
- 1安卓开发帧布局(FrameLayout)的简单使用
- 2基于SSM的员工信息管理系统(含文档)_基于ssm的员工管理系统
- 3HCIP交换技术(接口类型考察)实验_chyp接口
- 4css flex布局两个元素水平居中垂直居中
- 5ClickHouse Kafka表引擎使用详解_clickhouse kafka引擎
- 6Python自动化测试面试题-Selenium篇
- 7Python list 列表方法_python已有两个列表,判断如果存在,则输出其在列表二中的索引, 如果不存在
- 8【雕爷学编程】MicroPython手册之 pyboard 特定端口库 pyb.USB_micropython usb
- 9单片机通讯协议
- 10Linux编译器-vim使用
机器学习中的数据预处理方法与步骤_机器学习数据预处理
赞
踩
数据预处理是准备原始数据并使其适用于机器学习模型的过程。这是创建机器学习模型的第一步,也是至关重要的一步。
在创建机器学习项目时,我们并不总是遇到干净且格式化的数据。并且在对数据进行任何操作时,必须对其进行清理并以格式化的方式放置。所以为此,我们使用数据预处理任务。
为什么我们需要数据预处理?
真实世界的数据通常包含噪声、缺失值,并且可能采用无法直接用于机器学习模型的不可用格式。数据预处理是清理数据并使其适用于机器学习模型的必要任务,这也提高了机器学习模型的准确性和效率。
它涉及以下步骤:
- 获取数据集
- 导入相关库
- 导入数据集
- 查找缺失的数据
- 编码分类数据
- 将数据集拆分为训练集和测试集
- 特征缩放
一、获取数据集
要创建机器学习模型,我们需要的第一件事是数据集,因为机器学习模型完全适用于数据。以适当格式收集的特定问题的数据称为数据集。
数据集可能有不同的格式用于不同的目的,例如,如果我们想为商业目的创建关于肝病患者的机器学习模型,那么数据集将是肝病患者所需的数据集。数据集我们通常将其放入 CSV文件中。但是,有时,我们可能还需要使用 HTML 或 xlsx 文件。
什么是 CSV 文件?CSV 代表“逗号分隔值”文件;它是一种文件格式,允许我们保存表格数据,例如电子表格。它对于庞大的数据集很有用,并且可以在程序中使用这些数据集。
二、导入常见库
为了使用 Python 进行数据预处理,我们需要导入一些预定义的 Python 库。这些库用于执行一些特定的工作。我们将使用三个特定的库进行数据预处理,它们是:
- numpy
- matplotlib
- pandas
三、导入数据集
3.1 读取数据
一般使用pandas来读取文件:
data_set = pd .read_csv('Dataset.csv')
- 1
data_set是存储数据集的变量的名称,在函数内部,我们传递了数据集的名称。一旦我们执行了上面这行代码,它将成功地在我们的代码中导入数据集。
这里以心脏病数据集为例:
import pandas as pd
data=pd.read_csv('heart.csv')
data
- 1
- 2
- 3
- 4
- 5
读取如下:
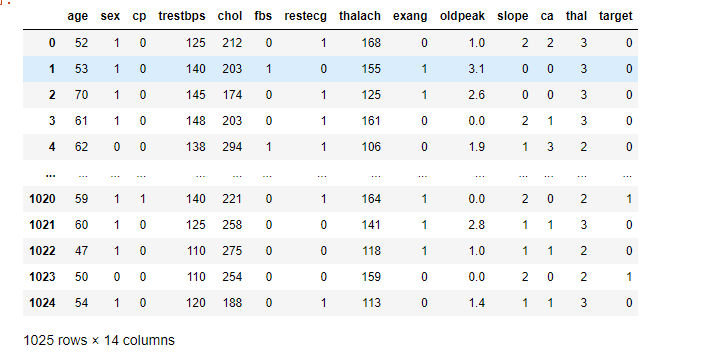
3.2提取因变量和自变量
在机器学习中,区分特征矩阵(自变量)和因变量与数据集很重要。在我们的数据集中,有三个自变量age,sex…其中target是因变量。
提取自变量
x= data.iloc[:,:-1].values
x
- 1
- 2
- 3
如下:

为了提取自变量,我们将使用Pandas 库的iloc[ ]方法。它用于从数据集中提取所需的行和列。在上面的代码中,第一个冒号(
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

