
- 11. 查询全部学生的学号、姓名、课程名称、成绩。_查询所有学生的学号,姓名,课程名和成绩
- 2学习opencv:PS滤镜—扩散_ps滤镜扩散有什么用
- 3基于Springboot框架家教老师预约系统设计与实现 开题报告
- 43D目标检测之数据集_3d目标检测数据集
- 5发现新词 | NLP之无监督方式构建词库(一)
- 6虚拟机下Redis的安装和部署_虚拟机上部署redis
- 7跨境电商竞品分析报告_跨境电商平台 竞品分析 苹果手机华为手机
- 8java基础教程01讲:使用idea写第一个java程序_idea怎么写代码
- 9Python模块学习 - fabric
- 10Linux进程管理学习心得_linux父子进程学习心得体会
RabbitMQ提供了6种消息模型介绍_rabbitmq有几种类型
赞
踩
RabbitMQ提供了6种消息模型,但是第6种其实是RPC,并不是MQ,因此不予学习。那么也就剩下5种。
但是其实3、4、5这三种都属于订阅模型,只不过进行路由的方式不同。

一.基本消息模型
RabbitMQ是一个消息代理:它接受和转发消息。 你可以把它想象成一个邮局:当你把邮件放在邮箱里时,你可以确定邮差先生最终会把邮件发送给你的收件人。 在这个比喻中,RabbitMQ是邮政信箱,邮局和邮递员。
RabbitMQ与邮局的主要区别是它不处理纸张,而是接受,存储和转发数据消息的二进制数据块。

P(producer/ publisher):生产者,一个发送消息的用户应用程序。
C(consumer):消费者,消费和接收有类似的意思,消费者是一个主要用来等待接收消息的用户应用程序
队列(红色区域):rabbitmq内部类似于邮箱的一个概念。虽然消息流经rabbitmq和你的应用程序,但是它们只能存储在队列中。队列只受主机的内存和磁盘限制,实质上是一个大的消息缓冲区。许多生产者可以发送消息到一个队列,许多消费者可以尝试从一个队列接收数据。
总之:
生产者将消息发送到队列,消费者从队列中获取消息,队列是存储消息的缓冲区。
我们将用Java编写两个程序;发送单个消息的生产者,以及接收消息并将其打印出来的消费者。我们将详细介绍Java API中的一些细节,这是一个消息传递的“Hello World”。
我们将调用我们的消息发布者(发送者)Send和我们的消息消费者(接收者)Recv。发布者将连接到RabbitMQ,发送一条消息,然后退出。
1.2.消息确认机制(ACK)
因此,RabbitMQ有一个ACK机制。当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收。不过这种回执ACK分两种情况:
- 自动ACK:消息一旦被接收,消费者自动发送ACK
- 手动ACK:消息接收后,不会发送ACK,需要手动调用
这需要看消息的重要性:
- 如果消息不太重要,丢失也没有影响,那么自动ACK会比较方便
- 如果消息非常重要,不容丢失。那么最好在消费完成后手动ACK,否则接收消息后就自动ACK,RabbitMQ就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了。
自动ACK存在的问题
消费者逻辑中有异常,但是还是会消费掉队列中的数据
二、work消息模型
工作队列或者竞争消费者模式
在第一篇教程中,我们编写了一个程序,从一个命名队列中发送并接受消息。在这里,我们将创建一个工作队列,在多个工作者之间分配耗时任务。
工作队列,又称任务队列。主要思想就是避免执行资源密集型任务时,必须等待它执行完成。相反我们稍后完成任务,我们将任务封装为消息并将其发送到队列。 在后台运行的工作进程将获取任务并最终执行作业。当你运行许多工人时,任务将在他们之间共享,但是一个消息只能被一个消费者获取。
这个概念在Web应用程序中特别有用,因为在短的HTTP请求窗口中无法处理复杂的任务。
接下来我们来模拟这个流程:
P:生产者:任务的发布者
C1:消费者,领取任务并且完成任务,假设完成速度较快
C2:消费者2:领取任务并完成任务,假设完成速度慢
面试题:避免消息堆积?
1) 采用workqueue,多个消费者监听同一队列。
2)接收到消息以后,而是通过线程池,异步消费。

