
热门标签
热门文章
- 1如何做好一名前端Leader_如果你是某项目前端团队的负责人,你将如何开展工作?
- 22020,智能货柜的现状与未来_智能称重柜在智能货柜整体销量中有多少占比
- 3Android 开发中的SSL pinning_ssl pinning 抓包
- 4基于python的拍卖系统_一个完整的拍卖系统
- 5GitHub Pages + Hexo搭建个人博客网站,史上最全教程_github pages +hexo
- 6Mac下常用命令_mac常用命令
- 7ChatGPT:让论文写作不再是难题
- 8mysql设置账号只能访问某些表,某些字段的权限_授予用户修改字段的权限
- 9大话设计模式——单例模式_c# 单例模式 大话设计模式
- 10这 11 款最佳 Linux 发行版深受 Ubuntu 爱好者喜欢!_哪个linux发行版好用
当前位置: article > 正文
GANs系列:CGAN(条件GAN)原理简介以及项目代码实现
作者:凡人多烦事01 | 2024-04-13 07:44:37
赞
踩
cgan

一、原始GAN的缺点
生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强。针对原始GAN不能生成具有特定属性的图片的问题, Mehdi Mirza等人提出了cGAN,其核心在于将属性信息y 融入生成器G和判别器D中,属性y可以是任何标签信息, 例如图像的类别、人脸图像的面部表情等。
