
- 1黑客工具软件大全100套(非常详细)从零基础入门到精通,看完这一篇就够了_抓取网页交互信息的工具黑客
- 2java web3j 智能合约 读方法和写方法_web3j获取调合约里的getnonce方法获取nonce,getnonce方法没有参数
- 3MySQL字符集详解_collation_connection
- 44种Python处理Excel数据的方法!_python操作excel
- 5centos7下安装python-pip
- 6常用wed扫描工具 awvs|appscan|Netsparker|Nessus_netsparker和awvs哪个好
- 7TCP三次握手以及SYN,ACK,Seq的不详细解释_syn seq
- 8WebSocket的用法——服务器主动给客户端推送数据_websocket主动推送数据到客户端
- 9Keil系列教程09_调试仿真_keil仿真调试教程
- 10OUC图书馆电脑开启无线网络,连接手机热点,解决联网但无法访问网络的问题
人工智能基础——模型部分:模型介绍、模型训练和模型微调 !!
赞
踩
文章目录
前言
本文将从什么是模型?什么是模型训练?什么是模型微调?三个问题,来展开介绍人工智能基础的模型部分。
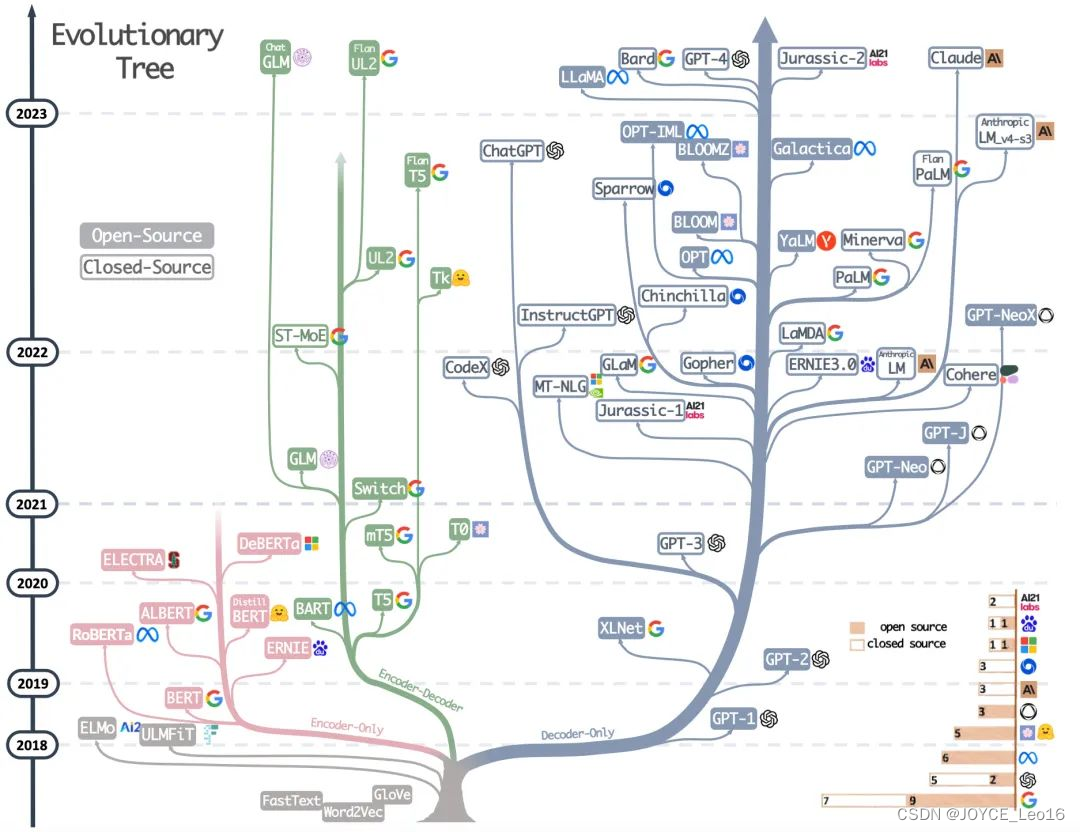
模型族谱
一、什么是模型
