
- 1普通二本,去过阿里外包,到现在年薪40W+的高级测试工程师,我的两年转行心酸经历..._二本去阿里巴巴外包项目
- 2智能革命:未来人工智能创业的天地
- 3软件测试工程师应该如何做职业规划?
- 4模拟退火算法求解TSP问题-python实现_tsp退火算法python
- 5[鹤城杯 2021]Middle magic
- 6php json decode 数组,php使用json_decode将json转换为数组
- 7【智能家居】6、语音控制及网络控制代码实现_c语言语音控制
- 8歪说软件工程28篇
- 9【剑指Offer】删除链表的节点
- 10【软件测试面试题】offer又失之交臂?项目经验项目描述看这个篇就够了_软件测试面试题项目业绩
音视频开发之旅(72)- AI数字人-照片说话之SadTalker_3d口型、表情、肢体驱动 ai
赞
踩
目录
1.效果展示
2.SadTalker原理学习
3.SadTalker代码流程分析
4.性能优化
5.参考资料
AI数字人目前做的最好的无疑是heygen,但是费用也是很贵,也有一些其他的商业应用,比如:微软小冰、腾讯智影、万兴播爆和硅基智能等。
而开源的方案也是层出不穷,比如:wav2lip、sadtalker、genfaceplusplus和videoRetalker,就在这两天 阿里的EMO也发布了一些效果视频也是相当不错,尚未开源。
今天我们来学习分析下Sadtalker。这里涉及到很多技术点:文字转语音、图像识别、音频驱动口型和肢体联动以及视频合成等
一、效果展示
普通话版
东北版
粤语版
河南版
生成步骤:
使用Stablediffusion文生图生成虚拟人物照片
准备文本内容,把内容使用文字转语音
使用音频驱动照片嘴唇和表型等变化生成视频
二、SadTalker原理学习
在制作会说话的头像(Talking Head Generation)时,会面临一些挑战,比如头部运动不自然、面部表情扭曲,甚至人物的身份似乎发生了变化。这些问题通常是由于直接从二维图像中学习头部和面部的运动,而这些二维图像中的运动信息是复杂相互关联的。同样,即使使用三维信息,也可能会遇到表情僵硬和视频不连贯的问题。
为了解决这些问题,西安交通大学的研究人员提出了SadTalker模型。这种方法首先生成了一个三维的脸部模型(3DMM),这个模型包括头部的姿势和表情等系数。然后,利用三维面部渲染器来生成视频。为了让生成的面部运动更加真实,研究者探索了音频和不同类型的面部运动系数之间的联系。他们设计了ExpNet网络,通过观察三维渲染的人脸来学习如何产生准确的面部表情。同时,为了生成多样化的头部动画,还设计了PoseVAE网络来生成不同风格的头部动画。最后,将生成的3DMM系数映射到面部渲染器的三维关键点空间,以生成最终的视频。
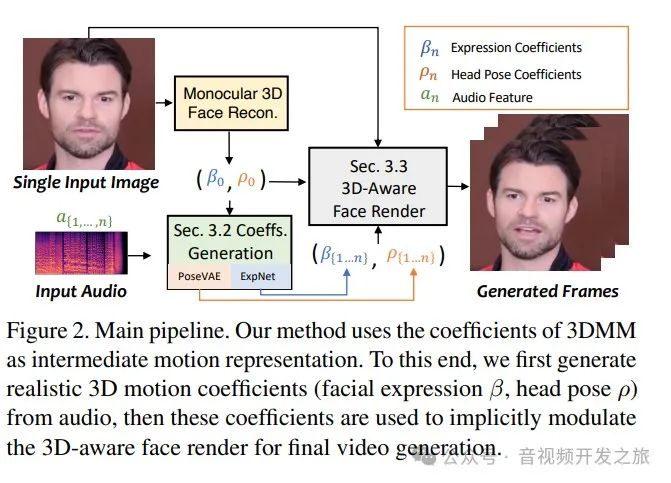
图片来自:https://arxiv.org/pdf/2211.12194.pdf
2.1 表情系数 ExpNet
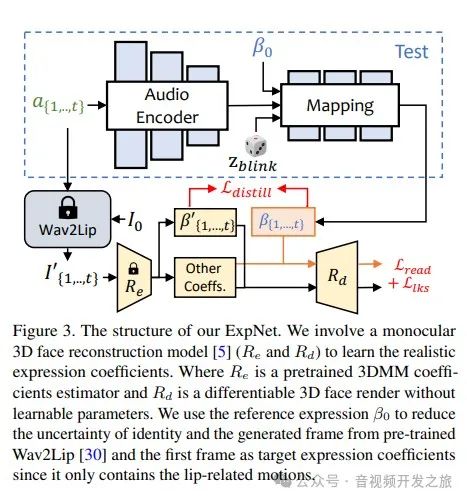
图片来自:https://arxiv.org/pdf/2211.12194.pdf
对于一段音频,首先生成t帧表情系数,其中每个帧的音频特征就是0.2s的梅尔频谱。训练时,利用一个基于ResNet的音频编码器映射到一个隐空间,然后线性层作为一个映射网络解码表情系数。为了保证个人特征,通过第一帧的表情系数建立表情和特定人的身份进行关联;为了减少在说话时其他面部成分的表情的权重,利用预训练的Wav2lip生成的嘴唇运动系数作为target
2.2 头部姿势 PoseVAE
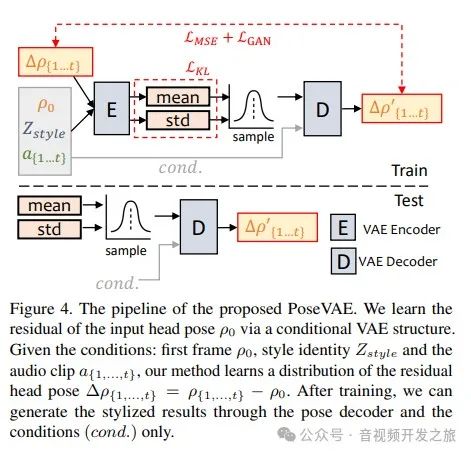
图片来自:https://arxiv.org/pdf/2211.12194.pdf
PoseVAE没有直接生成姿势,而是学习与第一帧姿势 ρ0之间的残差,这使本方法能够在测试阶段中基于第一帧条件下的生成更长、稳定和连续的头部运动
2.3 3D-aware面部渲染
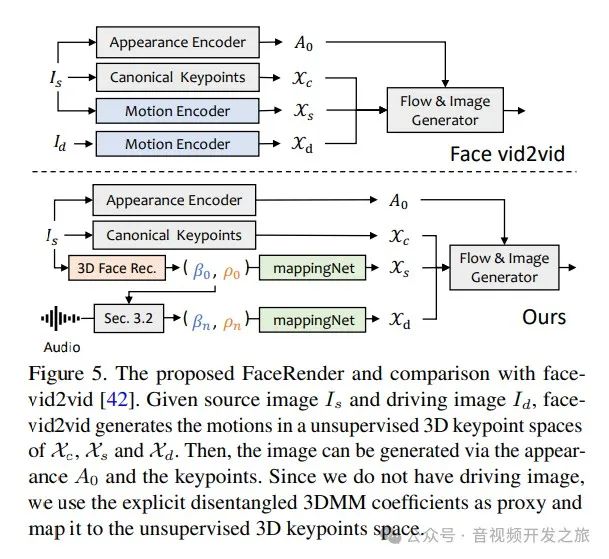
图片来自:https://arxiv.org/pdf/2211.12194.pdf
face-vid2vid需要真实视频作为驱动信号,而研究者提出的面部渲染器利用3DMM参数进行驱动,通过mappingNet来学习3DMM运动系数(头部姿势和表情)和3D关键点之间的关系
三、SadTalker代码实现分析
3.1. 模型初始化
preprocess_model:用于将人脸从图像中裁剪出来,并提取人脸的关键点以及3DMM形态模型
