- 1mllib逻辑回归 spark_Spark Mllib中逻辑回归
- 2用python编写飞机3D模型
- 310种混沌映射优化灰狼算法,可一键切换,可用于优化所有群智能算法,以灰狼算法为例进行介绍...
- 4ssh服务配置
- 5【数字IC/FPGA】Verilog中的force和release_verilog force release
- 6五、SpringCloud之Gateway网关整合Eureka_spring cloud gateway eureka
- 7Stacking算法:集成学习的终极武器
- 8git diff 命令6种使用场景
- 9手机电脑投屏软件_5款免费手机投屏软件汇总(手机、电脑、电视)全投屏
- 10YOLOv5-Backbone模块实现_yolov5 1backbone
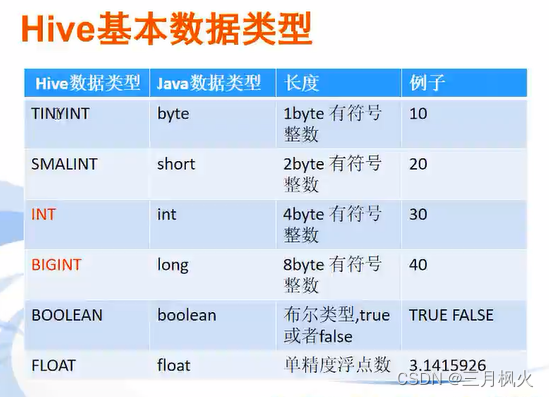
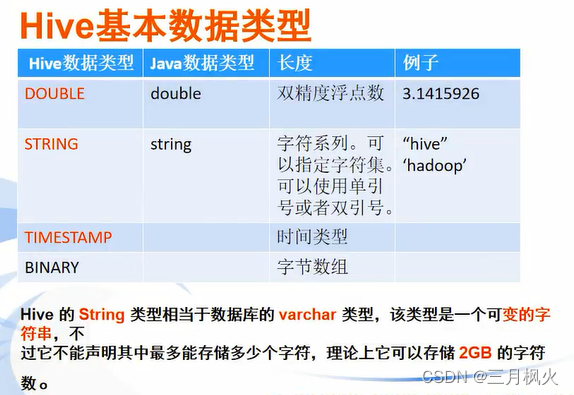
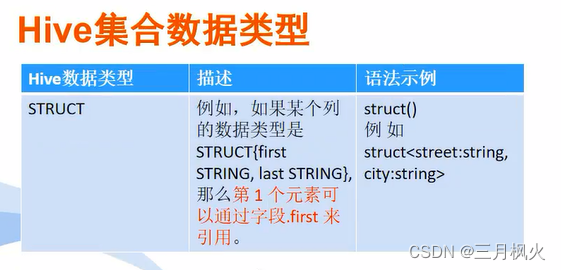
Hive基础和使用详解_hive 使用
赞
踩
一、启动hive
1. hive启动的前置条件
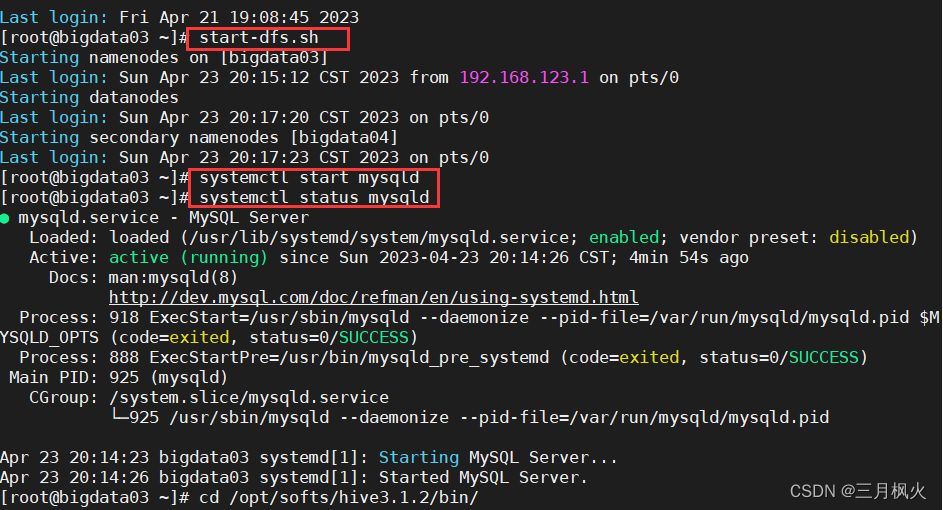

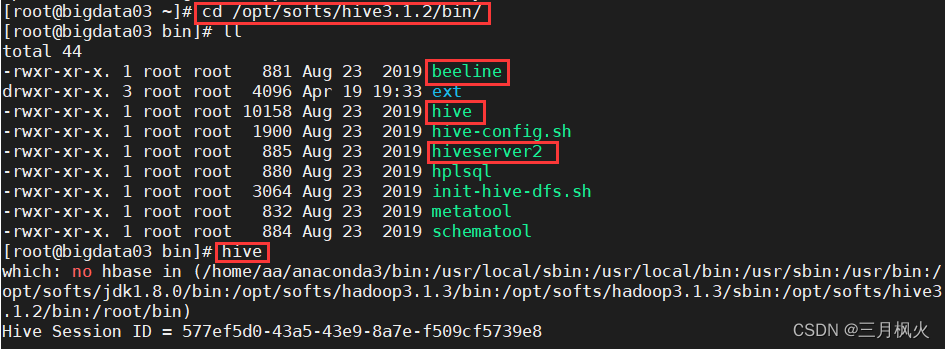
2. 启动方式一: hive命令
--切换到hive目录下的bin目录
cd /opt/softs/hive3.1.2/bin/
--执行hive命令
hive
- 1
- 2
- 3
- 4
- 5
3. 方式二:使用jdbc连接hive
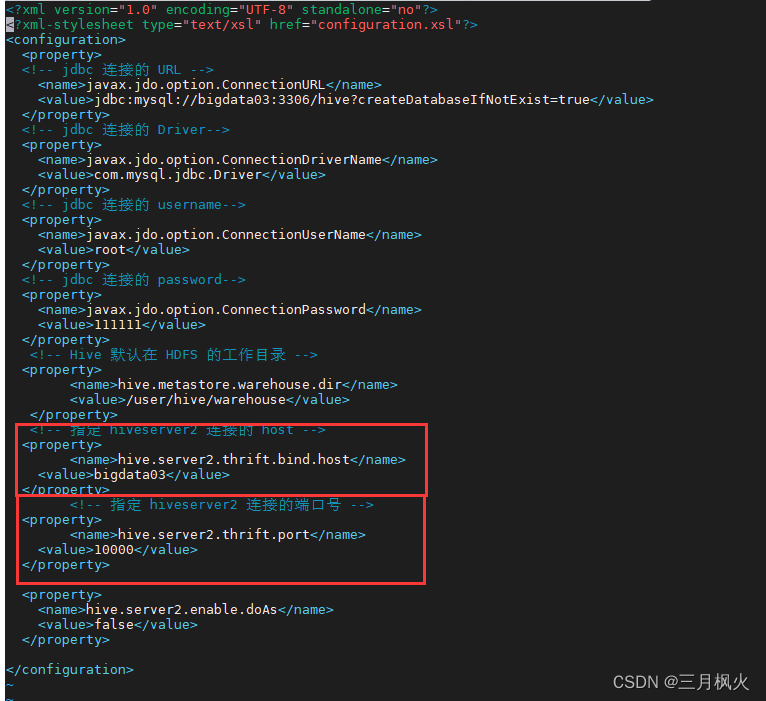
(1)在hive目录下配置文件hive-site.xml
cd /opt/softs/hive3.1.2/conf/
ll
vim hive-site.xml
- 1
- 2
- 3
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <!-- jdbc 连接的 URL --> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://bigdata03:3306/hive?createDatabaseIfNotExist=true</value> </property> <!