
- 1带你玩转PYNQ-Z2开发板 系列教程(一)—准备工作_pynq computer vision: getting started with pynq-z2
- 2FPGA秋招-笔记整理(1)
- 3【python】MQTT协议基础(简介+代码)
- 4【论文笔记】RS-Mamba for Large Remote Sensing Image Dense Prediction(附Code)
- 5JSON 与 对象 、集合 之间的转换_json 对象集合
- 6Hist2ST:联合Transformer和图神经网络从组织学图像中进行空间转录组学预测
- 7conda使用问题——CondaValueError: too few arguments, must supply command line package specs or --file
- 8信息安全技术网络安全等级保护基本要求GB/T 22239一2019(第一级安全要求)
- 9springboot3整合SpringSecurity实现登录校验与权限认证(万字超详细讲解)_springboot3 security
- 10牛客小白月赛36_卷王之王 题解
分布式系统面试全集通第一篇(dubbo+redis+zookeeper----分布式+CAP+BASE+分布式事务
赞
踩
作用:分布式解决网站高并发带来问题;
集群:相同的服务;
多台服务器部署相同应用构成一个集群;
作用:通过负载均衡设备共同对外提供服务;
业务系统分解为多个组件,让每个组件都独立提供离散,自治,可复用的服务能力;
通过服务的组合和编排来实现上层的业务流程;
作用:简化维护,降低整体风险,伸缩灵活;
+ 微服务:分散能力。
微服务[找到服务/微服务网关open API];
架构设计概念:各服务间隔离(分布式也是隔离),自治(分布式依赖整体组合),其它特性(单一职责,边界,异步通信,独立部署)
是分布式概念更加严格的执行;
SOA到微服务架构的演进过程;