audio_to_coeff:将音频转换为控制面部表情特别是唇部运动的系数
animate_from_coeff: 根据上面两个模型数据生成最终的面部动画
#将人脸从图像中裁剪出来,并提取人脸的关键点以及3DMM形态模型self.preprocess_model = CropAndExtract(path_of_lm_croper, path_of_net_recon_model, dir_of_BFM_fitting, self.device)#将音频转换为控制面部表情特别是唇部运动的系数self.audio_to_coeff = Audio2Coeff(audio2pose_checkpoint, audio2pose_yaml_path, audio2exp_checkpoint, audio2exp_yaml_path, wav2lip_checkpoint, self.device)#生成口型动画视频self.animate_from_coeff = AnimateFromCoeff(free_view_checkpoint, mapping_checkpoint, facerender_yaml_path, self.device)3.2. 处理流程
#3DMM Extractionfirst_coeff_path, crop_pic_path, crop_info = self.preprocess_model.generate(pic_path, first_frame_dir, self.preprocess)
batch = get_data(first_coeff_path, audio_path, self.device, ref_eyeblink_coeff_path, still=still)coeff_path = self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path)
data = get_facerender_data(coeff_path, crop_pic_path, first_coeff_path, audio_path, batch_size, input_yaw_list, input_pitch_list, input_roll_list, expression_scale=expression_scale, still_mode=still, preprocess=self.preprocess) return_path = self.animate_from_coeff.generate(data, save_dir, pic_path, crop_info, \ enhancer=enhancer, background_enhancer=background_enhancer, preprocess=self.preprocess)3.2.1 preprocess_model.generate
主要用于从视频帧中裁剪出人脸,并提取面部关键点和3DMM(三维形态模型)参数
#内部通过dlib进行人脸检测 获取人脸68个关键点,并提取面部关键点和3DMM(三维形态模型)参数x_full_frames, crop, quad = self.croper.crop(x_full_frames_before, still=True, xsize=pic_size)clx, cly, crx, cry = croplx, ly, rx, ry = quadlx, ly, rx, ry = int(lx), int(ly), int(rx), int(ry)oy1, oy2, ox1, ox2 = cly+ly, cly+ry, clx+lx, clx+rxcrop_info = ((ox2 - ox1, oy2 - oy1), crop, quad)
#get the landmark according to the detected facelm = self.kp_extractor.extract_keypoint(frames_pil, landmarks_path)
# load 3dmm paramter generator from Deep3DFaceRecon_pytorchsavemat(coeff_path, {'coeff_3dmm': semantic_npy, 'full_3dmm': np.array(full_coeffs)[0]})3.2.2 audio_to_coeff.generate
用于根据音频进行 表情系数和 头部姿态参数 的预测
