
- 1基于python的图书管理系统
- 2Flutter学习指南:交互、手势和动画,头条android面试
- 3女神节告白代码_女神节代码html
- 4Bert基础(九)--Bert变体之ALBERT
- 5OpenNLP中关于语言检测的语料训练
- 6MySQL基础语法之判断语句的学习&&如何将检索数据的返回值赋值给变量,以及如何查看变量
- 7聊天机器人教程 pytorch官方文档_数据集使用的是康奈尔大学的电影对话 这里我们将对话已经在预处理部分拆成一个个p
- 8北航计算机考研录取多少人,北航计算机考研近三年报考录取情况
- 9python_sklearn机器学习算法系列之K-Means(硬聚类算法)_python sklearn kmeans
- 10ChatGLM-6B-INT4部署
自然语言处理seq2seq模型实现人工智能对对联(基于TensorFlow框架)_seq2seq-couplet
赞
踩
目录
春节贴春联是中国人庆祝春节(过年)的特有习俗。但我真正对对联有些认识和喜欢,不是从年年贴春联开始的,而是从《唐伯虎点秋香》那段经典的对对子开始的。那工整又有韵律和意境的对子,配上有节奏的配乐读出来着实让人热血沸腾,大呼过瘾。
先来回味一下这段台词吧,你的耳边是否响起了对对子的节奏。。。
十年前,微软亚洲研究院推出了一个对联生成引擎,可以根据用户输入的上联自动生成下联,当时火了一把。那时候觉得这个好神奇啊。
十年后,人工智能的风已经热吹了几年。随着硬件GPU计算能力的提升,和深度学习框架(TensorFlow,PyTorch,MxNet等等)的推出和发展,人工智能(其实就是更深层的机器学习)首先在图像处理领域大放异彩,人脸识别、物体检测等技术应用广泛。然而,在自然语言处理处理方面,深度学习的应用还没有图像处理那么成熟。不过,人工智能作古诗,对对子应用的看起来还不错。
快过年了,贴对联是必不可少的传统风俗。不知道各位小伙伴有没有自己写过对联呢?写对联可不是一件简单的事情,如果不是满腹经纶绝难出口成章啊。最近我就发现了一个对对联的开源项目,绝对有才。
将试用网站分享给各位小伙伴,可以在线感受下AI机智对对联(建议用Google浏览器):https://ai.binwang.me/couplet/
效果图如下:



怎么样,对的还算工整吧,就是在专业领域不具有专业特色。
AI对对联项目,使用seq2seq模型,基于深度学习框架Tensorflow使用Python 3.6开发,作者是王斌一位软件工程师,一位极具才情的程序员。下面咱们就解析seq2seq模型原理机制。
对于一些自然语言处理任务,比如聊天机器人,机器翻译,自动文摘等,传统的方法都是从候选集中选出答案,这对素材的完善程度要求很高,随着最近几年深度学习的兴起,国外学者将深度学习技术应用与自然语言的生成和自然语言的理解的方面的研究,并取得了一些突破性的成果,比如,Sequence-to-sequence (seq2seq) 模型,它是目前自然语言处理技术中非常重要而且非常流行的一个模型,该技术突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型运用于翻译与职能问答这一类序列型任务的先河,并且被证实在各主流语言之间的相互翻译以及语音助手中人机短问快答的应用中有着非常好的表现,下面给大家简要介绍一下关于seq2seq模型的一些细节。
seq2seq模型是在2014年,是由Google Brain团队和Yoshua Bengio 两个团队各自独立的提出来[1] 和 [2],他们发表的文章主要关注的是机器翻译相关的问题。而seq2seq模型,简单来说就是一个翻译模型,把一个语言序列翻译成另一种语言序列,整个处理过程是通过使用深度神经网络( LSTM (长短记忆网络),或者RNN (递归神经网络)前面的文章已经详细的介绍过,这里就不再详细介绍) 将一个序列作为输入影射为另外一个输出序列,如下图所示:
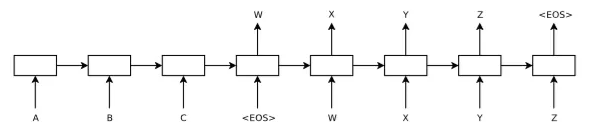
上图已经是在时间维度上进行了展开,对于没有展开的情况下,一般左边使用一个神经网络,接收输入序列"A B C EOS ( EOS=End of Sentence,句末标记)", 在这个过程中每一个时间点接收一个词或者字,并在读取的EOS时终止接受输入,最后输出一个向量作为输入序列的语义表示向量,这一过程也被称为编码(Encoder)过程,而第二个神经网络接收到第一个神经网络产生的输出向量后输出相应的输出语义向量,并且在这个时候每一个时刻输出词的概率都与前一个时刻的输出有关系,模型会将这些序列一次映射为"W X Y Z EOS",这一过程也被称为解码 (Decoder)过程,这样就实现了句子的翻译过程。整个过程的结构就像下图一样:

