
- 1经典应用丨光伏行业扫码追溯新标杆,海康机器人AI智能读码器!
- 2【Android 11】使用Android Studio调试系统应用之Settings移植(四):编译SettingsLib模块、导入子模块、解决编译错误_编译android setting
- 3Vite是如何用Esbuild 来提升性能的?_vite esbuild
- 4用C#实现实时监测文件夹,把word/excel/ppt自动转为pdf_c# 监控excel文件程序
- 5deepfacelive实时换脸教程(2024最新版)_real-time face swap for pc streaming or video call
- 6Java开发技术知识图谱_java服务端研发知识图谱 pdf
- 7免费的AI文案生成器有哪些?AI文案生成器排行榜
- 8操作系统实践之路——六、内存(3.如何实现内存页的分配与释放?)
- 9计算机网络——数据链路层(差错控制)
- 10基于SSM的红色文化展示小程序系统设计与实现【包调试】_基于ssm框架的“小红书”设计与实现
Sora技术原理简要分析_sora模型架构
赞
踩

目录
Sora 技术以其创新的“扩散+Transformer”混合模型为核心,能够生成高质量的视频内容。以下是对Sora技术路线的主要特点和技术原理的概述。
1.Sora 技术基本构架
Sora的核心架构,简单来说就是:一个能高效灵活的处理不同视频分辨率尺寸的Diffusion Transformer预训练模型。
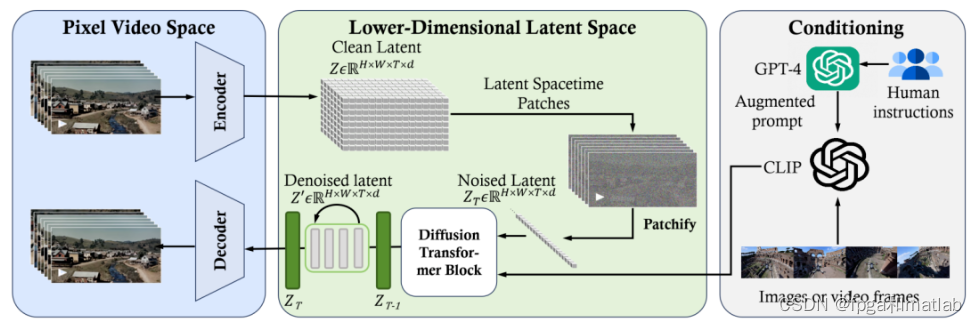
这个框图是用大语言模型中常用的Transformer网络结构,替换了原来的UNET网络结构。整体的生成逻辑,仍然保留了扩散模型从随机噪点图像数据逐步去噪得到清新图像的过程,只不过,这里的图像不是单幅图像,而是连续的多幅图像帧。
1.1 扩散模型
Sora中的扩散模型是一种先进的深度学习技术,主要用于生成高质量的图像和视频内容。扩散模型(Diffusion Model)的核心概念源自统计物理学,它利用一系列随机过程逐步将数据转换成随机噪声,然后通过逆过程学习如何从噪声中恢复原始数据。在Sora这个特定应用场景中,扩散模型被设计得能够理解并响应文本提示,从而生成与文本描述相符的视觉内容。
扩散模型主要包括两个主要阶段:
前向过程(Forward Process): 在前向过程中,模型会将真实的图像数据一步步地添加噪声,直到数据接近标准正态分布或其他简单分布。这一过程可以被视为数据退化的过程,每一步都会增加一定程度的随机性,最终完全掩盖掉原始信息。
反向过程(Reverse Process): 反向过程则是前向过程的逆操作,通过训练一个深度神经网络来估计每个步骤还原数据所需的条件概率分布。该网络学习如何逐步减少噪声,从随机分布中重建出高质量的图像或视频帧。为了实现这一点,模型通常需要解决一个连续的变分推断问题,或者通过训练来拟合对应各个噪声级别的分布函数。
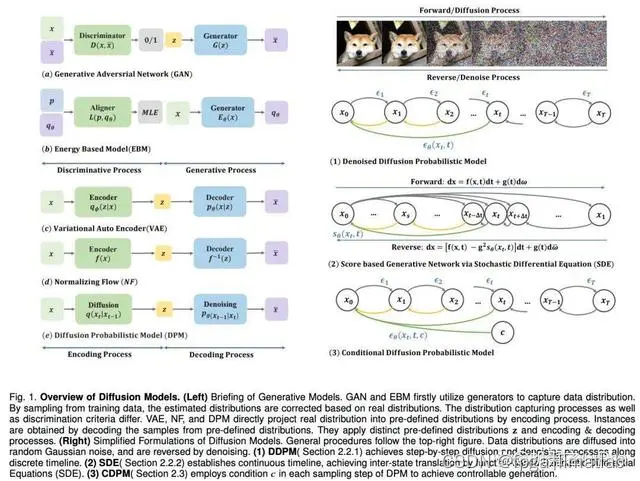
