
- 1SpringBoot整合Mybatis Bug已解决:The last packet sent successfully to the server was 0 milliseconds ago_mybatisplus hikaridatasource the last packet sent
- 2ROS+VSCODE 调试 保姆级教程_ros vsocde 调试
- 3PTA L1-064 估值一亿的AI核心代码 (20分)_7-2 估值一亿的ai核心代码 分数 20 作者 陈越 单位 浙江大学 ai.jpg 以上图片来自
- 4aardio的gdip基础绘图练习实例_aardio 画线
- 5JAVA数据处理(实现7种排序算法)_java各种排序算法实现
- 6数据仓库模型ETL架构(DWI/DWR/DM)
- 7[Leetcode]第一题:两数之和_leetcode第一题两数之和从文件中读取数据
- 8Web安全漏洞——文件上传(fileupload)_方法[upload]中包含可用于处理上传文件的参数,攻击者可能通过向服务器环境引入恶
- 9如何用Python画坤坤?_蔡徐坤代码python
- 10MySQL数据库的备份与恢复_mysqldump恢复数据库
【Flink】Flink 流批 一体 下 新的 Connector_flink connector
赞
踩

1.概述
出自:
作者: 任庆盛
阿里巴巴研发工程师

Flink 的数据重要的来源和去向
连接器是 Flink 与外部系统间沟通的桥梁。 如: 我们需要从 Kafka 里读取数据, 在 Flink 里把数据处理之后再重新写回到 HIVE、 elastic search 这样的外部系统里去
- 处理流程中的事件控制: 事件处理水印(watermark), 检查点对齐记录。
- 负载均衡: 根据不同并发的负载对数据分区进行合理的分配。
- 数据解析与序列化: 我们的数据在外部系统里可能是以二进制的形式存储的, 在数据库里可能是以各种列的形式来存储的。 我们再把它读到 Flink 里后, 需要对他进行一个解析, 之后才能够进行后面的数据处理。 所以我们同样在写回外部系
统的时候也需要对数据进行一个序列化的操作-把它转换成外部系统里对应的存储格式来进行存储。
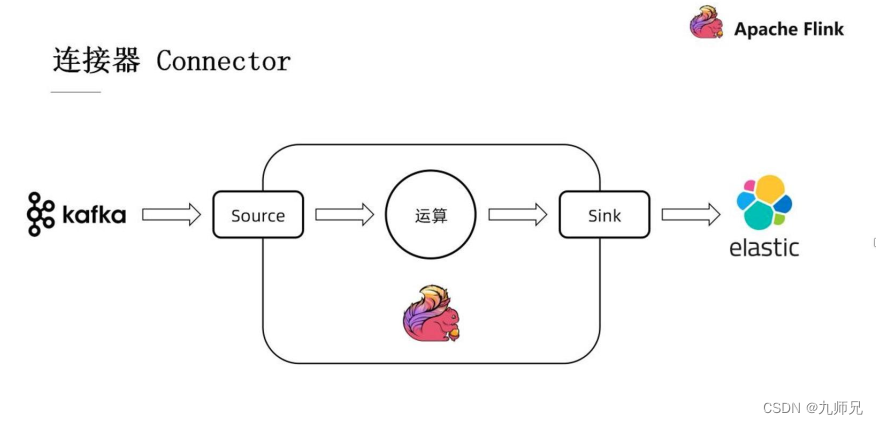