#sadtalker/src/test_audio2coeff.py
exp_pred = results_dict_exp['exp_coeff_pred'] results_dict_pose = self.audio2pose_model.test(batch) pose_pred = results_dict_pose['pose_pred']
coeffs_pred = torch.cat((exp_pred, pose_pred), dim=-1) #bs T 70coeffs_pred_numpy = coeffs_pred[0].clone().detach().cpu().numpy() savemat(os.path.join(coeff_save_dir, '%s.mat'%(batch['pic_name'])), {'coeff_3dmm': coeffs_pred_numpy})3.2.3 animate_from_coeff.generate 驱动人脸渲染
根据3dmm人脸模型数据以及音频驱动口型数据和关键点信息等 生成视频帧
生成256x256的人头口型说话视频、对音频进行重采样到16000,然后合并音轨和视轨
把裁剪人脸的生成的对口型视频再贴回到全身图生成全身视频
对人脸和背景进行画质增强或超分
#sadtalker/src/facerender/animate.pydef generate(self, x, video_save_dir, pic_path, crop_info, enhancer=None, background_enhancer=None, preprocess='crop'): #根据3dmm人脸模型数据以及音频驱动口型数据和关键点信息等 生成视频帧 predictions_video = make_animation(source_image, source_semantics, target_semantics, self.generator, self.kp_extractor, self.he_estimator, self.mapping, yaw_c_seq, pitch_c_seq, roll_c_seq, use_exp = True) predictions_video = predictions_video.reshape((-1,)+predictions_video.shape[2:]) predictions_video = predictions_video[:frame_num] ### the generated video is 256x256, so we keep the aspect ratio, #生成256x256的人头口型说话视频 imageio.mimsave(path, result, fps=float(25)) #对音频进行重采样到16000 sound = AudioSegment.from_mp3(audio_path) frames = frame_num end_time = start_time + frames*1/25*1000 word1=sound.set_frame_rate(16000) word = word1[start_time:end_time] word.export(new_audio_path, format="wav") #合并音轨和视轨 save_video_with_watermark(path, new_audio_path, av_path, watermark= None) #把裁剪人脸的生成的对口型视频再贴回到全身图生成全身视频 paste_pic(path, pic_path, crop_info, new_audio_path, full_video_path) #对人脸进行画质增强 enhanced_images = face_enhancer(full_video_path, method=enhancer, bg_upsampler=background_enhancer)四、性能优化
4.1 工程优化
4.1.1 处理速度慢
通过上面的代码分析,主要流程有三步:
人脸关键点检测&3DMM形态模型提取;根据音频进行 表情系数和 头部姿态参数;人脸渲染视频生成
其中最主要耗时有三块:FaceRender(人脸渲染)、seamlessClone(把人脸“贴回”原图)、画质增强
face render可以通过设置batch_size加快,batchsize从默认值2增加到4,人脸渲染时间降低2s,但gpu翻倍,如果gpu资源足够的话可以增加batchsize,否则就不要修改.
