
- 1字节测试岗面试挂在二面,我总结了失败原因,决定再战一次_字节测试二面
- 2各大互联网公司都有哪些部门?核心部门又是什么?一文全知道!
- 3各大互联网公司薪酬盘点!哪一家薪资最高?
- 4sql:建表删表语句,其中delete,truncate,drop区别_建表后truncate
- 5带你快速了解ISO27001信息安全管理体系认证_iso27001学习csdn
- 64x4矩阵键盘工作原理及扫描程序_小知识——矩阵键盘
- 7IntelliJ IDEA——Sonar Lint,Check Style, Find Bugs_sonarlint和findbugs
- 8系统安全和应用_应用系统安全
- 9python机器学习XGBoost梯度提升决策树的高效且可扩展实现
- 10爬虫原理(1)
深度学习系列26:transformer机制_transformer qkv
赞
踩
1. 引入attention
1.1 RNN结构的seq2seq模型
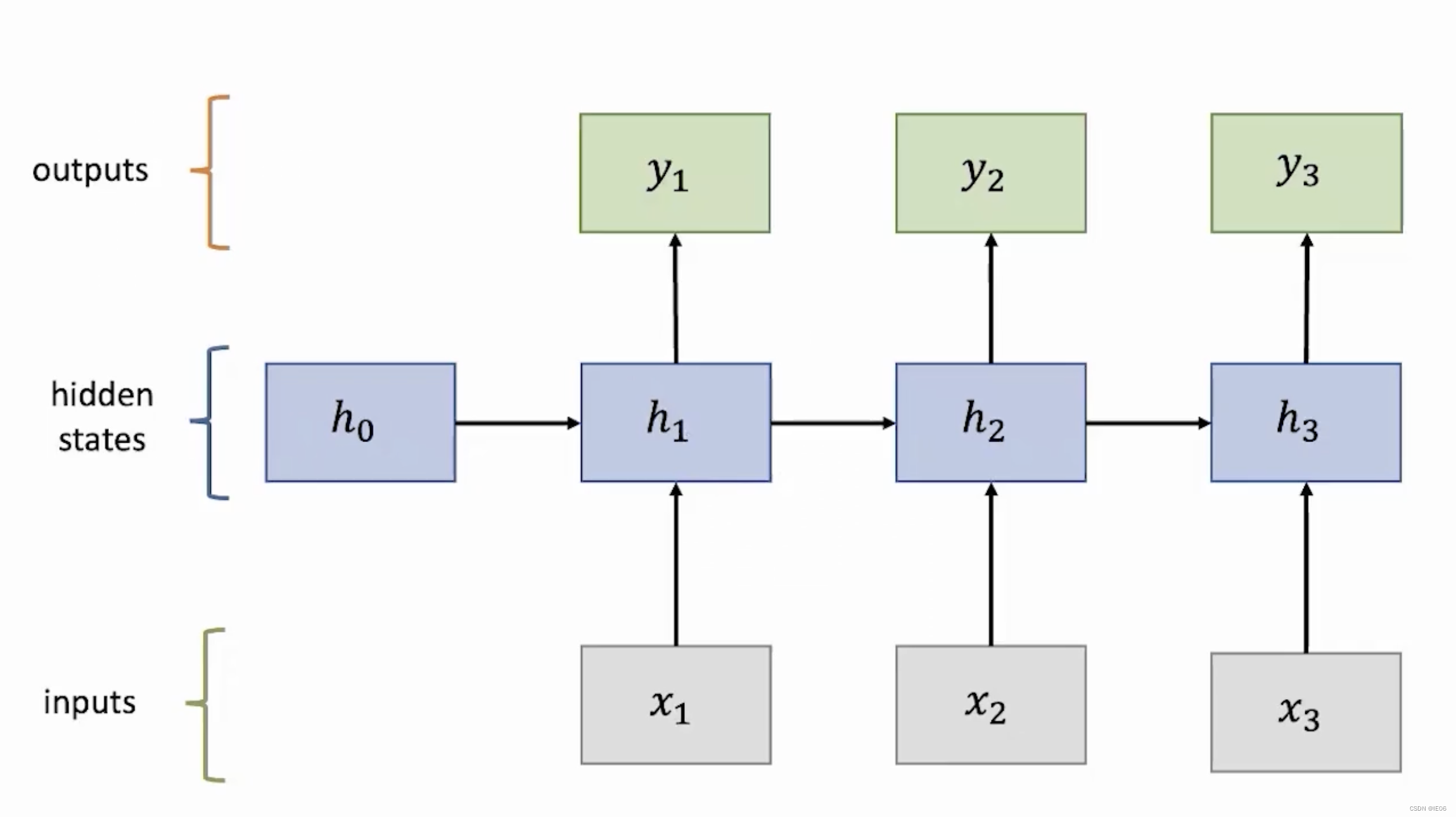
RNN的基本结构如下:
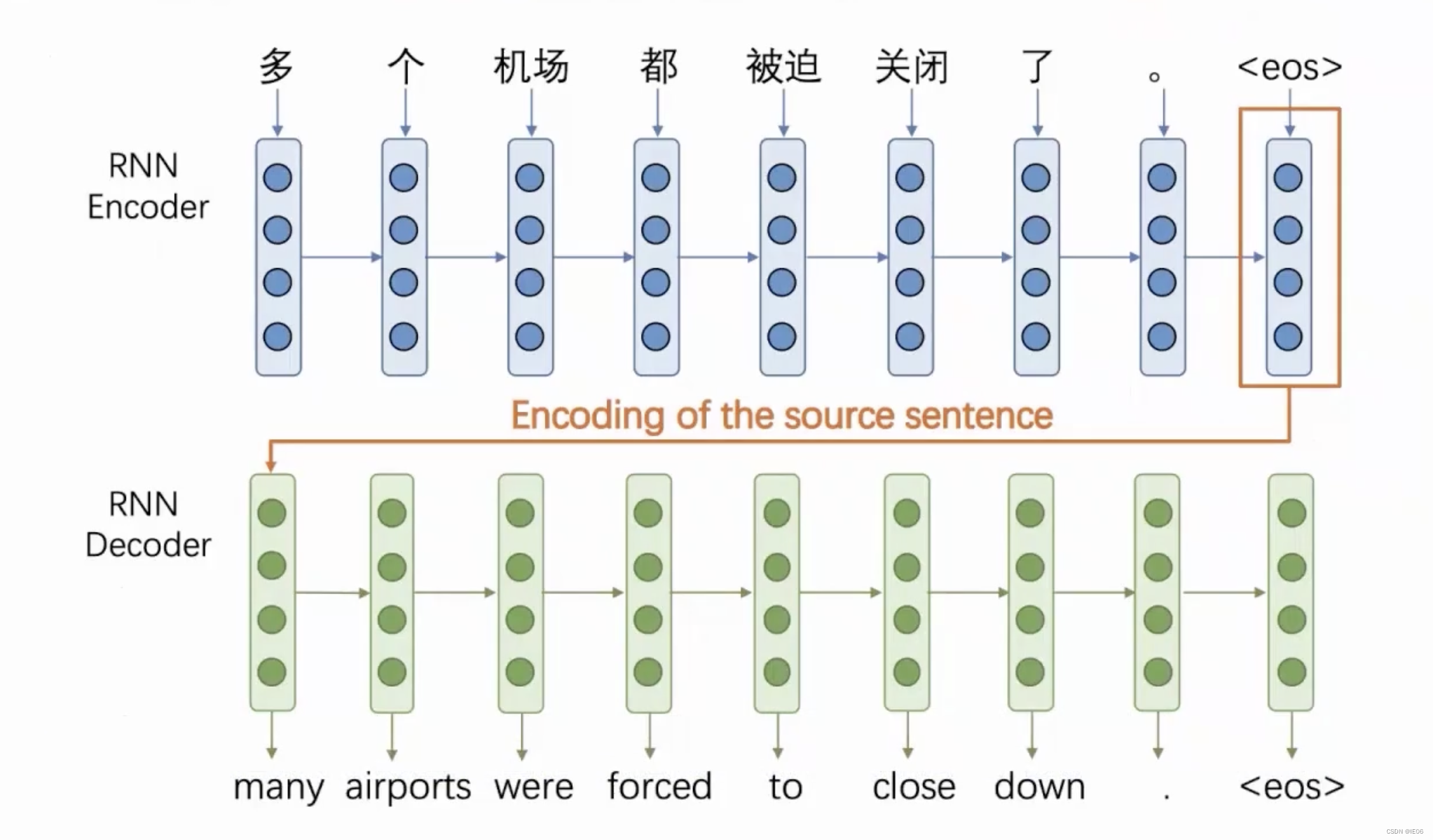
语言模型多是seq2seq任务,因此需要训练两个RNN:一个编码器和一个解码器:
传统深度学习方法存在无法感知远处context等问题,LSTM虽有所缓解,但并未彻底解决问题。因此目前主流是加入attention机制。
1.2 attention
如下图,我们在RNN encoder的基础上,加上一个注意力分数。encoder编码得到的最终结果s1被用来计算一个叫做注意力的向量,然后与s1再进行拼接。注意力机制告诉decoder,在当前阶段需要关注什么位置的输入。例如在下面的例子中,整个句子翻译的第一步关注的是多和个两个单词,因此输出结果为many;第二部关注机场这个单词,因此输出结果为airport。