不过,扩散模型的采样过程伴随反复推理求值。这一过程面临着不稳定性、高维计算需求和复杂的似然性优化等挑战。研究者为此提出了多种方案,如改进 ODE/SDE 解算器和采取模型蒸馏策略来加速采样,以及新的前向过程来提高稳定性和降低维度。
1.2Transformer架构
Sora 中使用的Transformer架构是一种广泛应用于自然语言处理以及其他领域(如计算机视觉和语音识别)的强大神经网络结构。Transformer由Google在2017年的开创性论文《Attention is All You Need》中首次提出,其关键特征在于彻底摒弃了循环神经网络(RNN)和卷积神经网络(CNN)在序列数据处理中的传统角色,转而采用自注意力机制(Self-Attention)为核心构建模块。该模型融入了 Transformer 结构,这是深度学习领域中用于处理序列数据的强大工具,尤其是在自然语言处理(NLP)中广泛应用。在Sora中,Transformer架构被用来理解和处理视频数据的时间序列特性,使得模型能够理解和生成连贯的视频内容。
在Sora模型中,Transformer架构用于处理文本到视频的生成任务,具体而言:
自注意力机制: 自注意力机制使得模型能够对输入序列中的每个位置进行全局计算,允许模型考虑整个序列上下文信息,而不是仅依赖于局部信息或过去的隐藏状态。这对于理解和生成复杂、长距离依赖的视频序列至关重要。
编码器-解码器架构: Sora可能采用了经典的Transformer编码器-解码器结构,其中编码器负责将输入的文本序列转化为高层次的语义表征,而解码器则依据这些表征生成相应的视频帧序列。每一层Transformer都包含了多头注意力子层(Multi-Head Attention)以及前馈神经网络(Feed-Forward Networks,FFNs)。
Diffusion Transformer(DiT): 特别针对Sora模型,提到的Diffusion Transformer(DiT)是一种定制化的Transformer变体,它在视频生成任务中扮演了重要角色。DiT结合了扩散模型的方法,并将其融入Transformer架构中,以便在逐帧生成视频的过程中更精细地控制信息传播和重构过程。
高效扩展能力: Transformer由于其并行计算的优势,在大规模数据上训练时能够展现出卓越的扩展性能,这对于训练像Sora这样的大型模型,要求模型能够处理大量文本和视频数据以学习两者间的复杂映射关系极为重要。
动态适应性: Transformer架构允许Sora模型根据给定的文本提示灵活地生成各种不同的视频内容,包括改变对象、背景、动作以及创建不同风格(如逼真、卡通或抽象)的视频。
2.Sora工作原理
Sora技术能够生成高分辨率、高保真度的视频,这意味着生成的视频不仅画面清晰,而且细节丰富,与真实世界场景相似度极高。
2.1实施步骤
步骤一:使用 DALLE 3( CLIP )把文本和图像对 <text,image> 建立关联性;
在训练阶段,将视频按1帧或者隔n帧用DALLE3(CLIP)按照一定的规范形成对应的描述文本,然后输入模型训练。
在推理阶段,首先将用户输入的prompt用GPT4按照一定的规范把它详细化,然后输入模型得到结果。