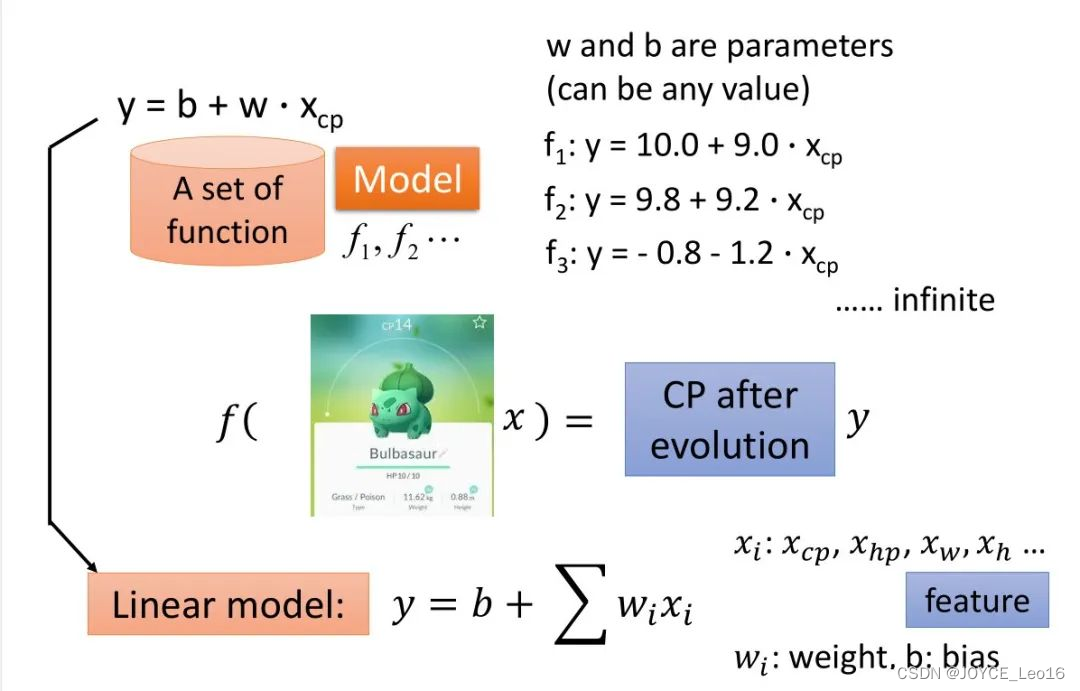
模型是一个函数:将现实问题转化为数学问题(Encoder编码器),通过求解数学问题来得到现实世界的解决方案(Decoder解码器)。
,这个模型
是一个函数,它根据输入数据(可以是文本、图像、语音、视频等)和一组参数
(通常表示为权重)来预测输出
。这里的输入和权重都是以数学形式(如矩阵或张量)表示的。
1. 输入数据:在深度学习中,原始数据(如文字、图片等)需要被转换成模型可以处理的数学形式。这通常意味着将数据编码为数值矩阵或张量。例如,文本可能被转换为词嵌入(word embeddings)或词频矩阵(term-frequency matrices),而图像则可能被转换为像素值矩阵。
2. 网络结构:模型的具体形式是由其网络结构决定的。在深度学习中,这通常是一个由多层神经元组成的神经网络。每一层都对输入数据进行某种转换,最终产生一个预测输出。
3. 参数训练:模型中的参数是未知的,需要通过训练来确定。训练过程通常涉及优化算法,如梯度下降(gradient descent),用于最小化预测输出与实际标签之间的差异(即损失函数)。
4. 输出类型:根据任务的不同,模型的输出可以是多种形式的:
二分类问题:输出为0或1(例如,垃圾邮件检测)。
多分类问题:输出为一系列标签中的一个(例如,图像分类)。