-- jdbc 连接的 Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- jdbc 连接的 username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc 连接的 password--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>111111</value> </property> <!-- Hive 默认在 HDFS 的工作目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!-- 指定 hiveserver2 连接的 host --> <property> <name>hive.server2.thrift.bind.host</name> <value>bigdata03</value> </property> <!-- 指定 hiveserver2 连接的端口号 --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
(2) 启动hiveserver2
-- 启动hiveserver2命令 hive --service hiveserver2 -- 注意:启动hiveserver2服务需要些时间才能启动完成, 且没有返回可输入命令行的界面,需要另开一个tab页面输入执行相关的命令指令 进阶的启动方式 (1)/opt/softs/hive3.1.2目录下创建logs目录 cd /opt/softs/hive3.1.2 mkdir logs (2)执行如下命令 cd /opt/softs/hive3.1.2/bin/ nohup hive --service hiveserver2 1>/opt/softs/hive3.1.2/logs/hive.log 2>/opt/softs/hive3.1.2/logs/hive_err.log & -- nohup:放在命令的开头,表示的意思为不挂起即关闭终端进程也保持允许状态 --1:代表标准日志输出 --2:表示错误日志输出 -- &:代表在后台运行 所以整个命令可以理解为:将hiveserver2服务后台运行在标准日志输出到hive.1og,错误日志输出到hive_err.log,唧使关闭终端(窗口),也会保持运行状态