作用:各服务可独立应用,组合服务也可系统应用(巨石应用[monolith]的简化实现策略-平台思想).
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 明确一个问题:分布式主要针对是部署方式,微服务则是将应用才分的一种应用架构
什么是CAP?为什么不能三者同时拥有
在设计一个分布式项目的时候会遇到三个特性:
- 一致性(consistency)
- 可用性(Availability)
- 分区容错(partition-tolerance)都需要的情景
输入/唤起更
CAP定律说的是在一个分布式计算机系统中,一致性,可用性和分区容错性这三种保证无法同时得到满足,最多满足两个。
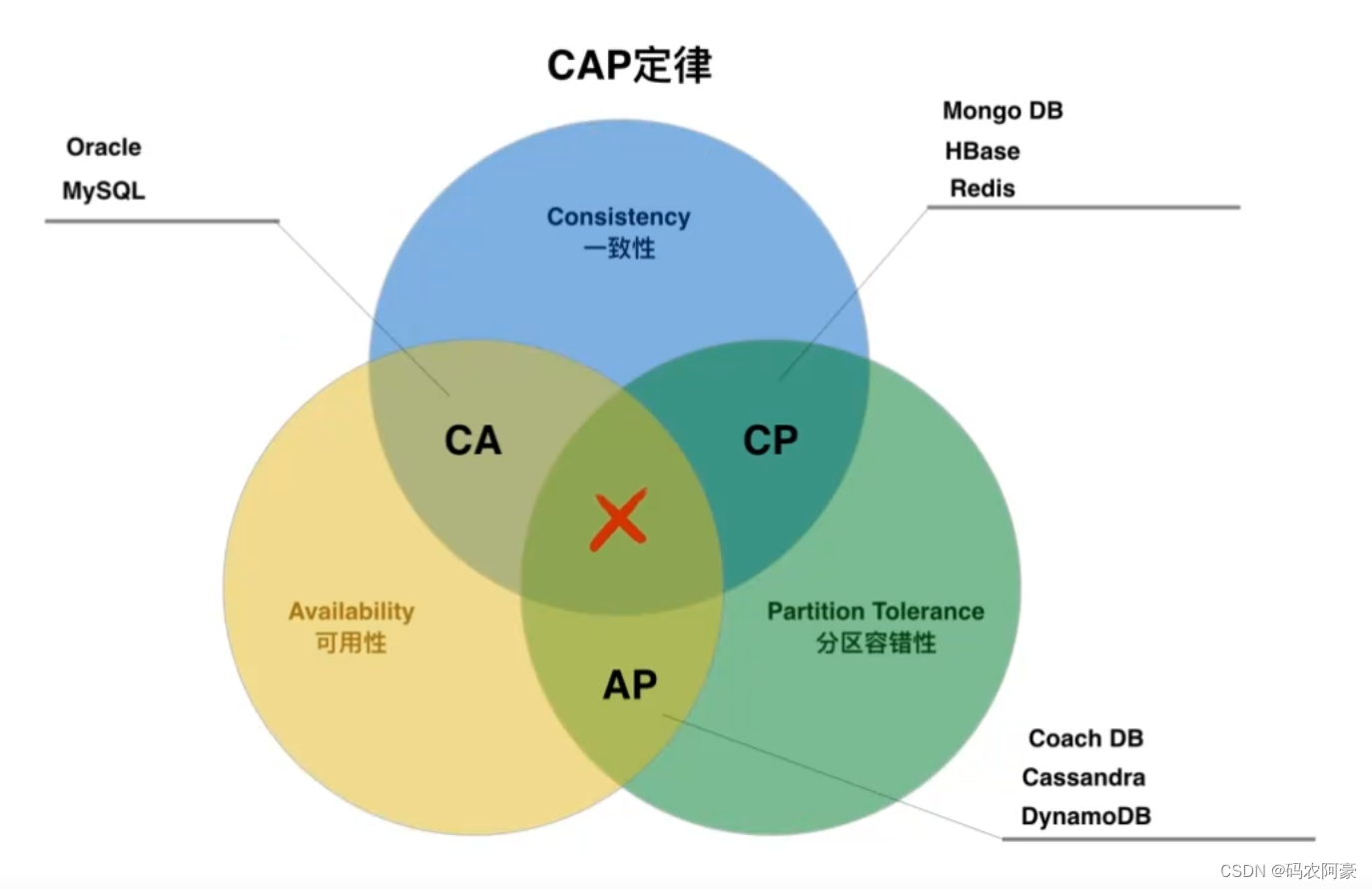
分区容错性
- 分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供服务。
- 分布式系统中,尽管部分节点出现任何消息丢失或者故障,系统应继续运行
- 通常分布式系统的各各结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间通信失败,此时仍可对外提供服务。
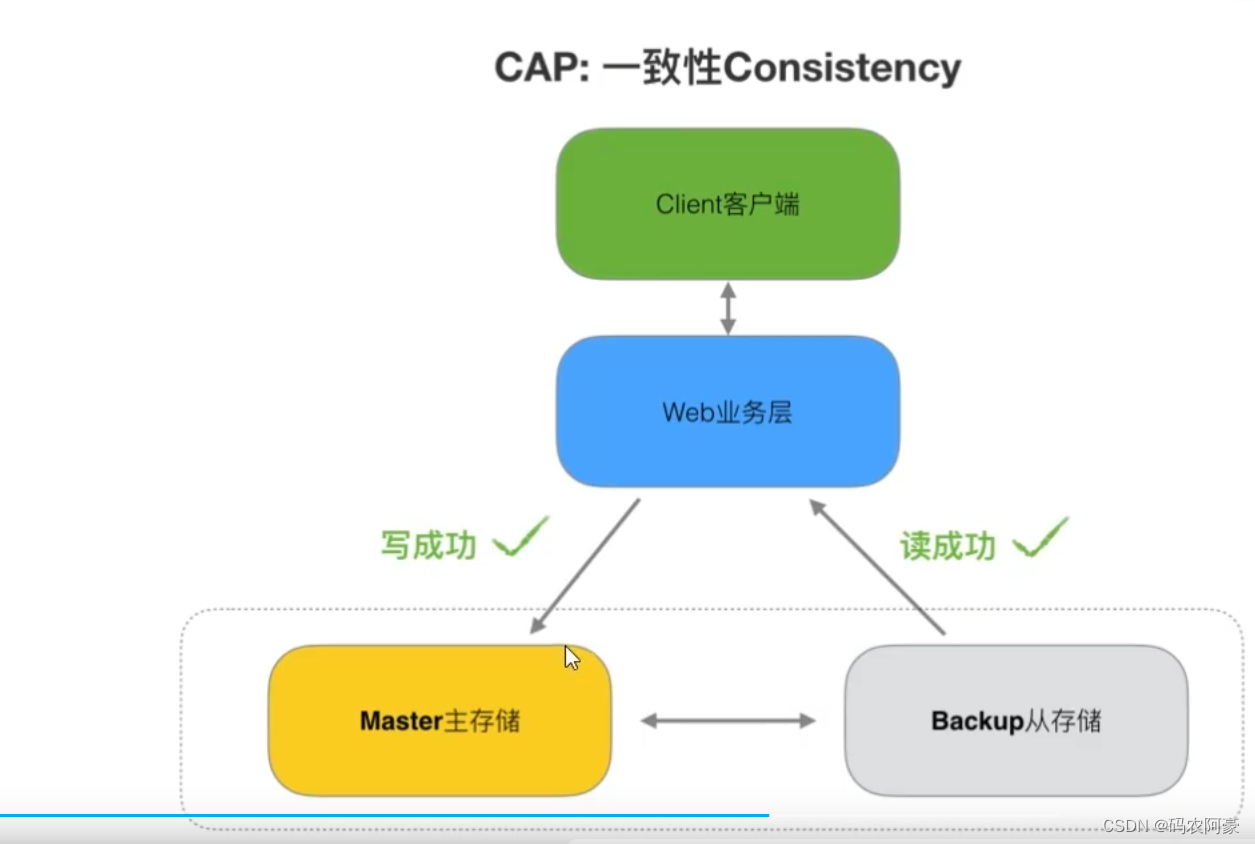
一致性
- 一致性指"all nodes see the same data at the same即更新操作成功并返回客户端time完成后,所有节点在同时间的数据完全一致。
- 一旦数据更新完成并成功返回客户端后,那么分布式系统中所有节点在同一时间的数据完全一致。
- 一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是最新的状态。
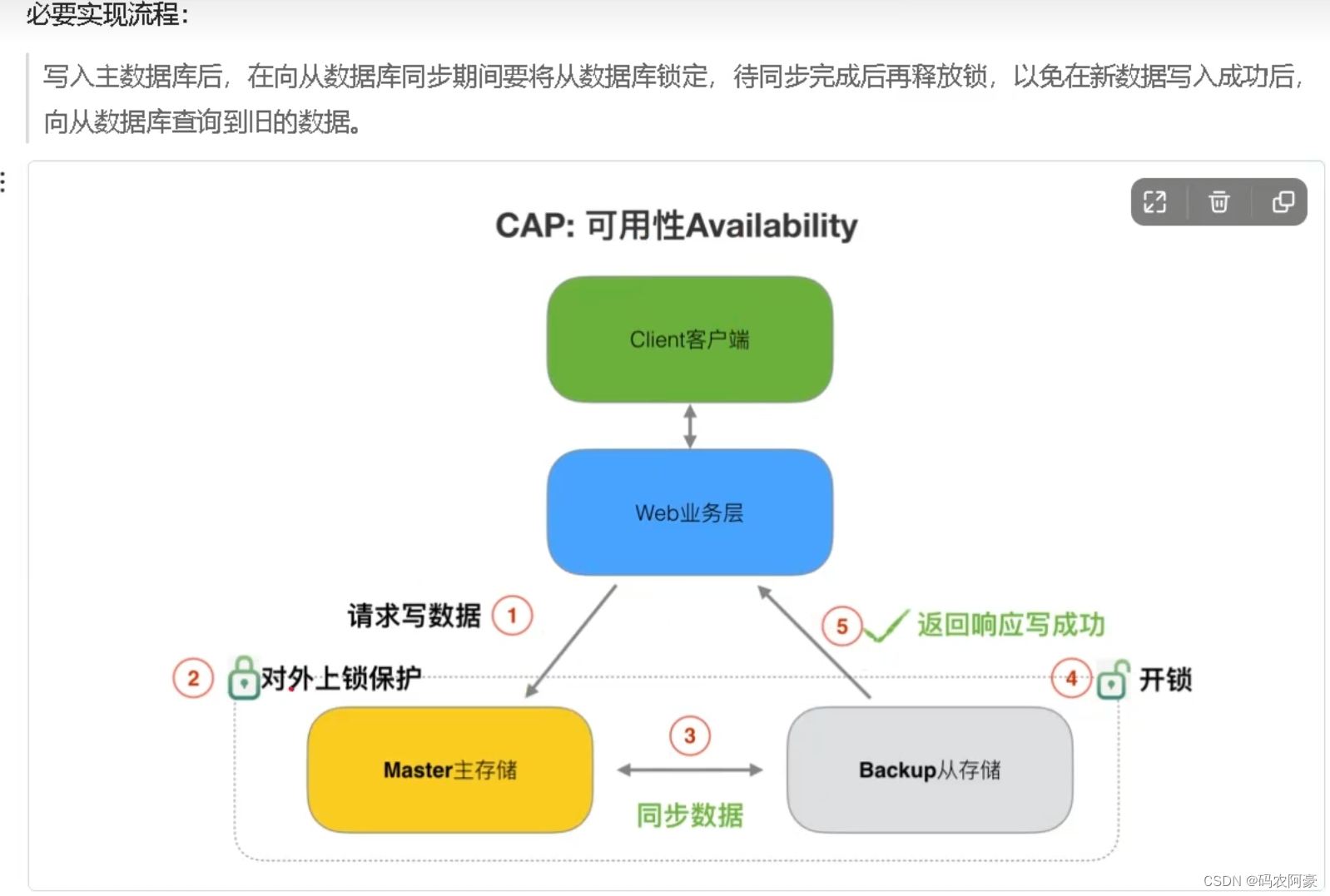
可用性
- 可用性指即服务一直可用,而且是正常响应时间。“Reads and writes always succeed”