回归问题:输出为一个连续数值(例如,房价预测)。
序列生成:输出为下一个词或字符的概率分布(例如,语言模型)。
5. 模型应用:一旦模型被训练好,它就可以用于对新数据进行预测。这些预测可以用于各种实际应用,如推荐系统、自动驾驶、语音识别等。
(Model)
神经网络:一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
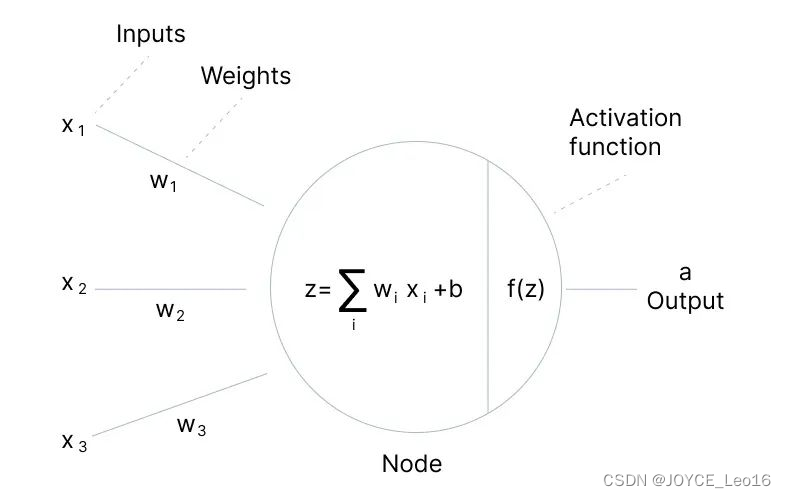
- 单个神经元模型:
神经元是神经网络的基本单元。每个神经元接收来自其他神经元的输入信号(或来自外部的数据),对这些信号进行加权求和,并通过一个激活函数来产生输出。
函数公式描述了这一过程,其中
是输入信号,
是对应的权重,
表示对所有输入信号的加权求和,而
是激活函数。
单个神经元模型
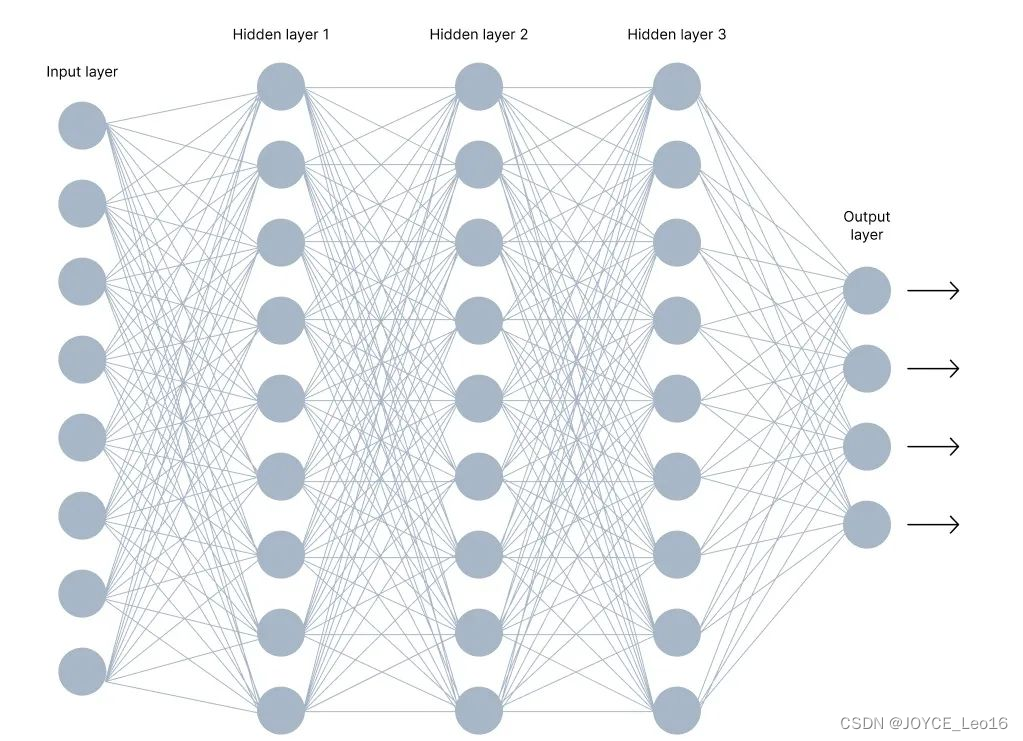
- 多个神经元模型:
神经网络是由多个神经元相互连接而成的复杂网络。
神经网络的每一层都会对其输入进行加权求和并通过激活函数得到输出,这些输出又会作为下一层的输入。
多个神经元模型(神经网络)
- 激活函数:
激活函数是神经网络中非常重要的组成部分,它决定了神经元如何将其输入转换为输出。激活函数为神经网络引入了非线性特性,使其能够学习并逼近复杂的函数。
