
- 1现代循环神经网络(GRU、LSTM)(Pytorch 14)
- 2微服务架构下,SpringCloud集成分布式文件存储中间件:FastDFS
- 3id门禁卡复制到手机_使用iPhone解锁开门?手机复制门禁卡教程分享
- 4java第一阶段 demo实例hashoperate及承抽象函数和实现接口_operate接口的实现类代码
- 5用户分享 | 飞凌嵌入式i.MX9352开发板外设功能测试
- 6面向 5G 的新型多载波传输技术比较_滤波组多载波技术特点和作用
- 7合肥特殊教育中专学校计算机,安徽省特殊教育中专学校2021年招生简章
- 8git如何拉取本地没有的远程分支_git fetch一个本地不存在的分支
- 9一个缓存泛型自动处理队列,留有处理事件接口
- 10【环境安装】nodejs 国内源下载与安装以及 npm 国内源配置
浅谈Kafka2.8+在Windows下的搭建与使用_kafka-clients 版本 对应
赞
踩
前言:
周末空闲时间无意找到了一套个性化推荐的源码,整体项目运用了SSH,HDFS,Flume,Hive,Kafka,Spark,Scala等。运行时,本来通过spark计算业务埋点数据时,却发现本地没有Kafka。因为我一直也没使用过Kafka,所以也作为新人,浅谈以下Kafka的环境安装与分别在PHP,Scala中的使用。
对比:
1. 横向,相比其他中间件。
