(STLR)进行训练,这是一种学习率调度策略,首先线性增加学习率,然后线性衰减。
在 ULMFiT 中使用逐步解冻来实现目标分类器的微调。 ULMFiT 不是一次性微调所有层(这会带来灾难性遗忘的风险),而是从最后一层(即最接近输出的层)开始逐渐解冻模型,因为这包含最少的一般知识。 首先,最后一层被解冻,所有解冻层都针对一个时期进行微调。 然后将下一组冻结层解冻并进行微调并重复,直到所有层都经过微调直至最后一次迭代收敛。
八、PEGASUS
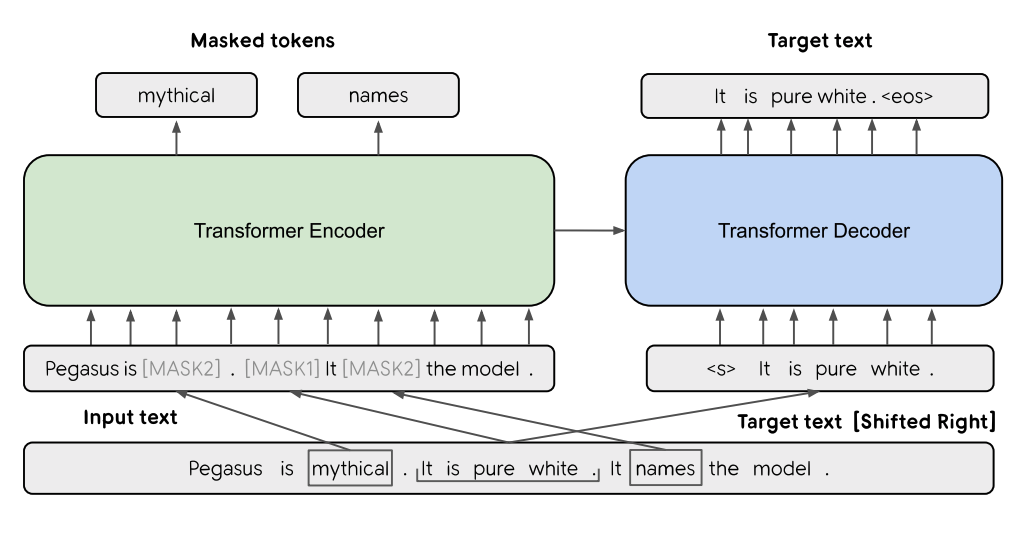
PEGASUS 提出了一种基于变压器的抽象概括模型。 它使用一种特殊的自监督预训练目标,称为间隙句子生成(GSG),旨在在与摘要相关的下游任务上表现良好。 正如论文中所报道的,“GSG 和 MLM 都同时应用于这个例子作为预训练目标。最初有三个句子。其中一个句子用 [MASK1] 屏蔽并用作目标生成文本(GSG)。另外两个句子 句子保留在输入中,但一些标记被 [MASK2] 随机屏蔽。”