激活函数的选择取决于具体的应用和模型架构。不同的激活函数有不同的性质和优缺点,需要根据实际情况进行选择。
常见的激活函数包括:
- Sigmoid函数:将输入映射到0和1之间,常用于二分类问题的输出层。
- Tanh函数:将输入映射到-1和1之间,类似于Sigmoid但中心化在0。
- ReLU(Rectified Linear Unit):对于非负输入直接输出该值,对于负输入输出0,是目前深度学习中最常用的激活函数之一。
- Leaky ReLU:对ReLU的改进,允许负输入有一个小的正斜率。
- Softmax函数:将多个神经元的输出映射为概率分布,常用于多分类问题的输出层。
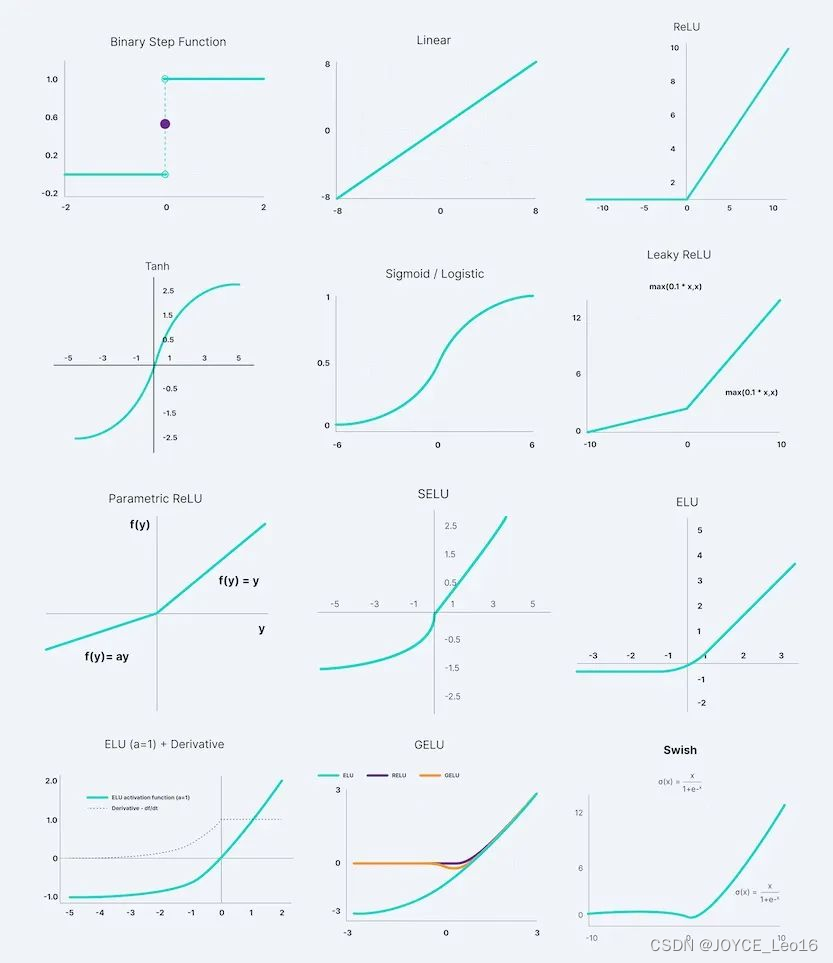
激活函数
二、什么是模型训练
模型训练:模型训练的本质是一个求解最优化问题的过程。通过不断迭代优化,旨在找到一组最优参数,使得模型对于给定输入的预测输出与真实输出之间的差异最小化,这个差异通常通过损失函数来衡量。

- 目标设定:
确定模型的目标,即希望模型学习到的任务,如分类、回归、聚类等。
根据任务选择或设计适当的损失函数,该函数能够量化模型预测与真实输出之间的差距。
- 数据准备:
收集并准备数据集,该数据集包含多个输入-输出对(样本),用于训练模型。
数据集通常分为训练集、验证机和测试集,分别用于训练模型、调整超参数和评估模型性能。