关于kafka与其他消息中间件的比较,网上很多的博主,不管是从运行原理还是中间件架构都有很详细的介绍。因为我平时用Rabbit居多,在没有看别人介绍前。Rabbi比Kafka于PHP开发更友好。因为kafka除了PHP的composer依赖包常年不更新外,kafka在windows下的PHP扩展需要自己编译。从这一点上看Rabbit就更适合业务性的消息队列,更别说他还有事务等对消息消费的高保障。kafka在数据增量方面更具优势,所以多数在大数据和推荐系统中都有运用。
2. 纵向,相比其他版本。
如标题所见,这里主要是2.8+与之前版本的对比。因为在2.8以前,kafka安装前需要安装zookeeper。这里只是一小个区别,其他的新特性具体参考kafka官方文档,因为我看到网上关于kafka的安装文章,别人都会安装zookeeper,所以这里就特别说明以下,以及后面启动时与其他人博客的不同。
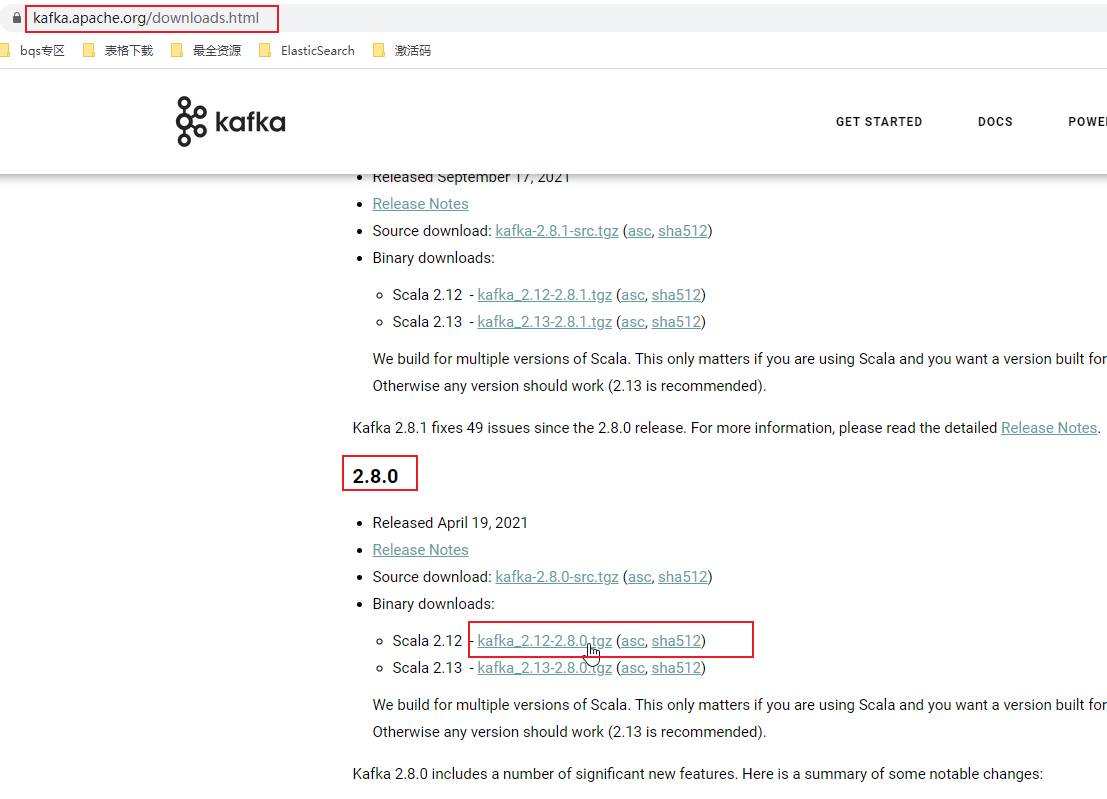
安装:
1. 下载
下载地址可以在浏览器搜索kafka官网自行下载,见上图。
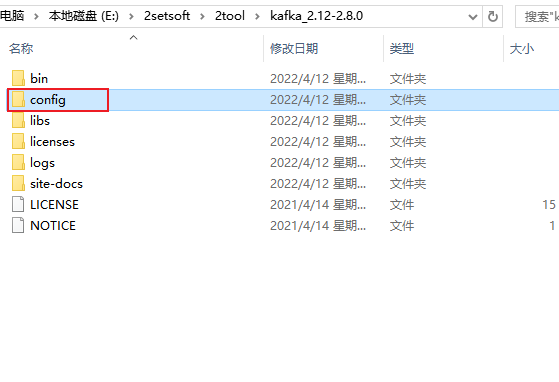
2. 配置
下载完后目录结构如下,进入config, 主要对zookeeper.properties和server.properties进行分布节点,服务端口,日志存放目录等等的设置,前期也是什么不用管保持默认配置进行启动。