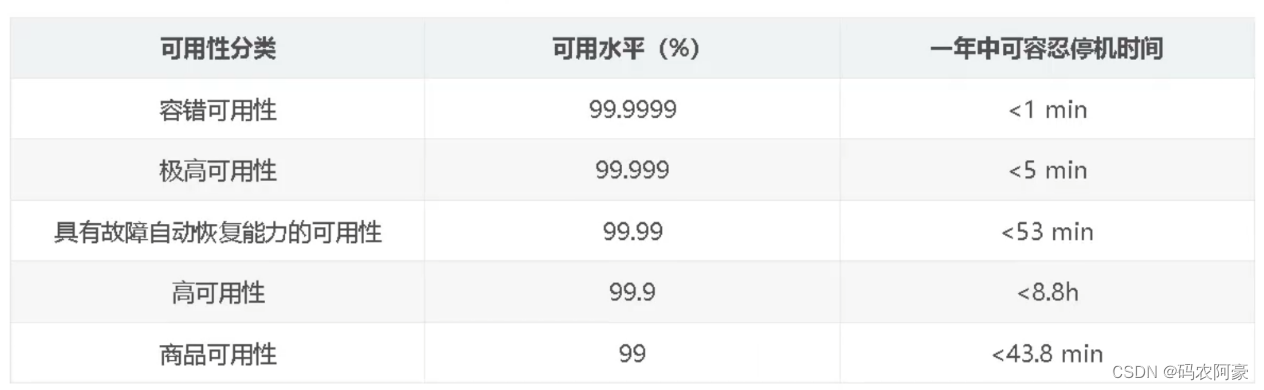
对于可用性的衡量标准如下:
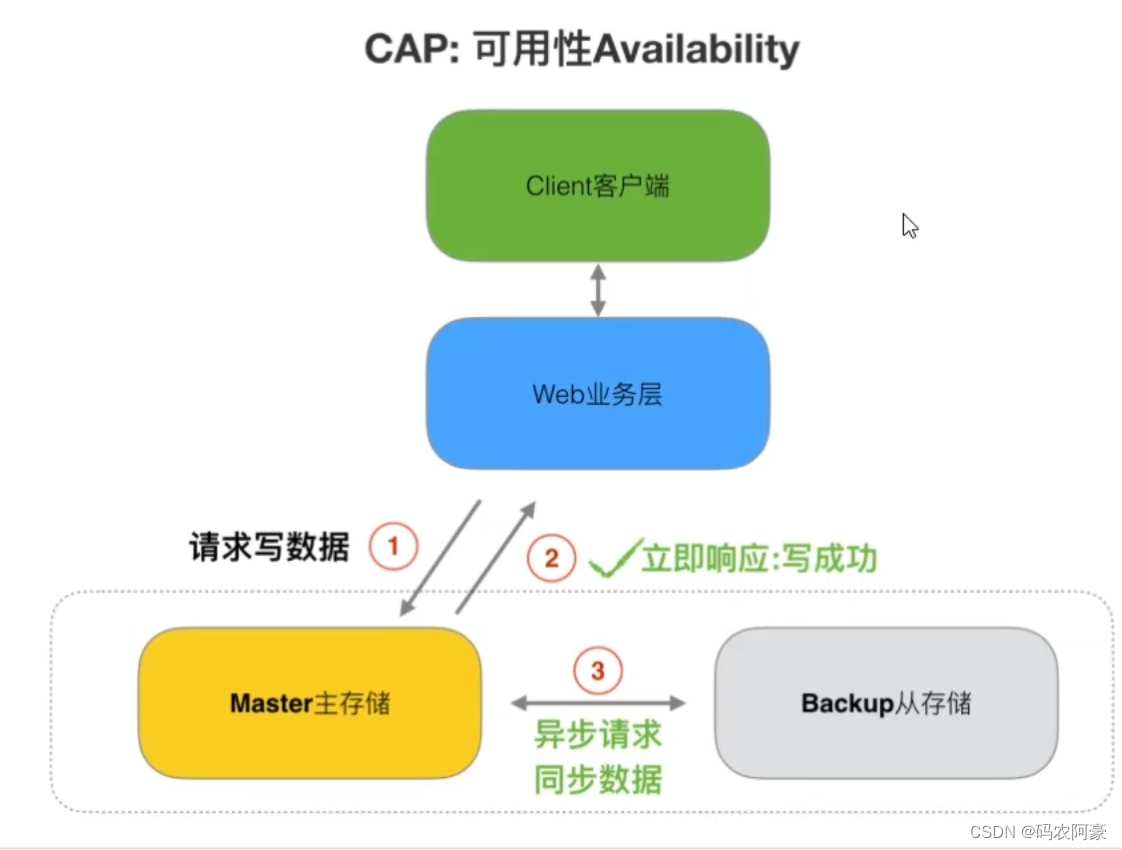
Base理论了解吗
BASE(Basically Available、Soft state、Eventual consistency)是基于CAP理论逐步演化而来的,核心思想是即便不能达到强一致性(Strong consistency),也可以根据应用特点采用适当的方式来达到最终致性(Eventual consistency)的效果。

基本可用
基本可用本质是一种妥协,也就是出现节点故障或者系统过载时,通过牺牲非核心功能的可用性,保障核心功能的稳定运行。
实现基本可用的几个策略:
- 1、流量削峰(不同地区售票时间错峰出售)
以订票系统设计为例,在春运期间,开始售票前后会出现及其海量的请求峰值。
可以在不同的时间,出售不同区域的票,将访问请求错开,削弱请求峰值。 - 2、延迟响应,异步处理(买票排队,基于队列先收到用户买票请求,排队异步处理,延迟响应)还以订票系统为例。用户提交购票请求后,往往会在队列中排队等待处理,可能几分钟或十几分钟后,系统才开始处理,然后响应处理结果。
- 3、体验降级(看到非实时数据,采用缓存数据提供服务)以互联网系统为例,若出现网络热点事件,产生了海量的突发流量,系统过载,大量图片因为网络超时无法显示那么可以用小图片代替原始图片,降低图片的清晰度和大小,提升系统处理能力。
- 4、过载保护熔断/限流,直接拒绝掉一部分请求,或者当请求队列满了,移除一部分请求,保证整体系统可用)把接收到的请求放在指定的队列中排队处理,如果请求等待时间超时,这时直接拒绝超时请求;如果队列满了之后,就清除队列中一定数量的排队请求,保护系统不过载,实现系统基本可用。
- 5、故障隔离(出现故障,做到故障隔离,避免影响其他服务)
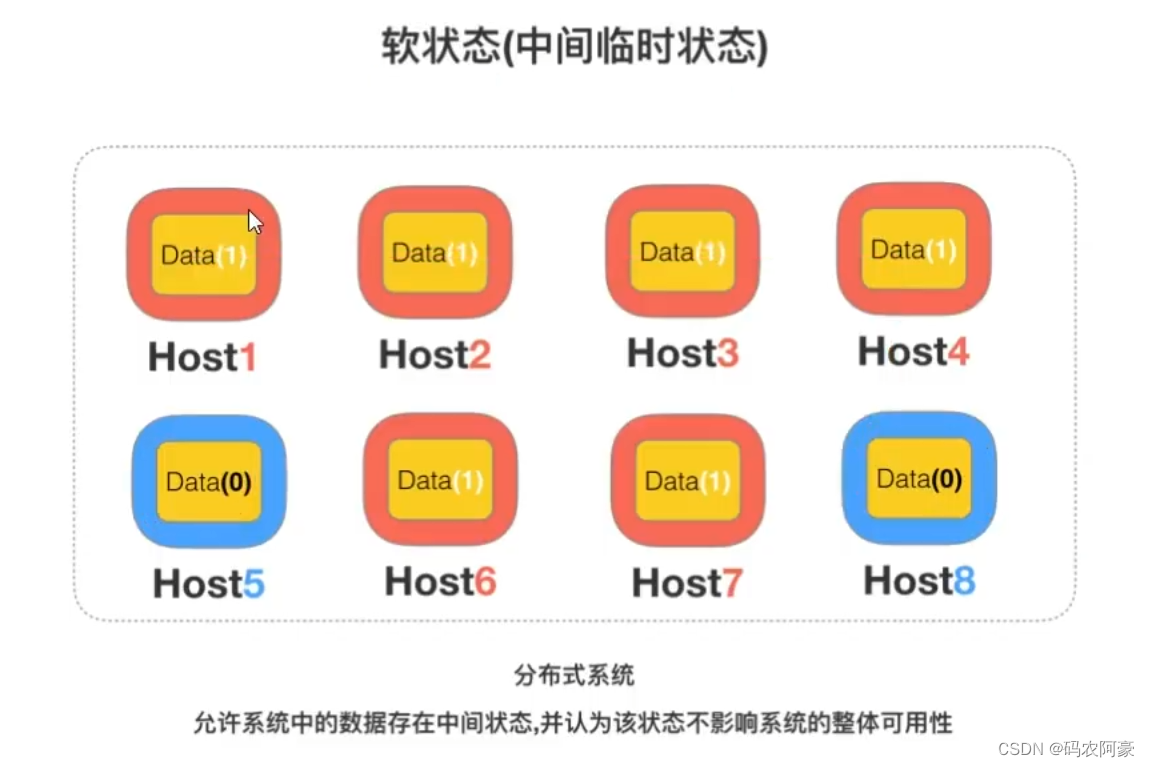
软状态
