
- 1SpringBoot3.0 集成 Redis2.6_springboot3.0 redis
- 2决胜B端(二)设计篇-从业务诊断到形成方案-调研_决胜b端2
- 3github上如何添加Demo动画_github.io在个人主页添加视频
- 4JAVA安全之Log4j-Jndi注入原理以及利用方式
- 5DataGridView取消默认选中行_datagridview取消选中状态
- 6MySQL的安装与环境变量配置_mysql中如何设置环境变量
- 7学校作业5_3字符串_统计英文文件中的单词数(头哥作业[Python])_统计英文文件中的单词数python头歌
- 8微信小程序picker多列选择器:四级联动
- 9ant design pro v5 - 03 动态菜单 动态路由(配置路由 动态登录路由 登录菜单)_ant design pro 动态菜单
- 10垃圾分类数据集-8w张图片245个类附赠tensorflow代码_垃圾分类数据集(垃圾图片数据集)
大语言模型系列-GPT-3.5(ChatGPT)_gpt3.5
赞
踩
前言
《Training language models to follow instructions with human feedback,2022》
前文提到了GPT-3的缺点,其中最大的问题是:语言模型更大并不能从本质上使它们更好地遵循用户的意图,大型语言模型可能生成不真实、有害或对用户毫无帮助的输出。
GPT-3.5正是基于此问题进行的改进,它通过对人类反馈进行微调,使语言模型与用户在广泛任务中的意图保持一致,专业术语是对齐(Alignment)。
ps:ChatGPT和InstructGPT是一对兄弟模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT-3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。
一、GPT-3.5的创新点
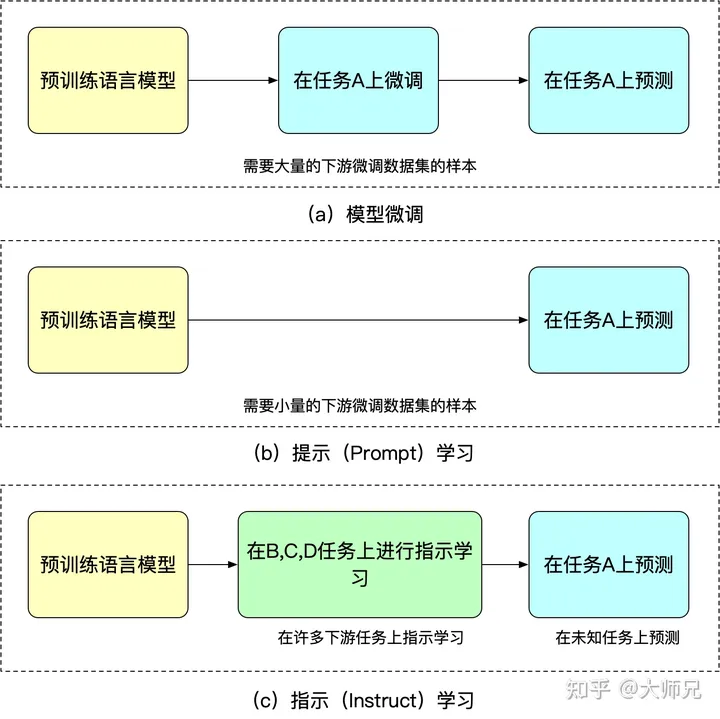
- 指示学习(Instruct Learning)和提示学习(Prompt Learning)
ps:指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。
- finetune需要大量数据集,会更新梯度,比较耗时
- Prompt用于激发语言模型的补全能力,针对某个具体任务的,泛化能力不如指示学习。
- Instruct用于激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。

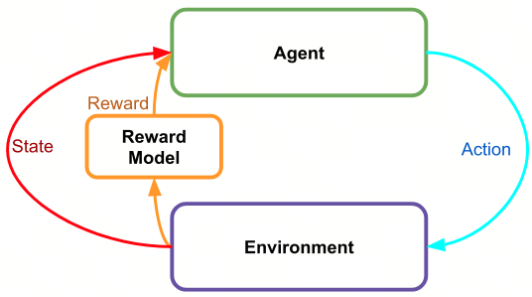