步骤二:视频数据切分为 Patches 通过 VAE 编码器压缩成低维空间表示

步骤三:基于 Difusion Transformer 从图像语义生成,完成从文本语义到图像语义进行映射;

2.2训练过程
训练流程包括以下步骤:
1.收集视频数据与标注信息。
2.训练图片字幕模型。
3.利用 GPT-4 丰富视频描述。
4.切分视频为 Patches。
5.应用视频压缩模型。
6.在潜在空间中处理视频数据。
7.应用扩散模型与 Transformer 进行训练。
8.最终恢复高清视频。
其基本流程图如下所示:

3.Sora技术效果展示
提供一段文字:依靠GPT语义解释能力、丰富的联想和丰富度,产生针对视频内容详细的描述。如文本是:“散步在夜晚东京街道上”,GPT发挥想象力,联想出一堆词和关联“高楼”、“繁华夜景”等等。
Diffusion:作为一个画师,根据关键词特征值对应的可能性概率,在海量视频库到处翻,看看抄哪一个碎块比较像,看哪个像,就猜对应的下一笔要落在什么地方。
通过Diffusion和Transformer共同联想,死记硬背,从巨大视频库里生拉硬拽,配合GAN(对抗式生成网络技术),把这些一张张碎块拼成图,再拼接成一个序列,每秒播放几十张,视频就出来了。
一些Open。AI官方发布的应用案例:
1.Prompt: A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.

Prompt: The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from it’s tires, the sunlight shines on the SUV as it speeds along the dirt road, casting a warm glow over the scene. The dirt road curves gently into the distance, with no other cars or vehicles in sight. The trees on either side of the road are redwoods, with patches of greenery scattered throughout. The car is seen from the rear following the curve with ease, making it seem as if it is on a rugged drive through the rugged terrain. The dirt road itself is surrounded by steep hills and mountains, with a clear blue sky above with wispy clouds.

Prompt: Five gray wolf pups frolicking and chasing each other around a remote gravel road, surrounded by grass. The pups run and leap, chasing each other, and nipping at each other, playing.

Prompt:Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.

Prompt: Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. The art style is 3D and realistic, with a focus on lighting and texture. The mood of the painting is one of wonder and curiosity, as the monster gazes at the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.