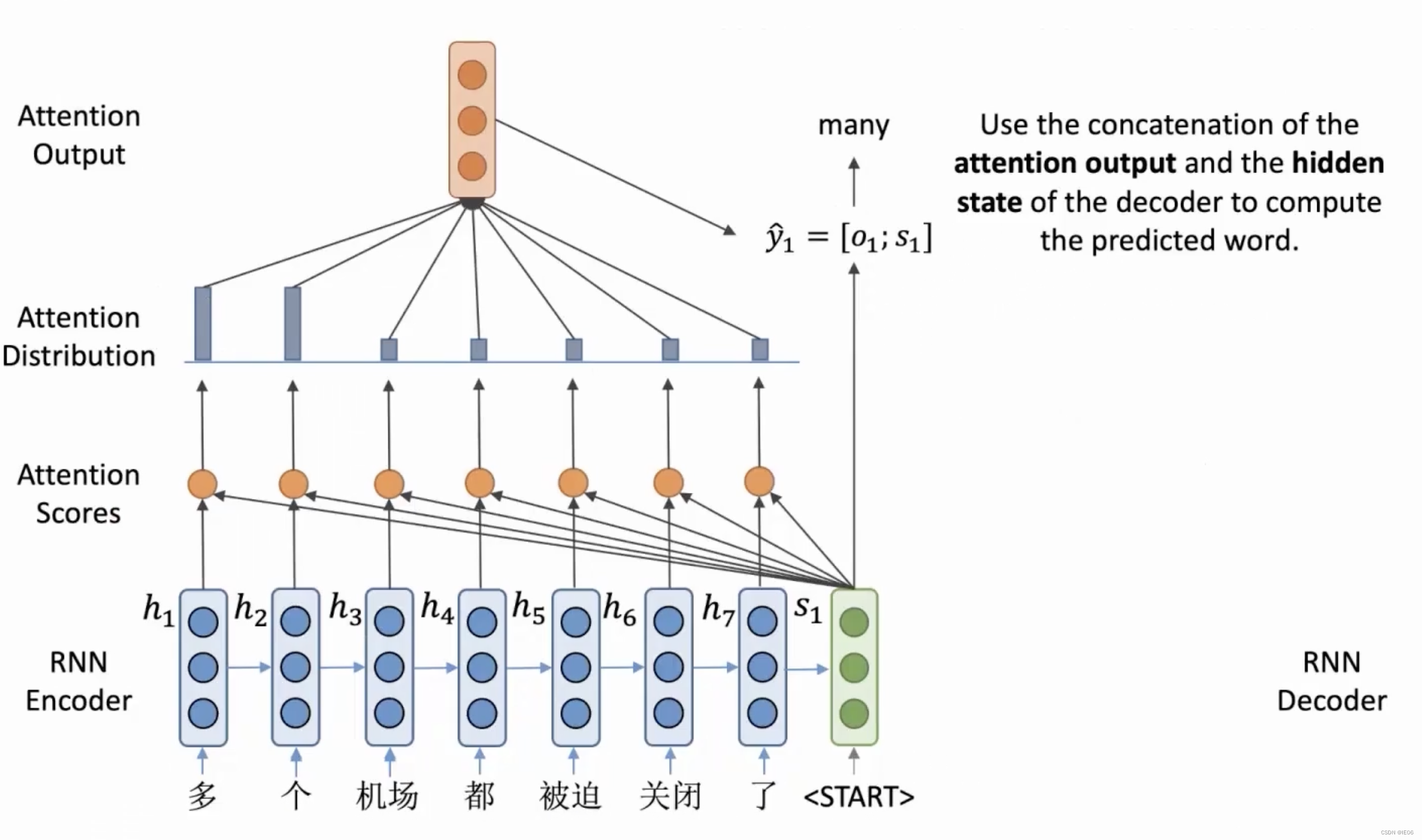
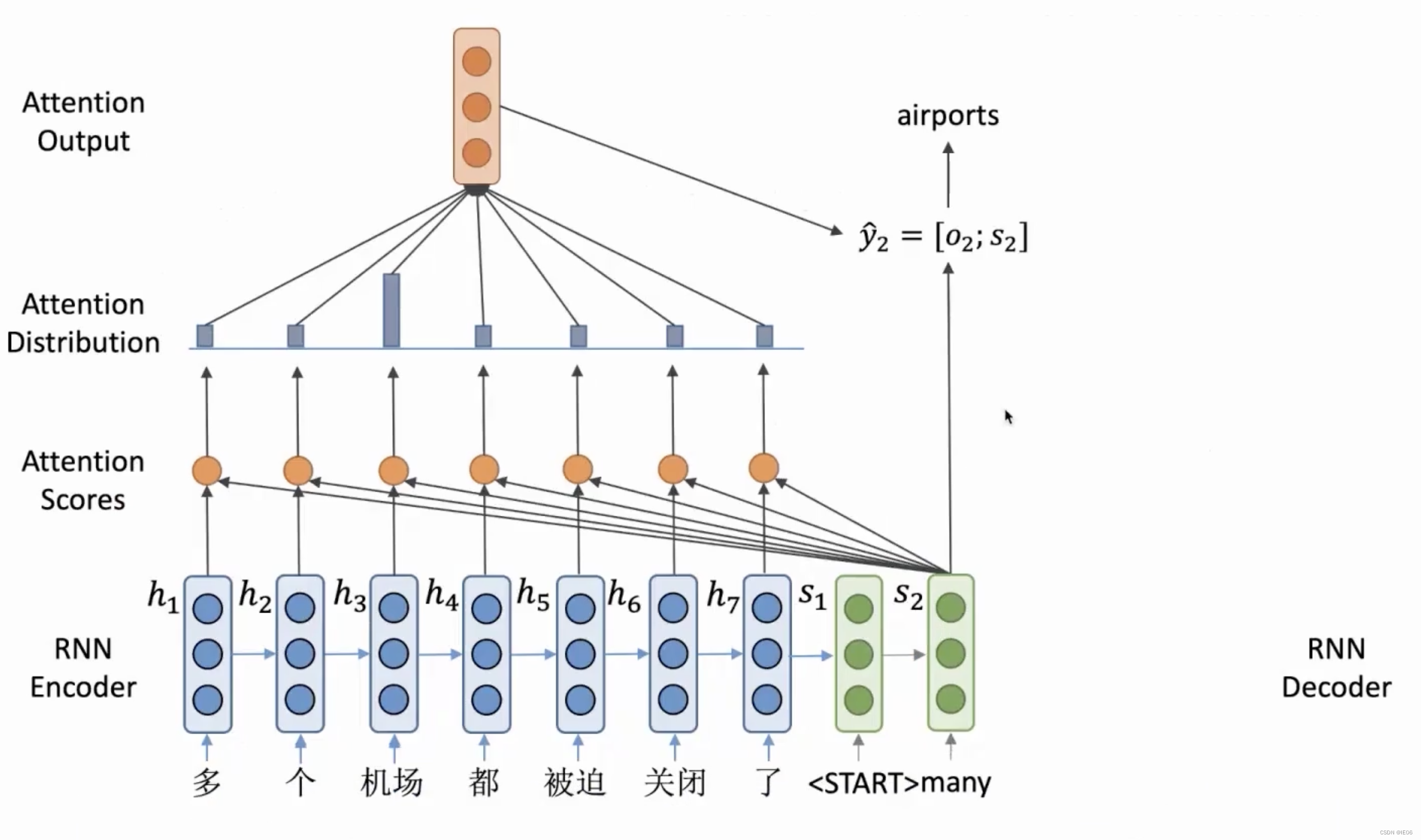
我们把中间结果s称为query vector,encoder得到的隐向量h称为value vector,这两者进行点积得到的e称为attention score。而decoder已经输出的结果称为key vector。
attention本质就是对value向量的加权平均。如果s和h长度不一样,则不能直接点积,而是需要在中间加上一个W,即e=sWh。也可以使用其他的方式来计算注意力,比如:
e
i
=
v
tanh
(
W
1
∗
h
i
+
W
2
∗
S
)
e_i=v \tanh(W_1*h_i+W_2*S)
ei=vtanh(W1∗hi+W2∗S)
注意力机制是一个非常直观的机制,刚刚例子的注意力数值绘制出来如下,简明易懂 :

