
- 1VSCode配置LeetCode(C++环境配置)简述_vscode leetcode c++
- 2【Gitee的使用】Gitee的简单使用,查看/创建SSH公匙、创建版本库、拉取代码、提交代码_gitee ssh
- 3动态规划之子序列以及子数组类型的问题_划分多个子数组是哪种动态规划
- 4python依赖包安装 pip换源_python安装换源
- 5统计一批学生的平均成绩和不及格人数_c语言统计不及格人数
- 6Flask框架学习之环境配置_flask对应的python版本
- 7Python+Django+Mysql开发简单在线音乐推荐系统 基于用户的协同过滤推荐算法 音乐播放推荐系统 个性化音乐推荐系统 可视化数据分析 爬虫 机器学习 人工智能_python个性化音乐推荐系统使用什么算法
- 8【论文阅读+复现】AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
- 9Zynq7020-PS端裸机--EMMC/SD驱动实现_zynq7020 emmc硬件设计
- 10Spring Boot构建RESTful API与单元测试,你真的知道软件测试按下开机键到启动发生什么吗
12款最常使用的网络爬虫工具推荐_爬虫软件
赞
踩
网络爬虫在当今的许多领域得到广泛应用。它的作用是从任何网站获取特定的或更新的数据并存储下来。网络爬虫工具越来越为人所熟知,因为网络爬虫简化并自动化了整个爬取过程,使每个人都可以轻松访问网站数据资源。使用网络爬虫工具可以让人们免于重复打字或复制粘贴,我们可以很轻松的去采集网页上的数据。此外,这些网络爬虫工具可以使用户能够以有条不紊和快速的抓取网页,而无需编程并将数据转换为符合其需求的各种格式。
在这篇文章中,我将介绍目前比较流行的20款网络爬虫工具供你参考。希望你能找到最适合你需求的工具。
【最新Python全套从入门到精通学习资源,文末免费领取!】
1、八爪鱼
八爪鱼是一款免费且功能强大的网站爬虫,用于从网站上提取你需要的几乎所有类型的数据。你可以使用八爪鱼来采集市面上几乎所有的网站。八爪鱼提供两种采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。下载免费软件后,其可视化界面允许你从网站上获取所有文本,因此你可以下载几乎所有网站内容并将其保存为结构化格式,如EXCEL,TXT,HTML或你的数据库。
你可以使用其内置的正则表达式工具从复杂的网站布局中提取许多棘手网站的数据,并使用XPath配置工具精确定位Web元素。另外八爪鱼提供自动识别验证码以及代理IP切换功能,可以有效的避免网站防采集。
总之,八爪鱼可以满足用户最基本或高级的采集需求,而无需任何编程技能。
2、HTTrack
作为免费的网站爬虫软件,HTTrack提供的功能非常适合从互联网下载整个网站到你的PC。它提供了适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在“设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取照片,文件,HTML代码,更新当前镜像的网站并恢复中断的下载。