上图显示的是一项十分典型的例子。
我们首先从 kafka 里通过 Source 读取其中的部分记录。 然后把这些记录送到Flink 当中的一些算子进行对应的运算, 再通过 Sink 写出到 elastic search 当中去, 所以 Source 和 Sink 在这个 Flink 作业的两端起到了一个接口的作用
2.Source API- Flink 数据的入口
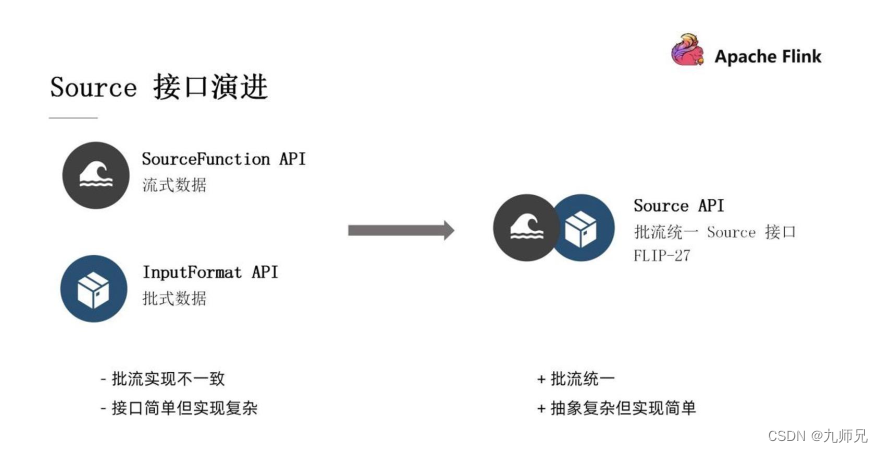
Source 在 Flink 1.10 版本之前是左侧的这两个接口: SourceFunction API(用来处理流式数据) , InputFormat API( 用来处理批式数据) 。 在 Flink 1.10 之后,社区引入了一个新的 Source API, 对整个的 Source 进行了重构。 那么为什么我们社区要做这样的一个工作呢?
批流实现不一致: 生态不断壮大的过程中, 旧的 API 暴露出来一些问题。 其中最直观的问题就是批流实现的不一致。
接口简单但实现复杂: 之前的 API 可能接口实现比较简单, 但实际上对于开发者来讲, 在实现这个接口的时候, 所有的逻辑、 所有的操作实现起来是非常复杂的, 对于开发者来讲也不够友好。
因此, 基于这些问题, 在 FLIP-27 中提出了一个新的 Source API 的设计。 其特点有二:
- 批流统一: 流式数据处理和批式数据处理不需要再维护两套代码, 用一套代码就够了。
- 实现简单: Source API 定义了很多概念上的抽象, 虽然说这些抽象看起来会比较复杂, 但是实际上是简化了开发者操作的开发者开发工作。
2.2 核心抽象

1) 记录分片(Split
有编号的记录集合
以 Kafka 来举例子。 Kafka 的分片既可以定义成一整个分区, 也可以定义成一个分区里的某一部分。 比如说我从 offset 为 100 的数据开始消费, 到 200 号之间我们定义为一个分片; 201~300 定义成另外一个分片, 这样也是可以的。 只要他是一个记录的集合、 我们给他一个唯一的编号, 我们就可以定义这样的一个记录分片。
进度可追踪
我们需要在这个分片当中记录现在处理到了哪一个位置, 我们在记录检查点的时候需要知道当前处理了哪些东西, 便于一旦出现了故障, 可以直接从故障中恢复起来。
记录分片的所有信息
