
- 1垂直同步_显示器自适应垂直同步即将大一统:NVIDIA有条件支持FreeSync
- 2微信小程序的常见的面试题(总结)_小程序面试题
- 3VMware中Kali Linux添加源,更新和安装vmtools_kali 2021.3安装vmtools
- 4使用ElasticsearchRepository和ElasticsearchRestTemplate操作Elasticsearch,Spring Boot整合Elasticsearch_idea连接elasticsearch elasticsearchresttemplate
- 5创维E900V22C、E900V22D_S905L3-L3B免拆卡刷固件_e900v22d刷机
- 6GO开发环境配置_go环境配置
- 7react实现HTML调摄像头拍照功能_react 拍照
- 8php GET 和 POST 方法的区别_php get和post 区别
- 9通俗讲解Pytorch梯度的相关问题:计算图、no_grad、zero_grad、retain_grad、detach和backward;Variable、Parameter和torch.tensor_pytorch retain_grad
- 10cortex a7 a53_西昊人体工学椅A7开箱测评
Bert基础(九)--Bert变体之ALBERT
赞
踩
在接下来的几篇,我们将了解BERT的不同变体,包括ALBERT、RoBERTa、ELECTRA和SpanBERT。我们将首先了解ALBERT。ALBERT的英文全称为A Lite version of BERT,意思是BERT模型的精简版。ALBERT模型对BERT的架构做了一些改变,以尽量缩短训练时间。本章将详细介绍ALBERT的工作原理及其与BERT的不同之处。
接着,我们将了解RoBERTa模型,它是Robustly Optimized BERT Pretraining Approach(稳健优化的BERT预训练方法)的简写。RoBERTa是目前最流行的BERT变体之一,它被应用于许多先进的系统。RoBERTa的工作原理与BERT类似,但在预训练步骤上有一些变化。我们将详细探讨RoBERTa的工作原理及其与BERT的区别。
然后,我们将学习ELECTRA模型,它的英文全称为Efficiently Learning an Encoder that Classifies Token Replacements Accurately(高效训练编码器如何准确分类替换标记)。与其他BERT变体不同,ELECTRA使用一个生成器(generator)和一个判别器(discriminator),并使用替换标记检测这一新任务进行预训练。我们将详细了解ELECTRA的具体运作方式。
最后,我们将了解SpanBERT,它被普遍应用于问答任务和关系提取任务。我们将通过探究SpanBERT的架构来了解它的工作原理。
首先,我们将了解BERT的精简版ALBERT。BERT的难点之一是它含有数以百万计的参数。BERT-base由1.1亿个参数组成,这使它很难训练,且推理时间较长。增加模型的参数可以带来益处,但它对计算资源也有更高的要求。为了解决这个问题,ALBERT应运而生。与BERT相比,ALBERT的参数更少。它使用以下两种技术减少参数的数量。
- 跨层参数共享
- 嵌入层参数因子分解
通过使用这两种技术,我们可以有效地缩短BERT模型的训练时间和推理时间。我们将首先了解这两种技术的工作原理,然后学习ALBERT是如何进行预训练的。
1、跨层参数共享
跨层参数共享是一种有趣的方法,它可以减少BERT模型的参数数量。我们知道BERT由N层编码器组成。例如,BERT-base由12层编码器组成。所有编码器层的参数将通过训练获得。但在跨层参数共享的情况下,不是学习所有编码器层的参数,而是只学习第一层编码器的参数,然后将第一层编码器的参数与其他所有编码器层共享。
下图显示了有N层编码器的BERT模型。为了避免重复,只有编码器1被展开说明。

我们已知每层编码器都是相同的,也就是说,每层编码器都包含多头注意力层和前馈网络层。所以,我们可以只学习编码器1的参数,并与其他编码器共享这套参数。在应用跨层参数共享时有以下几种方式。
- 全共享:其他编码器的所有子层共享编码器1的所有参数。
- 共享前馈网络层:只将编码器1的前馈网络层的参数与其他编码器的前馈网络层共享。
- 共享注意力层:只将编码器1的多头注意力层的参数与其他编码器的多头注意力层共享。
默认情况下,ALBERT使用全共享选项,也就是说,所有层共享编码器1的参数。现在,我们了解了跨层参数共享技术的工作原理。下面,我们将研究另一种有趣的参数缩减技术。
2、 嵌入层参数因子分解