3. 启动
也不知道是不是从2.8开始,bin目录下多了一个windows。所以在windows下启动进入到改目录,运行如下命令执行bat文件。注意启动的时候先zookeeper后kafka,停止的时候先kafka后zookeeper。
(1). zookeeper启动
zookeeper-server-start.bat ..\..\config\zookeeper.properties &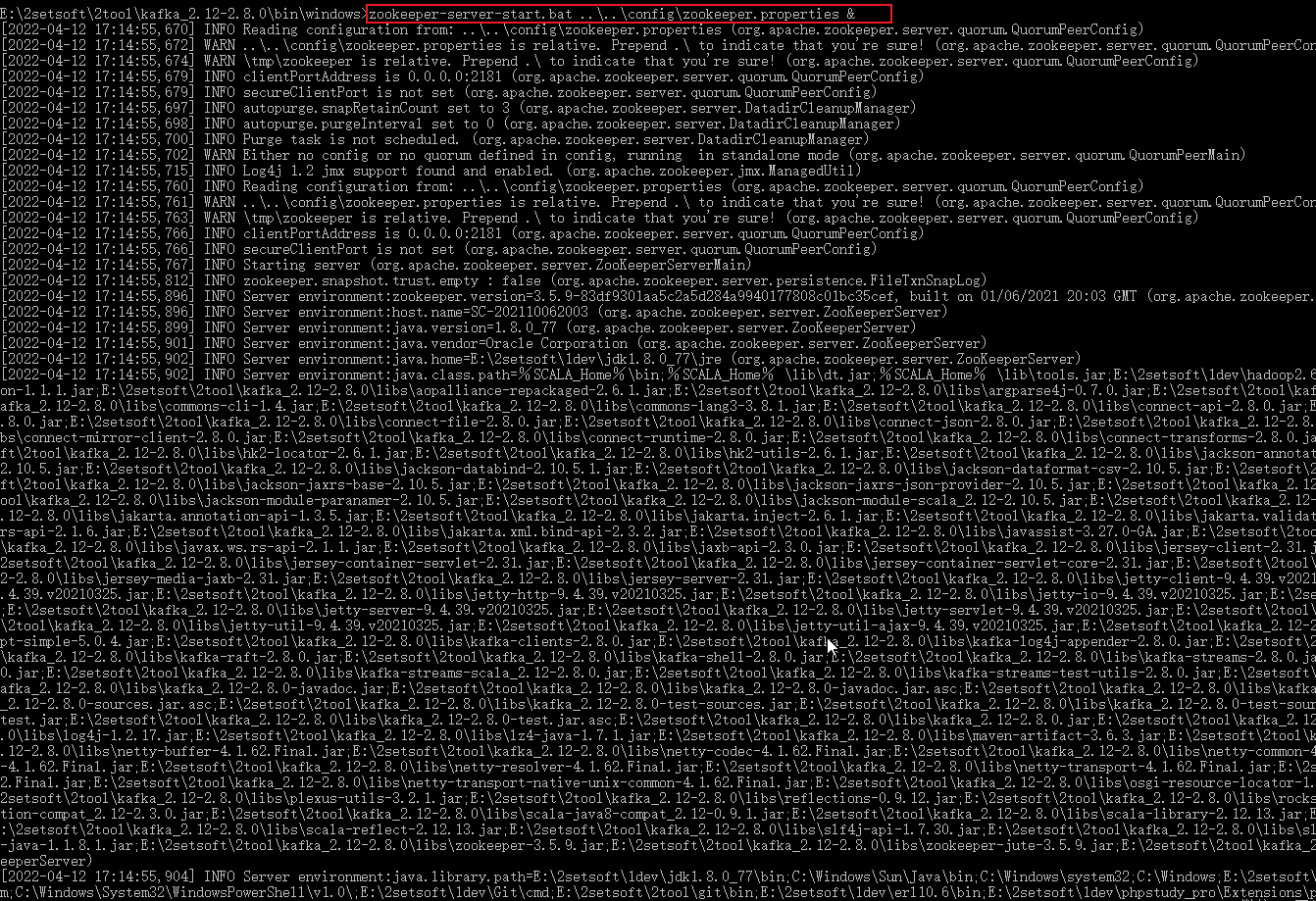
(2).kafka启动
kafka-server-start.bat ..\..\config\server.properties &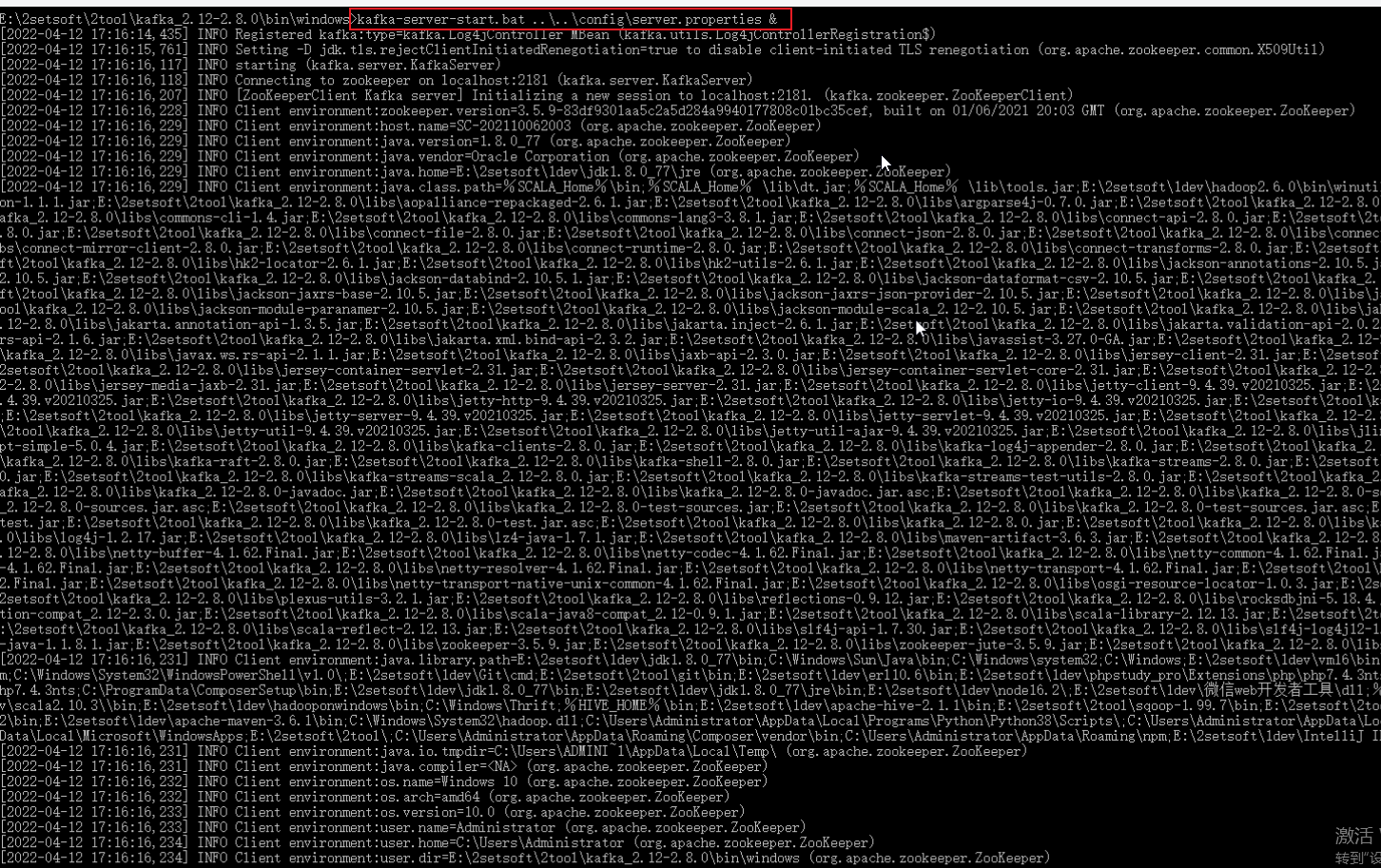
(3). 其他命令
- 查看所有topics
- kafka-topics.bat --list --zookeeper localhost:2181
- 新增topics
- kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Kafka存储机制:
-
topic中partition存储分布
-
partiton中文件存储方式
-
partiton中segment文件存储结构
-
在partition中通过offset查找message
图形化工具:
前期可以借助图形化工具快速具象的查看kafka的消息数据,也能便于理解其基本操作流程。以下推荐一块桌面端工具——offsetexplorer,可以在网上搜索下载,当然web控制台也不错,比如kafka manager。
1. kafka连接
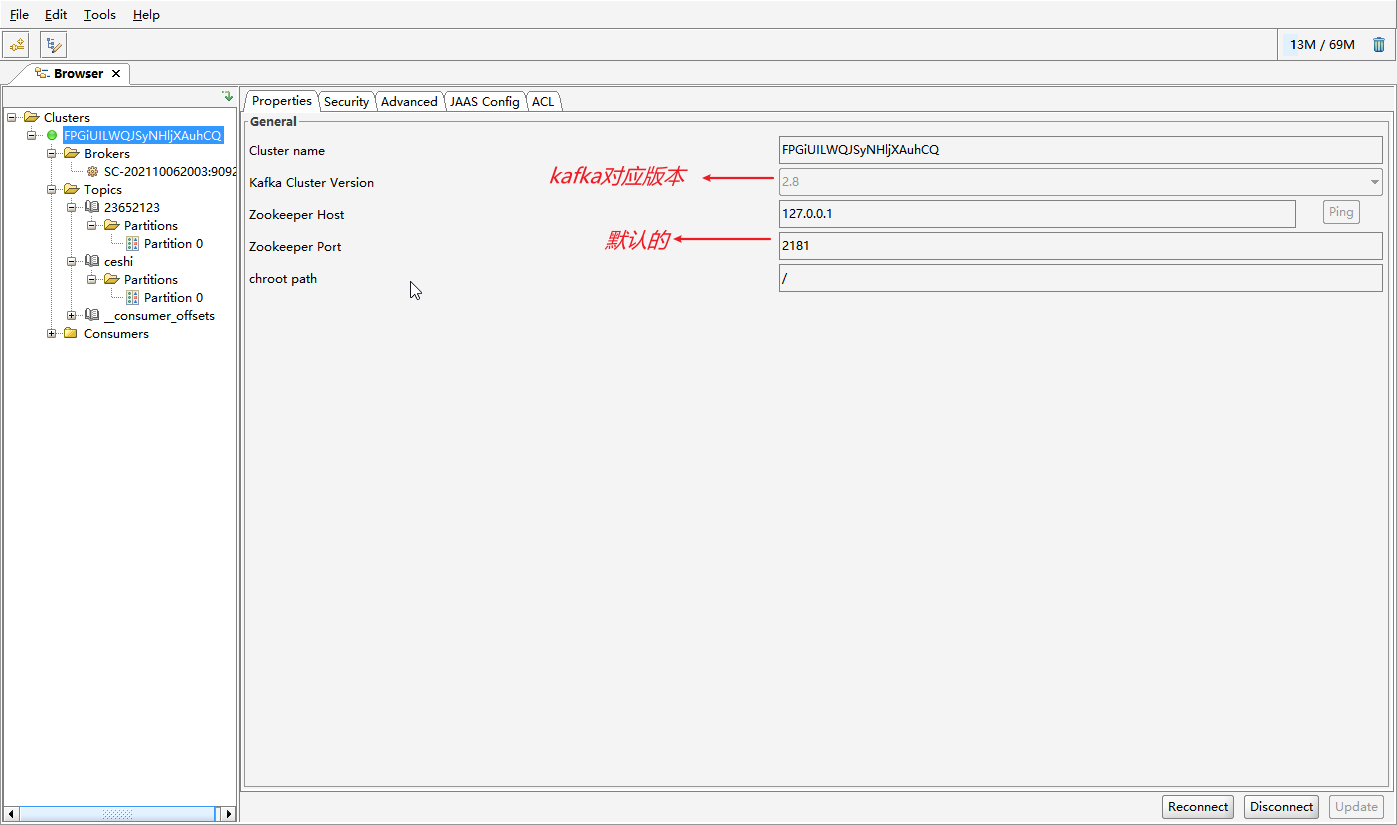
(2). Cluster name查看
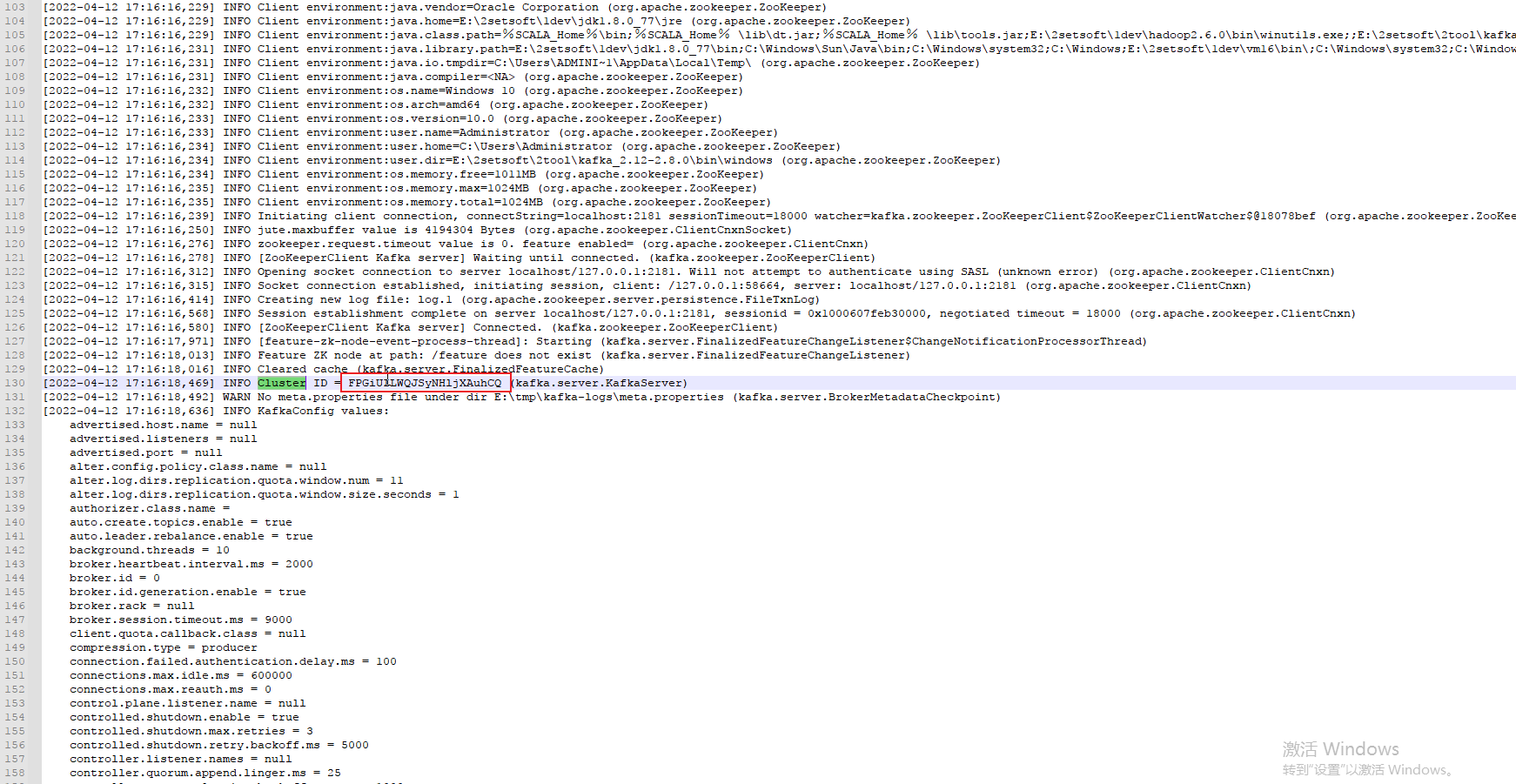
这个值如果没有设置的情况是生成的,可以在启动日志中查看,根目录/logs/server.log
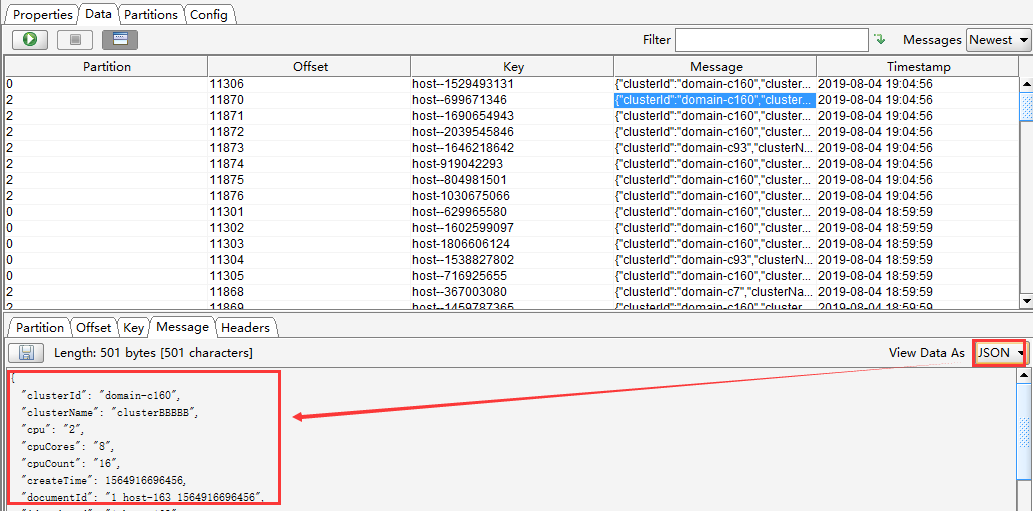
(3). Topics查看
通过运行一下新增topics或新增消息后就可以在Offset Explorer查看了,更多的使用方法也可以在网上找到。

PHP操作:
1. 下载依赖
composer require nmred/kafka-php2. 生产者 Producer.php
- <?php
-
- require './vendor/autoload.php';
-
- date_default_timezone_set('PRC');
-
- /* 创建一个配置实例 */
- $config = \Kafka\ProducerConfig::getInstance();
-