以 Kafka 举例来讲, 一个分区的起始和终止位点等信息是都要包含在整个记录分片里的。 因为我们在做 Checkpoint 的时候也是以记录分片为单位的, 所以说记录分片里的信息也应该是自洽的
2) 记录分片枚举器(Split Enumerator)
发现记录分片: 检测外部系统中所存在的分片
分配记录分片: Enumerator 是处于一个协调者的角色存在的。 它需要给我们的Source 读取器分配任务。
协调 Source 读取器: 例如某些读取器的进度可能太快了, 此时便要告诉他稍微慢一点儿来保证 watermark 大致是一致的。
3) Source 读取器(Source Reader)
从记录分片读取数据: 根据枚举器分配的记录分片来读取数据
事件时间水印处理: 需要从我们从外部系统中读下来的数据里提取事件时间, 然后做出对应的水印发送的操作。
数据解析: 对从外部系统中读取到的数据进行反序列化, 发送至下游算子
2.3 枚举器-读取器架构
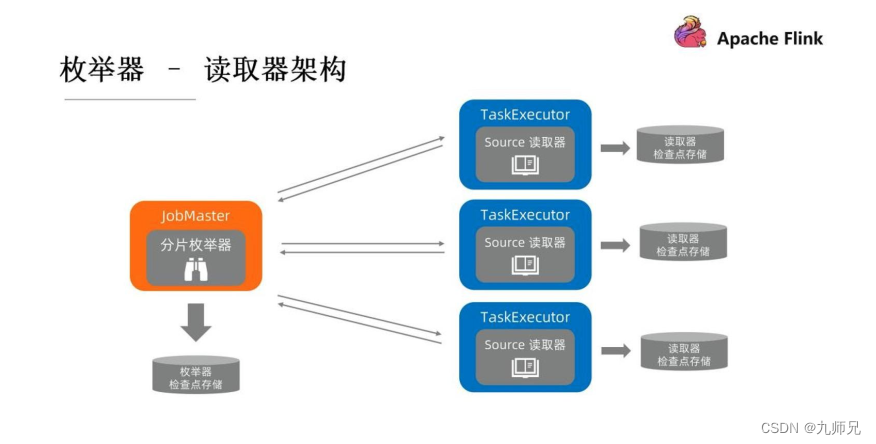
分片枚举器是运行在 Job Master 上面的, Source 读取器是运行在 Task Executor 上面的。 因此, 枚举器是领导者、 协调者的角色, 读取器是执行者的角色。他们的检查点存储也是各自分开的, 但之间会存在一些通信。 比如说枚举器是需
要给读取器来分配任务, 也要通知读取器后续没有更多的分片需要处理。 由于一个运行环境不一样, 他们两个之间也不可避免地会存在一些网络通信。 便有了如下通讯栈的定义。
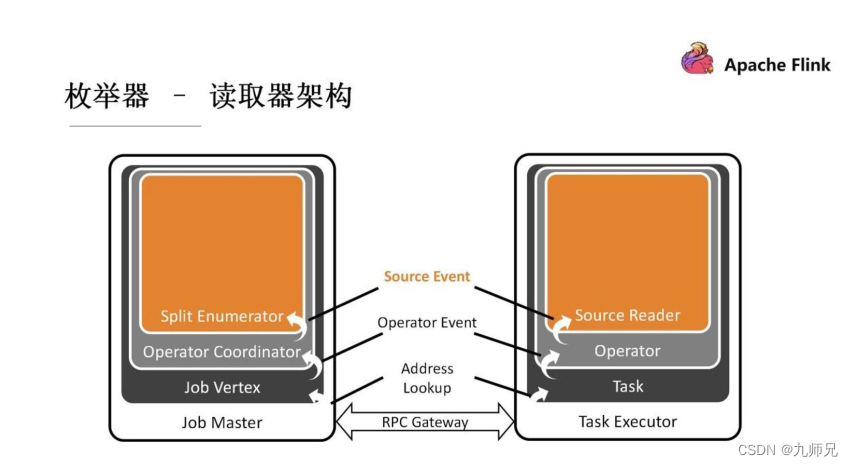
这个通讯栈上面确定了一些 event 来提供给开发者进行自己的实现。
首先, 最上面这层是 Source Event, 留给开发者自己去定义一些客户化的操作。比如假使现在设计的一个 Source, 可能 reader 在某些条件下可能要暂停读取, 那么 SplitEnumerator 可以通过这种 Source event 的方式发送给 Source Reader。
其次, 再下面一层分别是叫 Operator Coordinator, 算子的协调者。 它和真正去执行任务的算子通过 Operator Event 算子事件进行沟通的。 我们已经事先定义好了一些算子事件, 如添加分片、 通知我们的 leader 没有新的分片了等。 这些对于所有的 Source 都通用的事件, 是在 Operator Event 这一层来进行抽象的。