软状态(弱状态)->允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延迟。
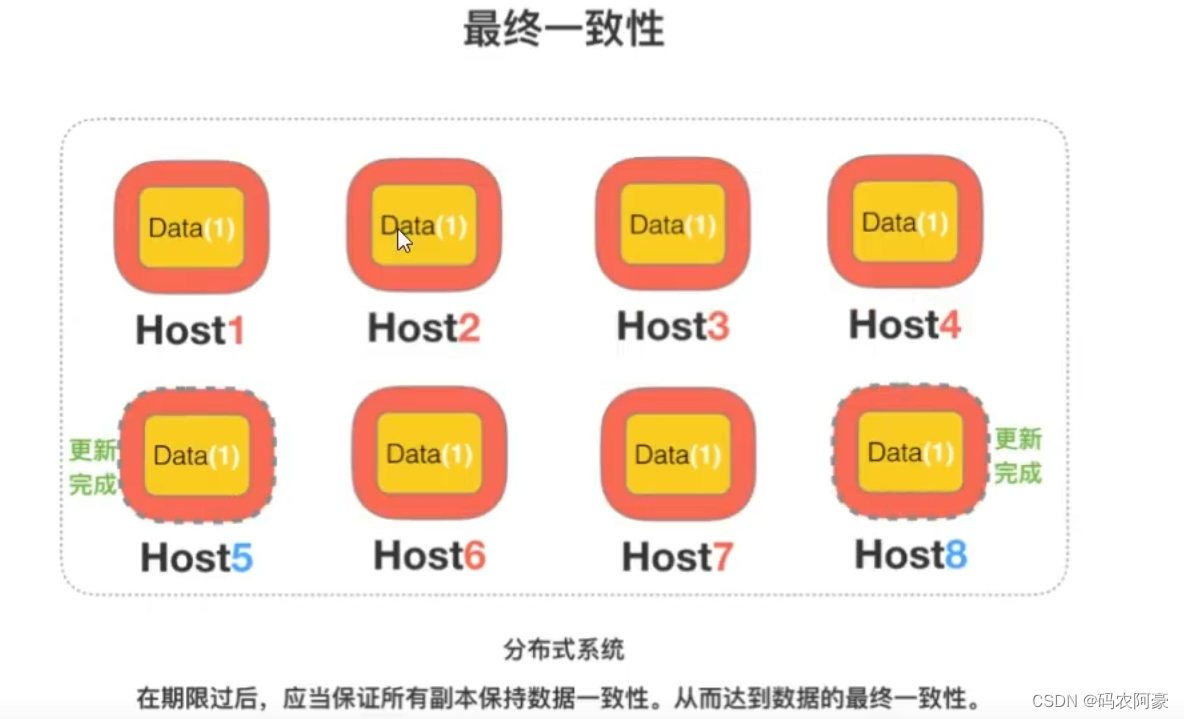
最终一致性
上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性。
从而达到数据的最终一致性。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。
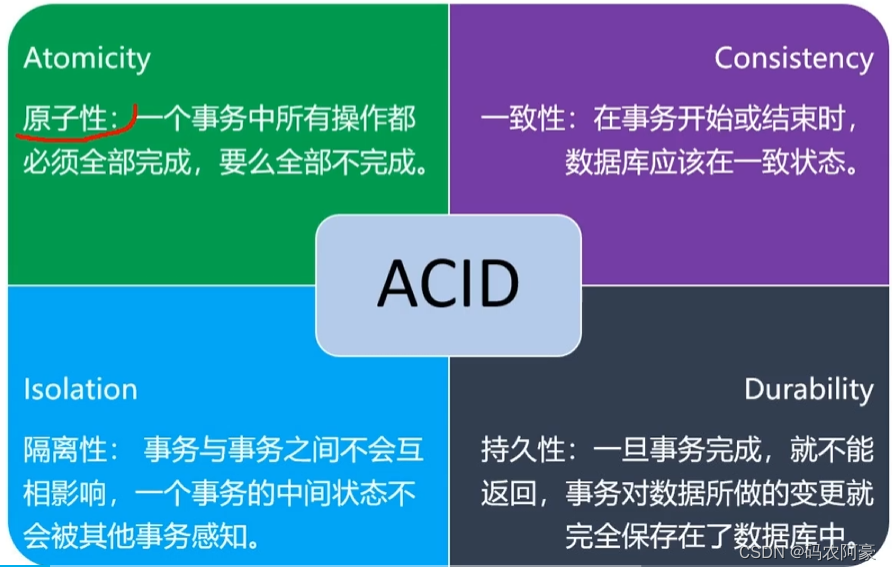
什么是分布式事务
分布式事务是相对本地事务而言的,对于本地事务,利用数据库本身的事务机制,就可以保证事务的ACID
特性。
分布式事务有哪些常见的实现方案?
到现在,分布式事务已经有很多的解决方案了,有2PC、3PC、TCC,这一篇博客,我们先来分别讲讲最早的2PC、3PC这两种解决方案的模型及理论基础,以后再丰富其他的分布式事务解决方案。
2PC(Two Phase Commit)
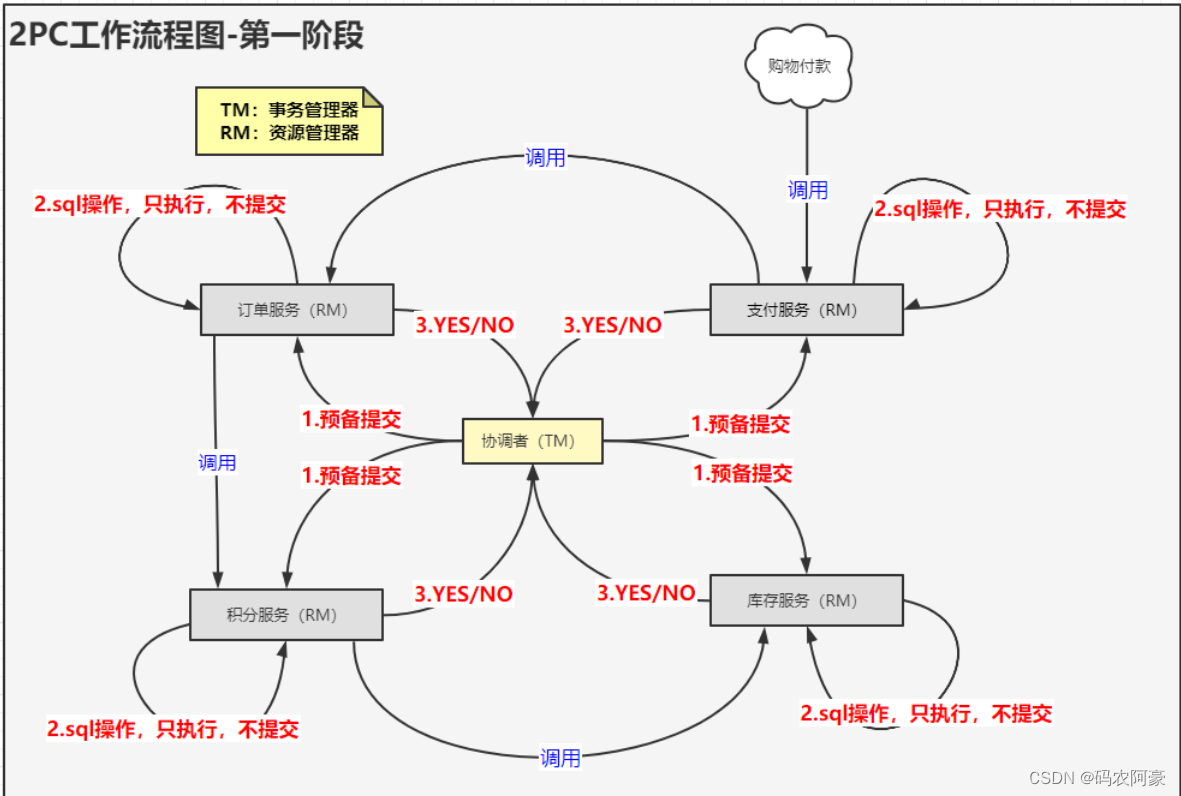
第一阶段:执行事务操作
- 事务询问。
协调者节点向所有参与者节点询问是否可以执行提交操作,并开始等待各参与者节点的响应。 - 执行事务。
参与者节点执行询问发起的所有事务操作,并将Undo信息和Redo信息写入数据库日志。(若操作成功,这里其实每个参与者已经执行了事务操作) - 各参与者向协调者反馈事务询问的响应。
各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则反馈一个“同意”消息;如果执行失败,则反馈一个“中止”消息。
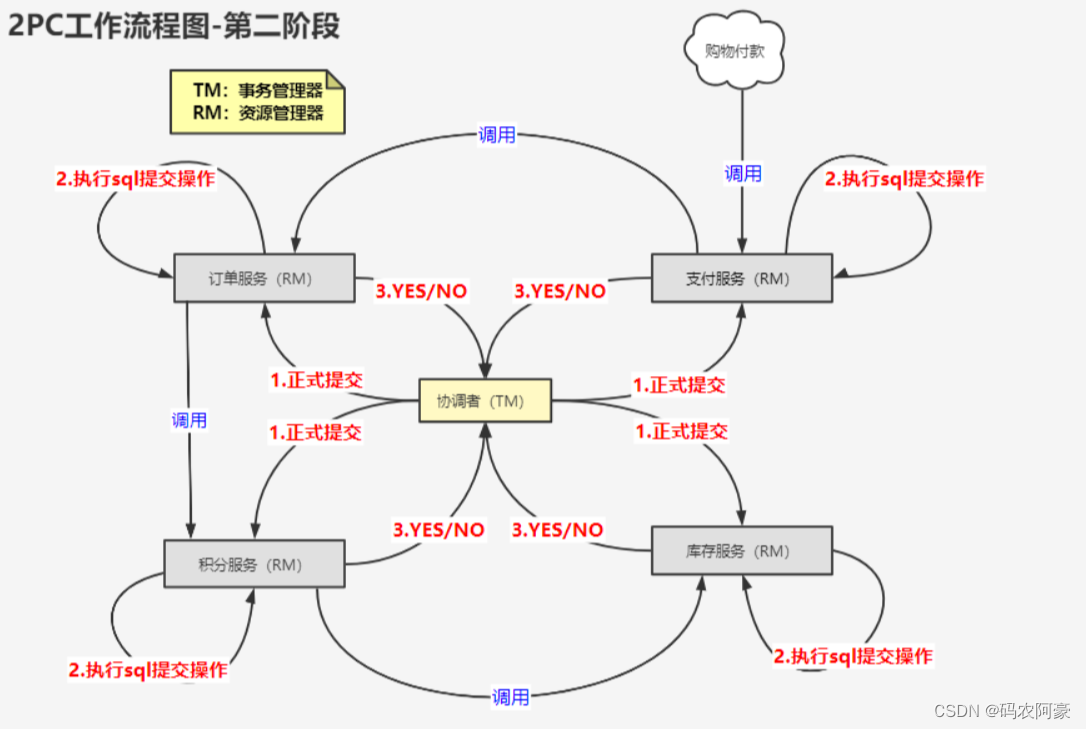
第二阶段:执行事务提交
当所有参与者节点在第一阶段向协调者节点反馈的消息全都是“同意”时:
- 发送事务提交请求
协调者节点向所有参与者节点发出“正式提交(commit)”请求。 - 事务正式提交