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(3)执行beeline命令
beeline -u jdbc:hive2://bigdata03:10000 -root
- 1
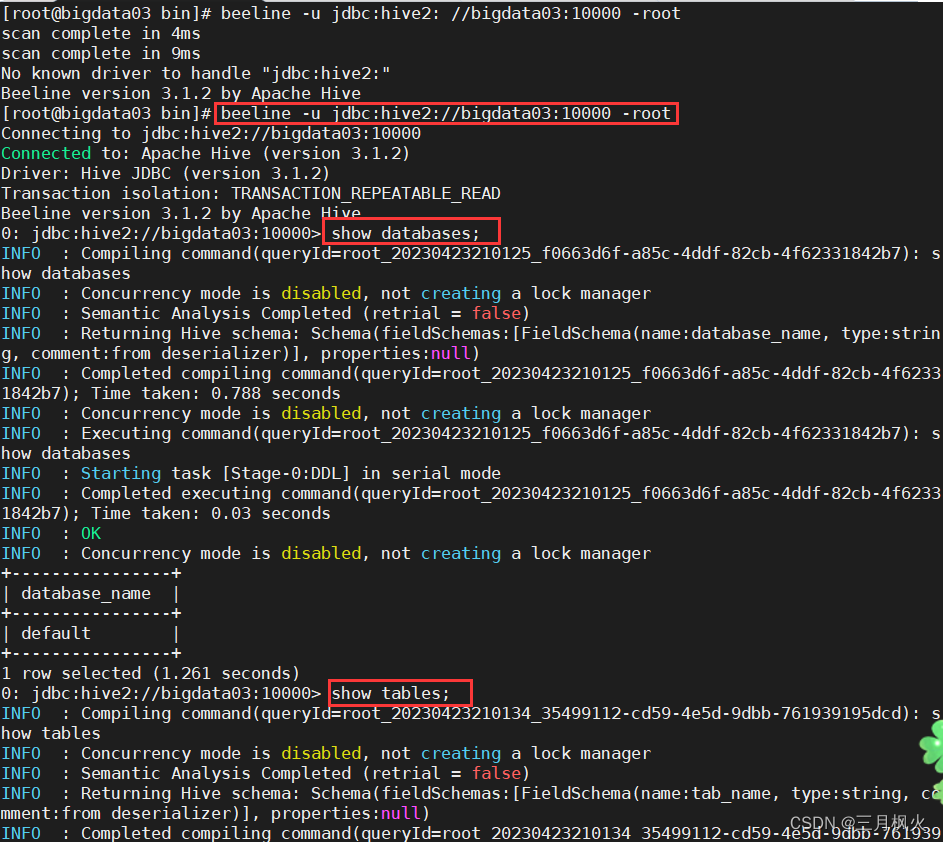
进阶:
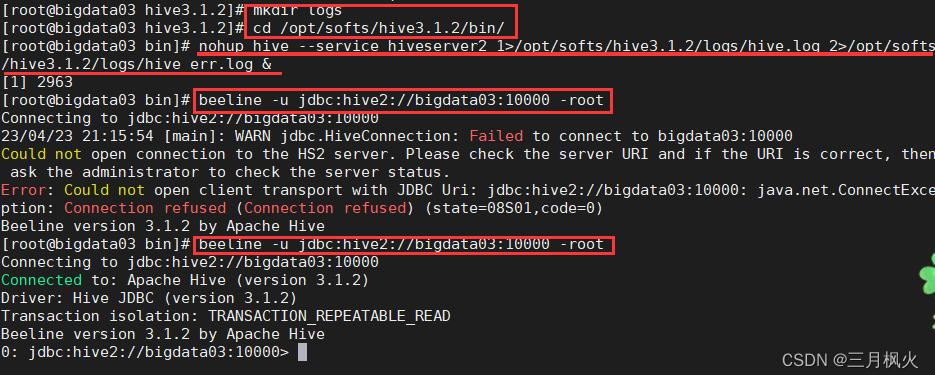
注意:执行beeline命令时可能会报错,因为启动hiveserver2需要两三分钟时间,只有等hiveserver2启动完成后,可能用beeline命令完成jdbc连接。
二、Hive常用交互命令
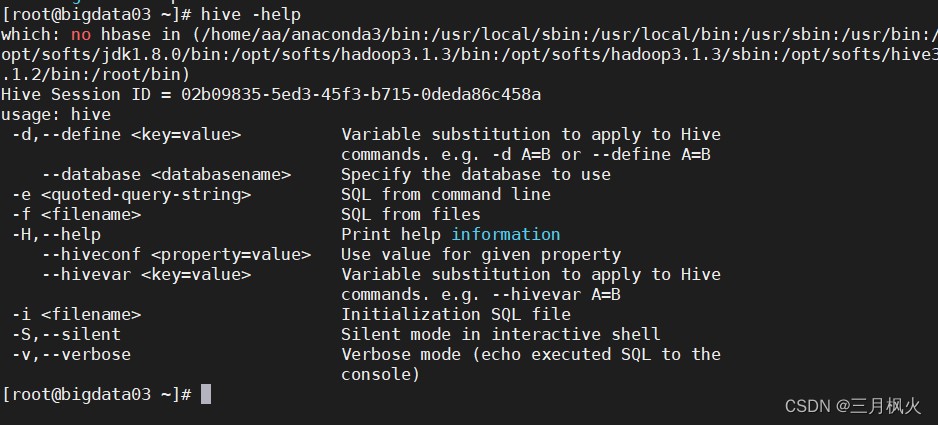
1. hive -help 命令
hive -help
- 1
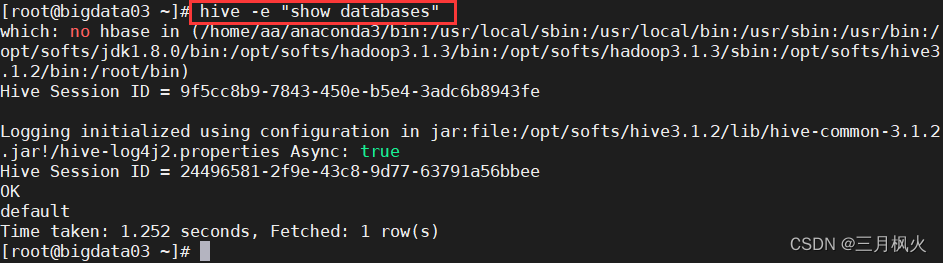
2. hive -e 命令
hive -e "show databases"
- 1
不进入hive的交互窗口执行sql语句
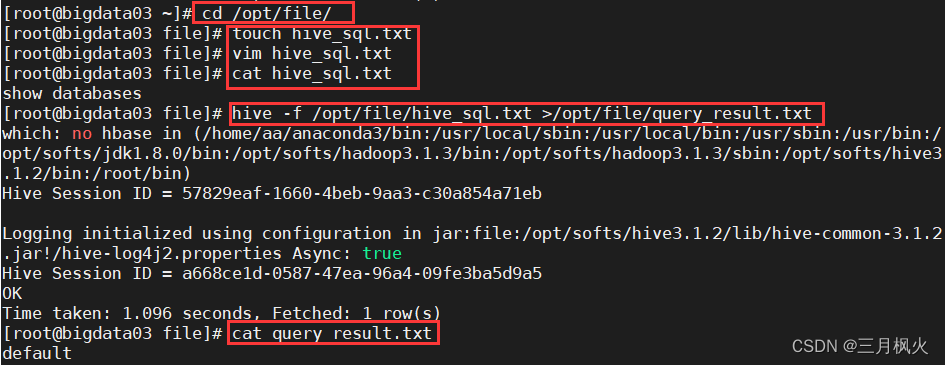
3. hive -f 命令
执行文件中的sql语句
-- 创建文件
cd /opt/file/
touch hive_sql.txt
vim hive_sql.txt
- 1
- 2
- 3
- 4
- 5
-- 添加sql语句命令“show databases”
show databases
- 1
- 2
cat hive_sql.txt
-- 将执行结果写入到新文件中
hive -f /opt/file/hive_sql.txt >/opt/file/query_result.txt
-- 查看执行结果
cat query_result.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4. 退出hive窗口
(1) exit;
(2) quit;
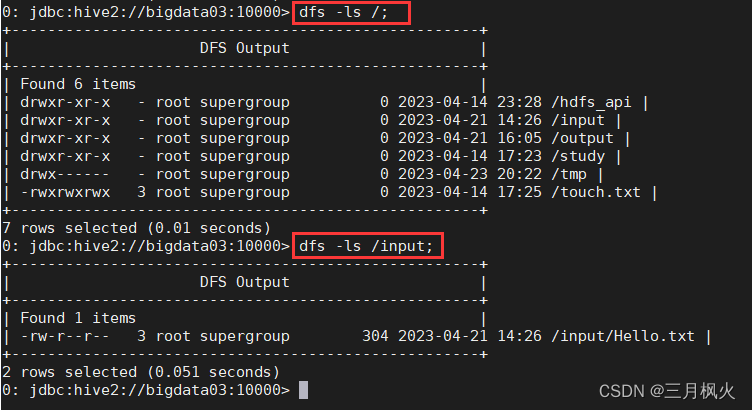
5. 在hive窗口中执行dfs -ls /;
在hive窗口中执行 dfs -ls /; 查看hdfs文件系统
三、Hive语法
