
- 1Mysql查询语句大全
- 2(二)百度AI 开放平台API调用之AccessToken的获取_百度开放平台申请access_token
- 3html接入高德地图
- 4ELK日志分析系统之Kafka
- 5node 多种方法连接mysql_node连接mysql
- 6SystemVerilog Assertions应用指南 第一章(1.25章节 “first_match”运算符)_systemverilog的assertion first_match
- 7员工转正申请书_员工入职、试工、转正、辞退作业管理制度
- 8轻松教你苹果airdrop怎么用_airdrop在哪里打开
- 9Maya-Mel-转动动画_用maya 动画表达式做圆周运动
- 10MySql的安装配置超详细教程与简单的建库建表方法_mysql怎么安装创建
Hadoop大数据-HDFS分布式文件系统_分布式文件系统hdfs
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
Hadoop分布式文件系统(HDFS)扮演着非常重要的大数据存储作用,以文件的形式为上层应用提供海量的数据存储服务,高可靠、高容错、高扩展性。
本文具体介绍HDFS分布式文件系统,实验安装部分可参考Hadoop伪分布式集群环境搭建
可参考博客资源下载
Hadoop集群部署及测试实验(一).docx
Hadoop集群部署及测试实验(二).docx
Hadoop集群部署及测试实验(三).docx
一、HDFS的简介
HDFS:Hadoop Distributed File System,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础。
支持海量数据的存储,成百上千的计算机组成存储集群,HDFS可以运行在低成本的硬件之上,具有的高容错、高可靠性、高可扩展性、高吞吐率等特征,非常适合大规模数据集上的应用。
1.HDFS的演变
传统文件系统:
将数据文件直接存储在一台服务器上
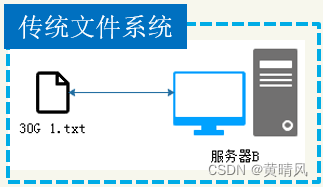
当数据越来越大时,就需要扩容,由于文件过大,上传和下载都非常耗时。
解决方案:
扩容解决:增加硬盘和内存(空间有限,治标不治本)
扩展解决:增加多台服务器(分布式存储雏形)
分布式文件系统雏形
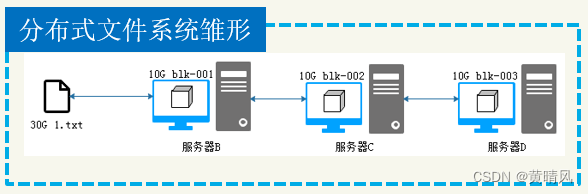
解决了空间问题,还需要解决上传与下载的效率问题:
解决方案:
数据切片:将一个大数据分隔成多个数据块。
并行传输:将数据块以并行的方式传输到分布式服务器(服务器B、C、D同时接收数据存储)