此外,HTTTrack还提供代理支持,以通过可选身份验证最大限度地提高速度。
HTTrack用作命令行程序,或通过shell用于私有(捕获)或专业(在线Web镜像)使用。 有了这样的说法,HTTrack应该是首选,并且具有高级编程技能的人更多地使用它。
3、 Scraper
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google sheets。此工具适用于初学者以及可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的专家。Scraper是一个免费的网络爬虫工具,可以在你的浏览器中正常工作,并自动生成较小的XPath来定义要抓取的URL。
4、OutWit Hub
Outwit Hub是一个Firefox添加件,它有两个目的:搜集信息和管理信息。它可以分别用在网站上不同的部分提供不同的窗口条。还提供用户一个快速进入信息的方法,虚拟移除网站上别的部分。
OutWit Hub提供单一界面,可根据需要抓取微小或大量数据。OutWit Hub允许你从浏览器本身抓取任何网页,甚至可以创建自动代理来提取数据并根据设置对其进行格式化。
OutWit Hub大多功能都是免费的,能够深入分析网站,自动收集整理组织互联网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。但是要自动提取精确数据就需要付费版本了,同时免费版一次提取的数据量也是有限制的,如果需要大批量的操作,可以选择购买专业版。
5、ParseHub
Parsehub是一个很棒的网络爬虫,支持从使用AJAX技术,JavaScript,cookie等的网站收集数据。它的机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统,或者你可以使用浏览器中内置的Web应用程序。
作为免费软件,你可以在Parsehub中设置不超过五个publice项目。付费版本允许你创建至少20private项目来抓取网站。
6、Scrapinghub
Scrapinghub是一种基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,一家代理IP第三方平台,支持绕过防采集对策。它使用户能够从多个IP和位置进行网页抓取,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。如果其爬虫工具无法满足你的要求,其专家团队可以提供帮助。。
7、Dexi
作为基于浏览器的网络爬虫,允许你从任何网站基于浏览器抓取数据,并提供三种类型的爬虫来创建采集任务。免费软件为你的网络抓取提供匿名Web代理服务器,你提取的数据将在存档数据之前在的服务器上托管两周,或者你可以直接将提取的数据导出到JSON或CSV文件。它提供付费服务,以满足你获取实时数据的需求。
8、Webhose
使用户能够将来自世界各地的在线资源抓取的实时数据转换为各种标准的格式。通过此Web爬网程序,你可以使用涵盖各种来源的多个过滤器来抓取数据并进一步提取多种语言的关键字。
