
- 1go 利用channel实现定时任务
- 2spring boot应用程序接口调优记录_spring boot 压测
- 33D抓取算法的网络结构原理及作用
- 4【Python自动化Excel】多个excel文件,按列匹配数据_用python实现将多个excel按某列匹配合并
- 5github 2fa中国认证及TOTP App_two-factor authentication (2fa) is required for yo
- 6NVIC中断分组和配置
- 7ambari全攻略流程,认识ambari(一)
- 8git推送时密码出错无法重新输入出现Authentication failed for解决_git push authentication failed for
- 9uni-app总结_猫眼电影播放 uniapp
- 10超详细的Guava RateLimiter限流原理解析_ratelimiter 分钟限流
CEPH分布式存储搭建(对象、块、文件三大存储)_wget -o 对象存储数据
赞
踩


安装的ceph版本:
ceph version 12.2.12 luminous
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/ceph.repo https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph-deploy/ceph.repo
手动yum epel 源
开始集群环境配置前建议最好关闭每个节点的selinux 和 firewalld 服务
sed -i “/^SELINUX/s/enforcing/disabled/” /etc/selinux/config
setenforce 0
切换到root账户下,安装ntpdata时间同步服务器
- yum install ntpdate -y
-
- crontab -e
-
- \* * * * * /usr/sbin/ntpdate ntp.aliyun.com &> /dev/null
-
- ntpdate ntp.aliyun.com
检查各个节点的repo源是否正常
#yum repolist
在各个节点上创建用户ceph并赋予权限
- useradd ceph
-
- echo '111111' | passwd --stdin ceph
-
- echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph
-
- chmod 0440 /etc/sudoers.d/ceph
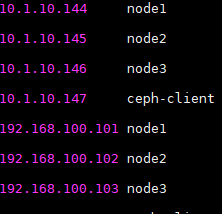
配置主机名解析,使用/etc/hosts, 例如:
# 配置sudo不需要tty
#sed -i 's/Default requiretty/#Default requiretty/' /etc/sudoers
# 配置免密钥登录 username为你创建的ceph,也就是账户名
- #su - ceph
-
- #export username=ceph ssh-keygen
-
- #ssh-copy-id ${username}@node1 ssh-copy-id ${username}node2 ssh-copy-id ${username}@node3
# 主节点安装 ceph-deploy
$sudo yum install -y ceph-deploy python-pip
#在ceph账户下创建my-cluster目录,用以存放后面收集到的密钥文件和集群配置文件
- $mkdir my-cluster
- $cd my-cluster
# 部署节点
$ceph-deploy new node1 node2 node3
# 编辑 ceph.conf 配置文件
- $cat ceph.conf [global]
-
- .....
-
- public network = 10.1.10.0/24
-
- cluster network = 192.168.100.0/24
-
-
# 安装 ceph包,替代 ceph-deploy install node1 node2 node3,不过下面的命令需要在每台node上安装 yum
#install -y ceph ceph-radosgw
在管理节点以ceph用户运行
$ cd ceph-cluster
#这个步骤是为了防止在生成keying文件信息时会自动将你的yum源换成更改为aliyun之前的,科学上网也是没用
$ ceph-deploy install --no-adjust-repos node1 node2 node3
# 配置初始 monitor(s)、并收集所有密钥: ceph-deploy mon create-initial
ls -l *.keyring
#这一步完成之后,my-cluster 目录下就会出现收集到的密钥文件
# 把配置信息拷贝到各节点
$ceph-deploy admin node1 node2 node3
#每次更改ceph的配置文件,都可以用这个命令推送到所有节点上,使用—overwrite-conf config push 参数命令时,建议提前备份好配置文件,防止覆盖过程中出现配置文件复原的问题
#配置osd,列出各个节点上所有可以用来作为osd设备的磁盘
$ceph-deploy disk list ceph-mon1 ceph-mon2 ceph-mon3 ceph-osd4
#要以ceph用户在~/my-cluster/目录下执行s
#清空osd节点上用来作为osd设备的磁盘,此步骤相当于格式化磁盘
- $ceph-deploy disk zap node1 /dev/sdb /dev/sdc