2.1 能者多劳
刚才的实现有问题吗?
- 消费者1比消费者2的效率要低,一次任务的耗时较长
- 然而两人最终消费的消息数量是一样的
- 消费者2大量时间处于空闲状态,消费者1一直忙碌
现在的状态属于是把任务平均分配,正确的做法应该是消费越快的人,消费的越多。
怎么实现呢?
我们可以使用basicQos方法和prefetchCount = 1设置。 这告诉RabbitMQ一次不要向工作人员发送多于一条消息。 或者换句话说,不要向工作人员发送新消息,直到它处理并确认了前一个消息。 相反,它会将其分派给不是仍然忙碌的下一个工作人员。

三、订阅模型分类
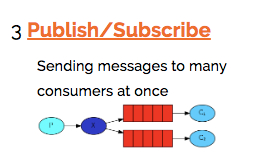
在之前的模式中,我们创建了一个工作队列。 工作队列背后的假设是:每个任务只被传递给一个工作人员。 在这一部分,我们将做一些完全不同的事情 - 我们将会传递一个信息给多个消费者。 这种模式被称为“发布/订阅”。
解读:
1、1个生产者,多个消费者
2、每一个消费者都有自己的一个队列
3、生产者没有将消息直接发送到队列,而是发送到了交换机
4、每个队列都要绑定到交换机
5、生产者发送的消息,经过交换机到达队列,实现一个消息被多个消费者获取的目的
X(Exchanges):交换机一方面:接收生产者发送的消息。另一方面:知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
Exchange类型有以下几种:
Fanout:广播,将消息交给所有绑定到交换机的队列
Direct:定向,把消息交给符合指定routing key 的队列
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
我们这里先学习
Fanout:即广播模式
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
2.4.订阅模型-Fanout
在广播模式下,消息发送流程是这样的:
- 1) 可以有多个消费者
- 2) 每个消费者有自己的queue(队列)
- 3) 每个队列都要绑定到Exchange(交换机)
- 4) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
- 5) 交换机把消息发送给绑定过的所有队列
- 6) 队列的消费者都能拿到消息。实现一条消息被多个消费者消费
2.4.1.生产者
两个变化:
- 1) 声明Exchange,不再声明Queue
- 2) 发送消息到Exchange,不再发送到Queue
2.4.2.消费者1
要注意代码中:队列需要和交换机绑定
我们运行两个消费者,然后发送1条消息:

2.5.订阅模型-Direct
有选择性的接收消息
在订阅模式中,生产者发布消息,所有消费者都可以获取所有消息。
在路由模式中,我们将添加一个功能 - 我们将只能订阅一部分消息。 例如,我们只能将重要的错误消息引导到日志文件(以节省磁盘空间),同时仍然能够在控制台上打印所有日志消息。
但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
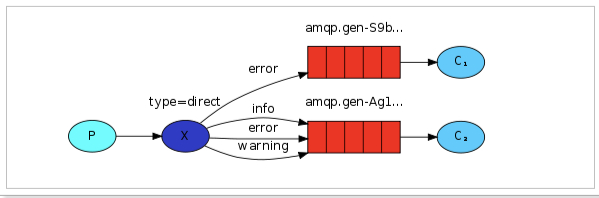
在Direct模型下,队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
消息的发送方在向Exchange发送消息时,也必须指定消息的routing key。
P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
C1:消费者,其所在队列指定了需要routing key 为 error 的消息
C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
2.5.1.生产者
此处我们模拟商品的增删改,发送消息的RoutingKey分别是:insert、update、delete

2.5.2.消费者1
我们此处假设消费者1只接收两种类型的消息:更新商品和删除商品。

2.5.3.消费者2


2.6.订阅模型-Topic
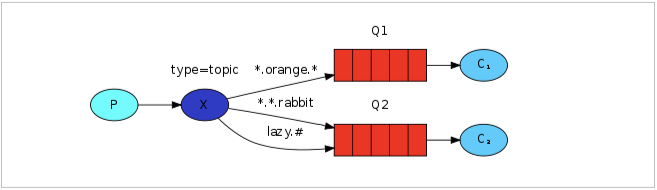
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
audit.#:能够匹配audit.irs.corporate 或者 audit.irs
audit.*:只能匹配audit.irs
使用topic类型的Exchange,发送消息的routing key有3种: item.isnert、item.update、item.delete:
2.6.2.消费者1
我们此处假设消费者1只接收两种类型的消息:更新商品和删除商品

2.6.3.消费者2
我们此处假设消费者2接收所有类型的消息:新增商品,更新商品和删除商品。

2.7.持久化
如何避免消息丢失?
1) 消费者的ACK机制。可以防止消费者丢失消息。
2) 但是,如果在消费者消费之前,MQ就宕机了,消息就没了。
是可以将消息进行持久化呢?
要将消息持久化,前提是:队列、Exchange都持久化