- 使用了基于人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),使结果对齐。
ps:
- 强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模型训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。
- 同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人类反馈的强化学习便应运而生。
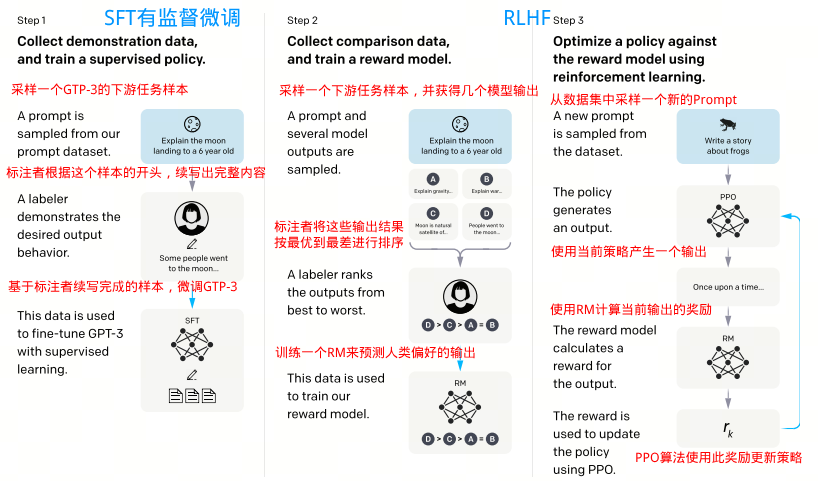
二、GPT-3.5的训练流程
InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。InstructGPT/ChatGPT的训练流程如下所示:
- 收集演示数据并进行监督训练
- 收集对比数据,训练奖励模型
- 使用PPO针对奖励模型优化策略
具体一点可以看如下例子:
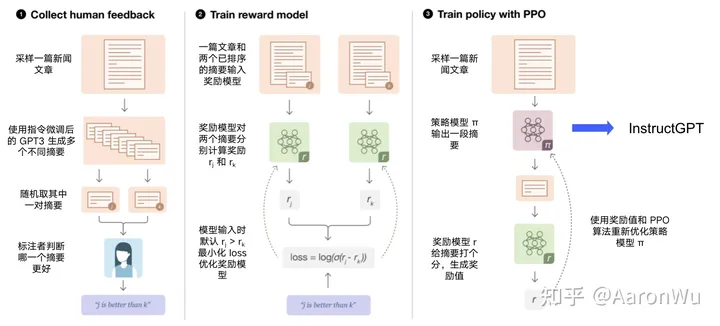
以上三个步骤采用的数据集是不同的
SFT数据集
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注员(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注员的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;
Few-shot任务:labeler给出一个指示,以及该指示的多个查询-响应对;
用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示。
RM数据集
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标,要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。
PPO数据集
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。即有不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
三、ChatGPT的诞生
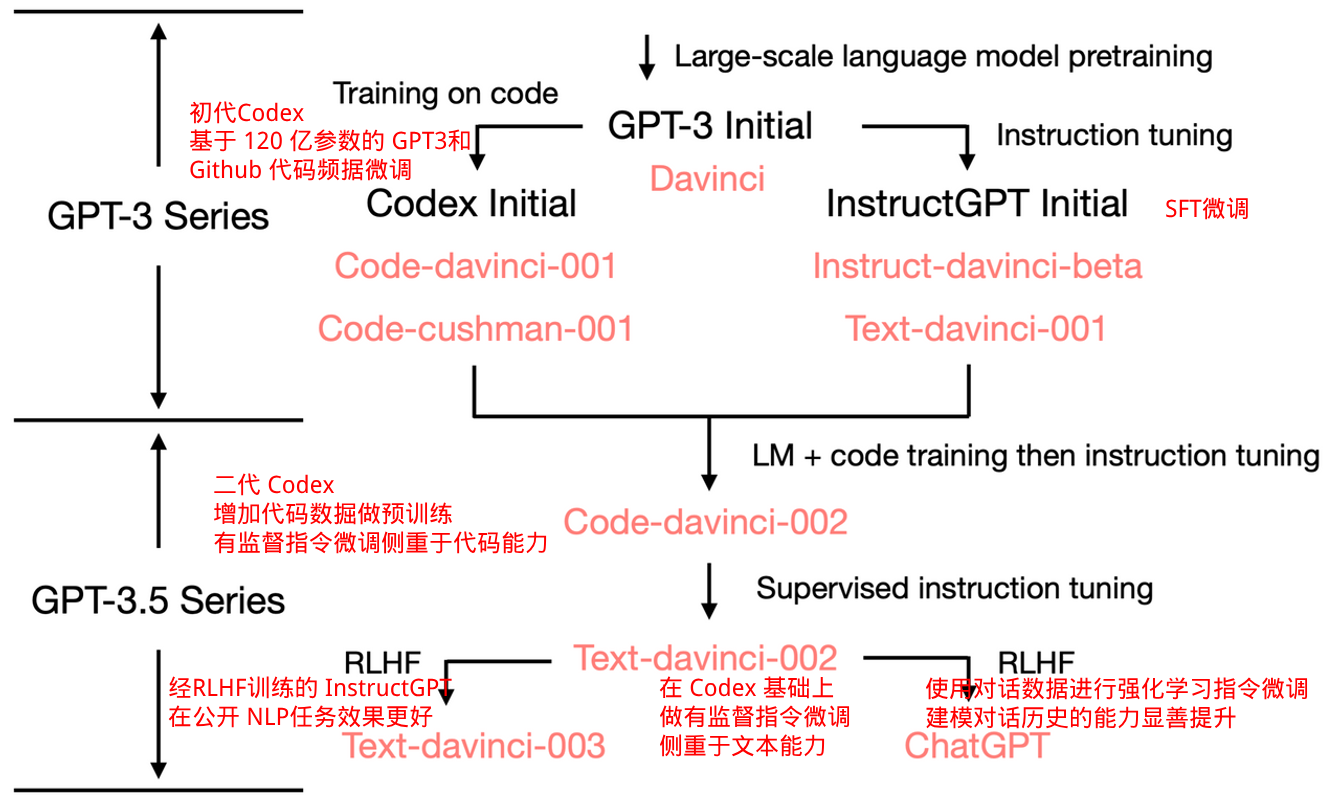
总结
ChatGPT的优缺点如下:
优点:
- 参数更小,真实性更强
- 无害性提升
- 编码能力强
缺点:
- 会降低模型在通用NLP任务上的效果
- 仍可能给出错误结论
- 对指示非常敏感
- 对简单概念的过分解读
- 对有害的指示可能会输出有害的答复