-
- $ceph-deploy disk zap node2 /dev/sdb /dev/sdc
-
- $ceph-deploy disk zap node3 /dev/sdb /dev/sdc
#创建OSD
- ceph-deploy osd create node1 --data /dev/sdb
-
- ceph-deploy osd create node2 --data /dev/sdb
-
- ceph-deploy osd create node3 --data /dev/sdb
-
- ceph-deploy osd create node1 --data /dev/sdc
-
- ceph-deploy osd create node2 --data /dev/sdc
-
- ceph-deploy osd create node3 --data /dev/sdc
#此时集群配置基本完成ceph-s 查看状态失败时,可以在各个节点的/etc/ceph/ 目录下查看配置文件所属用户和用户组是否为ceph,如果不是可以在各个节点以root运行
setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
#ceph.client.admin.keyring文件是 ceph命令行 所需要使用的keyring文件
#不管哪个节点,只要需要使用ceph用户执行命令行工具,这个文件就必须要让ceph用户拥有访问权限,就必须执行这一步
#查看集群状态,到这一步集群基本上就已经能用了
#ceph –s
#L版之后需要部署mgr,可以启动dashboard UI监控模块,更直观的查看集群状态
$ceph-deploy mgr create node1 node2 node3
#开启dashboard模块,用于UI查看
$ceph mgr module enable dashabord
#浏览器输入地址后加上默认端口号7000
任何普通的Linux主机(RHEL或基于debian的)都可以充当Ceph客户机。客户端通过网络与Ceph存储集群交互以存储或检 索用户数据。Ceph RBD支持已经添加到Linux主线内核中,从2.6.34和以后的版本开始。
# 创建 ceph 块客户端用户名和认证密钥
$ceph auth get-or-create client.rbd mon ‘allow r’ osd ‘allow class-read object_prefix rbd_children, allow rwx pool=rbd’|tee ./ceph.client.rbd.keyring
//scp ceph.client.rbd.keyring /etc/ceph/ceph.conf ceph-client:/etc/ceph/ceph.client.rbd.keyring (应该是copy不过去的,权限问题)
#客户端安装完了以后,再手动把密钥文件拷贝到客户端 也就是在客户端下vim 一个文件并写入密钥
还需要将配置文件ceph.conf也手动copy过去
# 安装ceph客户端
#wget -O /etc/yum.repos.d/ceph.repo https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph- deploy/ceph.repo
#客户端安装ceph,需手动把主机生成的client.rbd.keyring 密钥文件复制到客户端
- #yum -y install ceph
-
- #cat /etc/ceph/ceph.client.rbd.keyring
-
- #ceph -s --name client.rbd
客户端创建块设备及映射
( 1) 创建块设备
默认创建块设备,会直接创建在 rbd 池中,但使用 deploy 安装后,该rbd池并没有创建
# 创建池和块
- $ceph osd lspools # 查看集群存储池
-
- $ceph osd pool create rbd 50 # 50 为 place group 数量,由于我们后续测试,也需要更多的pg,所以这里设置为50
计算PG数
对于一个在生产环境中的 ceph分布式存储 集群中,提前根据需求和配置规划好 PG 是非常重要的,随
着使用时间的积累和 ceph 集群的不断扩展我们跟需要 ceph集群的性能能够不断的跟进
计算 Ceph 集群的PG 数的公式如下:
PG 总数 = (OSD 总数 * 100)/ 最大副本数
结果必须舍入到最接近2的N次幂的值。比如如果ceph 集群有160个OSD 且副本数是3,这样根据公
式计算得到的PG 总数是 5333.3,因此舍入到这个值到最近的 2 的N次幂的结果就是8192个PG,再根
据你所创建的存储池规划,所有的 pool 的PG数加起来是不能超过集群中 PG 的总量的。
我们还应该计算 Ceph集群中每一个POOL (池)的PG 总数。计算公式如下 :
POOL PG_NUM | PG 总数 = ((OSD 总数 * 100)/ 最大副本数)/ POOL 数
同样使用前面的例子:OSD 总数是160,副本数是3,POOL(池)总数是3。根据上面这个公式,计
算得到每个池的 PG 总数应该是1777.7,最后舍入到2 的N次幂得到结果为每个池 2048 个PG。
平衡每个池中的PG 数和每个 OSD 中的PG 数对于降低 OSD 的方差、避免速度缓慢的恢复进程是相
当重要的。
# 客户端创建 块设备
$rbd create rbd1 --size 10240 --name client.rbd
- $rbd ls --name client.rbd
-
- $rbd ls -p rbd --name client.rbd
-
- $rbd list --name client.rbd