Address Lookup 是用来定位消息应该发送给哪一个 Operator 的。 因为 Flink整个作业执行起来后会有一个加一个有向无环图的。 不同的算子可能运行在不同的Task Manager 上面, 那么怎么去找到对应的 task、 对应的算子便是这一层的任务。
由于网络通信的存在, Job Master 和 Task Executor 之间有一个 RPCGateway。 所有的 Event 最终都会通过 RPC Gateway、 通过 RPC 调用的方式来进行网络传输。
2.4 Source 读取器设计
为了简化 Source 读取器实践步骤, 减少开发者工作, 社区已经为大家提供了 SourceReaderBase。 用户在开发的时候可以直接继承 SourceReaderBase 类, 从而大大简化开发者的一些开发工作。 那么我们接下来对 SourceReaderBase 进行分析。看上去好像这张图里有非常多的组件, 但实际上我们可以把它拆成两部分来理解。
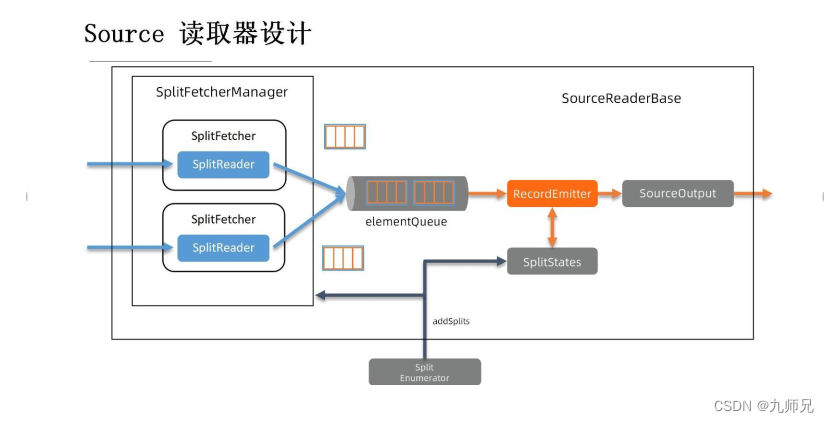
以中间 elementQueue 队列作为界限, 队列左侧用蓝色标出来的部分是需要和外部系统打交道的组件, 在 elementQueue 的右侧用橙色标出来的部分是和 Flink的引擎侧打交道的部分。
首先, 左侧是由一个或者是多个分片的读取器构成的, 每一个 reader 通过一个Fetcher 来驱动, 多个 Fetcher 会统一由一个 Fetcher Manager 来管理。 这里的实现也有非常多种, 比如说可以只开一个线程、 只开这一个 SplitReader, 通过这一个
读取器来消费多个分区。 此外, 我们也可以根据需求, 开多个线程-一个线程运行一个feature, 进行一个 reader, 每个 reader 负责一个分区来并行的去消费数据。 这些完全取决于用户的实现、 选择。
出于性能考虑, 每次 SplitReader 会从外部系统中取一批数据, 把它们放到elementQueue 里。 如图所示, 在这个蓝色框子里的是每次取下来的一批数据, 而后橙色框是这一批数据下面的每条数据。