1.DDL语句


1.1 创建数据库
create database if not exists bigdata;
- 1
- 2
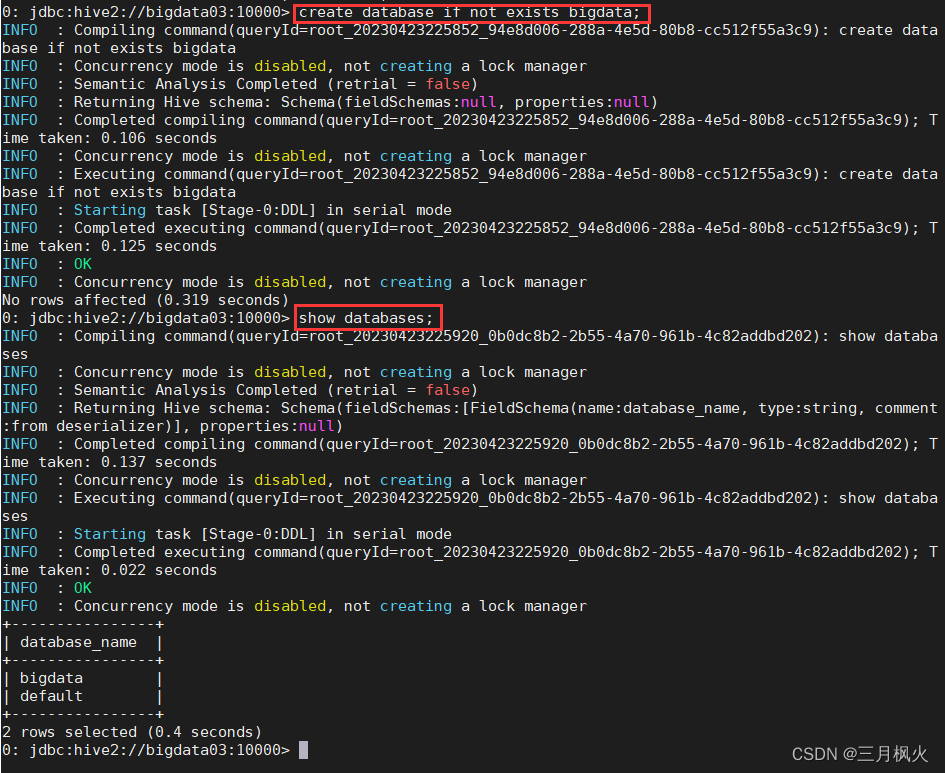
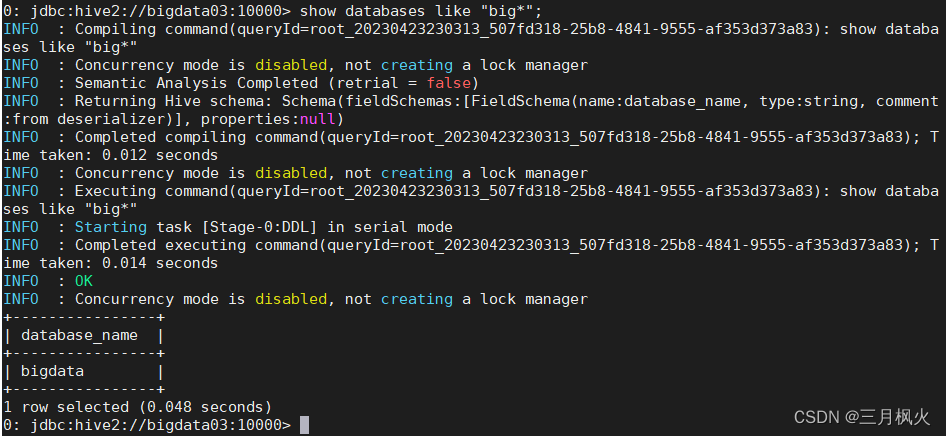
1.2 两种方式查询数据库

show databases;
show databases like "big*";
- 1
- 2
1.3 显示数据库信息

desc database bigdata;
desc database extended bigdata;
- 1
- 2
- 3
- 4
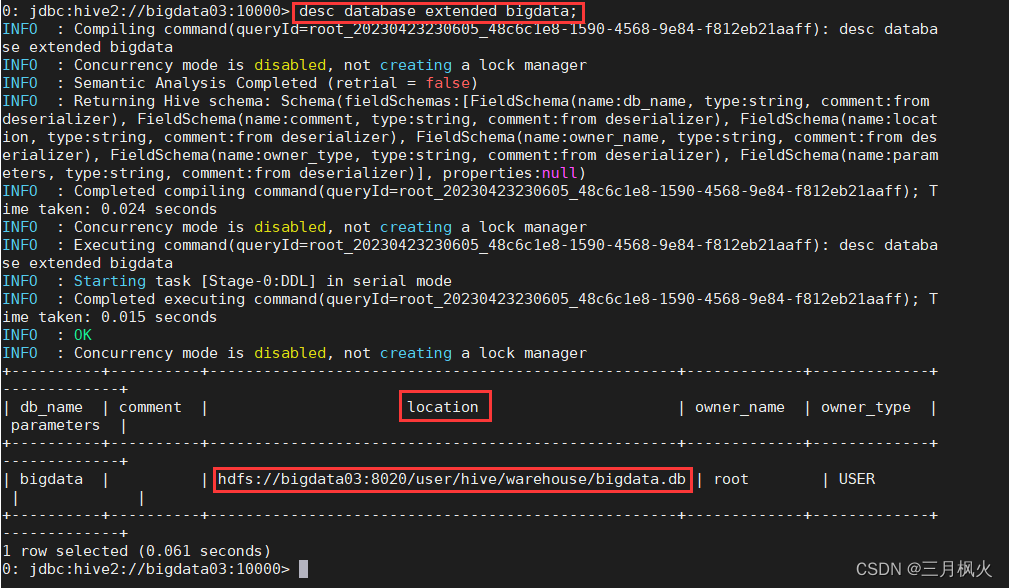
1.4 切换数据库

1.5 修改数据库配置信息

alter database bigdata set dbproperties('createtime'='20230423');
desc database extended bigdata;
- 1
- 2
- 3
- 4
- 5
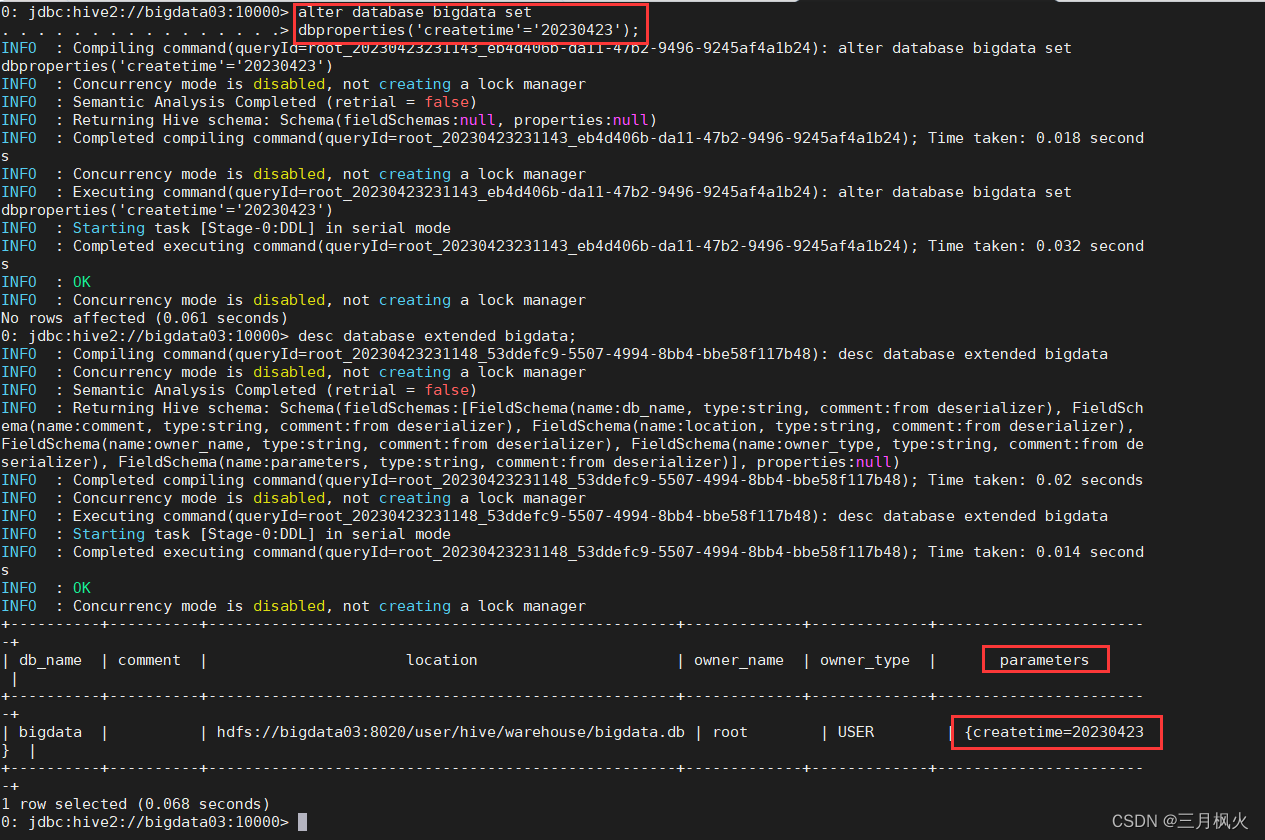
同时也可以看到数据在hdfs上的存储路径(Location):
hdfs://bigdata03:8028/user/hive/warehouse/bigdata.db
1.6 删除数据库
注意:两种语法对应的一个是 空数据库,一个是 非空数据库

1.7 创建hive表(重点)

1.7.1 hive详细的建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXIST] table_name [(col_name data_type [COMMENT COL_COMMENT],.....)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment],....)] [CLUSTERED BY (col_name,col_name,....)] [SORTED BY (col_name [ASC|DESC],...)] INFO num_buckets BUCKETS] [ROW FORMAT DELIMITED FIELDS TERMINATED BY ','] [STORED AS