- 模型构建:
选择或设计模型架构,这可以是简单的线性模型、决策树,或是复杂的神经网络。
初始化模型参数,这些参数将在训练过程中被优化。
- 迭代优化:
通过优化的方式调整模型参数,以最小化训练集上的损失函数。
在每次迭代中,计算损失函数关于模型参数的梯度,并使用优化算法(如梯度下降)更新参数。
通过验证集来监控模型的性能,防止过拟合,并调整超参数以获得更好的性能。
- 评估与部署:
使用测试集评估训练好的模型的性能,确保其具有良好的泛化能力。
部署模型到生产环境,对新数据进行预测和推理。
模型训练
求解最优化问题:通过梯度下降等优化算法,迭代更新模型参数以最小化损失函数,其中反向传播是高效计算神经网络参数梯度的关键方法。
过程涉及定义损失函数、初始化模型参数、选择优化算法、迭代更新参数(通过梯度下降和反向传播)、调整学习率和其他超参数以及评估模型性能等步骤。
- 定义损失函数:
首先我们需要根据具体任务(分类、回归等)定义一个损失函数,该函数能够量化模型预测与真实标签之间的差异。损失函数的选择取决于问题的性质和数据分布。

损失函数
- 初始化模型参数:
接下来,我们需要初始化模型的参数。这些参数将在训练过程中通过优化算法进行更新,以最小化损失函数。
- 选择优化算法:梯度下降