以30G数据为例,切成3块,每块10G,并行传到B C D服务器后,时间能减少到原来传输的1/3。
分布式存储方案能实现的原因是数据存储的速度远远小于网络传输的速度。
解决了上传速度问题,文件通过数据库分别存储在服务器集群中,用户如何获取一个完整的文件呢?
解决方案:
信息记录:用一台专门的服务器(其实是一个服务),用来记录文件被切割后的数据块信息以及数据块的存储位置信息。
HDFS文件系统雏形
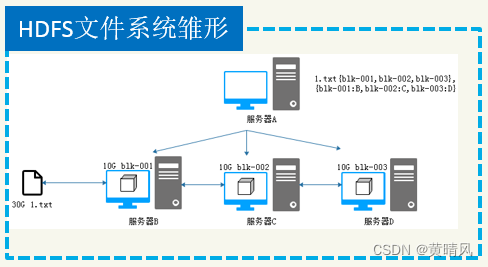
服务器A用于管理其他服务器,记录文件被切分多少数据块,分别存储在哪个服务器中,当客户端取回数据时,先向A请求数据,A提供下载地址目录,客户端在分别从数据节点按数据顺序流取回数据。
解决了数据取回的问题,系统功能基本上实现了,但当集群中某一台服务器宕机,就无法正常上传和获取数据了,这就是俗称单点故障。
解决方案:
数据备份:每个服务器额外存储数据块,如下图,每个服务器都存储两个数据块,当一台宕机的时候,可以从其他两台备份里找到,组成完整的数据块。
集群监测:服务器A实时监控服务器集群,发现服务器宕机后,迅速踢出存储集群,并恢复备份数据。
HDFS文件系统
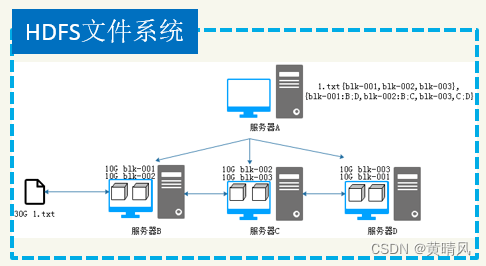
HDFS分布式文件系统也解决了:
(1)单机负载高的问题
(2)数据的可靠性和安全性
(3)文件管理困难
2.HDFS体系结构详解
系统概述
随着数据量的不断增大,导致数据在单机存储不了,HDFS就是解决大规模数据存储及存储过程的各种问题的。
(1)对外提供统一的文件管理能力,对于用户来说就像操作一台服务器
(2)支持超大文件存储,可以达到TB、PB级别,实际上HDFS就是针对大文件的,并不适合细碎的小文件。
(3)流式数据访问,数据吞吐量高,一次写入、多次读取。(不适合需要频繁修改的数据存储)
(4)简单的一致性,文件一旦写入后,一般就不需要进行修改,简单的保证数据的一致性。
(5)硬件故障检测及应对,快速检测故障、快速自动恢复,高容错、高可靠性的特点。
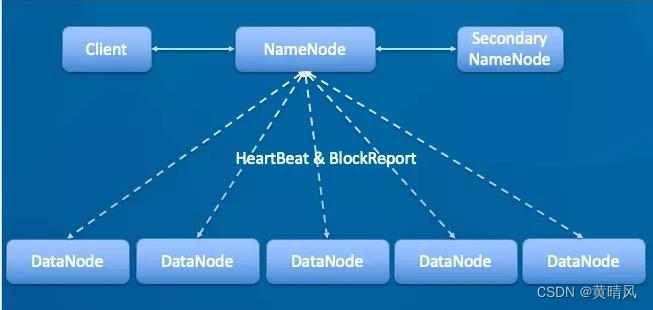
HDFS系统架构
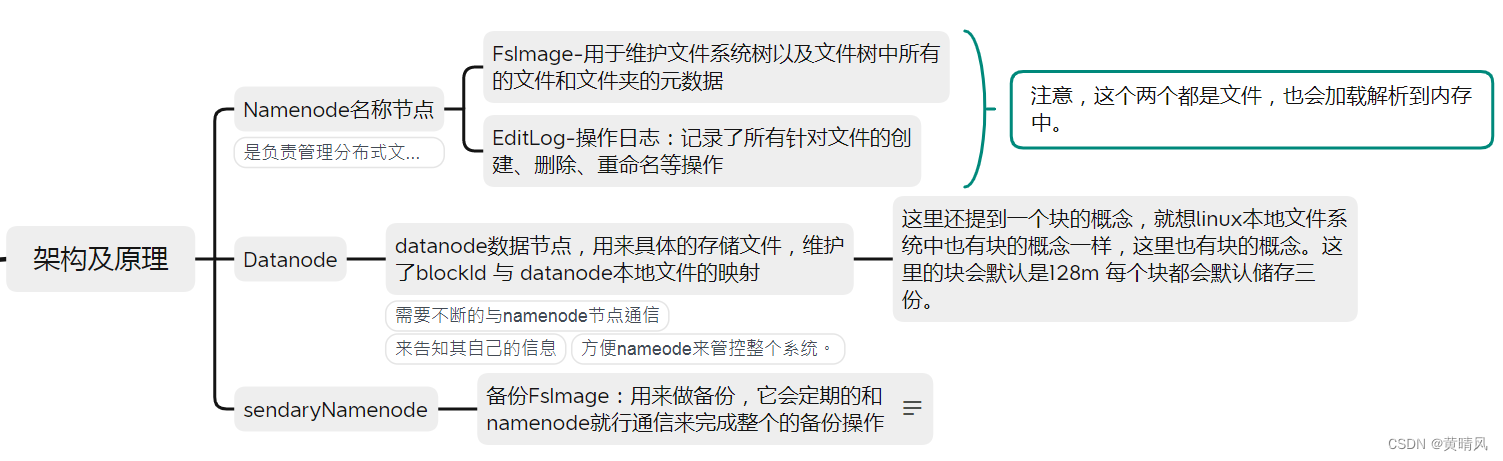
HDFS由一组计算机(节点)组成,节点上运行着不同的程序:
- NameNode
- Secondary NameNode
- DataNode
在一台服务器节点使用jps查看HDFS服务进程
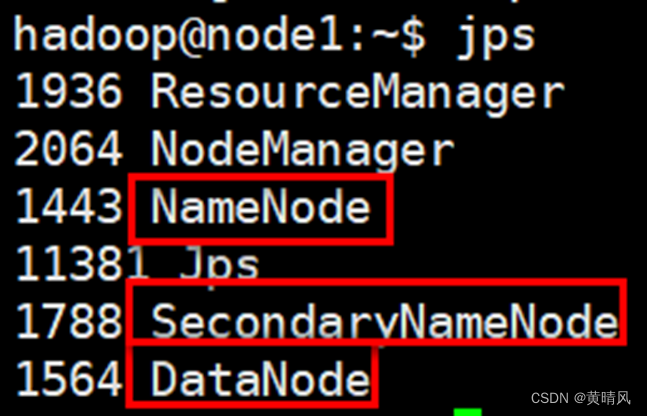
此处出现三个服务,分别是:NameNode、Secondary NameNode 、DataNode如下图所示:
(1)NameNode