其次, elementQueue 的右侧是由 RecordEmitter 和 SourceOutput 组成的。RecordEmitter 把每条记录发送给下游的另外一个 SourceOutput 会把记录输出出去。 每次 RecordEmitter 会从中间 elementQueue 里拿一批数据下来, 把它们一条
一条发送到下游。 由于 RecordEmitter 是由主线程来驱动的, 该主线程现在的设计里是用了一个无锁的 mailbox 模型, 它会把需要执行工作分成一个一个 mail, 每次工作线程从 mailbox 里取出来一个 mail 然后来进行工作, 所以我们应该注意, 这里的实现一定要是无阻塞的。
RecordEmitter 每次往下游发送数据的同时会向下游汇报-后面会不会还有后续的数据需要处理。 与此同时呢, 我们也会把当前这个分片的处理进度记录在 SplitStates当中, 记录它当前的状态、 处理到了什么位置。
当 SplitEnumerator 在外部系统当中发现了新的分片, 它需要通过 RPC 调用addSplits 方法将新的分片添加读取器。 在 SplitFetchermanager 这一侧会根据之前用户已经选定的线程模型把新分片分配出去(如只有一个线程, 那便会给这个线程分
配一个新任务, 再让 reader 去读取这个新的分片。 如果整体是多线程的实现的, 那便新建一个线程, 新建一个 reader 来单独去处理分片。 同样我们也要在 SplitStates中记录当前处理的这个进度是怎么样的。
2.5 创建检查点
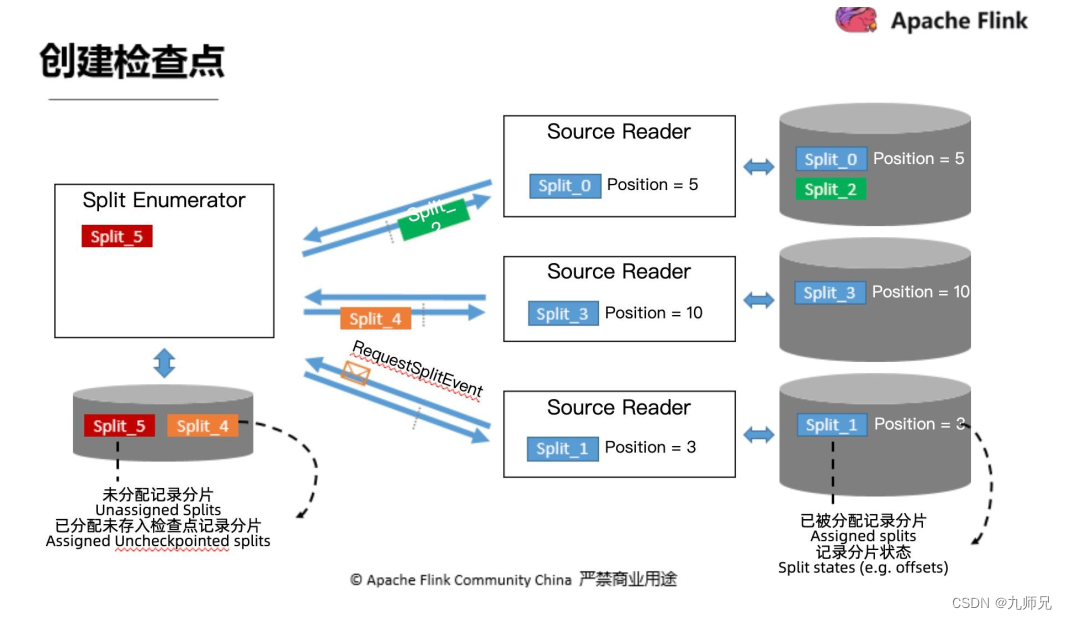
接下来我们来看一下在新的 Source API 当中是怎么处理检查点的。
首先, 左侧我们的协调者, 分片枚举器。 图中所示, 它目前手中还有一个分片(Split_5) 没有分配出去。 中间箭头部分是正在传输路上的一些分片。 虚线是这个检查点的边界。 我们可以看到二号分片已经在检查点前面了, 四号分片在检查点后面,最下方的 reader 正在向 SplitEnumerator 请求一个新的分片。 再看 reader, 三个reader 分别已经分配到了某一些 Split、 也进行了一些处理, 已经有 Position 了。
那我们分别来看一下枚举器和读取器需要在检查点的时候存储哪些东西?