为了最小化损失函数,我们需要选择一个优化算法。最常用的优化算法之一是梯度下降(Gradient Descent)及其变种(如随机梯度下降SGD、小批量梯度下降Mini-batch Gradient Descent、Adam等)。
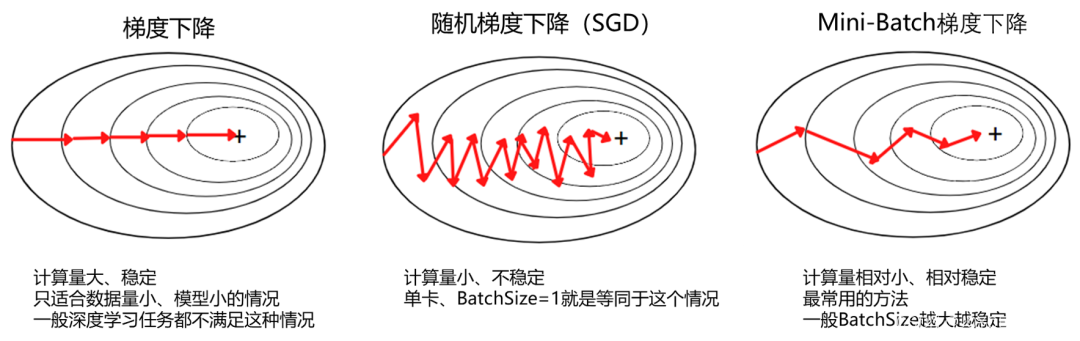
梯度下降
迭代更新参数:反向传播计算梯度
使用选定的优化算法,我们开始迭代地更新模型参数。在每次迭代中,我们计算损失函数关于模型参数的梯度,并按照梯度的相反方向更新参数。由于神经网络具有多层嵌套的结构,直接计算损失函数对所有参数的梯度非常困难,计算梯度通常通过反向传播(Backpropagation)来实现。它利用链式法则,从输出层开始逐层计算梯度,并将梯度信息反向传播到输入层。
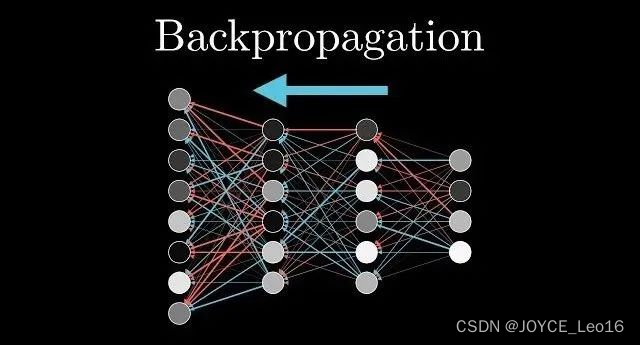
反向传播
- 调整学习率和其他超参数:
学习率是梯度下降中的一个重要超参数,它决定了参数更新的步长。过大的学习率可能导致训练不稳定,而过小的学习率可能导致收敛速度过慢。因此,需要适当地调整学习率以确保训练的稳定性和收敛速度。此外,还有其他超参数(如批量大小、正则化系数等)也需要进行调整以优化模型性能。
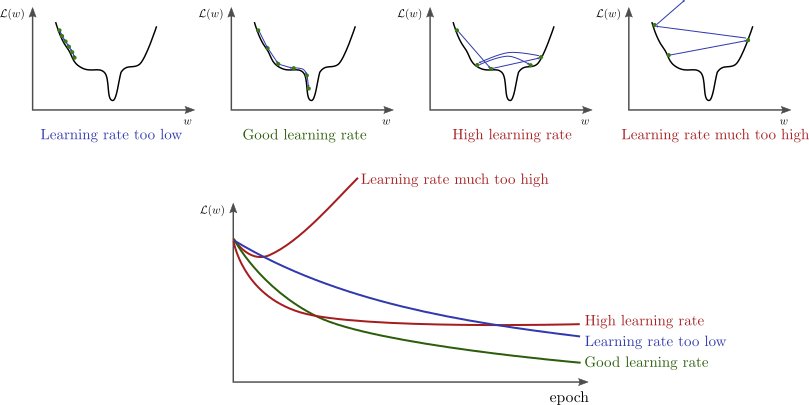
学习率
- 评估模型性能:
在训练过程中或训练结束后,我们需要评估模型的性能。这通常通过使用验证集或测试集来计算模型的准确率、召回率、F1分数等指标来完成。根据评估结果,我们可以对模型进行调整以进一步提高性能。
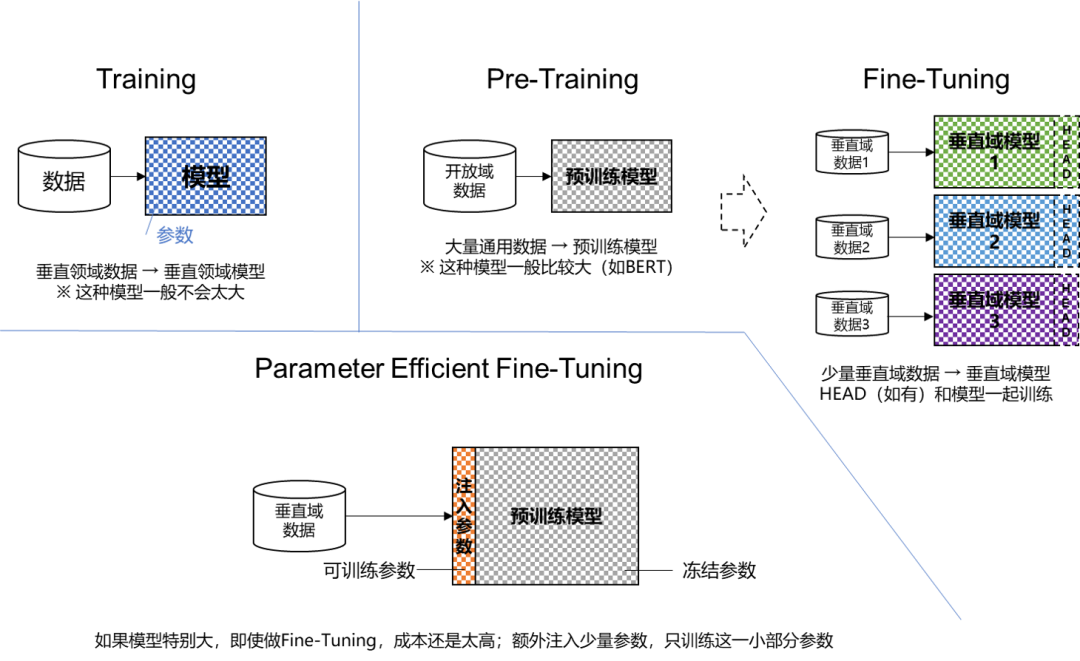
三、什么是模型微调
模型微调(Fine-tuning):通过特定领域数据对预训练模型进行针对性优化,以提升其在特定任务上的性能。
模型微调(Fine-tuning)
- 1. 微调的定义
大模型微调是利用特定领域的数据集对已预训练的大模型进一步训练的过程。它旨在优化模型在特定任务上的性能,使模型能够更好地适应和完成特定领域的任务。
- 2. 微调的核心原因
定制化功能:微调的核心原因是赋予大模型更加定制化的功能。通用大模型虽然强大,但在特定领域可能表现不佳。通过微调,可以使模型更好地适应特定领域的需求和特征。
领域知识学习:通过引入特定领域的数据集进行微调,大模型可以学习该邻域的知识和语言模式。这有助于模型在特定任务上取得更好的性能。
- 3. 微调的方式
全量微调(Full Fine-Tuning):全量微调利用特定任务数据调整预训练模型的所有参数,以充分适应新任务。它依赖大规模计算资源,但能有效利用预训练模型的通用特征。
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT):PEFT旨在通过最小化微调参数数量和计算复杂度,实现高效的迁移学习。它仅更新模型中的部分参数,显著降低训练时间和成本,适用于计算资源有限的情况。