NameNode也被称为名节点或管理节点或元数据节点,(根据上图来讲就是服务器A)相当于HDFS的大脑,管理文件系统的命名空间,维护整个文件系统的目录数,及目录数中的所有子目录和文件。
以下是NameNode具体工作
- 管理维护HDFS(管理DataNode上文件Block的均衡,维持副本数量)
- 接收客户端的请求:上传、下载、创建目录等
- 维护了两个非常重要的文件: edits文件(操作日志文件) --> 记录操作日志(edit log) fsimage文件 --> HDFS的元信息
第三点中两个重要文件:
- fsimage文件(File System Image)文件系统镜像,主要 存储HDFS的元信息,是元数据的完整快照,当NameNode启动时候,会将fsimage加载到内存中。(有点像虚拟机备份用的系统快照)
- edit.log文件(HDFS元信息数据的编辑日志) 该文件保存用户对命名镜像的修改信息。
在HDFS上,fsimage镜像目的是记录文件的元信息,而edit.log记录的元信息变化的过程,比如新增、删除等。
类比银行账单一个是存取流水,一个是余额。

创建文件、删除文件、再创建文件abc的过程,最终结果目录下只有一个

如何理解edit log 和fsimage?

1)edits (edit log)
1)edits记录了HDFS的操作日志
2)最新的操作日志:edits_inprogress****
3)都是二进制
4)HDFS提供一个工具:edits viewer 日志查看器 ----> XML
在系统中查看edits

2)fsimage
1)HDFS的元信息:存在 fsimage文件
2)就跟edits文件在一起
3)记录:数据块的位置、冗余信息、文件属性等
4)也是一个二进制
5)HDFS提供一个 image viewer ----> 文本或者xml
在系统中查看fsimage
(2)Secondary NameNode
Secondary NameNode也被称为从元数据节点(辅助名称节点),是HDFS主从架构中的备用节点,但它并不是NameNode的备用或备份,主要功能是给NameNode打下手:
FsImage是一个大型文件,如果频繁执行写操作,会导致系统极其缓慢,通过Edit Log记录编辑日志,定点写入检查点,并将之前的Edit Log日志文件删除,但NameNode比较繁忙,所以将这一工作交给Secondary NameNode,Secondary NameNode的功能保证了HDFS系统的完整性。
- 定期将Edit Log日志文件和FsImage镜像文件拷贝到Secondary NameNode,并合并到FsImage镜像文件中,此时NameNode将新建一个新的空Edit Log日志文件。