参与者节点正式完成提交操作,并释放在整个事务期间占用的资源。 - 反馈事务提交结果
参与者节点向协调者节点发送“完成”消息。 - 完成事务
协调者节点收到所有参与者节点反馈的“完成”消息后,完成分布式事务。
当任一参与者节点在第一阶段反馈的响应为“中止”,或者协调者在第一阶段接收反馈信息超时:
发送事务回滚请求
协调者节点向所有参与者节点发出“回滚操作(rollback)”请求。
- 事务回滚
各参与者节点收到请求,利用之前写入的Undo信息执行本地事务回滚操作,并释放在整个事务期间占用的资源。 - 反馈事务回滚结果
参与者节点向协调者节点发送“回滚完成”消息。 - 中断事务
协调者节点收到所有参与者节点反馈的“回滚完成”消息后,取消事务。
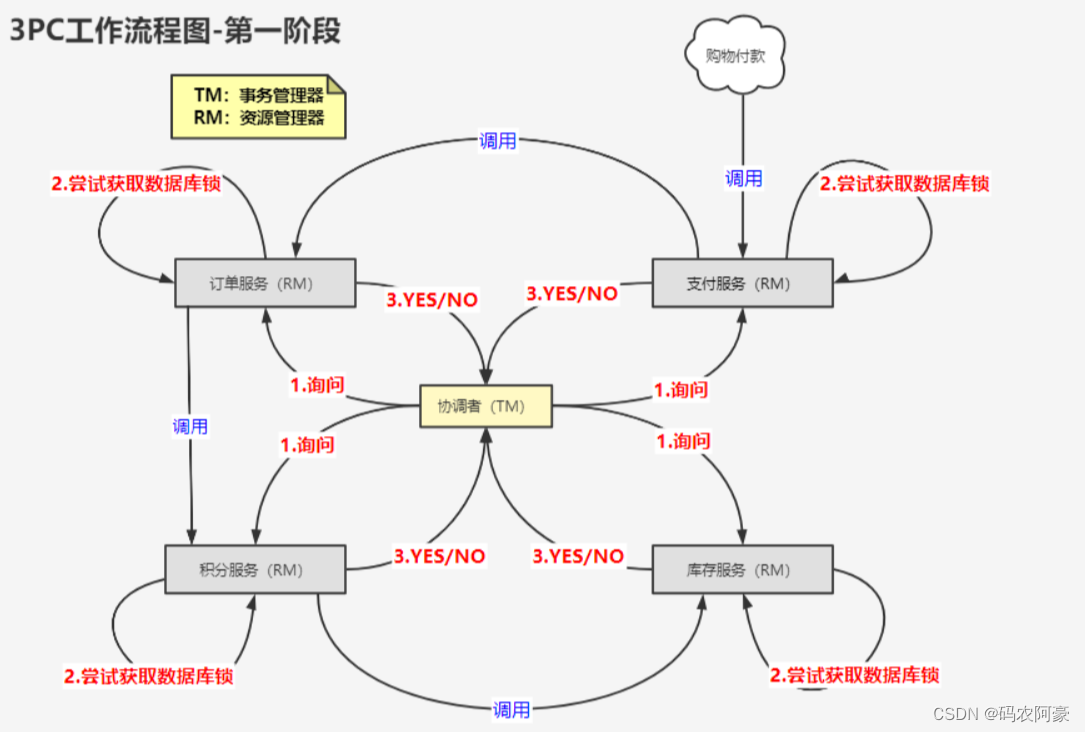
3PC(Three Phase Commit)
3PC没有解决2PC所有问题,只是降低了灾难的发生概率。只是在2PC基础上,多一个询问
TCC(Try Commit Cancel)
这个模型有两个个阶段,但是与2PC的三个阶段又有所不同。
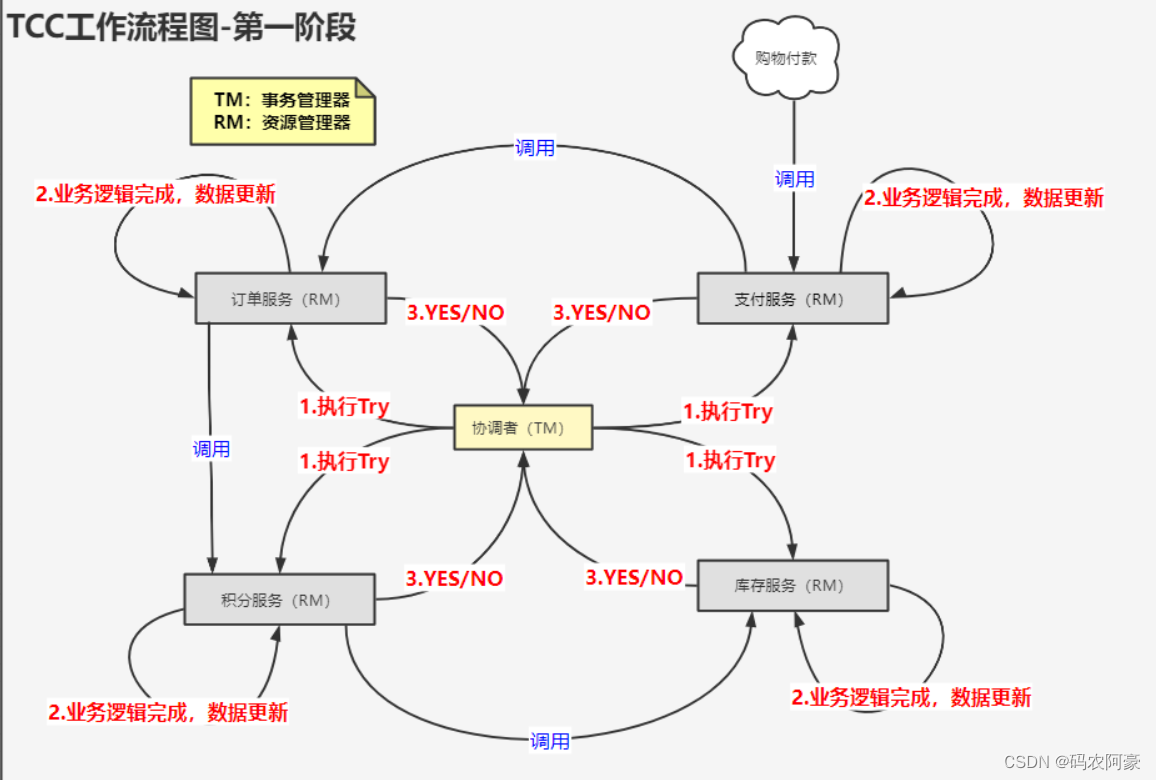
第一阶段:执行Try操作
- 事务发起。
协调者节点向所有参与者节点发起执行业务逻辑包含数据操作的命令,并开始等待各参与者节点的响应。 - 执行数据操作。
直接对数据库的数据执行操作。 - 各参与者向协调者反馈执行操作的响应。
各参与者节点响应协调者节点发起的数据操作。如果参与者节点的数据操作实际执行成功,则反馈一个“同意”消息;如果有一个参与者执行失败,则反馈一个“中止”消息。
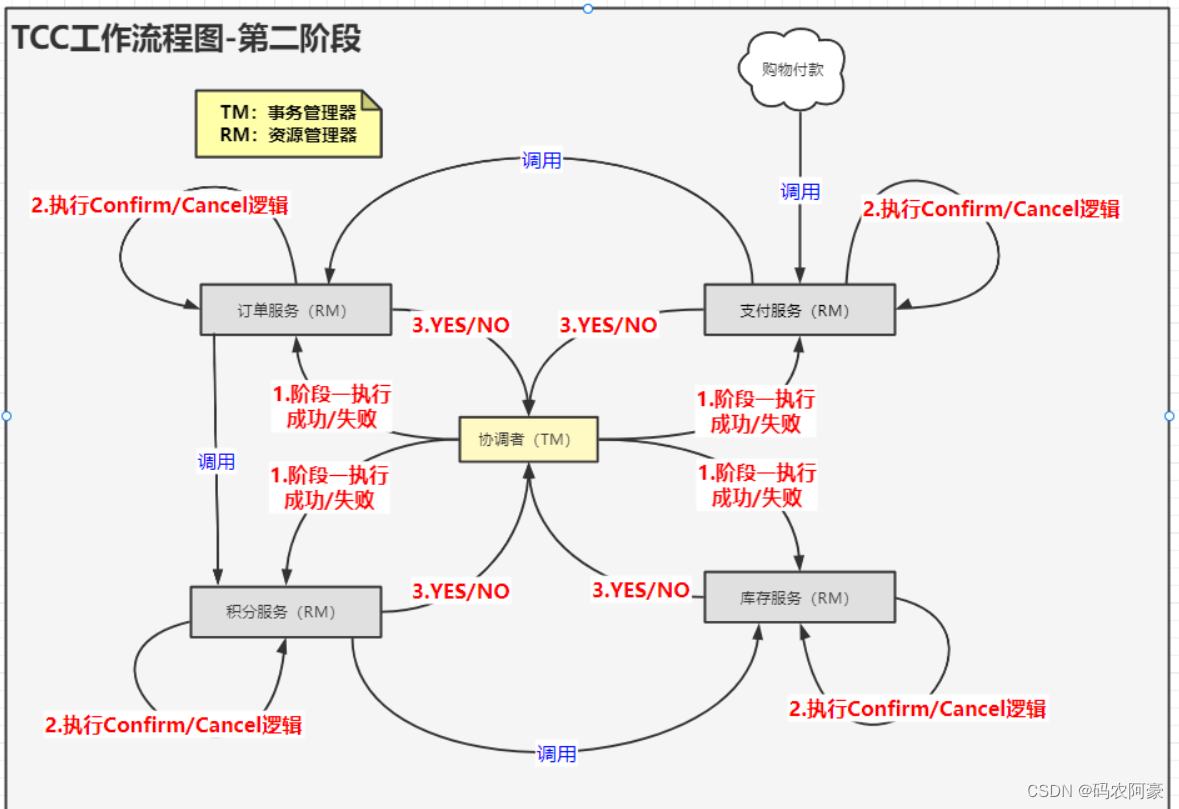
第二阶段:执行Confirm/Cancel操作
根据阶段一各事务参与者的响应,如果所有事务参与者在阶段一执行成功,那就执行Confirm操作,有一个事务参与者在阶段一执行失败,就执行Cancel操作,进行数据库数据恢复。