- /* Topic的元信息刷新的间隔 */
- $config->setMetadataRefreshIntervalMs(10000);
-
- /* 设置broker的地址 */
- $config->setMetadataBrokerList('127.0.0.1:9092');
-
- /* 设置broker的代理版本 */
- $config->setBrokerVersion('1.0.0');
-
- /* 只需要leader确认消息 */
- $config->setRequiredAck(1);
-
- /* 选择异步 */
- $config->setIsAsyn(false);
-
- /* 每500毫秒发送消息 */
- $config->setProduceInterval(500);
-
- /* 创建一个生产者实例 */
- $producer = new \Kafka\Producer();
-
- for($i = 0; $i < 100; $i++ ) {
- $producer->send([
- [
- 'topic' => 'test',
- 'value' => 'test'.$i,
- ],
- ]);
- }

3. 消费者 Consumer.php
- <?php
-
- require './vendor/autoload.php';
-
- date_default_timezone_set('PRC');
-
- $config = \Kafka\ConsumerConfig::getInstance();
- $config->setMetadataRefreshIntervalMs(10000);
- $config->setMetadataBrokerList('127.0.0.1:9092');
- $config->setGroupId('test');
- $config->setBrokerVersion('1.0.0');
- $config->setTopics(['test']);
-
- $consumer = new \Kafka\Consumer();
- $consumer->start(function($topic, $part, $message) {
- var_dump($message);
- });
Scala操作:
1. 创建基于Maven的Scala项目
(1). 创建
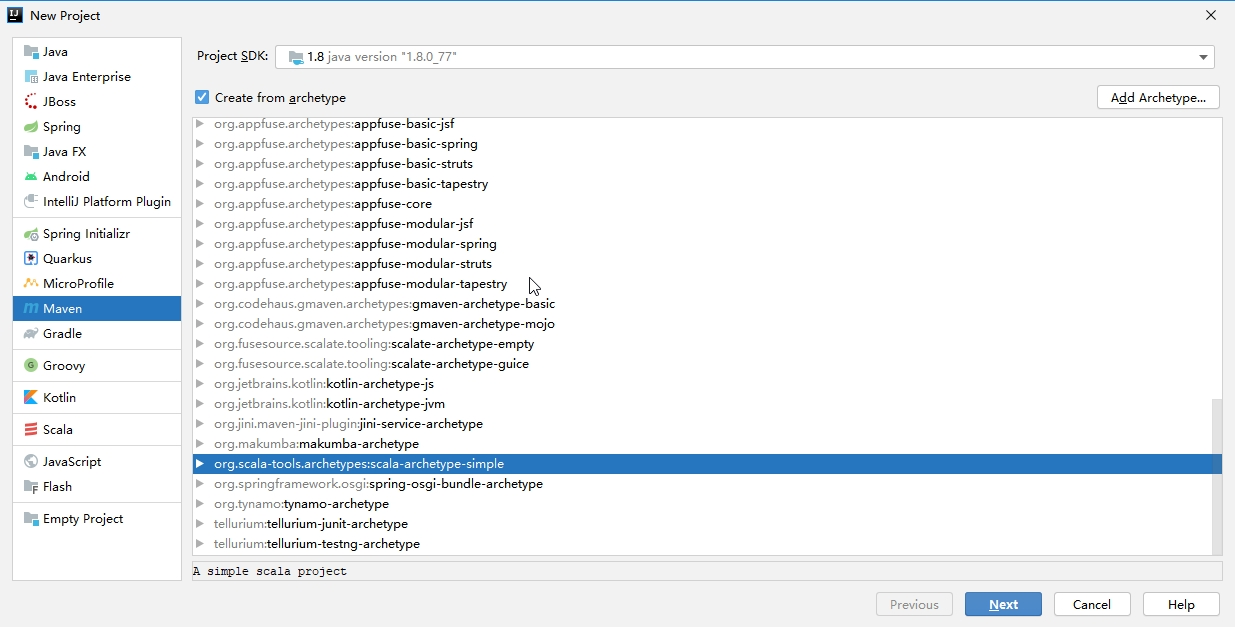
(2). 添加模板(没有模板的前提)
可以网上搜索Scala-archetype-simple的位置并填写。
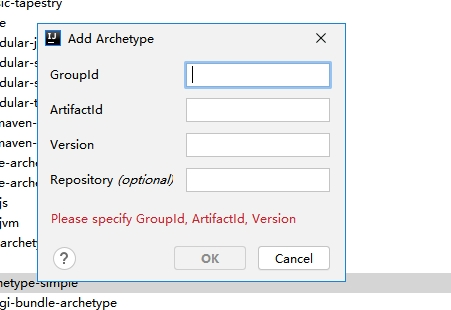
(3). 完成创建等待IDE自动构建
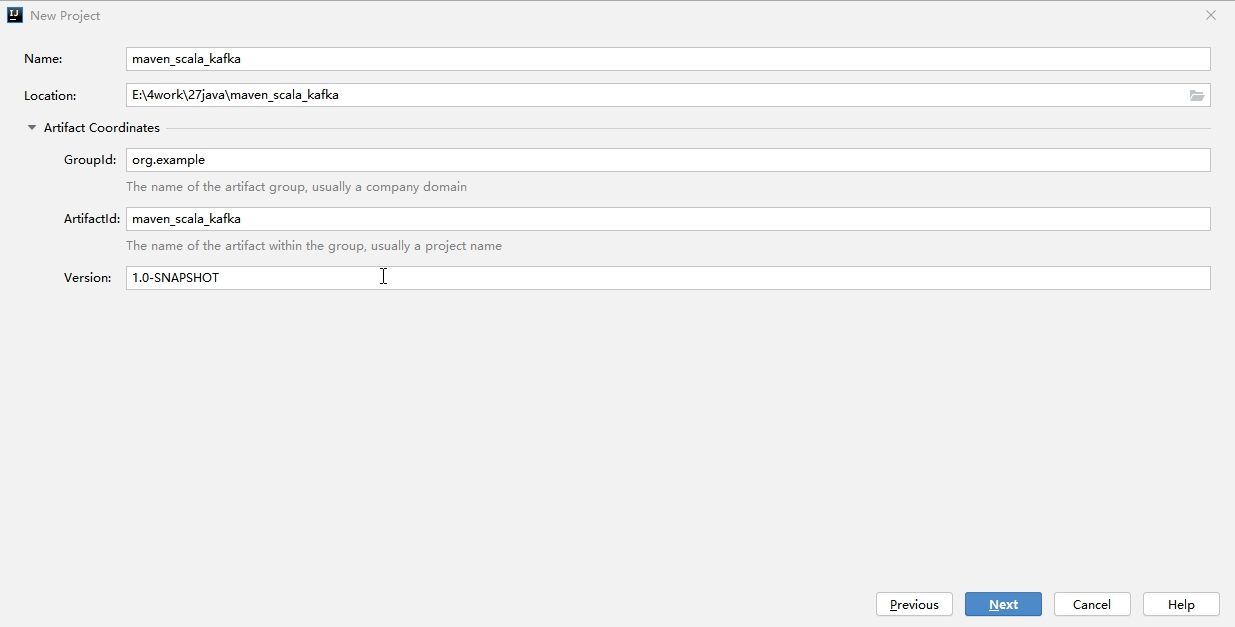