BERT使用WordPiece词元分析器创建WordPiece标记。WordPiece标记的嵌入大小被设定为与隐藏层嵌入的大小(特征大小)相同。WordPiece嵌入是无上下文信息的特征,它是从词表的独热(one-hot)编码向量中习得的,而隐藏层嵌入是由编码器返回的有上下文信息的特征。
我们用V表示词表的大小。BERT的词表大小为30000。我们用H表示隐藏层嵌入的大小,用E表示WordPiece嵌入的大小。
为了将更多的信息编码到隐藏层嵌入中,我们通常将隐藏层嵌入的大小设置为较大的一个数。例如,在BERT-base中,隐藏层嵌入的大小被设置为768。隐藏层嵌入的维度是 V ∗ H = 30000 ∗ 768 V*H = 30000 * 768 V∗H=30000∗768。由于WordPiece嵌入的大小与隐藏层嵌入的大小相同,因此如果隐藏层嵌入的大小H为768,那么WordPiece嵌入的大小E也为768。因此,WordPiece嵌入的维度是 V ∗ E = 30000 ∗ 768 V*E = 30000 * 768 V∗E=30000∗768。也就是说,增加隐藏层嵌入的大小H也会同时增加WordPiece嵌入的大小E。
WordPiece嵌入和隐藏层嵌入都是通过训练学习的。将WordPiece嵌入的大小设置为与隐藏层嵌入的大小相同,会增加需要学习的参数数量。那么应当如何避免这种情况呢?我们可以使用嵌入层参数因子分解方法,将嵌入矩阵分解成更小的矩阵。
我们将WordPiece嵌入的大小设置为隐藏层嵌入的大小,因为我们可以直接将词表的独热编码向量投射到隐藏空间。通过分解,我们将独热编码向量投射到低维嵌入空间( V ∗ E V*E V∗E),然后将这个低维嵌入投射到隐藏空间( E ∗ H E*H E∗H),而不是直接将词表的独热编码向量投射到隐藏空间( V ∗ H V*H V∗H)。也就是说,我们不是直接投射 V ∗ H V*H V∗H,而是将这一步分解为 V ∗ E V*E V∗E和 E ∗ H E*H E∗H。
举个例子,假设词表V的大小为30000,我们不必将WordPiece嵌入的大小设置为隐藏层嵌入的大小。假设WordPiece嵌入的大小E为128,隐藏层嵌入的大小H为768,我们通过以下步骤投射 V ∗ H V*H V∗H。
- 首先,将词表[插图]的独热编码向量投射到低维WordPiece嵌入的大小E,即 V ∗ E V*E V∗E。WordPiece嵌入的维度为 V ∗ E = 30000 ∗ 128 V*E = 30000*128 V∗E=30000∗128。
- 接着,将WordPiece嵌入的大小E投射到隐藏层H中,即 E ∗ H E*H E∗H,维度变为 E ∗ H = 128 ∗ 768 E*H = 128*768 E∗H=128∗768。
3、 训练ALBERT模型
与BERT类似,ALBERT模型使用英语维基百科数据集和多伦多图书语料库进行预训练。我们已知BERT是使用掩码语言模型构建任务和下句预测任务进行预训练的。与之类似,ALBERT模型是使用掩码语言模型构建任务进行预训练的,但ALBERT没有使用下句预测任务,而是使用句序预测(sentence order prediction,SOP)这一新任务。为什么不使用下句预测任务呢?
ALBERT的研究人员指出,使用下句预测任务进行预训练其实并不十分有效。与掩码语言模型构建任务相比,它并不是一个很难的任务。此外,下句预测任务将主题预测和一致性预测融合在一个任务中。为了解决这样做所导致的问题,研究人员引入了句序预测任务。句序预测基于句子间的连贯性,而不是基于主题预测。下面,让我们详细了解句序预测任务的工作原理。
3.1 句序预测任务
与下句预测任务类似,句序预测也是二分类任务。下句预测任务训练模型预测一个句子对是属于isNext类别,还是属于notNext类别,而句序预测任务则需要训练模型预测在给定的句子对中,两个句子的顺序是否被调换。我们以下面的一个句子对为例来说明这一点。
- 句子1:She cooked pasta(她做了意大利面)
- 句子2:It was delicious(它很美味)
在这两个句子中,可以看出句子2是句子1的后续句子。我们将此句子对标记为正例。我们可以通过调换句子的顺序来创建一个负例,如下所示。
- 句子1:It was delicious(它很美味)
- 句子2:She cooked pasta(她做了意大利面)
可以看到,句子顺序被调换了。我们把这一句子对标记为负例。
模型的目标是分析句子对是属于正例(句子顺序没有互换)还是负例(句子顺序互换)。我们可以使用任何语言的语料库为句序预测任务创建一个数据集。假设我们有几份文档,从一份文档中抽取两个连续的句子,将其标记为正例。接下来,将这两个句子的顺序互换,将其标记为负例。
现在我们知道,ALBERT模型是使用掩码语言模型构建任务和句序预测任务进行预训练的。与BERT相比,ALBERT模型的效率和能力如何?