Confirm 操作用于执行数据操作成功之后的业务逻辑。
Cancel 操作用于恢复阶段一对数据的操作。
2PC、3PC、TCC区别
1.在2PC的第一阶段基础之上,3PC新加了一个准备阶段(上图所示),用于询问所有参与者节点是否已经准备好要进行分布式事务操作了,这一阶段没有对资源的占用,只是测试数据库是否能获取锁即可,只是保证所有参与者都有能力参与事务,如果有网络或者其他问题就不用进行第二、三阶段了。
2. 在3PC的所有阶段,都为所有参与者节点和协调者节点添加了超时机制,防止因某一节点宕机造成的资源无法释放问题。
3. 2PC中所有阶段,只对协调者节点添加了超时机制。
4. TCC模型主要是在应用层做的一个分布式事务,2PC和3PC则是在数据库层做的分布式事务。
5。 TCC模型可以用于不支持事务的数据库,但是2PC和3PC要求数据库必须支持事务。
2PC存在问题
2PC只对协调者节点添加了超时机制,如果协调者这一重要角色宕机,所有参与者的资源就会一直得不到释放,降低系统的可用性。
2PC中,当其中任一节点宕机情况出现时,不能保证数据的最终一致性。
TCC存在问题
代码编写难度高
每个参与者的业务都要写try、confirm、cancel三个操作,并且各个操作的业务都有所不同
为满足一致性,要满足try、canfirm、cancel三个操作的幂等。
对于幂等性,可参考文章【分布式事务讲解 - Seata分布式事务框架(AT、TCC两种模式)】
TCC的优点
TCC的优点全是因为实现了应用层的分布式事务,优点如下:
可以降低数据库锁冲突,提高吞吐量。
可以通过应用控制数据库锁的粒度,而不用像2PC和3PC使数据库阻塞等待。
可以通过部署集群解决单点故障。
对比2PC,3PC有什么优点
为所有参与者节点和协调者节点添加了超时机制:
1)如果协调者等待参与者反馈信息超时,直接给所有参与者发送中断分布式事务请求。
2)如果在第三阶段任一参与者等待协调者提交事务信息超时,那就默认提交事务
添加超时机制,可以防止因某一节点宕机造成的资源无法释放问题以及资源占用时间过长问题。