file_format] [LOCATION hdfs_path] 字段解释 1 CREATE TABLE创建一个指定名字的表,如果名字相同抛出异常,用户可以使用IF NOT EXIST来忽略异常 2 EXTERNAL关键字可以创建一个外部表,在建表的同时指定一个实际数据的路径(LOCATION) ,hive在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据 3 COMMENT是为表和列添加注释 4 PARTITIONED BY是分区表 5 CLUSTERED BY 是建分桶(不常用) 6 SORTED BY 是指定字段进行排序(不常用) 7 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' 是指每行数据中列分隔符为"," 默认分隔符为" \001" 8 STORED AS 指定存储文件类型,数据文件是纯文本,可以使用STORED AS TEXTFILE 9 LOCATION 指定表在HDFS上的存储位置,内部表不要指定, 但是如果定义的是外部表,则需要直接指定一个路径。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
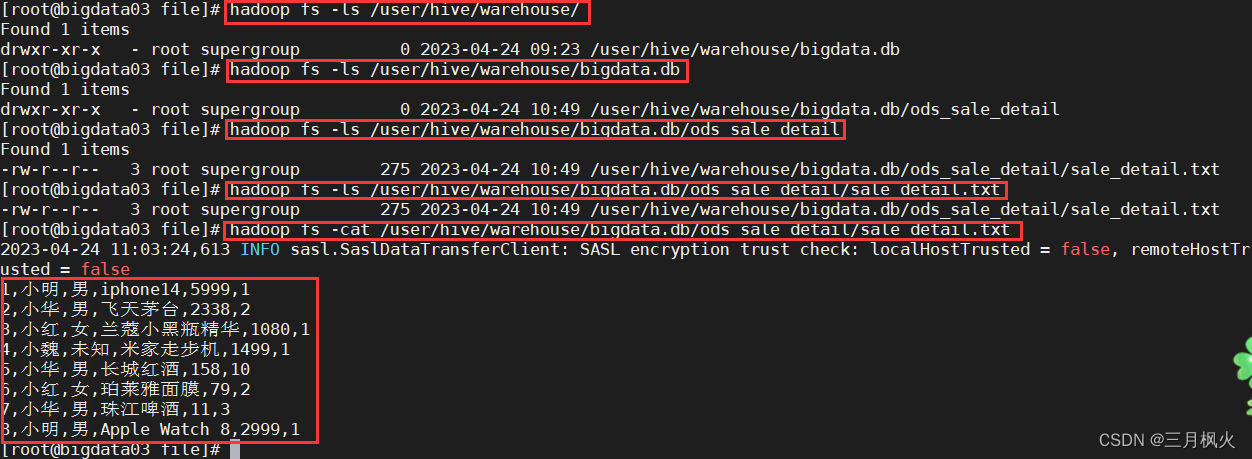
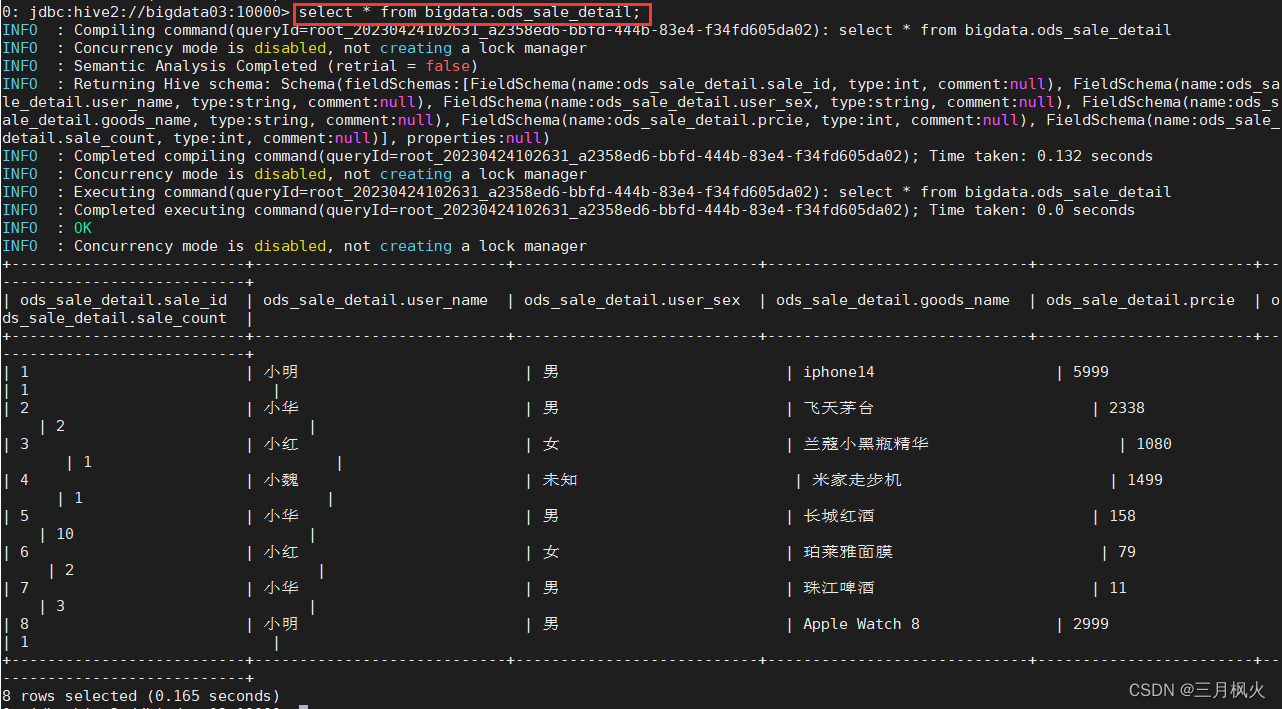
对sale_detail 中的数据:
1,小明,男,iphone14,5999,1
2,小华,男,飞天茅台,2338,2
3,小红,女,兰蔻小黑瓶精华,1080,1
4,小魏,未知,米家走步机,1499,1
5,小华,男,长城红酒,158,10
6,小红,女,珀莱雅面膜,79,2
7,小华,男,珠江啤酒,11,3
8,小明,男,Apple Watch 8,2999,1
1.7.2 创建hive内部表:
CREATE TABLE IF NOT EXISTS bigdata.ods_sale_detail
(
sale_id INT COMMENT "销售id"
,user_name STRING COMMENT "用户姓名"
,user_sex STRING COMMENT "用户性别"
,goods_name STRING COMMENT "商品名称"
,prcie INT COMMENT "单价"