seamlessClone 驱动口型动的是256*256的人头区域,最终想输出full的视频,需要把上面的头部视频加上mmmmmmmmmmmmmmmmbn 原始图片根据mask和location进行合并成新的视频,这个可以优化,通过线程池进行加速,耗时可以从40s减少到20s
```#src/utils/paste_pic.py
修改如下# tmp_path = str(uuid.uuid4())+'.mp4'
# out_tmp = cv2.VideoWriter(full_video_path, cv2.VideoWriter_fourcc(*'MP4V'), fps, (frame_w, frame_h)) # for crop_frame in tqdm(crop_frames, 'seamlessClone:'): # p = cv2.resize(crop_frame.astype(np.uint8), (crx-clx, cry - cly))
# mask = 255*np.ones(p.shape, p.dtype) # location = ((ox1+ox2) // 2, (oy1+oy2) // 2) # gen_img = cv2.seamlessClone(p, full_img, mask, location, cv2.NORMAL_CLONE) # out_tmp.write(gen_img)
# 自定义修改开始 def process_image(crop_frame): p = cv2.resize(crop_frame.astype(np.uint8), (ox2-ox1, oy2 - oy1))
mask = 255*np.ones(p.shape, p.dtype) location = ((ox1+ox2) // 2, (oy1+oy2) // 2) gen_img = cv2.seamlessClone(p, full_img, mask, location, cv2.NORMAL_CLONE)
return gen_img tmp_path = str(uuid.uuid4())+'.mp4' out_tmp = cv2.VideoWriter(tmp_path, cv2.VideoWriter_fourcc(*'MP4V'), fps, (frame_w, frame_h))
processed_frames = [] # 存储处理后的图像
# 创建线程池 # 指定线程池的最大线程数 max_threads = 10
# 创建线程池并设置max_workers参数 with futures.ThreadPoolExecutor(max_workers=max_threads) as executor: # 提交任务并获取处理结果 processed_frames = [] for gen_img in tqdm(executor.map(process_image, crop_frames), total=len(crop_frames) ,desc='seamlessClone:'): processed_frames.append(gen_img)
# 一次将所有处理后的图像写入视频文件 for frame in processed_frames: out_tmp.write(frame) # 自定义修改结束```
感谢 https://github.com/OpenTalker/SadTalker/issues/520画质增强这块耗时暂时没有很好的优化方案
4.1.2 显存占用过多
如果是图片比较大,很容易爆显存,这是如果内存足够大的话,可以把在make_animation中把图片放到cpu,注意内存不要爆了。
另外可以对大图像进行resize进行输入
4.2 模型加速
使用 TensorRT 对 SadTalker 模型进行加速
修改 ONNX 模型,降低模型精度。float32 精度下加速效果不是很明显,可能只有 1.x 倍的提升,而在 fp16 精度下虽然有 2.5 倍的提升,但是生成的视频质量会有所下降
具体参考:SadTalker 模型加速方案 https://zhuanlan.zhihu.com/p/675551997
五、参考资料
1. 论文链接:https://arxiv.org/pdf/2211.12194.pdf
2. 【论文精读】 SadTalker:Stylized Audio-Driven Single Image Talking Face Animation https://blog.csdn.net/weixin_45508265/article/details/129756195
3. TensorRT 使用指南(4):SadTalker 模型加速方案 https://zhuanlan.zhihu.com/p/675551997
4. 【三种生成数字人的方法】 https://www.youtube.com/watch?v=fhkr202Hhu0&ab_channel=AI-Candy
感谢你的阅读
接下来我们继续学习输出AIGC相关内容,欢迎关注公众号“音视频开发之旅”,回复“AI数字人” 获取学习资料,一起学习成长。
欢迎交流