- 枚举器: 未分配记录分片(Split_5) , 已分配未存入检查点记录分片(Split_4)
- 读取器: 已被分配记录分片(Split_0,1,3) , 记录分配状态(Split_2)
2.6 三步简单实现 Source
1) Split/SplitState
Split: 外部系统分片
SplitSerializer: 序列化/反序列化 Split 传递给 SourceReader
SplitState: Split 状态, 用于 Checkpoint 与恢复
2) SplitEnumerator
发现与订阅 Split
EnumState: Enumerator 的状态, 用于 Checkpoint 与恢复
EnumStateSerializer: 序列化/反序列化 EnumState
3) SourceReader
SplitReader: 与外部系统进行数据交互的接口
FetcherManager: 选择线程模型(目前已有)
RecordEmitter: 转换消息类型与处理事件时间
如果我们仔细去想一下就会发现, 其实这些东西绝大多数都是和外部系统打交道的, 也就是说和 Flink 引擎本身打交道的部分很少, 用户不再需要去担心 checkpoint锁的问题, 多线程的问题等等, 能够把更多的开发精力来集中在开发和外部系统交互的部分上。 所以说, 新的 Source API 是通过这些抽象来大大地简化了开发者的开发。
3.Sink API- Flink 数据的出口
如果对 Flink 有一定的了解的话会发现它可以做到精确一次的语义, 数据既不重复也不丢失。 那么为了实现这个“精确一次” Flink 也做了很多的工作, 其中非常重要的一点就是在 Sink 端实现了二阶段提交。
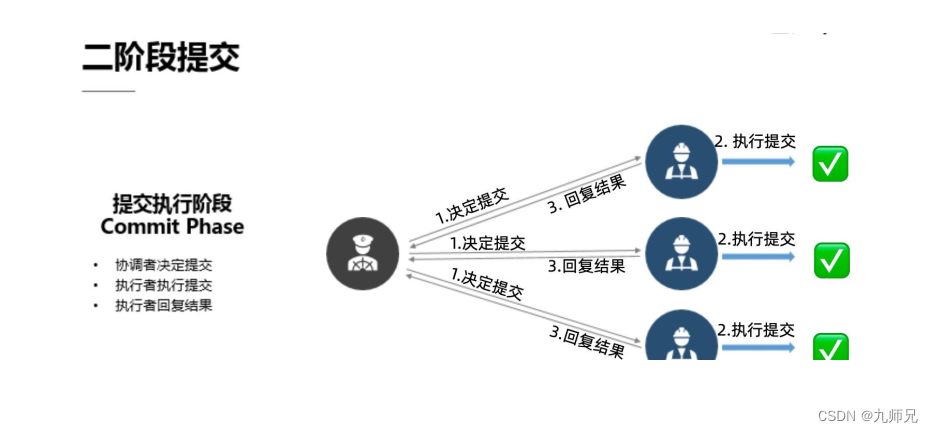
3.1 一) 预提交阶段
在预提交阶段里, 由于我们的这个分布式系统一般是存在这种“协调者 1+执行者 n” 的模式, 那么在预提交的预提交阶段里, 首先我们的协调者是需要请求提交的, 也就是说他需要给所有的执行者来发送请求提交的消息, 从而来开始整个的二阶