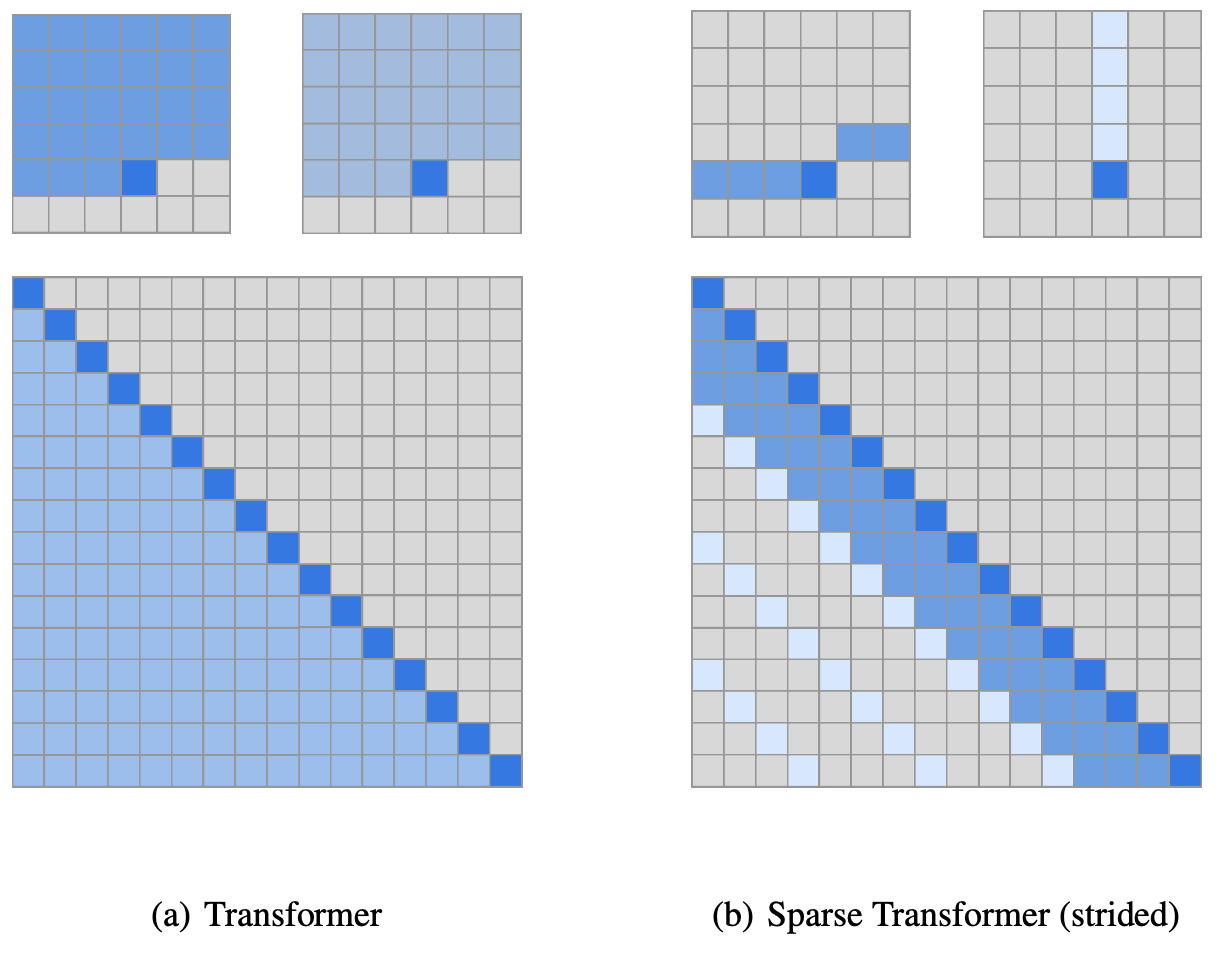
九、Sparse Transformer
稀疏变换器是一种基于变换器的架构,它利用注意力矩阵的稀疏分解来减少时间/内存。 Transformer 架构的其他变化包括:(a) 重构的残差块和权重初始化,(b) 一组稀疏注意力内核,可有效计算注意力矩阵的子集,© 在向后传递期间重新计算注意力权重以减少注意力 内存使用情况
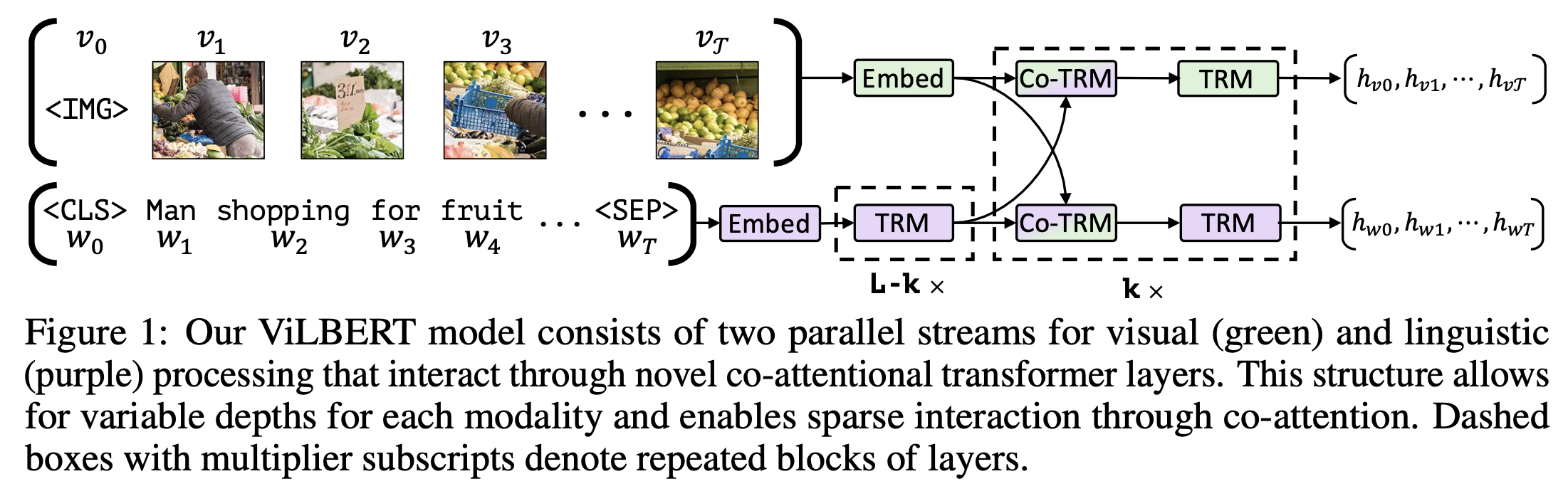
十、Vision-and-Language BERT
视觉和语言 BERT (ViLBERT) 是一种基于 BERT 的模型,用于学习图像内容和自然语言的任务无关的联合表示。 ViLBERT 将流行的 BERT 架构扩展为多模态双流模型,在单独的流中处理视觉和文本输入,并通过共同注意转换器层进行交互。