你可以将删除的数据保存为XML,JSON和RSS格式。并且允许用户从其存档访问历史数据。此外,支持最多80种语言及其爬行数据结果。用户可以轻松索引和搜索抓取的结构化数据。
总的来说,可以满足用户的基本爬行要求。
9、Import
用户只需从特定网页导入数据并将数据导出到CSV即可形成自己的数据集。
你可以在几分钟内轻松抓取数千个网页,而无需编写任何代码,并根据你的要求构建1000多个API。公共API提供了强大而灵活的功能来以编程方式控制并获得对数据的自动访问,通过将Web数据集成到你自己的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于Windows,Mac OS X和Linux的免费应用程序,以构建数据提取器和抓取工具,下载数据并与在线帐户同步。此外,用户还可以每周,每天或每小时安排抓取任务。
10、80legs
80legs是一个功能强大的网络抓取工具,可以根据自定义要求进行配置。它支持获取大量数据以及立即下载提取数据的选项。80legs提供高性能的Web爬行,可以快速工作并在几秒钟内获取所需的数据
11、Content Graber
Content Graber是一款面向企业的网络爬行软件。它允许你创建独立的Web爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结构化数据,包括Excel报告,XML,CSV和大多数数据库。
它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试界面。允许用户使用C#或 .NET 调试或编写脚本来编程控制爬网过程。例如,Content Grabber可以与Visual Studio 2013集成,以便根据用户的特定需求为高级且机智的自定义爬虫提供最强大的脚本编辑,调试和单元测试。
12、UiPath
UiPath是一款用于免费网络抓取的机器人过程自动化软件。它可以自动从大多数第三方应用程序中抓取Web和桌面数据。如果运行Windows系统,则可以安装机械手过程自动化软件。Uipath能够跨多个网页提取表格和基于模式的数据。
Uipath提供了用于进一步爬行的内置工具。处理复杂的UI时,此方法非常有效。Screen Scraping Tool可以处理单个文本元素,文本组和文本块,例如表格格式的数据提取。
此外,创建智能Web代理不需要编程,但你内部的.NET黑客可以完全控制数据。

关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
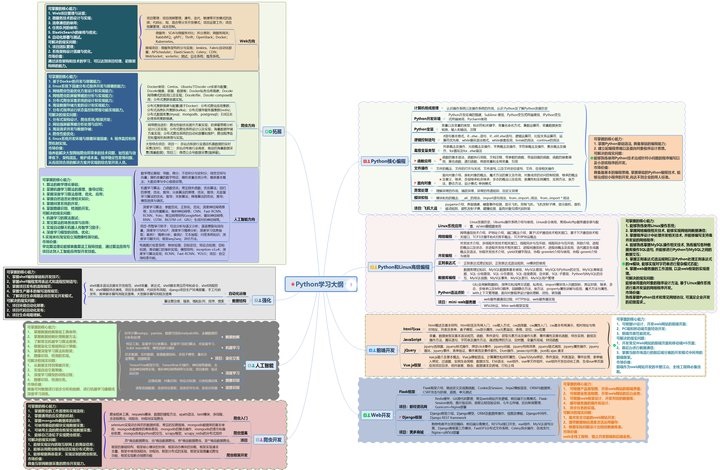
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、python副业兼职与全职路线
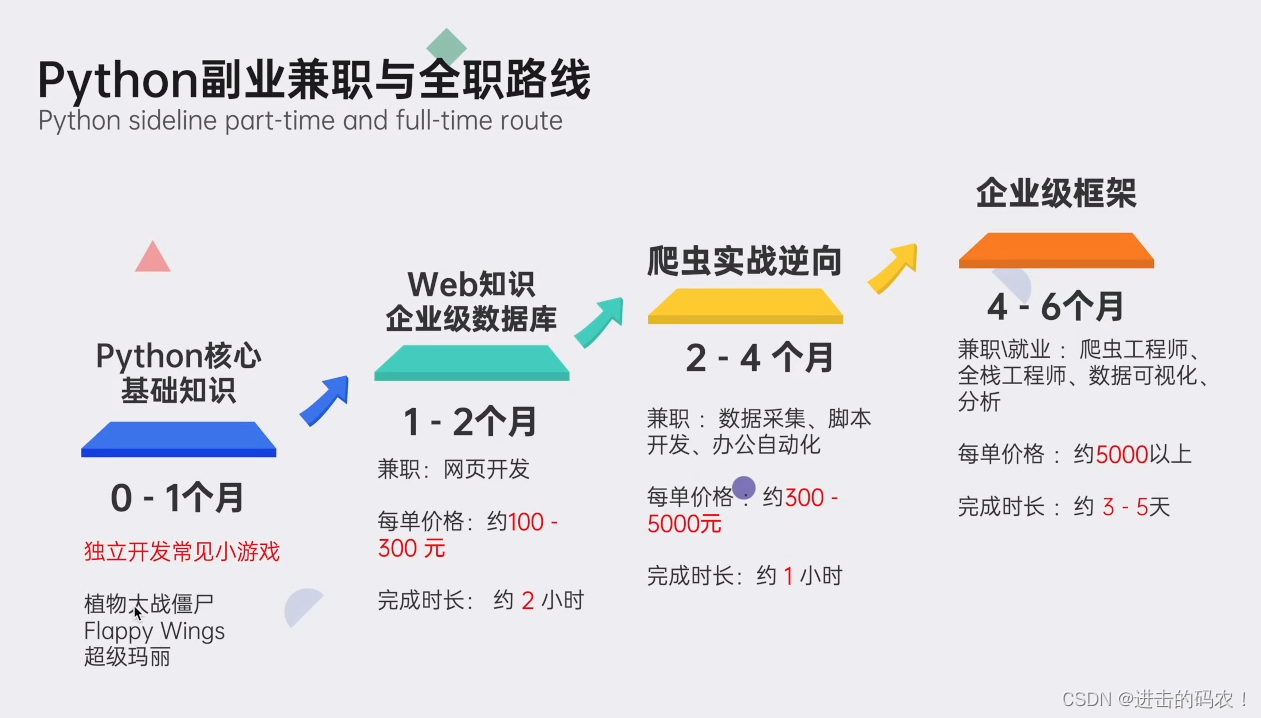
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/492705
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