1.3 self-attention/encoder-decoder-attention
上面的注意力机制基于的RNN是一个顺序执行的过程,因此很难使用GPU来高效训练。因此在2017年提出来新的transformer结构。
transformer的attention要注意如下几点:
- 注意力机制从qv转为了kqv(kq需要进行scale)。这里的q不再是上面RNN中的s,而是和v一样,都是通过一个变换矩阵得到的,通过这种方式我们不再拘泥于RNN的顺序机制,而可以高效利用GPU进行并行训练。在encoder中叫self-attention,k从输入得到;在decoder中叫cross-attention,k从输出得到。
- decoder模块中,kq计算完后需要进行mask(将矩阵上三角设置为负无穷大,softmax后当前位置后面的attention全都变为0),然后再和v进行计算。
- 引入多头注意力机制,即从多个不同角度做attention(用不同的方式初始化即可),然后按列拼接起来。一般需要把v/k/q维度也降下来,
d
′
=
d
/
h
d'=d/h
d′=d/h,这样拼接起来后和原来的维度相同。
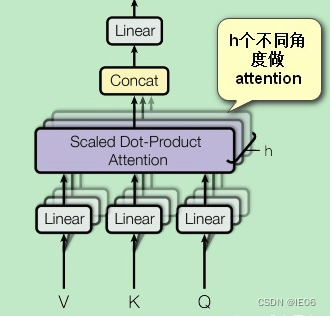
下面详细介绍transformer的结构。
2. transformer
2.1 整体结构
Transformer中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了 6 层 Encoder-Decoder 结构。
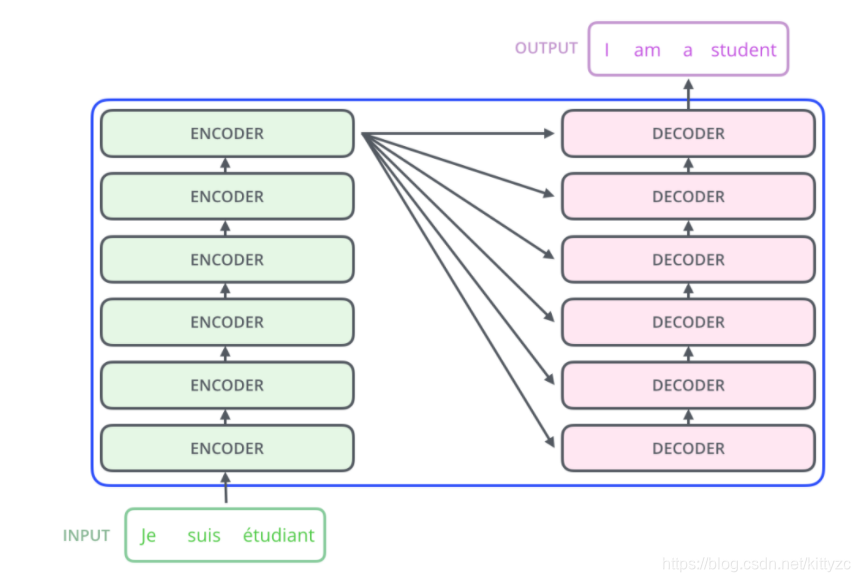
为了方便理解,我们只看其中一个Encoder-Decoder 结构。
Encoder部分由一个self-attention+前馈网络构成,Decoder部分中间多了一个Encoder-Decoder-attention层。