(4). 给项目添加Scala SDK依赖
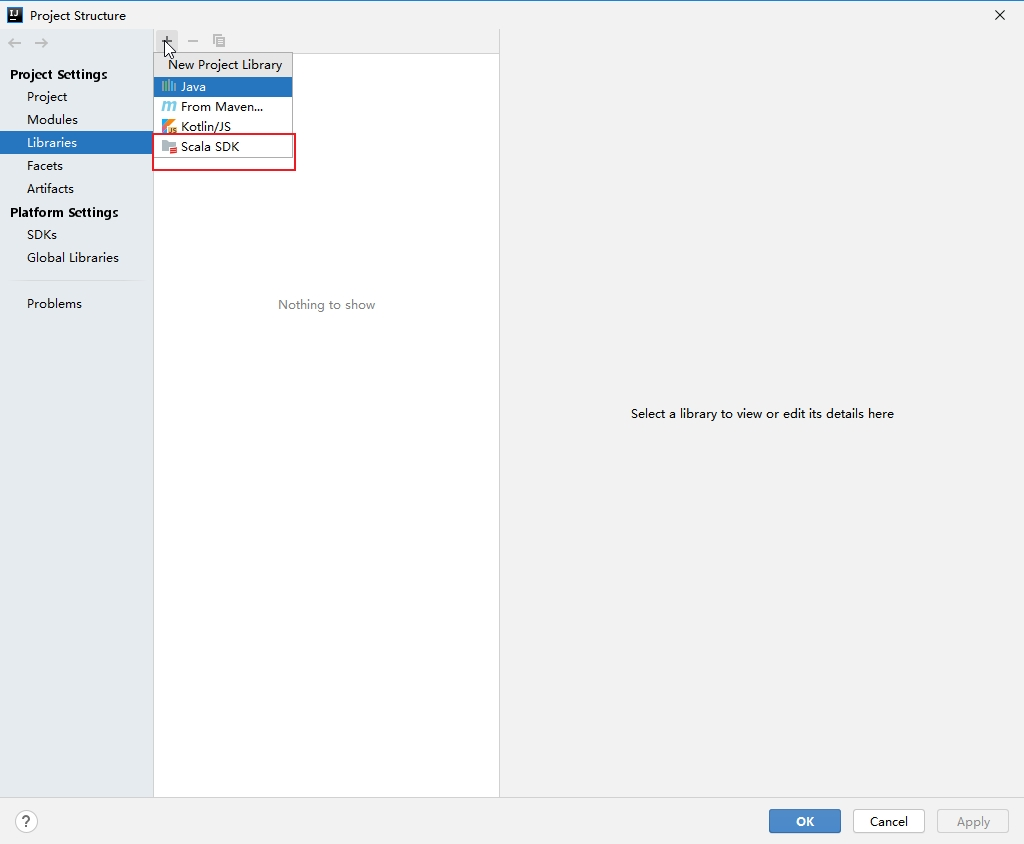
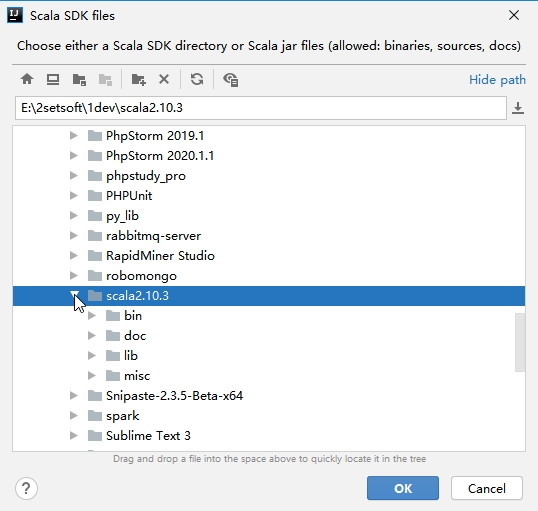
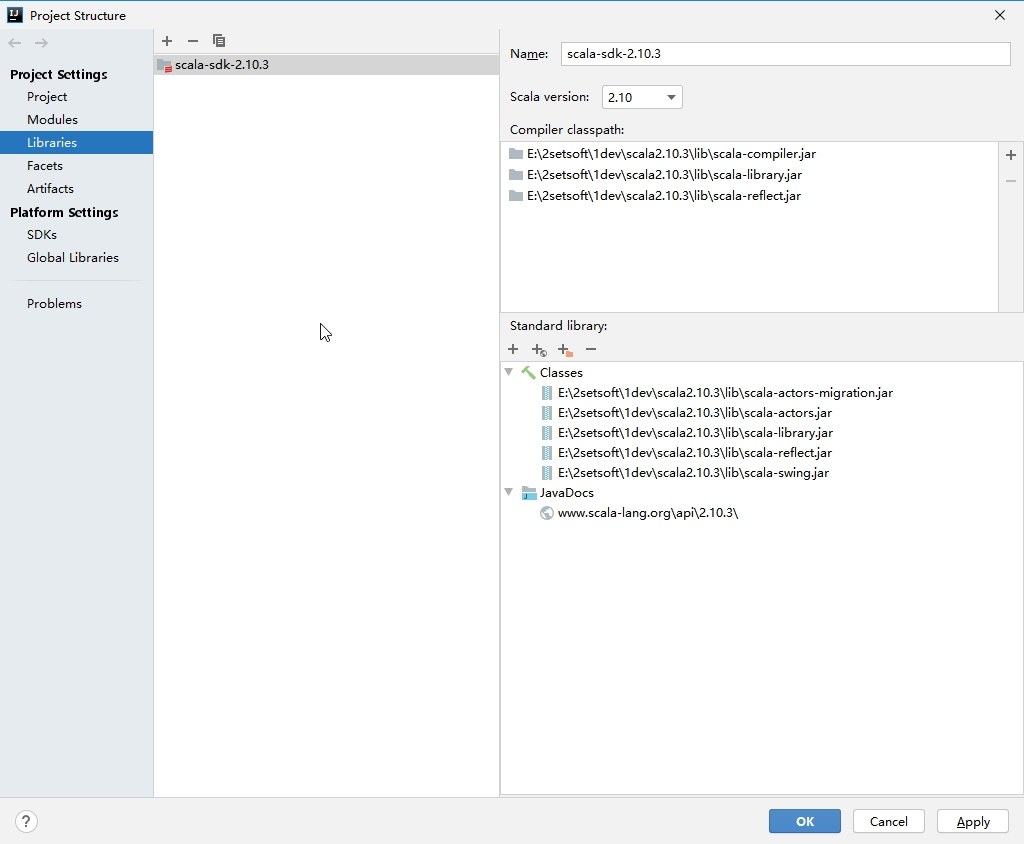
2. 配置
(1). 修改pom.xml的scala版本为本地安装scala对应的号。
(2). Cannot resolve plugin org.scala-tools:maven-scala-plugin: unknown解决方法
- 添加一下依赖后再Maven刷新
-
- <dependency>
- <groupId>org.scala-tools</groupId>
- <artifactId>maven-scala-plugin</artifactId>
- <version>2.11</version>
- </dependency>
- <dependency>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-eclipse-plugin</artifactId>
- <version>2.5.1</version>
- </dependency>
3. 添加kafka依赖
- <!--kafka-->
