
- 1next 14 appRouter redux数据持久化_nextjs redux 持久化存储
- 2mac与windows服务器 访问和共享
- 3Android 15全面解读:性能飙升、隐私守护与智能生活新纪元_安卓15
- 4标题:怎样通过Dialogflow构建一个聊天机器人?React版。_dialogflow机器人
- 5连接Mongodb数据库的步骤以及注意事项_如何连接mongodb数据库
- 6小程序公告php实现,小程序两种滚动公告栏的实现方法
- 7Git仓库完整迁移全过程_gitee 将a仓库的克隆到b仓库
- 8FP6381AS5CTR原厂SOT23-5 1.2A同步降压IC DC-DC变频器
- 9STM32参考代码,编译时出现“cannot open source input file, no such file or directory"错误
- 10微信小程序用户隐私保护指引设置指南_mp后台-设置-基本设置-服务内容声明-用户隐私保护指引]中声明“剪切板”隐私收集
Github 1.9K Star的数据治理框架-Amundsen
赞
踩

Amundsen的使命,整理有关数据的所有信息,并使其具有普遍适用性。
这是Amundsen官网的一句话,对于元数据的管理工作,复杂且繁琐。可用的工具很多但各有千秋,数据血缘做的较好的应该是Apache Atlas,而数据可视化做的较好的应该是Apache Superset。业界一直需要一个可以整合这些功能,让数据治理更加的简单便捷,而这正是Amundsen的使命。
类似于Atlas (Apache),Datahub (LinkedIn)。Amundsen主要在于提高数据分析师,数据科学家和数据工程师的工作效率。它可以通过为数据资源建立索引,并通过一定的机制来支持在页面上进行排名搜索。可以将其视为搜索功能,但搜索的是元数据。该项目以挪威探险家Roald Amundsen(第一个发现南极的人)的名字命名。
Amundsen由LF AI&Data基金会维护。LF AI&Data是Linux Foundation的保护基金会,支持人工智能,机器学习,深度学习和数据方面的开源创新。

目前Amundsen在github有1.9kStar,还没有Releases的版本,项目正处于蒸蒸日上的上升期。

架构
下图显示了Amundsen的总体架构。

可见,Hive,Presto等数据源通过Databuilder ingestion框架获取元数据,写入Elasticsearch和Neo4j,通过搜索服务与元数据服务提供给前端。
主要模块如下:
前端服务
作为用户交互的web页面。
这是基于Flask的Web应用程序,页面是React构建的。
搜索服务
搜索服务采用Elasticsearch的搜索功能(或者Apache Atlas),并提供一个RESTful API服务。
元数据服务
元数据服务目前使用的Neo4j的图数据库进行交互。
功能展示
Amundsen提供了搜索,推荐,表描述,数据预览在内的非常多的功能,数据血缘功能正在研发中。
以上是部分功能展示:
登陆页面:Amundsen的登陆页面

搜索预览:查看搜索结果
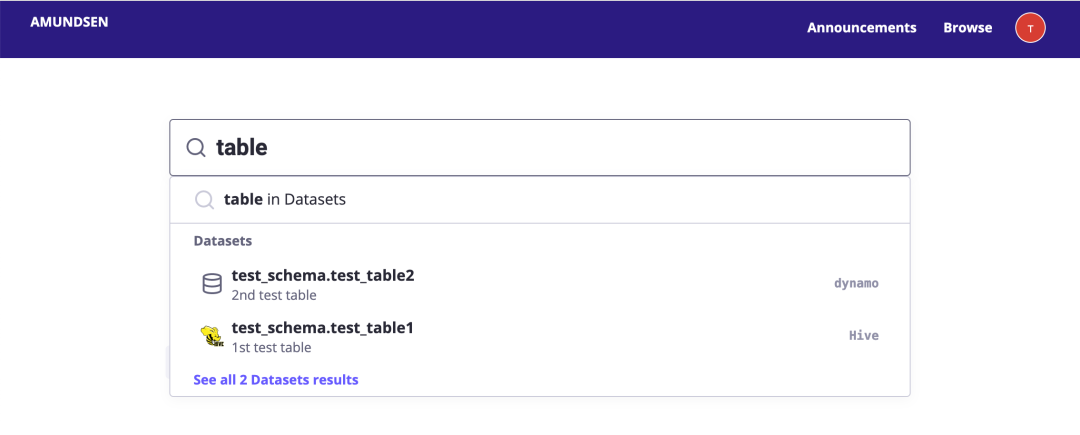
表的详细页面:Hive 等表的可视化

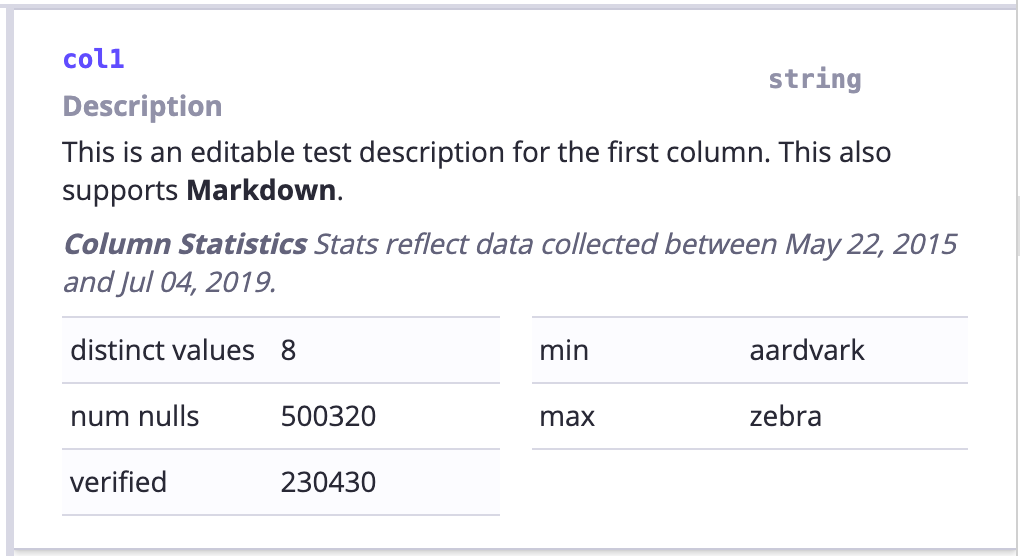
列详细信息:主要是一些列的统计信息
数据预览页面:表数据预览的可视化,可以与Apache Superset或其他数据可视化工具集成。

集成
Amundsen支持的数据源非常多。
Apache Druid,Apache Hive,CSV,Oracle,
Mysql,Delta Lake等等。
Amundsen还可以连接到任何提供dbapi或sql_alchemy接口的数据库。
同时Amundsen还支持和一些仪表盘的集成,比如
Redash,Tableau。
ETL工具的集成,Apache Airflow。
BI可视化工具,Apache Superset。
未来规划
作为数据治理领域的未来之星,Amundsen有着非常好的计划。
2021年愿景
可以和所有的数据源进行集成,解决越来越多的数据治理问题。
近期工作重点
数据血缘(设计完成)
集成数据质量系统(进行中)
列值过滤(已开始)
搜索结果层次结构(计划中)
当然,还有很多计划中的功能,这里不一一列举。
期待未来Amundsen的发展,我们也将对其新版本与新功能的发布持续关注!