,sale_count INT COMMENT "销售数量"
)
COMMENT "销售内部表"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
STORED AS TEXTFILE;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
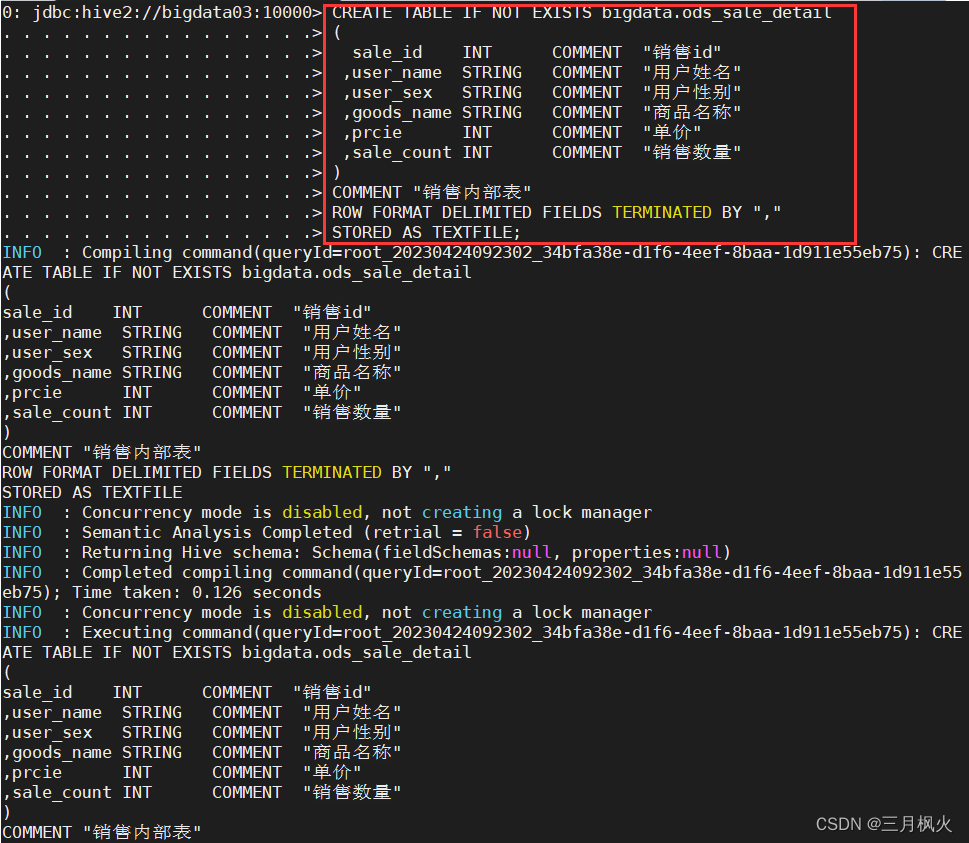
查看建表结果
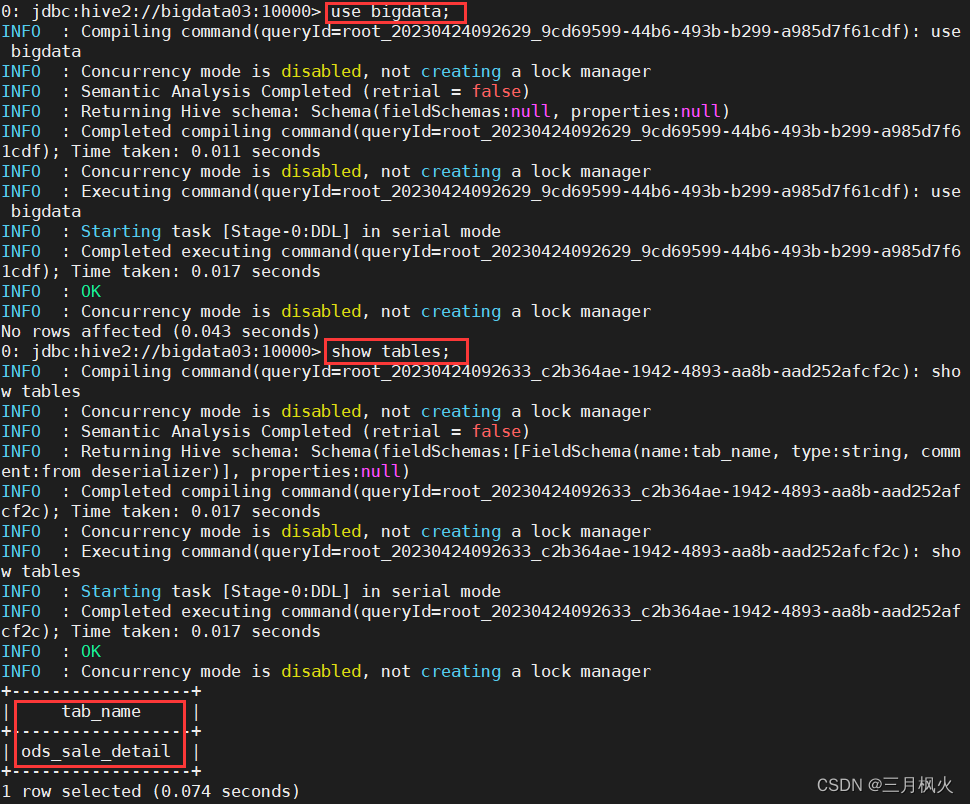
1.7.3 创建hive外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS bigdata.ods_sale_detail_external
(
sale_id INT COMMENT "销售id"
,user_name STRING COMMENT "用户姓名"
,user_sex STRING COMMENT "用户性别"
,goods_name STRING COMMENT "商品名称"
,price INT COMMENT "单价"
,sale_count INT COMMENT "销售数量"
)
COMMENT "销售外部表"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
STORED AS TEXTFILE
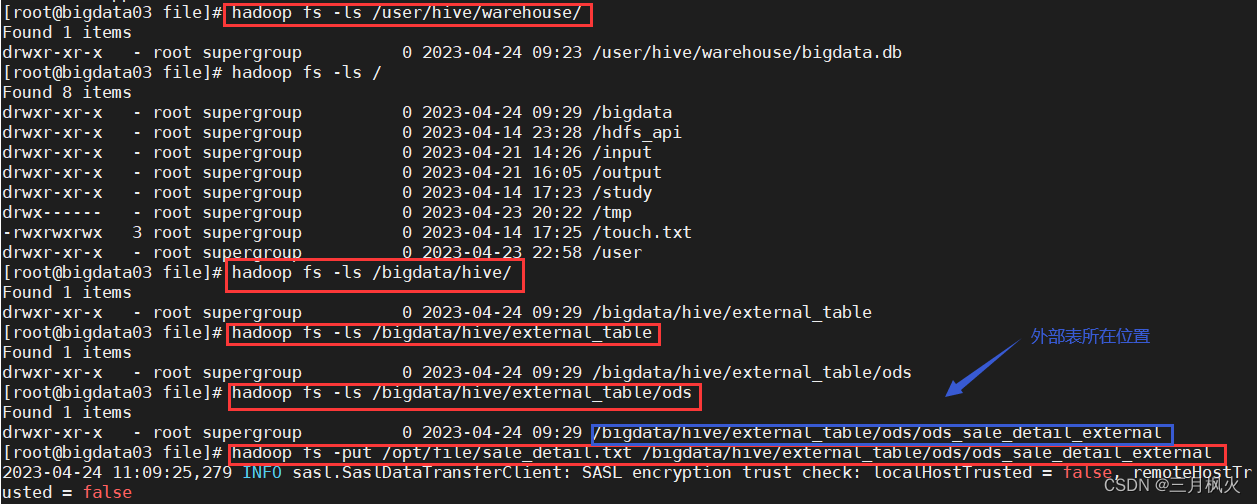
LOCATION "/bigdata/hive/external_table/ods/ods_sale_detail_external";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
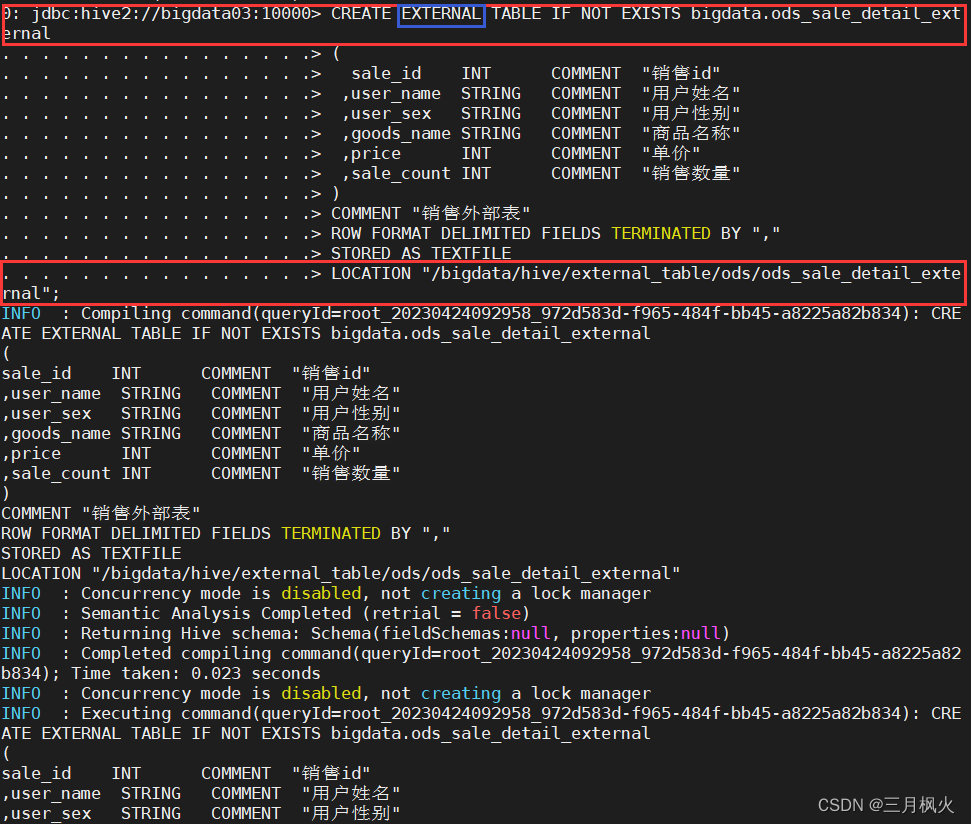
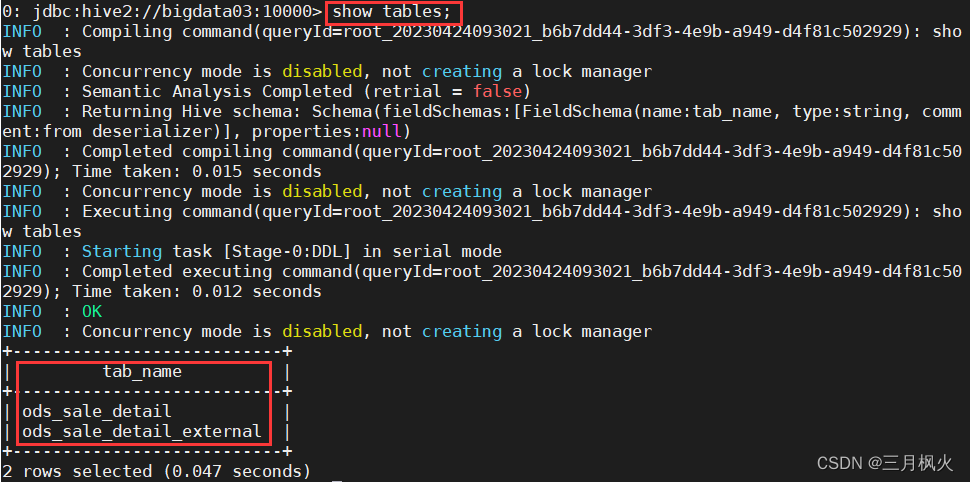
2. DML语句
2.1 向表中装载数据(Load)

在虚拟机bigdata03的 /opt/file目录下创建 sale_detail.txt 文件, 添加:
1,小明,男,iphone14,5999,1
2,小华,男,飞天茅台,2338,2
3,小红,女,兰蔻小黑瓶精华,1080,1