在第一阶段,不锁定资源,就好像在Synchronized外面加了个if条件,能降低分布式事务执行失败率。
有哪些分布式锁的实现方案?
一、 分布式锁场景
般需要使用分布式锁的场景如下:
效率:使用分布式锁可以避免不同节点重复相同的工作,比如避免重复执行定时任务等;正确性:使用分布式锁同样可以避免破坏数据正确性,如果两个节点在同一条数据上面操作,可能会出现并发问题。
二、分布式锁特点
一个完善的分布式锁需要满足以下特点:
·互斥性:互斥是所得基本特性,分布式锁需要按需求保证线程或节点级别的互斥。·可重入性:同一个节点或同一个线程获取锁,可以再次重入获取这个锁;
·锁超时:支持锁超时释放,防止某个节点不可用后,持有的锁无法释放;
高效性:加锁和解锁的效率高,可以支持高并发
·高可用:需要有高可用机制预防锁服务不可用的情况,如增加降级;
阻塞性:支持阻塞获取锁和非阻塞获取锁两种方式;
·公平性:支持公平锁和非公平锁两种类型的锁,公平锁可以保证安装请求锁的顺序获取锁,而非公平锁
基于缓存实现分布式锁,以Redis为例
加锁
public class RedisTool { private static final String LOCK\_SUCCESS = "OK"; private static final String SET\_IF\_NOT\_EXIST = "NX"; private static final String SET\_WITH\_EXPIRE\_TIME = "PX"; /\*\* \* 加锁 \* @param stringRedisTemplate Redis客户端 \* @param lockKey 锁的key \* @param requestId 竞争者id \* @param expireTime 锁超时时间,超时之后锁自动释放 \* @return \*/ public static boolean getDistributedLock(StringRedisTemplate stringRedisTemplate, String lockKey, String requestId, int expireTime) { return stringRedisTemplate.opsForValue().setIfAbsent(lockKey, requestId, 30, TimeUnit.SECONDS); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
这个setIfAbsent()方法一共五个形参:
第一个为key,我们使用key来当锁,因为key是唯一的。
第二个为value,这里写的是锁竞争者的id,在解锁时,我们需要判断当前解锁的竞争者id是否为锁持有者。
第三个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期时间的设置,具体时间由第五个参数决定;
第四个参数为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的setIfAbsent()方法就只会导致两种结果:
1.当前没有锁(key不存在),那么就进行加锁操作,并对锁设置一个有效期,同时value表示加锁的客户端。
2.已经有锁存在,不做任何操作。上述解锁请求中,缓存超时机制保证了即使一个竞争者加锁之后挂了,也不会产生死锁问题:超时之后其他竞争者依然可以获取锁。通过设置value为竞争者的id,保证了只有锁的持有者才能来解锁,否则任何竞争者都能解锁,那岂不是乱套了。
解锁
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

…(img-I7CGzPa0-1712882763554)]
[外链图片转存中…(img-8hSBKrgP-1712882763555)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-GX0WSzNJ-1712882763555)]