4.Sora应用领域
影视创作: 从电影、动画到广告,Sora可以轻松生成各种类型的视频片段。创作者可以借助Sora构建丰富多彩的场景、塑造生动的角色,为影视作品增添更多创意元素。
社交媒体推广: Sora为用户提供了创造有趣、引人注目的视频内容的能力,有助于提升在社交媒体平台上的曝光度。这对于个人博客、品牌或企业来说,是一种有效的营销和品牌传播手段。
游戏开发: 游戏开发者可以利用Sora制作游戏中的角色动画和场景效果,为游戏增添更高的交互性和趣味性。Sora为游戏创意提供了无限的可能性,提升了游戏体验的质量。
教育和培训: Sora的功能可以应用于教学视频、培训材料的制作。通过Sora生成的视频,教育者能够创造引人入胜的场景,提高学生的学习兴趣和理解能力。
虚拟现实(VR)和增强现实(AR): Sora的视频生成技术可用于制作VR和AR应用的内容,为用户提供更为沉浸式的体验。这在培训、虚拟旅游和产品展示等方面具有广泛的应用前景。
广告和营销: 营销团队可以借助Sora制作创意十足的广告内容,从而吸引更多目标受众,提高品牌的知名度和吸引力。
医疗和健康: Sora的视频生成技术可以应用于医疗培训视频、健康教育材料的制作,提高医学信息传递的效果,同时为患者提供更清晰的理解。
艺术和文化创作: 艺术家和文化创作者可以通过Sora创造出富有创意和表现力的视频艺术作品,推动数字艺术的发展。
5.Sora优缺点分析
5.1和其他技术的对比
Sora有别于上述AI视频模型的优势在于,既能准确呈现细节,又能理解物体在物理世界中的存在,并生成具有丰富情感的角色,甚至该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
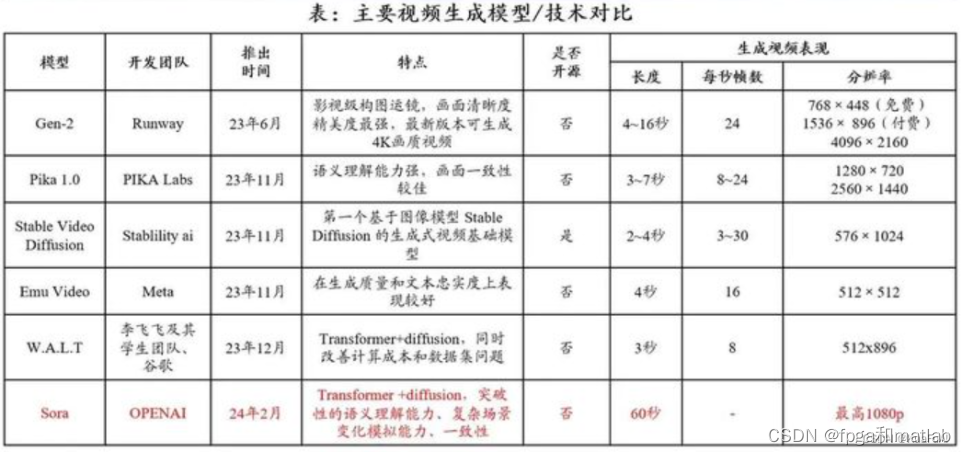
5.2优缺点
优势
1).准确性和多样性:Sora可将简短的文本描述转化成长达1分钟的高清视频。它可以准确地解释用户提供的文本输入,并生成具有各种场景和人物的高质量视频剪辑。它涵盖了广泛的主题,从人物和动物到郁郁葱葱的风景、城市场景、花园,甚至是水下的纽约市,可根据用户的要求提供多样化的内容。
2).强大的语言理解:OpenAI利用Dall·E模型的recaptioning(重述要点)技术,生成视觉训练数据的描述性字幕,不仅能提高文本的准确性,还能提升视频的整体质量。
3).以图/视频生成视频:Sora除了可以将文本转化为视频,还能接受其他类型的输入提示,如已经存在的图像或视频。这使Sora能够执行广泛的图像和视频编辑任务,如创建完美的循环视频、将静态图像转化为动画、向前或向后扩展视频等。
4).视频扩展功能:由于可接受多样化的输入提示,用户可以根据图像创建视频或补充现有视频。作为基于Transformer的扩散模型,Sora还能沿时间线向前或向后扩展视频。
5).优异的设备适配性:Sora具备出色的采样能力,能够为各种设备生成与其原始纵横比完美匹配的内容。从宽屏的 1920x1080p 到 竖 屏 的1080x1920,两者之间的任何视频尺寸都能轻松应对.
6).场景和物体的一致性和连续性:Sora可以生成带有动态视角变化的视频,人物和场景元素在三维空间中的移动会显得更加自然。Sora 能够很好地处理遮挡问题
缺点
1).物理交互的不准确模拟:Sora模型在模拟基本物理交互,如玻璃破碎等方面,不够精确。这可能是因为模型在训练数据中缺乏足够的这类物理事件的示例,或者模型无法充分学习和理解这些复杂物理过程的底层原理。

2).长时视频样本的不连贯性:在生成长时间的视频样本时,Sora可能会产生不连贯的情节或细节,这可能是由于模型难以在长时间跨度内保持上下文的一致性。

3).对象的突然出现:视频中可能会出现对象的无缘无故出现,这表明模型在空间和时间连续性的理解上还有待提高。

Sora技术路线展示了在AI生成视频领域最新的技术创新,通过整合扩散模型和Transformer结构,实现视频内容的高质量自动生成。然而,这种技术仍然面临着诸多技术难题和伦理考量,随着技术的发展和优化,未来将在影视制作、虚拟现实、游戏开发等多个领域有着广阔的应用前景。