4、 对比ALBERT与BERT
与BERT类似,ALBERT是通过不同的配置进行预训练的。不过与BERT相比,ALBERT的所有配置的参数都比较少。下图比较了BERT和ALBERT的不同配置。我们可以看到,BERT-large有3.4亿个参数,而ALBERT-large只有1800万个参数。
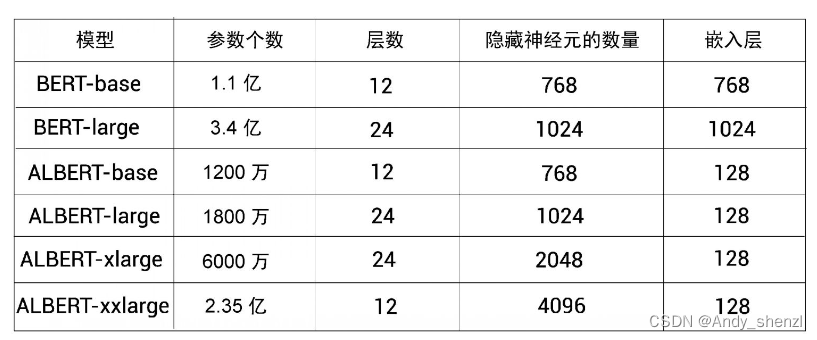
结果来自论文“ALBERT: A Lite BERT for Self-supervised Learning of Language Representations”。
与BERT一样,在预训练后,我们可以针对任何下游任务微调ALBERT模型。ALBERT-xxlarge模型在多个语言基准数据集上的性能明显优于BERT-base和BERT-large。这些数据集包括SQuAD 1.1、SQuAD 2.0、MNLI、SST-2和RACE。
因此,ALBERT模型可以作为BERT的一个很好的替代品。
5、从ALBERT中提取嵌入
有了Hugging Face的Transformers库,我们可以像使用BERT那样使用ALBERT模型。举个例子,假设需要得到句子Paris is a beautiful city中每个单词的上下文嵌入,我们来看看如何使用ALBERT实现。
导入必要的模块。
from transformers import AlbertTokenizer, AlbertModel
- 1
下载并加载预训练的ALBERT模型和词元分析器。在本例中,我们使用ALBERT-base模型。
model = AlbertModel.from_pretrained('albert-base-v2')
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
- 1
- 2
将句子送入词元分析器,得到预处理后的输入。
sentence = "Paris is a beautiful city"
inputs = tokenizer(sentence, return_tensors = "pt")
- 1
- 2
打印结果。
输出结果包括input_ids、token_type_ids和attention_mask,它们都被映射到输入句。输入句Paris is a beautiful city由5个标记(单词)组成,加上[CLS]和[SEP],共有7个标记,如下所示。
{
'input_ids': tensor([[ 2, 1162, 25, 21, 1632, 136, 3]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])
}
- 1
- 2
- 3
- 4
- 5
然后,将输入送入模型并得出结果。模型返回的hidden_rep包含最后一个编码器层的所有标记的隐藏状态特征和cls_head。cls_head包含最后一个编码器层的[CLS]标记的隐藏状态特征。
hidden_rep, cls_head = model(**inputs)
- 1
我们可以像在BERT中一样获得句子中每个标记的上下文嵌入,如下所示。
- hidden_rep[0][0]包含[CLS]标记的上下文嵌入。
- hidden_rep[0][1]包含Paris标记的上下文嵌入。
- hidden_rep[0][2]包含is标记的上下文嵌入。以此类推,hidden_rep[0][6]包含[SEP]标记的上下文嵌入。
这样一来,我们就可以像使用BERT模型那样使用ALBERT模型了。此外,我们还可以针对下游任务对ALBERT模型进行微调,这与对BERT模型进行微调的方式类似。