下面以文章[1]的内容为主介绍一下该过程中相关的一些数学公式和结果。
在Yoshua Bengio文章中使用的是RNN网络作为基本的神经网络对输入序列和输出序列进行学习。这里给一个基本的介绍,如下图所示:

其中h是隐藏层,y是输出层,输入是一个时间序列x = (x1, x2, ..., xT), 对于每一个时间t,RNN中隐藏层的h的更新由下面的表达式决定:
![]()
f是一个非线性的激活函数,f可以是tanh或者sigmoid函数。
RNN网络可以通过学习整个输入序列的概率分布来对下一个字或者词进行预测,在这种情况下,对于时间t时,其概率分布为P(xt| xt-1, ...., x1), 之后再根据其分布去推测新的字或者词的概率,比如说对于最后使用softmax函数对输出进行变换之后,得到如下表达式:
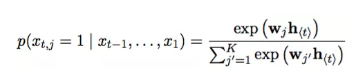
对j遍历词袋中可能的值,这一就就可以得到每个字或者词在下一个时间出现的是概率值。
在文章中整个模型图为如下图所示:
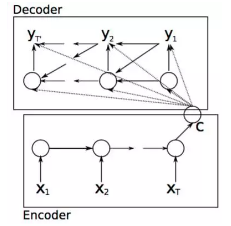
整个模型和第一部分介绍的类似,整个模型分为解码和编码的过程,编码的过程结束后悔输出一个语义向量c,之后整个解码过程根据c进行相应的学习输出。
对于整个编码的过程就是上面第二部分介绍的RNN网络学习的的过程,最后输出一个向量c。而对于解码过程,对应的是另外一个RNN网络,其隐藏层状态在t时刻的更新根据如下方程进行更新:
![]()
除了新加了c变量以外,其它和RNN原本的函数关系是一样的。类似的条件概率公式可以写为:
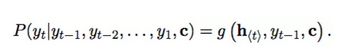
对于整个输入编码和解码的过程中,文行中使用梯度优化算法以及最大似然条件概率为损失函数去进行模型的训练和优化:
![]()
其中sita为相应模型中的参数,(xn, yn)是相应的输入和输出的序列。
总的来说,上面介绍的模型是最简单的模型,对于解码和编码的过程使用的是一层的RNN,Google 团队[1]使用的起初也是一层的LSTM模型,后面有一篇文章提出的对Encoder和Decoder部分使用多层的LSTM,其原理和1层的RNN是一样的。如下图所示:

其实对于这种encoder和decoder的模型,有一个问题是:起始的时间序列被编码转化成语义向量c,之后再被解码,那么一开始的信息经过长时间的从左往右传播已经丢失了很多,而最后编码的信息也是在最后解码,因此文章[3]中提出,在对输入的序列编码时,使用倒序输入,也就是原始的输入顺序为"A B C"的,那么新的方式编码的输入方式为 "C B A" ,这样A编码成c之后,就会马上进行解码,这样丢失的信息就没有之前那么多,经过这样的处理之后,取得了很大的提升,而且这样处理使得模型能够很好的处理长句子。
上面的方法虽然有一定的改善,但是对于输入词C来讲,信息丢失的依旧很厉害,因此未来解决这一缺点,Bahdanu等人提出在Encoder和Decoder的基础上提出了注意力机制。在上面的模型结构中,每次预测都是从语义向量c中进行信息提取,在含有注意力机制的模型结构中,除了对最后的语义向量进行提取信息,还会对每一时刻的ht输出的结果进行信息的提取,这样Encoder过程中的隐藏状态都被利用上了。如下图所示:

其中ct和at为注意力层,对每一个隐藏层的状态都提取相应的信息,之后再将整体的信息给编码层。
上面基本上已经介绍完了seq2seq模型,接下来看看该模型可以在那些领域应用。首先作为为机器翻译问题为出发点提出来的seq2seq模型,机器翻译的准确率因为该模型的提出而有了较大的提升。
作为seq2seq模型研发团队,Google Brain团队在2014年的文章[5]的应用案例中对LSTm的隐藏结点做了主成分分析,如下图所示,从图中可以看出,模型中的语境向量很明显包涵了输入序列的语言意义,后沟将不同次序所产的的不同意思的语句划分开,这对于提升机器翻译的准确率很有帮助。

其次seq2seq模型因为突破了传统的固定大小输入问题框架,因而除了翻译场景,还被用于智能对话与问答的实现以及微博的自动回复,2015年华为团队,通过seq2seq为基础设计的模型实现了计算机对微博的自动回复,并通过模型间的对比得到了一系列有意思的结果。
了解原理后,小伙伴们可以在GitHub下载、编译运行并训练该项目:https://github.com/wb14123/seq2seq-couplet
这个作者提供了70万条对联的数据,有了这个数据就可以训练我们自己的模型了。
做深度学习训练是最考验硬件的,必须上GPU,不然训练可能要一两个月才能完成。通常深度学习的系统环境是这样的:
CPU:现在常规的已经足够,计算主要靠GPU;
内存:至少16GB,越多越好;
GPU: NVIDIA,至少是gtx-1060吧。目前最具性价比的是gtx-1080 Ti
OS: Ubuntu 16.04 (普遍使用的版本)
Python: Python 3.6 版 (2.x的版本用的很少了)
深度学习框架: TensorFlow、PyTorch和MxNet最流行
训练的过程很漫长...最终训练了一周。搞人工智能的活儿没点儿像样的硬件,还真耗不起青春啊。训练期间,有足够的时间去完成其它的功能。
使用GitHub中的Server.py程序即可实现模型训练。
- from flask import Flask, jsonify, request
- from flask_cors import CORS, cross_origin
- from model import Model
- from gevent.wsgi import WSGIServer
- import logging
- app = Flask(__name__)
- CORS(app)
- vocab_file = '/data/dl-data/couplet/vocabs'
- model_dir = '/data/dl-data/models/tf-lib/output_couplet_prod'
- m = Model(
- None, None, None, None, vocab_file,
- num_units=1024, layers=4, dropout=0.2,
- batch_size=32, learning_rate=0.0001,
- output_dir=model_dir,
- restore_model=True, init_train=False, init_infer=True)
- @app.route('/chat/couplet/<in_str>')
- def chat_couplet(in_str):
- if len(in_str) == 0 or len(in_str) > 50:
- output = u'您的输入太长了'
- else:
- output = m.infer(' '.join(in_str))
- output = ''.join(output.split(' '))
- print('上联:%s;下联:%s' % (in_str, output))
- return jsonify({'output': output})
- http_server = WSGIServer(('', 5000), app)
- http_server.serve_forever()

给小伙伴们分享一个拓展项目,用Python进行诗歌接龙:https://blog.csdn.net/m0_38106923/article/details/87873666
参考内容:
[1] Cho et al., 2014, learning phase representations using RNN Encoder-decoder for statistical machine translation.
[2] Sutskever et al, 2014, Sequence to sequence learning with neural networks.
[3] Manning et al. 2015, Effective approaches to attention-based neural machine translation.
[4] Bahdanau et al. 2014, Neural machine translation by jointly learning to align and translate