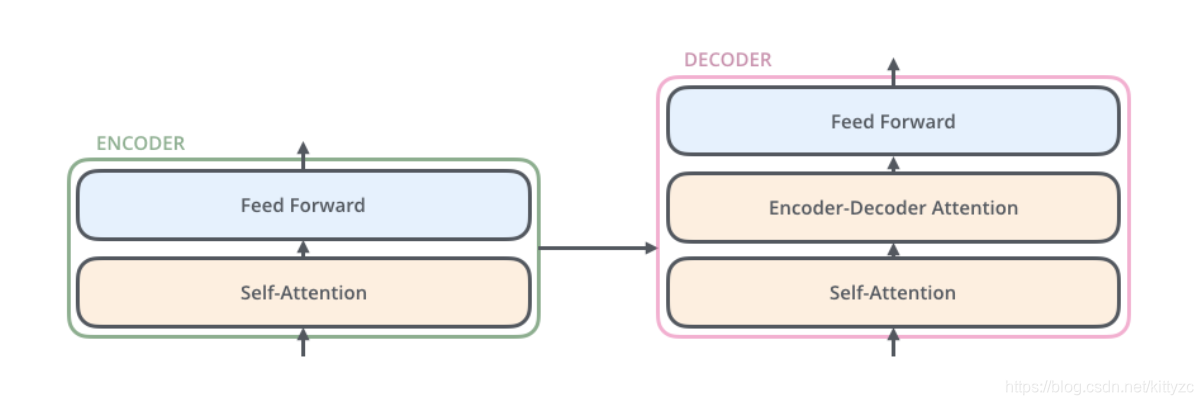
2.2 Embedding
(1) 将文字转换为固定维度的特征向量,即word2vec。

(2) 加入位置encoding,最简单的可以是直接将绝对坐标 0,1,2 编码。这里使用的是Tranformer的sin-cos 规则:

下面是可视化的结果:
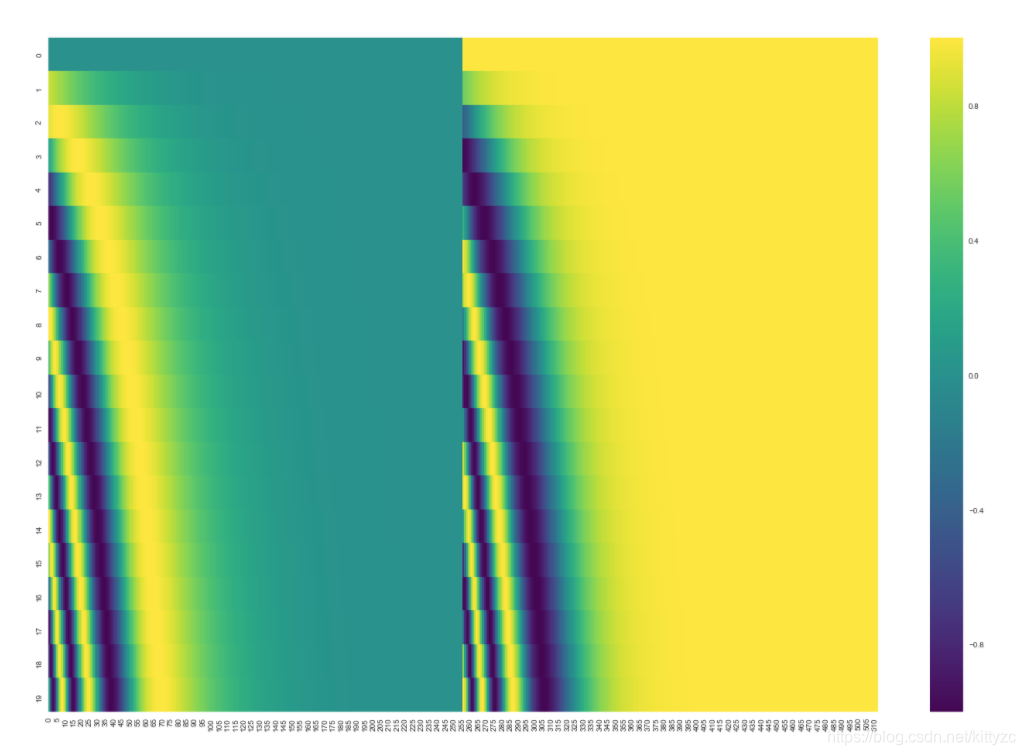
(3)每个编码器的都会接收到一个list(每个元素都是词向量),只不过其他编码器的输入是前个编码器的输出。list的尺寸是可以设置的超参,通常是训练集的最长句子的长度。
2.3 进入self-attention模块
transformer使用了多头机制,赋予attention多种子表达方式。简单来说,就是embedding中加入了更多的句子上下文信息。