模型微调流程:在选定相关数据集和预训练模型的基础上,通过设置合适的超参数并对模型进行必要的调整,使用特定任务的数据对模型进行训练以优化其性能。
流程包含以下四个核心步骤:
- 1. 数据准备:
选择与任务相关的数据集。
对数据进行预处理,包括清洗、分词、编码等。
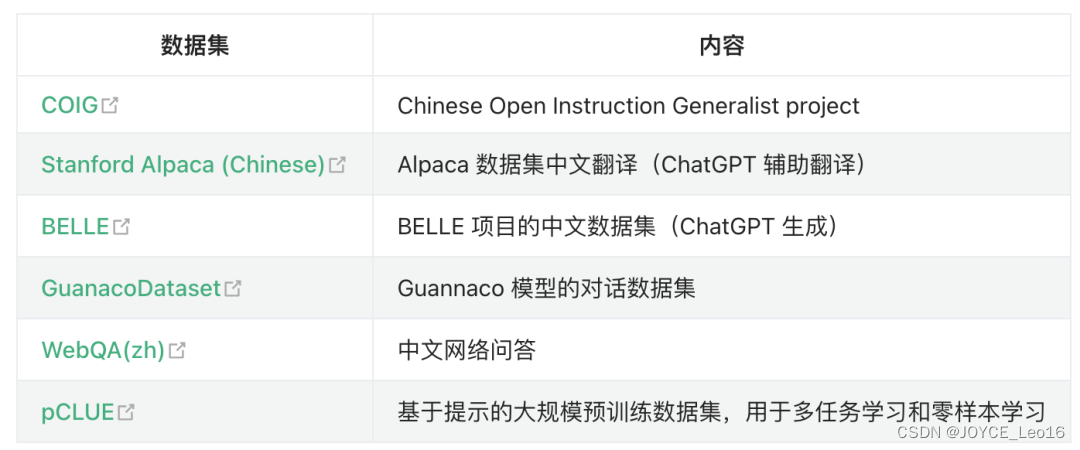
微调开源数据集
- 2. 选择基础模型:
选择一个预训练好的大语言模型,如LLaMA、ChatGLM、BERT、GPT-3等。
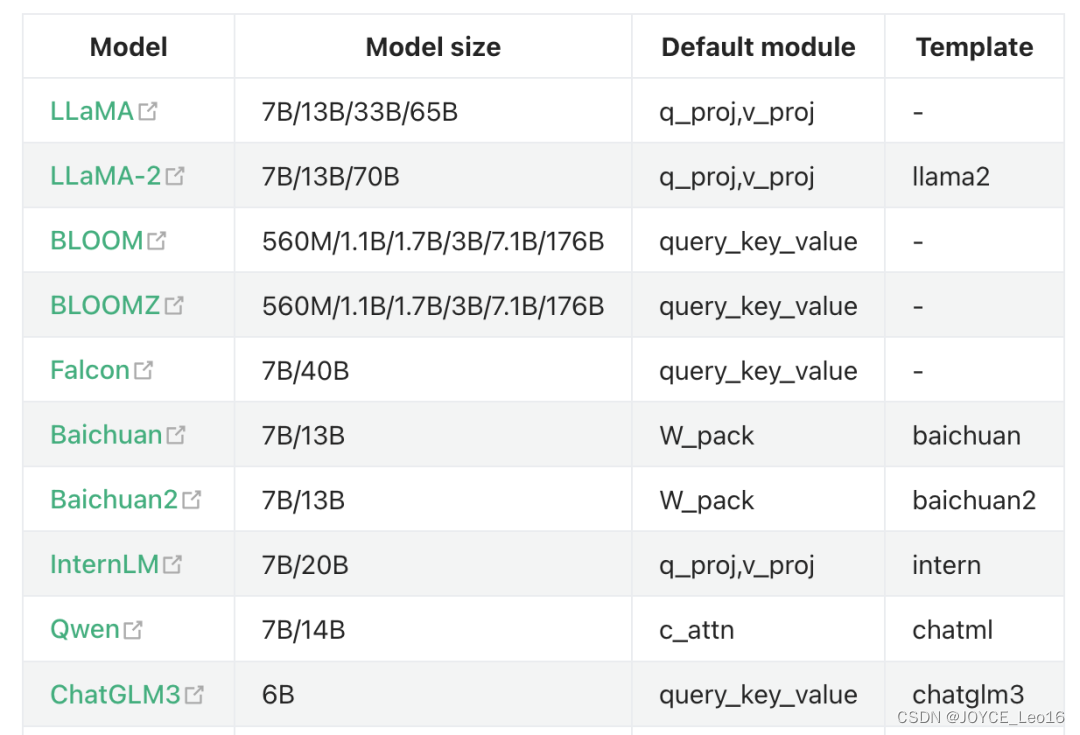
支持微调的模型
- 3. 设置微调参数:
设定学习率、训练轮次(epochs)、批处理大小(batch size)等超参数。
根据需要设定其他超参数,如权重衰减、梯度剪切等。
- 4. 微调流程:
加载预训练的模型和权重。
根据任务需求对模型进行必要的修改,如更改输出层。
选择合适的损失函数和优化器。
使用选定的数据集进行微调训练,包括前向传播、损失计算、反向传播和权重更新。
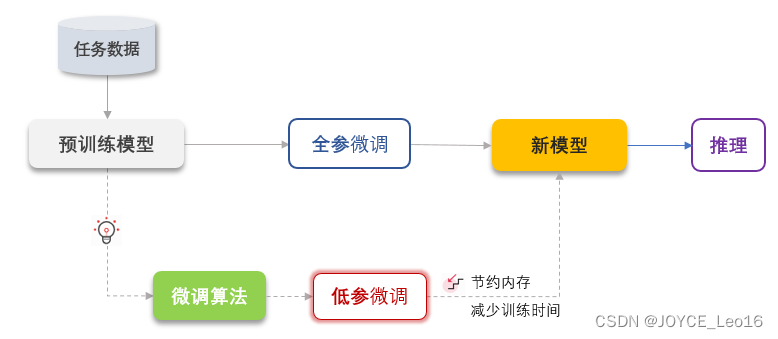
模型微调流程
参考:架构师带你玩转AI