- 将合并后的FsImage镜像文件拷贝回NameNode,减少Edit Log日志文件的大小,缩减集群重启的时间。
合并过程
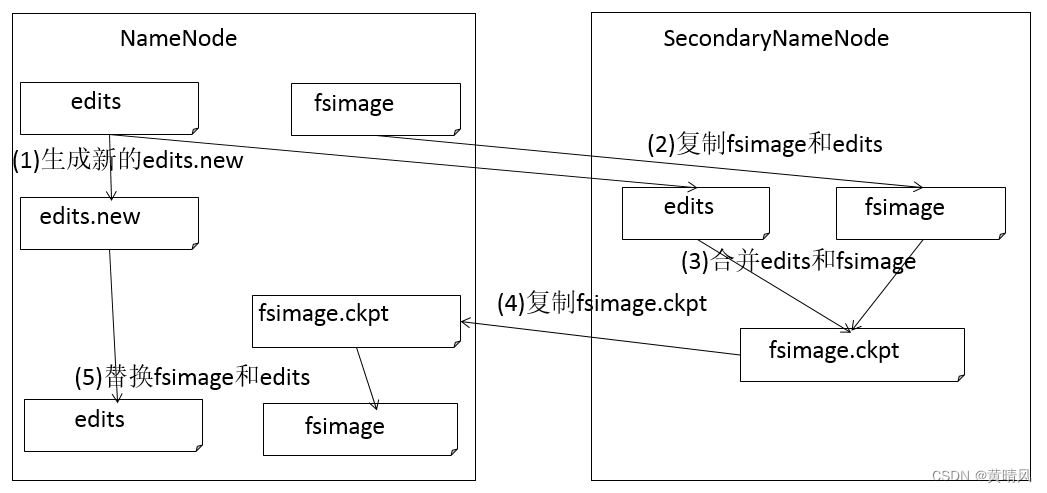
1)首先生成一个名叫edits.new的文件,用于记录合并过程中产生的日志信息;
2)当触发到某一时机时(时间间隔达到1小时或Edits中的事务条数达到1百万)时SecondaryNamenode将edits文件、与fsimage文件从NameNode上下载到SecondNamenode上;
3)将edits文件与fsimage进行合并操作,合并成一个fsimage.ckpt文件;
4) 将生成的合并后的文件fsimage.ckpt文件上传到NameNode上;
5) 在NameNode上,将fsimage.ckpt变成fsimage文件替换NameNode上原有的fsimage文件。将edits.new文件上变成edits文件替换NameNode上原有的edits文件。
检查点(checkpoint) 合并的时间点
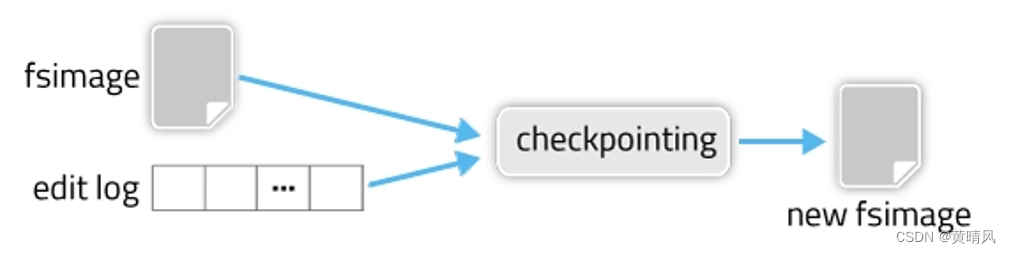
什么时候进行合并?
1)每隔60分钟(dfs.namenode.checkpoint.period)
2)当edits文件达到100万条事务(dfs.namenode.checkpoint.txns)
3)edits文件达到默认值(如64兆)
只要达到这几个条件之一就可以触发检查点操作,具体可以通过配置文件配置。
为什么在检查点合并能减少namenode启动的时间?
因为在namenode启用的时候会读取fsimage并跟edit logs合并,检查点合并后,可以减小edit logs文件,提升namenode启动的时间。
(3)DataNode
DataNode被称为数据节点,是HDFS主从架构的从节点。在DataNode节点上数据块就是普通文件,通过数据节点的linux系统下进行文件查看,可以在DataNode存储块对应的目录下看到数据块(块名称是blk_blkID)。
DataNode存储块对应的目录默认是$(dfs.data.dir)/current的子目录下,$(dfs.data.dir)是定义的文件存储目录
比如:/data/dfs/data/current
- 1
- 2

数据块大小(一整个大的文件被切成多大的数据块进行上传):
Hadoop 1.x 默认 64MB
Hadoop 2.x 默认128MB
上传一个大于128M的文件(例子为206M)
hdfs dfs -put hadoop-2.7.3.tar.gz /user/hadoop
- 1
上传完成,打印文件的Block报告