4,小魏,未知,米家走步机,1499,1
5,小华,男,长城红酒,158,10
6,小红,女,珀莱雅面膜,79,2
7,小华,男,珠江啤酒,11,3
8,小明,男,Apple Watch 8,2999,1
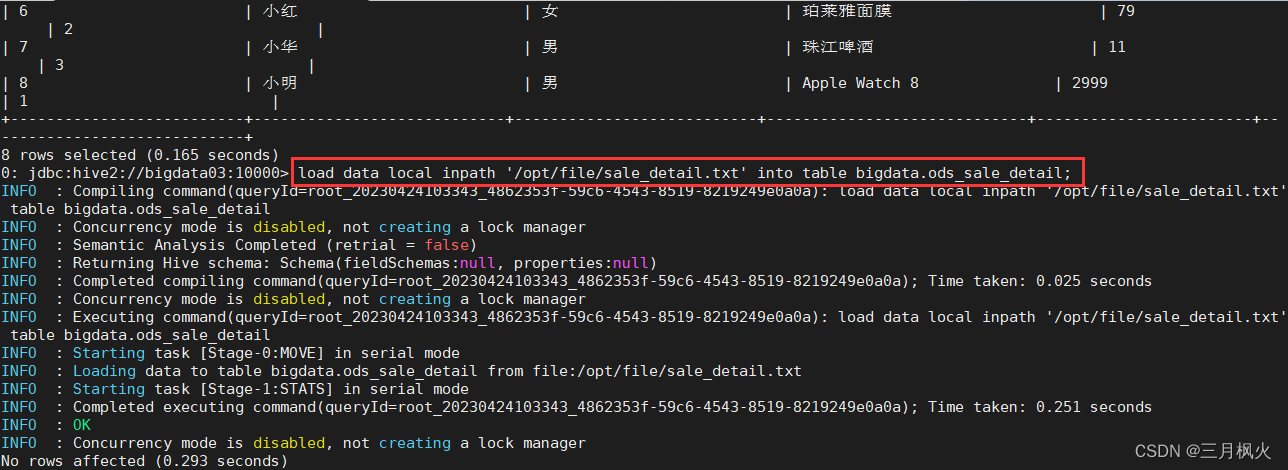
-- load data [local] inpath '数据的 path' [overwrite] into table dbname.tablename [partition (partcol1=val1,…)];
-- 不含overwrite,多次执行装载Load会不去重
load data local inpath '/opt/file/sale_detail.txt' into table bigdata.ods_sale_detail;
- 1
- 2
- 3
- 4
- 5
- 6
Load命令 不含overwrite,多次执行装载Load会不去重
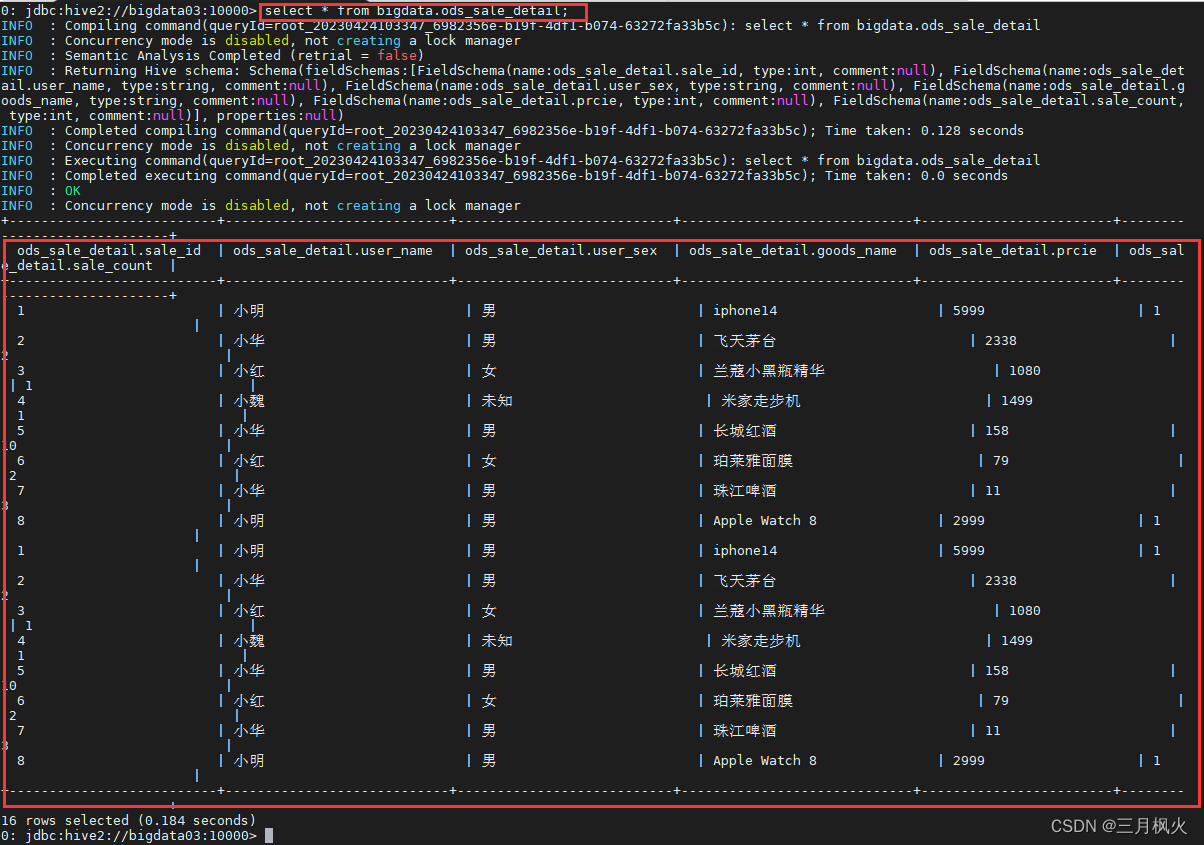
再次执行Load命令:
再次查看数据表,会发现数据会再次追加,不会去重
2.2 Load命令 添加 overwrite, 数据去重
Load命令 添加 overwrite,多次执行装载Load会去重
load data local inpath '/opt/file/sale_detail.txt' overwrite into table bigdata.ods_sale_detail;
- 1
- 2
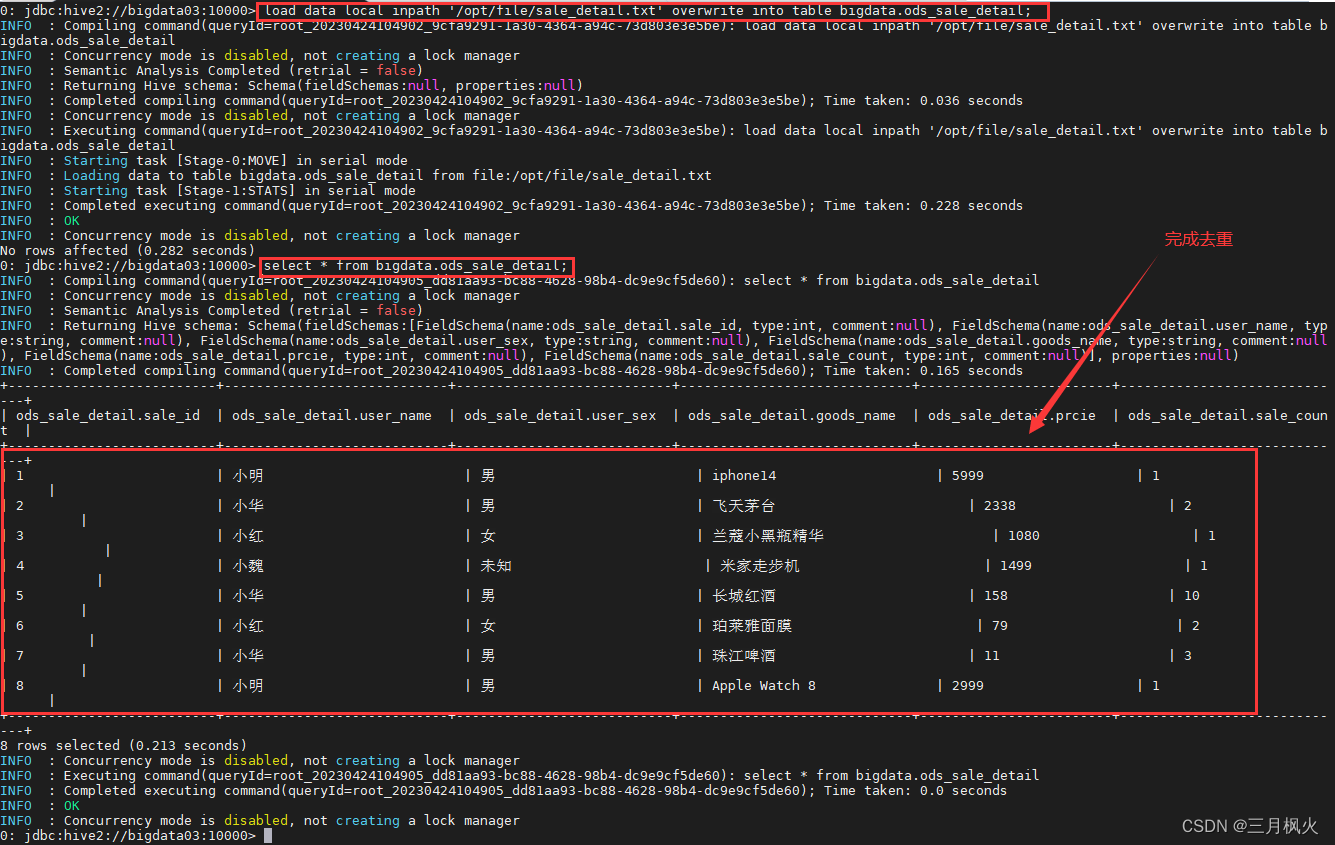
利用含数据的txt文件,添加数据到外部表中
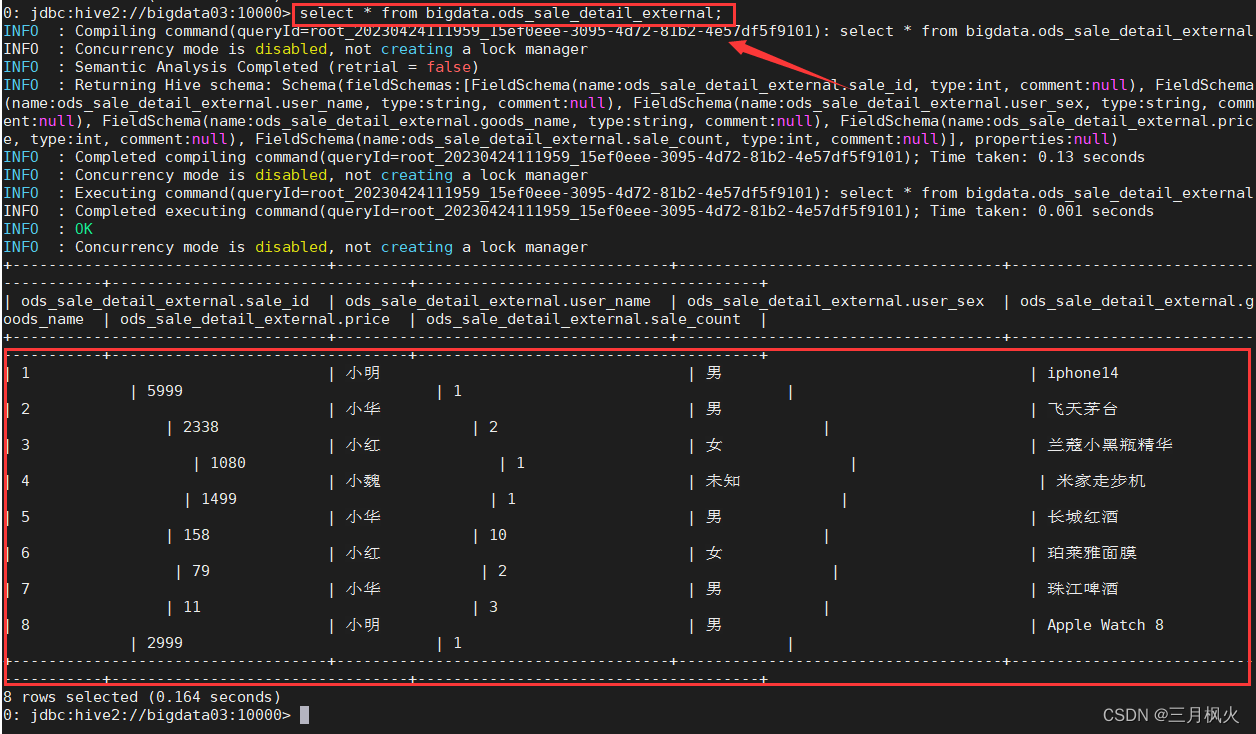
hadoop fs -put /opt/file/sale_detail.txt /bigdata/hive/external_table/ods/ods_sale_detail_external
- 1
- 2
命令行界面查询外部表数据:
查看建表信息
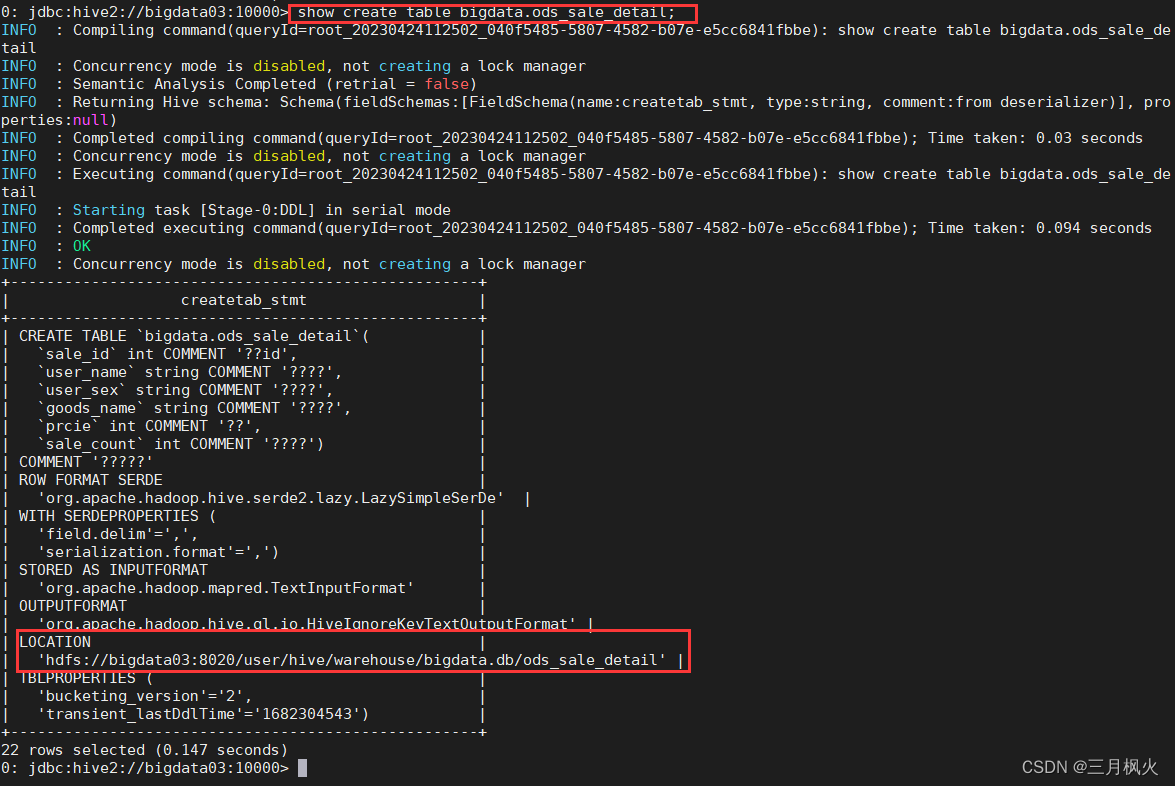
可以发现表bigdata.ods_sale_detail的存储路径等信息
LOCATION
| ‘hdfs://bigdata03:8020/user/hive/warehouse/bigdata.db/ods_sale_detail’ |