映射块设备
$rbd --image rbd1 info --name client.rbd #此时映射到客户端,应该会报错
layering: 分层支持
exclusive-lock: 排它锁定支持对
object-map: 对象映射支持(需要排它锁定(exclusive-lock))
deep-flatten: 快照平支持(snapshot flatten support)
• fast-diff: 在client-node1上使用krbd(内核rbd)客户机进行快速diff计算(需要对象映射),我们将无法在CentOS内核3.10 上映射块设备映像,因为该内核不支持对象映射(object-map)、深平(deep-flatten)和快速diff(fast-diff)(在内核4.9中引 入了支持)。为了解决这个问题,我们将禁用不支持的特性,有几个选项可以做到这一点:
1)动态禁用
$rbd feature disable rbd1 exclusive-lock object-map deep-flatten fast-diff --name client.rbd
2) 创建RBD镜像时,只启用 分层特性。
$rbd create rbd2 --size 10240 --image-feature layering --name client.rbd
3)ceph.conf 配置文件中禁用
rbd_default_features = 1
# 我们这里动态禁用
$rbd feature disable rbd1 exclusive-lock object-map fast-diff deep-flatten --name client.rbd
#这一步创建出对应的块映射文件 /dev/rbd0
$rbd map --image rbd1 --name client.rbd rbd showmapped --name client.rbd
#创建文件系统并挂载
#fdisk -l /dev/rbd0
- #mkfs.xfs /dev/rbd0
-
- #mkdir /mnt/ceph-disk1
-
- #mount /dev/rbd0 /mnt/ceph-disk1 df -h /mnt/ceph-disk1
# 写入数据测试
#dd if=/dev/zero of=/mnt/ceph-disk1/file1 count=100 bs=1M
# 做成服务,开机自动挂载
#wget -O /usr/local/bin/rbd-mount https://raw.githubusercontent.com/aishangwei/ceph-demo/master/client/rbd-mount chmod +x /usr/local/bin/rbd-mount
#wget -O /etc/systemd/system/rbd-mount.service https://raw.githubusercontent.com/aishangwei/ceph- demo/master/client/rbd-mount.service
- #systemctl daemon-reload
-
- #systemctl enable rbd-mount.service
-
- #reboot -f
-
- #df -h
# 安装ceph-radosgw
#yum -y install ceph-radosgw
# 部署
$ceph-deploy rgw create node1 node2 node3
# 配置80端口
- #vi /etc/ceph/ceph.conf
-
- ……. [client.rgw.node1]
-
- rgw_frontends = "civetweb port=80"
$sudo systemctl restart ceph-radosgw@rgw.c720183.service
](mailto:ceph-radosgw@rgw.c720183.service)
*#你也可以使用默认的7480端口*
# 创建池
- #wget https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph-deploy/rgw/pool
-
- #wget https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph-deploy/rgw/create_pool.sh
- $chmod +x create_pool.sh
-
- $./create_pool.sh
# 测试是否能够访问 ceph 集群
- $sudo cp
-
- $ceph -s -k /var/lib/ceph/radosgw/ceph-rgw.node3/keyring --name client.rgw.node3
使用 S3 API 访问 Ceph 对象存储
# 创建 radosgw 用户
#radosgw-admin user create --uid=radosgw --display-name=“radosgw"
注意:请把 access_key 和 secret_key 保存下来 ,如果忘记可使用:radosgw-admin user info --uid … -k … --name …
# 安装 s3cmd 客户端
#yum install s3cmd -y
# 将会在家目录下创建 .s3cfg 文件 , location 必须使用 US , 不使用 https, s3cmd --configure
# 编辑 .s3cfg 文件,修改 host_base 和 host_bucket
- #vi .s3cfg
-
- ……
-
- host_base = node3.hongyuan.com:7480