可以看到 hadoop-2.7.3.tar.gz 大小为216198931字节。第一块134217728字节,刚好128M,剩下的81981203为一个块。
打印文件块的位置信息(-locations)
hdfs fsck /user/hadoop/hadoop-2.7.3.tar.gz -files -blocks -locations
- 1

可看到每块的存储位置,在两个节点上,标红的为数据节点ip。
Datanode总结:
- 一个数据块在Datanode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- Datanode启动后想namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有namenode给该Datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个Datanode的心跳,则认为该节点不可用。集群运行中可用安全加入和退出一些机器。
- 文件切分成块,(默认大小128M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)
- Datanode在本地文件系统存储文件块数据,以及块数据的校验和。可以创建,删除,移动和重命名文件,当文件创建,写入和关闭之后不能修改文件的内容。
- 当Datanode读取block的时候,它会计算checksum,如果计算后的checksum,与block创建时值不一样,说明该block已经损坏。如果块已损坏,Client会读取其它Datanode上的block.namenode标记该块已经损坏,然后复制block达到预期设置的文件备份数。Datanode在其文件创建后三周验证其checksum。
二、副本策略
1.副本技术
副本技术即分布式数据复制技术,是分布式计算的一个重要组成部分。允许数据在多个服务器端共享,且本地服务器可以存取不同物理地点的远程服务器上的数据,也可以使所有服务器均持有数据副本。
副本技术:
(1)提高系统可靠性
(2)负载均衡
(3)提高访问效率
2.机架感知(HDFS副本冗余存储策略)
首先,一个重要的假设前提是HDFS运行于一个具有树状网络拓扑结构的集群上。例如集群由多个数据中心组成,每个数据中心里有多个机架,而每个机架上有多台计算机(数据节点)。
如下图所示:
网络拓扑(NetworkTopology)
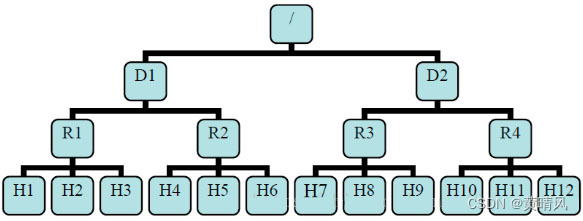
在Hadoop里,以类似于一种文件目录结构的方式来表示节点。
例如,R1的位置可以表示为 /D1/R1,而H12的位置可以表示为 /D2/R4/H12。