2.3 删除内部表
删除内部表ods_sale_detail
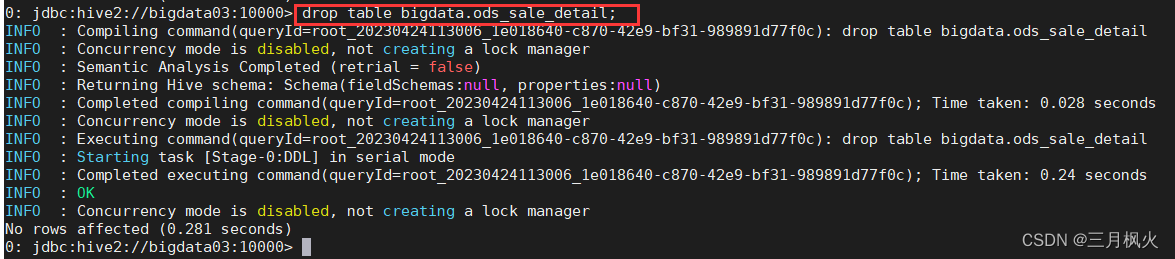
drop table bigdata.ods_sale_detail;
- 1
- 2
删除后查看该内部表是否还存在:
hadoop fs -ls /user/hive/warehouse/bigdata.db/ods_sale_detail
删除成功(表和数据一起删除):

2.4 删除外部表
删除外部表ods_sale_detail_external
drop table bigdata.ods_sale_detail_external;
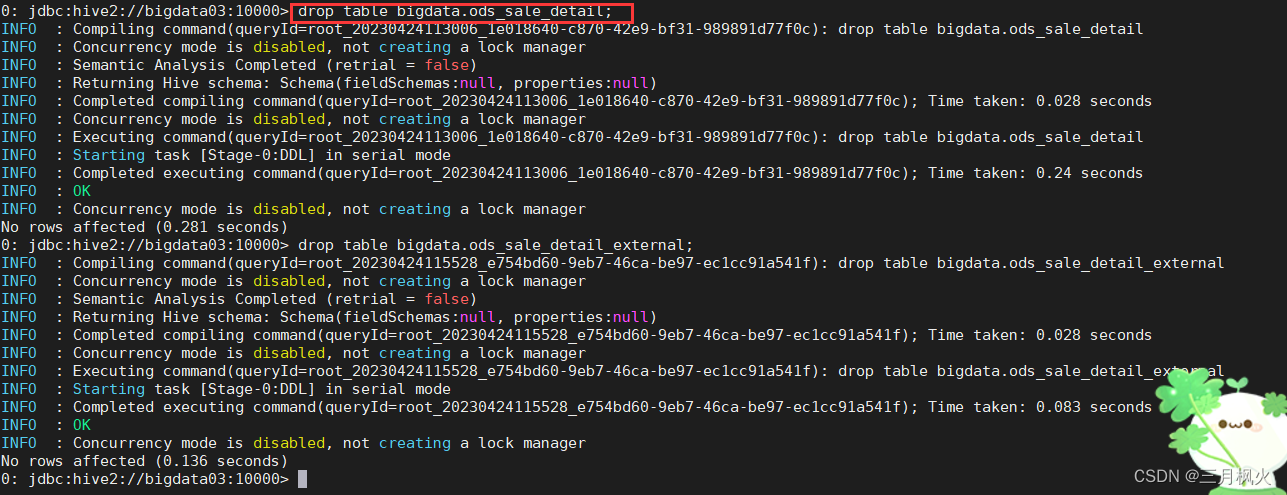
删除外部表后,只删表结构,不能在命令行界面查询

但外部文件还在,数据依旧保留

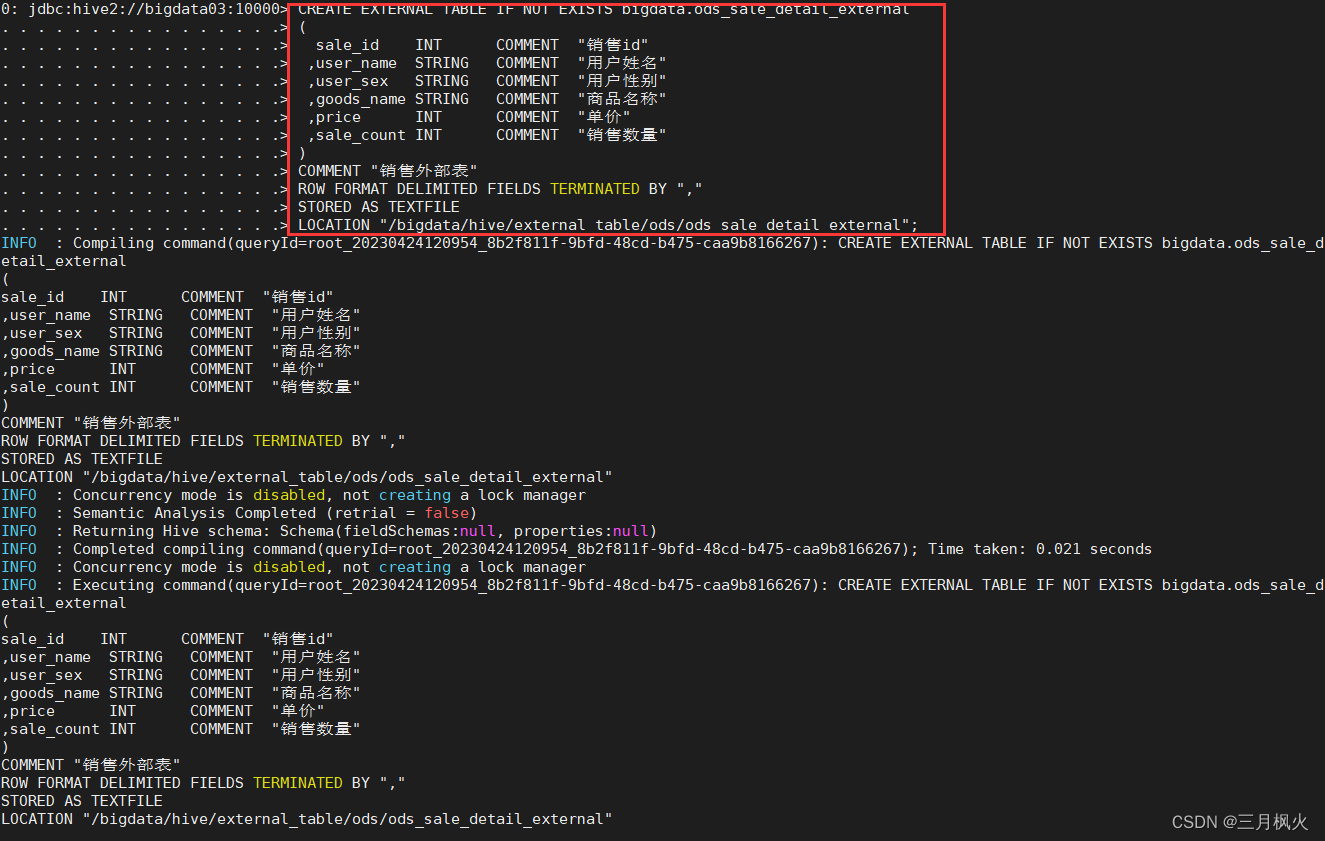
当再次创建hive外部表时:
CREATE EXTERNAL TABLE IF NOT EXISTS bigdata.ods_sale_detail_external
(
sale_id INT COMMENT "销售id"
,user_name STRING COMMENT "用户姓名"
,user_sex STRING COMMENT "用户性别"
,goods_name STRING COMMENT "商品名称"
,price INT COMMENT "单价"
,sale_count INT COMMENT "销售数量"
)
COMMENT "销售外部表"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
STORED AS TEXTFILE
LOCATION "/bigdata/hive/external_table/ods/ods_sale_detail_external";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
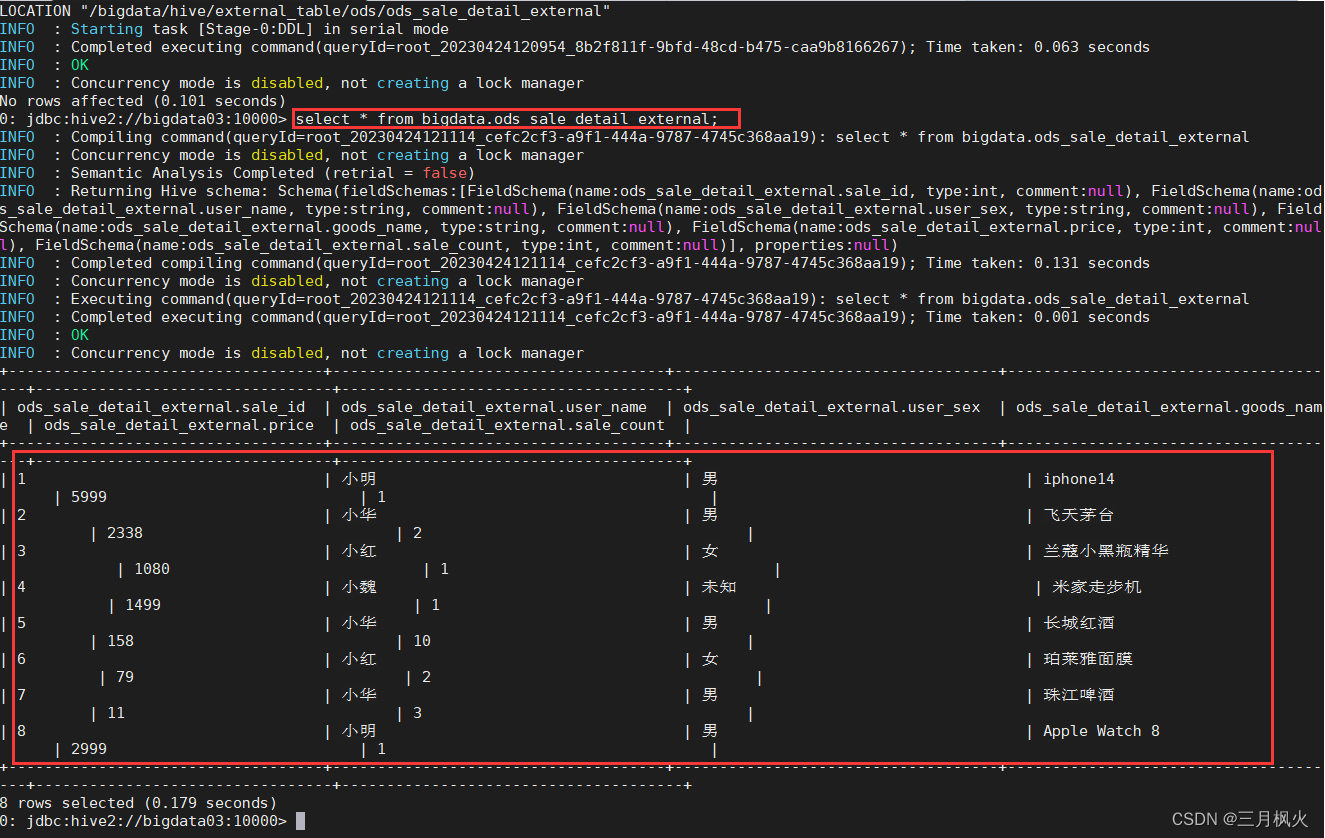
依然可以在命令行界面查询数据:
select * from bigdata.ods_sale_detail_external;
四、Hive其他参考资料