-
- host_bucket = %(bucket).node3.hongyuan.com:7480
-
- ……
-
-
# 创建桶并放入文件 s3cmd mb s3://first-bucket s3cmd ls
#s3cmd put /etc/hosts s3://first-bucket s3cmd ls s3://first-bucket
# 部署 cephfs
$ceph-deploy mds create node2
注意:查看输出,应该能看到执行了哪些命令,以及生成的keyring
- $ceph osd pool create cephfs_data 128
-
- $ceph osd pool create cephfs_metadata 64 #用来存放元数据的池
-
- $ceph fs new cephfs cephfs_metadata cephfs_data
-
- $ceph mds stat ceph osd pool ls ceph fs ls
# 创建用户(可选,因为部署时,已经生成)
- $ceph auth get-or-create client.cephfs mon ‘allow r’ mds ‘allow r, allow rw path=/’ osd ‘allow rw pool=cephfs_data’ -o ceph.client.cephfs.keyring
-
-
-
- $scp ceph.client.cephfs.keyring ceph-client:/etc/ceph/
通过内核驱动和FUSE客户端挂载 Ceph FS
在Linux内核2.6.34和以后的版本中添加了对Ceph的本机支持。
# 创建挂载目录
#mkdir /mnt/cephfs
# 挂载
- #ceph auth get-key client.cephfs // 在 ceph fs服务器上执行,获取 key
-
- #mount -t ceph node2:6789:/ /mnt/cephfs -o name=cephfs,secret=…… echo …*secret*…> /etc/ceph/cephfskey // 把 key保存起来
-
- #mount -t ceph node2:6789:/ /mnt/cephfs -o name=cephfs,secretfile= /etc/ceph/cephfskey #name 为用户名 cephfs
-
-
-
- #echo "c720182:6789:/ /mnt/cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfskey,_netdev,noatime 0 0" >>
- #/etc/fstab
# 校验
- #umount /mnt/cephfs
-
- #mount /mnt/cephfs
-
-
-
- #dd if=/dev/zero of=/mnt/cephfs/file1 bs=1M count=1024
Ceph文件系统由LINUX内核本地支持;但是,如果您的主机在较低的内核版本上运行,或者您有任何应用程序依赖项,
您总是可以使用FUSE客户端让Ceph挂载Ceph FS。
# 安装软件包
#rpm -qa |grep -i ceph-fuse // yum -y intall ceph-fuse
# 挂载
- #ceph-fuse --keyring /etc/ceph/ceph.client.cephfs.keyring --name client.cephfs -m node2:6789 /mnt/cephfs
-
- #echo "id=cephfs,keyring=/etc/ceph/ceph.client.cephfs.keyring /mnt/cephfs fuse.ceph defaults 0 0 _netdev" >> /etc/fstab
注:因为 keyring文件包含了用户名,所以fstab不需要指定用了
将CephFS 导出为NFS服务器
网络文件系统(Network Filesystem, NFS)是最流行的可共享文件系统协议之一,每个基于unix的系统都可以使用它。 不理解Ceph FS类型的基于unix的客户机仍然可以使用NFS访问Ceph文件系统。要做到这一点,我们需要一个NFS服 务器,它可以作为NFS共享重新导出Ceph FS。NFS- ganesha是一个在用户空间中运行的NFS服务器,使用libcephfs支 持Ceph FS文件系统抽象层(FSAL)。
# 安装软件
#yum install -y nfs-utils nfs-ganesha
##如果你的aliyun源中没有nfs-ganesha package 时,需要手动编译nfs-ganesha 源码包
#可参照下面的链接
https://editor.csdn.net/md/?articleId=103496886
# 启动 NFS所需的rpc 服务
#systemctl start rpcbind; systemctl enable rpcbind systemctl status rpc-statd.service
# 修改配置文件
#vi /etc/ganesha/ganesha.conf

#通过提供Ganesha.conf 启动NFS Ganesha守护进程
- #ganesha.nfsd -f /etc/ganesha.conf -L /var/log/ganesha.log -N NIV_DEBUG
-
-
-
- #showmount -e
# 客户端挂载
- #yum install -y nfs-utils mkdir /mnt/cephnfs
-
- #mount -o rw,noatime node2:/ /mnt/cephnfs