当数据节点启动的时候,需要通过一种机制来明确它在集群中的位置,才能构建完整的网络拓扑图。
因此,首先它需要确认它的上级节点(通常也就是机架)的位置。
数据节点程序支持选项”-p”或”-parent”从命令行读入上级节点位置。
如果没有指定这个选项,那么会使用一个默认的上级节点。
至于如何获取上级节点信息,由实施Hadoop的机构自行决定。一个常用的做法是使用脚本打印当前机器的上级节点信息到标准输出stdout。
这样数据节点启动的时候就可以获取到上级节点的信息(Hadoop应该是通过接口’DNSToSwitchMapping’来解析这个信息,具体请参考手册的Class说明)。
数据节点会把它的位置信息发给名称节点。
当名称节点收到数据节点的位置信息以后,它会先检查网络拓扑中是否已经有这个数据节点的记录。
如果有,它会把旧的记录删除,加入新的节点位置信息。
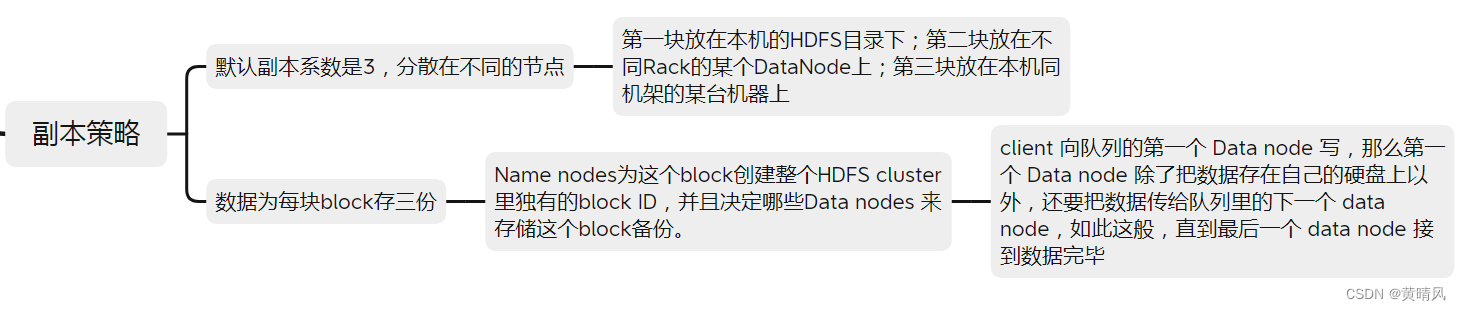
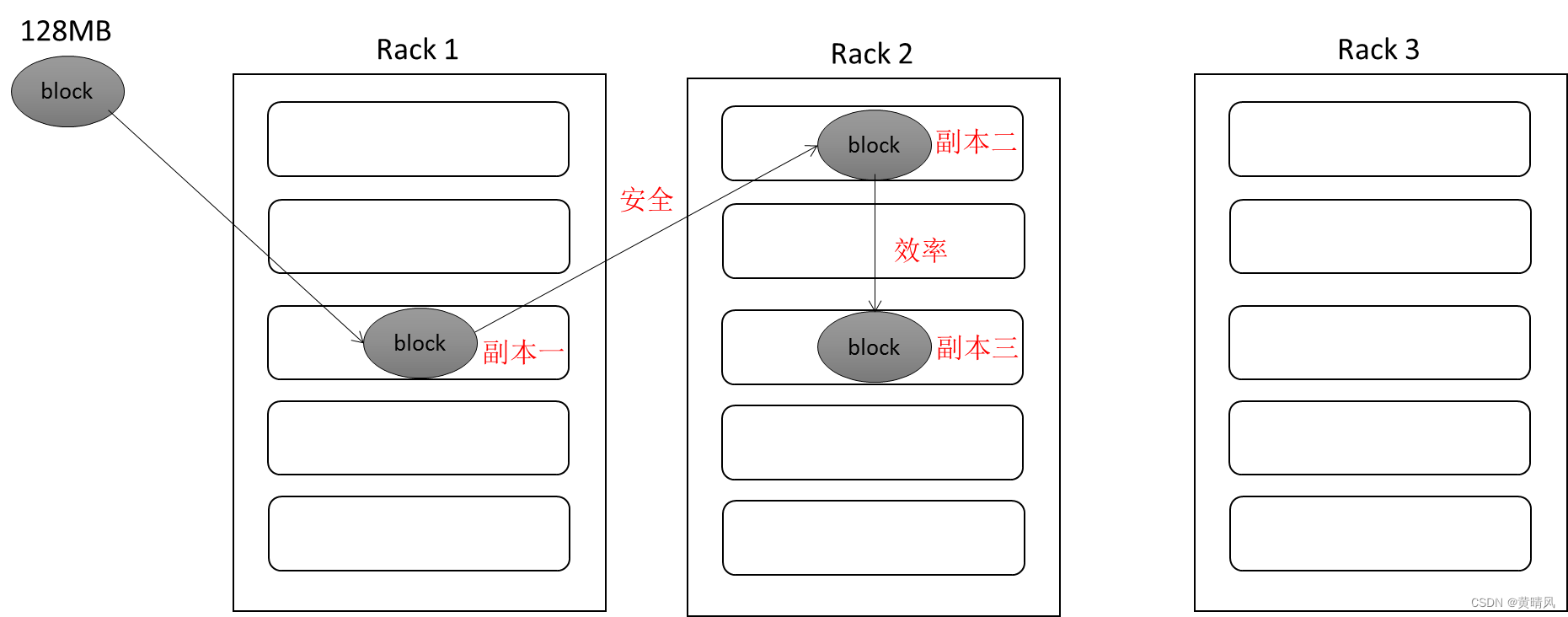
HDFS副本冗余存储策略
- 默认为副本数为3
- 第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同机架的其他节点上。
- 更多副本:随机节点
网络拓扑机器之间的距离
这里基于一个网络拓扑案例,介绍在复杂的网络拓扑中 hadoop 集群
每台机器之间的距离。
有了机架感知,NameNode 就可以画出上图所示的 datanode 网络拓
扑图。
D1,R1 都是交换机,最底层是 datanode。则 H1 的
rackid=/D1/R1/H1,H1 的 parent 是 R1,R1 的是 D1。这些 rackid
信息可以通过 topology.script.file.name 配置。有了这些 rackid 信息
就可以计算出任意两台 datanode 之间的距离。
- distance(/D1/R1/H1,/D1/R1/H1)=0 相同的 datanode
- distance(/D1/R1/H1,/D1/R1/H2)=2 同一 rack 下的不同 datanode
- distance(/D1/R1/H1,/D1/R2/H4)=4 同一 IDC(互联网数据中心(机 房))下的不同 datanode
- distance(/D1/R1/H1,/D2/R3/H7)=6 不同 IDC 下的 datanode
所以我们可以根据通过计算网络拓扑的值来实现机架感知的数据副本冗余存储策略。
总结
本文仅仅简单Hadoop系统的HDFS的系统架构,以及系统架构中软件的功能与特点,在数据备份方面讲解了机架感知的原理。