二、CGAN的基本原理
cGAN的中心思想是希望 可以控制 GAN 生成的图片,而不 是单纯的随机生成图片。 具体来说,Conditional GAN 在生成器和判别器的输入中 增加了额外的 条件信息,生成器生成的图片只有足够真实 且与条件相符,才能够通过判别器。
实际上 , 在无条件约束的生成模型中 , 没法控制数据生成的模式。然而,通过额外的信息对模型进行约束,有可能指导数据生成的过程。条件约束可以是类标签 , 可以是图像修补的部分数据, 甚至是来自不同模态的数据
cGAN将 无监督学习 转为 有监督学习 使得网络可以更好地在我们的掌控下进行学习!
从公式看,cgan相当于在原始GAN的基础上对生成器部分 和判别器部分都加了一个条件
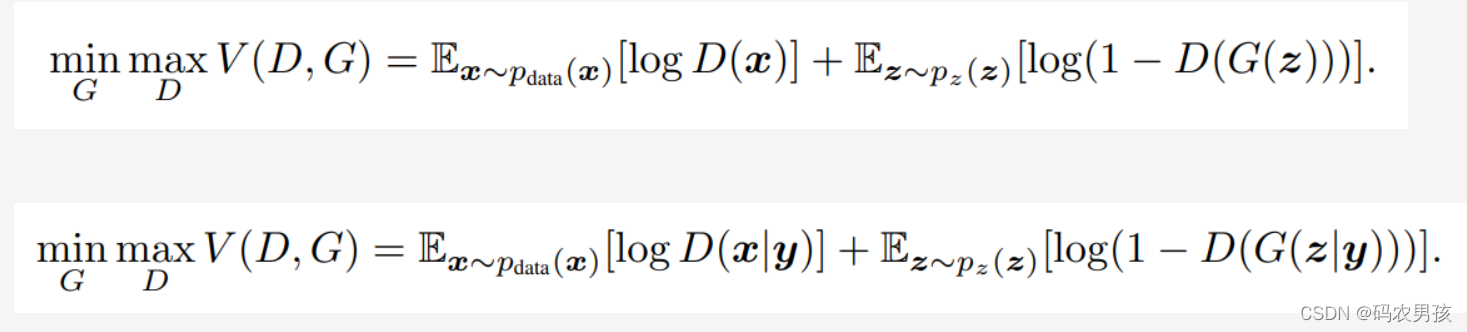
三、CGAN模型
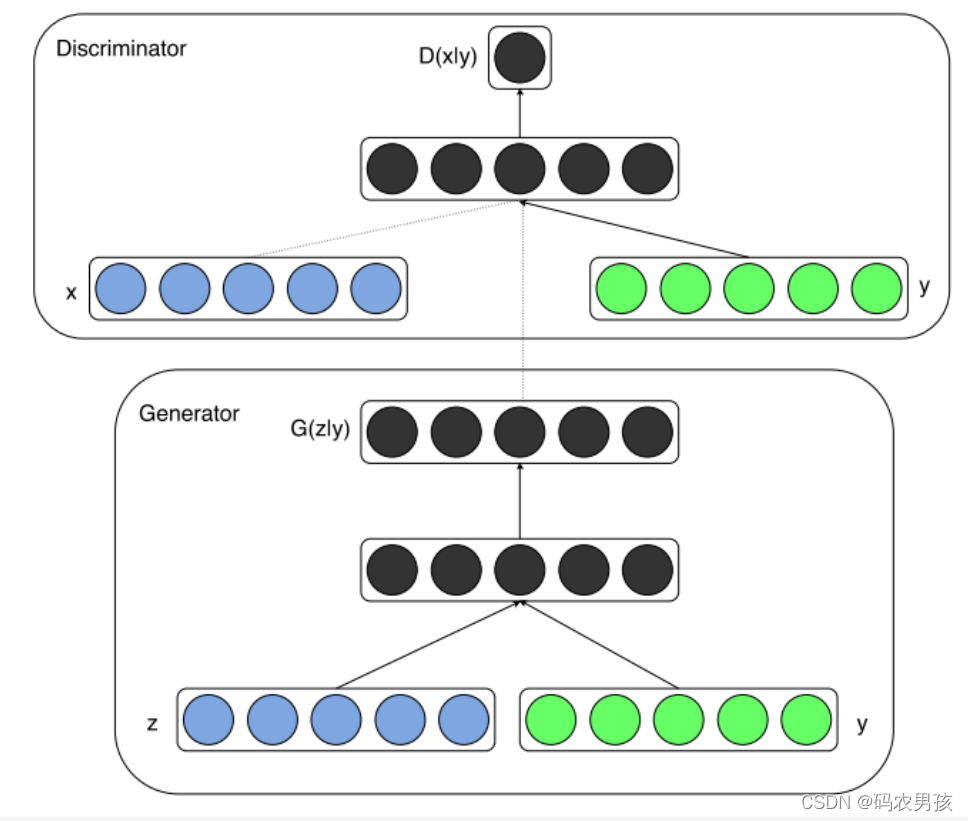
如果将上图绿色部分的y去掉,就是GAN的原理图。
四、CGAN结构
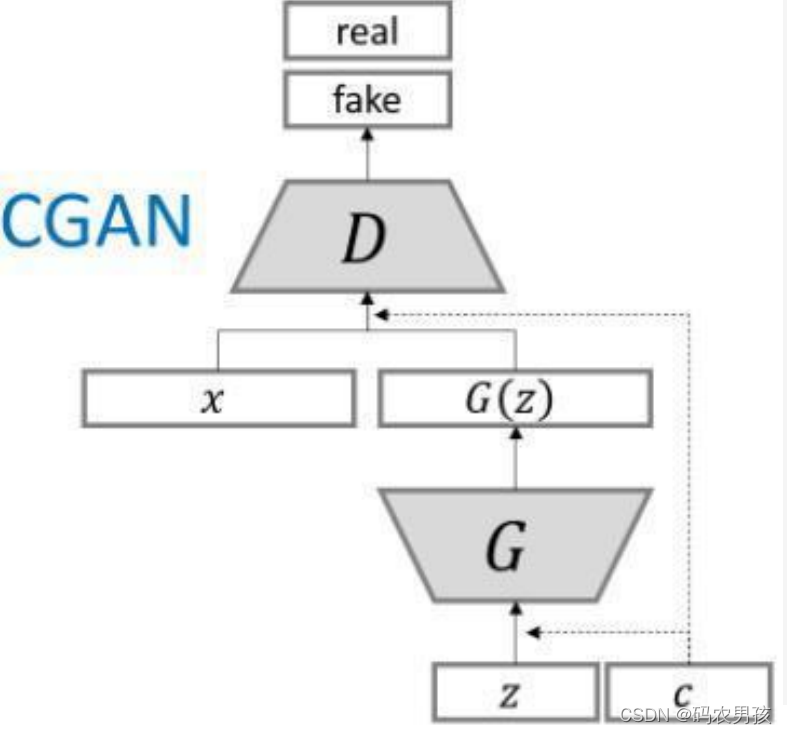
为了实现条件GAN的目的,生成网络和判别网络的原理和 训练方式均要有所改变。
模型部分,在判别器和生成器中
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/415185
推荐阅读
相关标签