段提交。
当执行者收到了请求提交的消息, 他会做一些提交的准备工作。 在所有的准备工作都做完之后, 他所有的执行者会向这个协调者回复说明现在已经准备好进行下一步的提交工作了。 当协调者收到了所有执行者的“可继续” 请求后, 预提交阶段结束,
进入我们提交第二阶段-提交执行阶段。
3.2 (二) 提交执行阶段
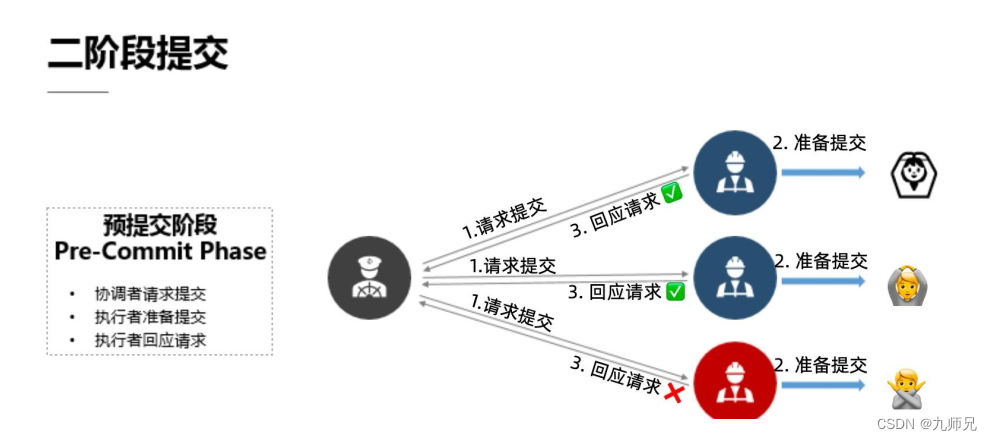
提交者会向执行者发送决定提交的消息, 执行者会把刚刚准备好的提交相关的东西来进行一个处理, 来真正的去执行一个提交的动作。 在完成之后会向协调者汇报一个回复的结果, 反馈提交是否正常执行。
一旦协调者决定进入第二个提交执行阶段, 所有的执行者必须要不打折扣地把命令执行下去。 也就是说如果某个协调者在这一阶段出了问题的话, 他在恢复起来之后还是要把这个决定执行下去的。 也就是说一旦决定提交, 执行者便必须要把提交这一个动作贯彻下去。
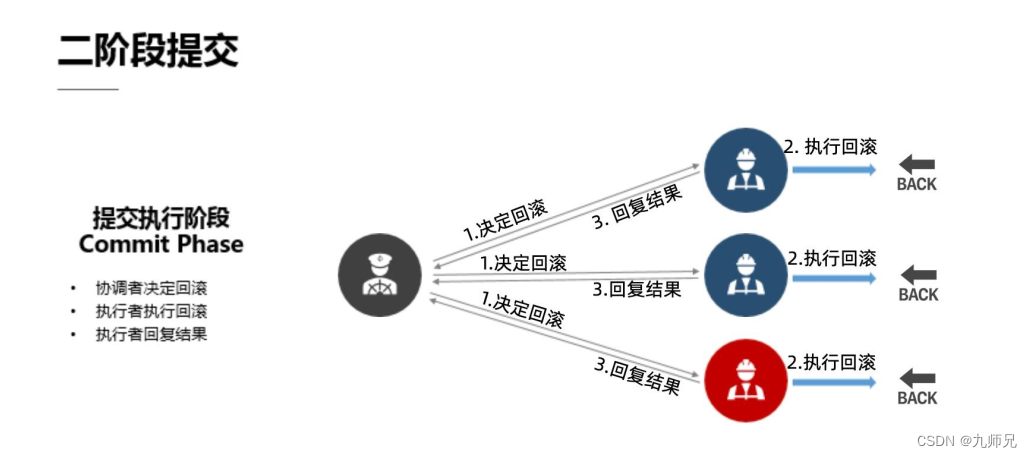
如果在预提交阶段某一个执行者准备提交的时候可能出现了一些故障等、 没有做正确的提交动作, 那么他可能向协调者会回应了一个错误, 比如网络断了, 也可能经过一段时间超时之后协调者没有收到这个三号执行者的回应请求, 那么协调者就会触发第二阶段的回滚动作。 也就是会告诉所有的执行者“这次提交尝试失败了, 需要大家回滚到之前的状态” 。 而后我们的执行者便会出现一个回滚动作, 撤销上一步操作。
3.3 (三) 二阶段提交在 Flink 中的做法
1) 预提交阶段

以这个文件系统的 Sink 来举个例子。
文件系统的 Sink 在接收到了检查点边界之后做预提交动作(把当前的数据落盘写到硬盘上的某一个临时文件里) , 当预提交阶段完成之后, 所有的 operator 会向我们的协调者回复 “已经准备好进行提交” 的信息。
2) 提交执行阶段
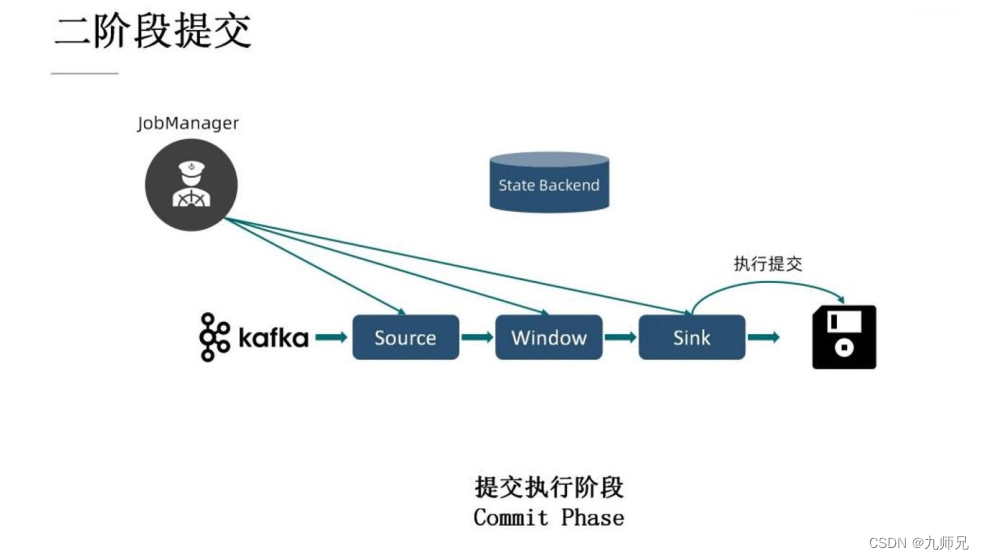