像下面的例子所示,在多头下有多组query/key/value-matrix,而非仅仅一组(论文中使用8-heads)。每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中。
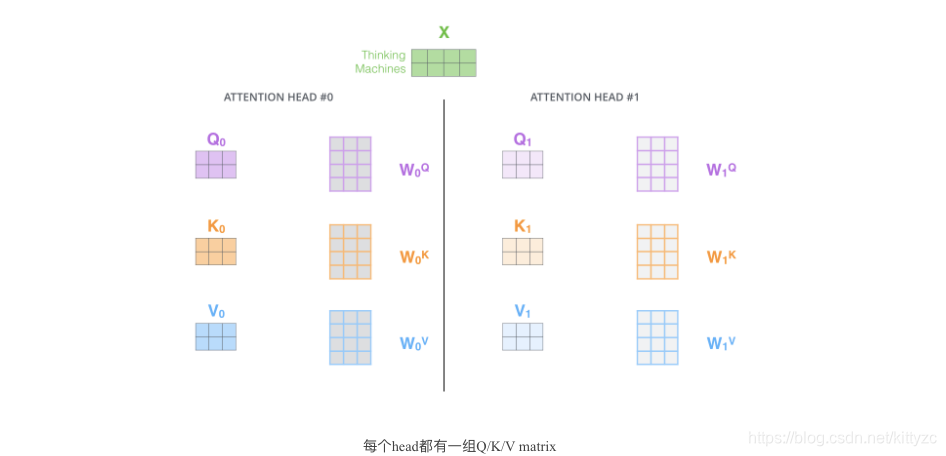
如果我们计算multi-headed self-attention的,分别有八组不同的Q/K/V matrix,我们得到八个不同的矩阵。
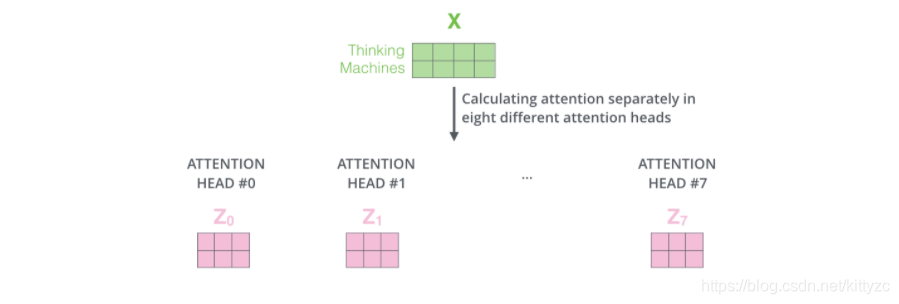
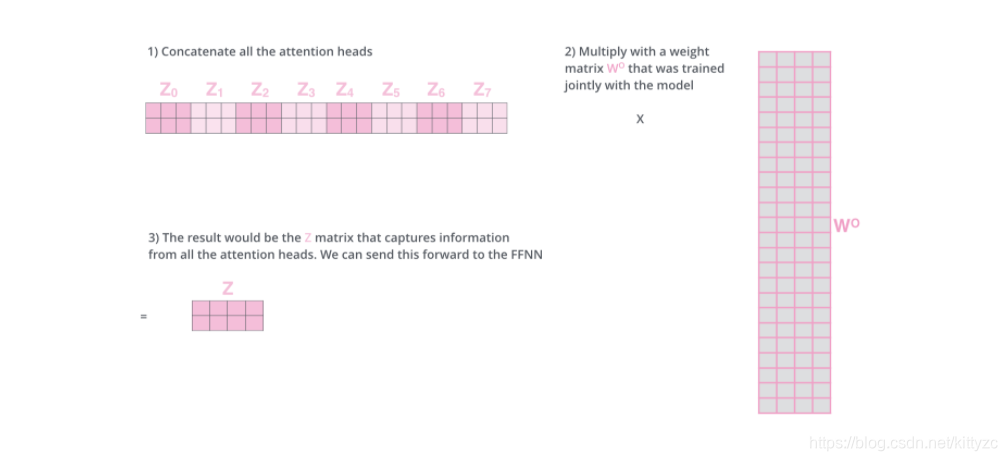
前向网络并不能接收八个矩阵,而是希望输入是一个矩阵,所以要有种方式处理下八个矩阵合并成一个矩阵。
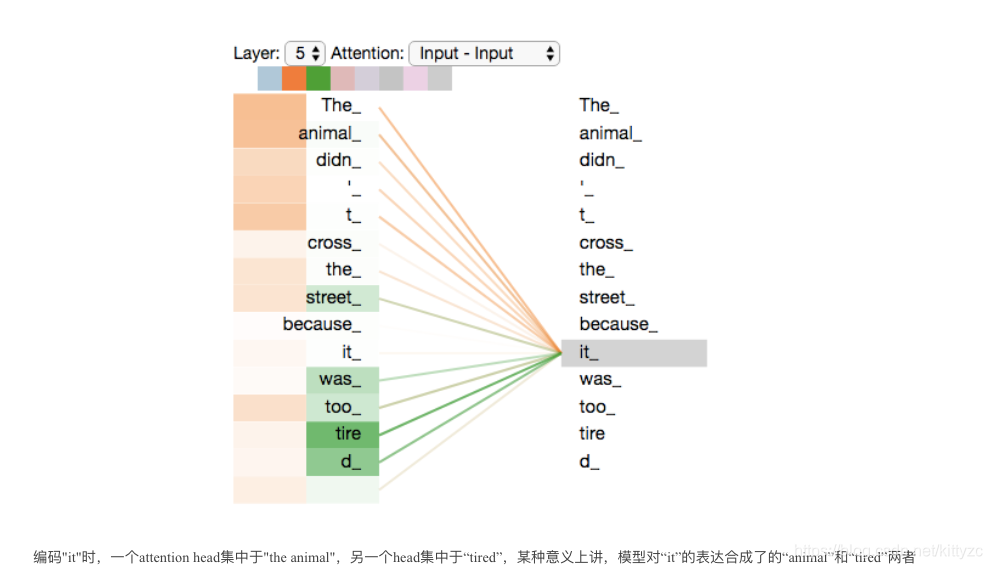