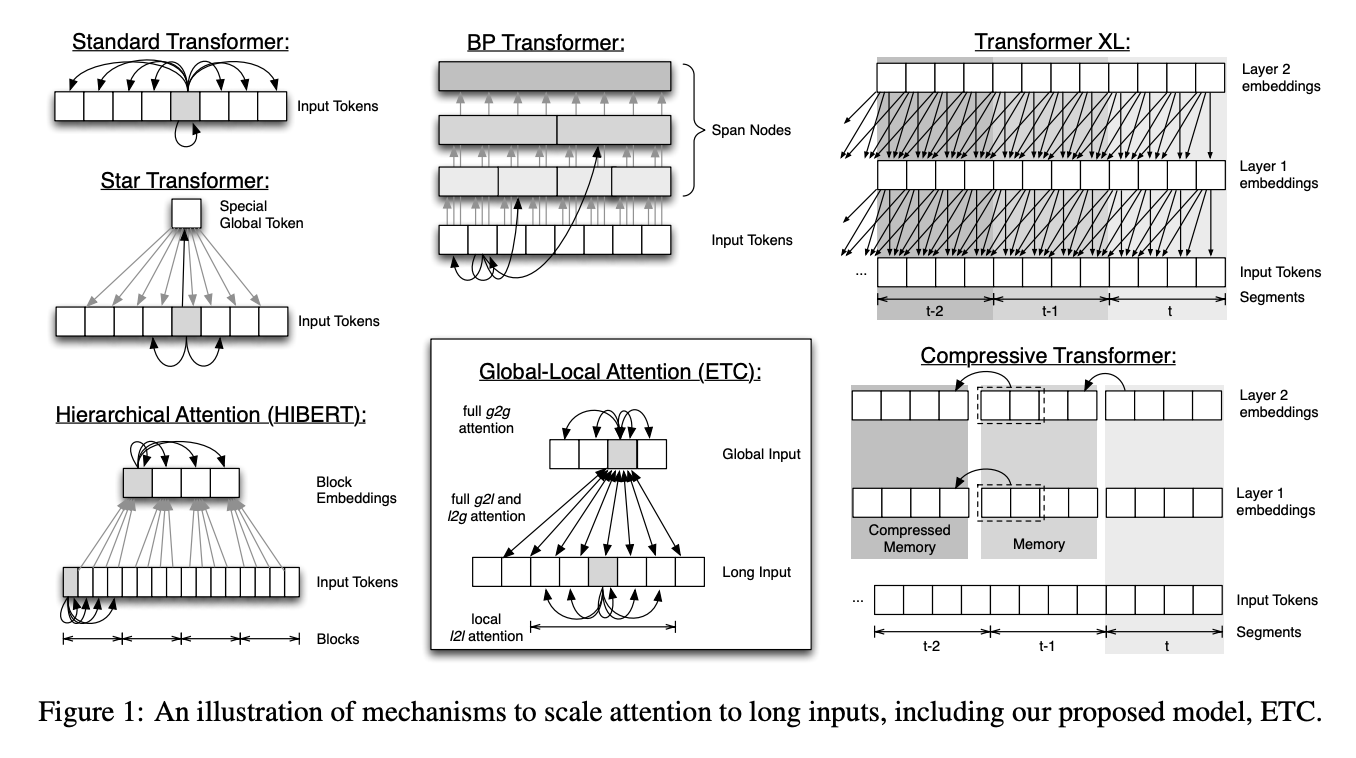
十一、Extended Transformer Construction(ETC)
Extended Transformer Construction(ETC)是 Transformer 架构的扩展,采用了新的注意力机制,主要通过两种方式扩展了原来的架构:(1)它允许将输入长度从 512 扩展到数千; (2)它可以摄取结构化输入而不仅仅是线性序列。 使 ETC 实现这些目标的关键思想是一种新的全局局部注意力机制,再加上相对位置编码。 ETC 还允许从现有的 BERT 模型中提升权重,从而在训练时节省计算资源。
十二、GLM
GLM 是一种双语(英语和中文)预训练的基于 Transformer 的语言模型,遵循仅解码器自回归语言建模的传统架构。 它利用自回归空白填充作为其训练目标。