第二个阶段, 提交执行阶段开启。 JobManager 会向所有的算子发送提交执行的指令, Sink 在接收到这个指令之后, 便会真正的去做最后的提交动作。
我们还是以文件系统来来举例子, 那么刚刚我们已经说过了, 在预提交的阶段数据被写到了一个临时文件里, 那么在真正的进行提交的时候, 临时文件会被按照我们事先定义好的这个名字规范重命名, 相当于实现了提交。
这里要注意, 临时文件这一设置并非无用, 它对后续可能发生的回滚等状况具有铺垫性的作用。 我们是巧妙利用了二阶段提交的机制来保障精确一次的语义。
3.4 (四) Sink 模型

Writer: 负责在写入或预提交的阶段, 把上游源源不断的数据写到中间的某一个状态里去。
Committable: 上述所说的“中间的状态” , 是可以进行这个提交操作的元件
Committer: 把 Committable 真正的去提交上去
Global Commiter: 全局提交器。 这个组件是可选的、 取决于你的外部系统。例: Iceberg
4.、 未来发展

完善新 Source
因为 Source 和 Sink 刚刚推出不久, 所以说相对来讲还是存在一些问题的。 有些开发者可能会有一些新的需求、 需要新的更新与提升。 目前已经算一个相对稳定的状态, 但还是需要去不断地完善。
迁移现有连接器至新 API
随着流批一体连接器的不断推进, 所有的连接器会迁移到新的 API 上。
连接器测试框架
连接器测试框架尝试去给所有的 connector 提供一个相对来讲比较一致、 统一
的测试标准。 测试开发者不再需要去自己写一些 case、 考虑各种各样的测试环境、
试场景等等。 让我们的开发者能够像搭积木一样快速地用不同的场景, 不同的用例来
测试自己的代码, 从而把更多的开发精力集中在开发这个本身的逻辑上面, 大大减少
开发者的测试负担。 这也是 Source API, Sink API 和后续的 framework 研发的一致
目标。 是为了让连接器开发更加简单、 门槛更低, 从而吸引更多的开发者为 Flink 生