现在加入attention heads之后,重新看下当编码“it”时,哪些attention head会被集中。
2.4 进入前馈模块
前馈网络比较简单,所有的向量都共享相同的权重。
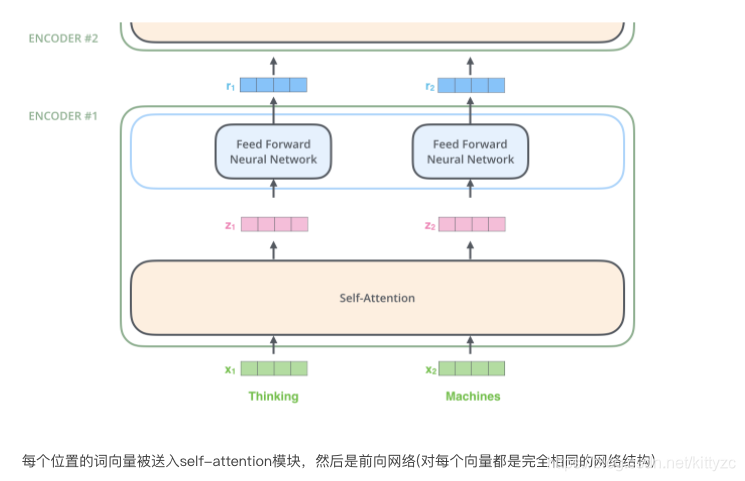
编码器结构中值得提出注意的一个细节是,在每个子层中(self-attention, ffnn),都有残差连接,并且紧跟着layer-normalization(下图的虚线部分)。
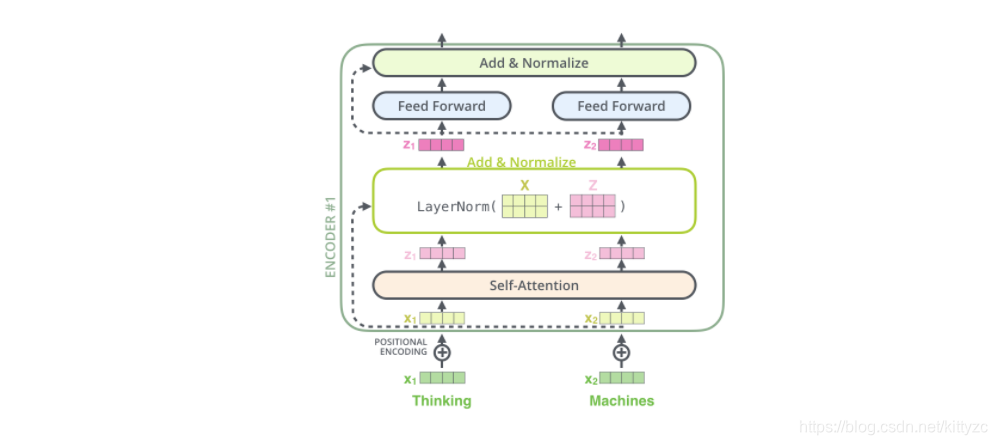
加入残差设计和层归一化操作目的是为了防止梯度消失,加快收敛:
- 残差设计:我们在上一步得到了经过注意力矩阵加权之后的 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/479402
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