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka_2.11</artifactId>
- <version>1.1.0</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka-clients</artifactId>
- <version>1.1.0</version>
- </dependency>
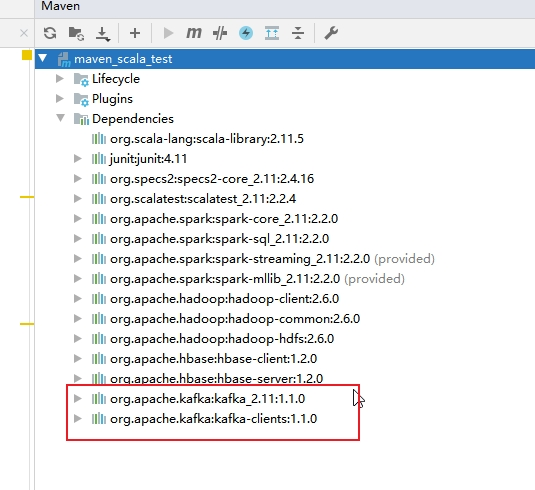
4. 创建消费者
- package com.xudong
-
- import java.util.Properties
- import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord, RecordMetadata}
-
- object KafkaProducerDemo {
-
- def main(args: Array[String]): Unit = {
- val prop = new Properties
- // 指定请求的kafka集群列表
- prop.put("bootstrap.servers", "127.0.0.1:9092")
- prop.put("acks", "all")
- // 请求失败重试次数
- //prop.put("retries", "3")
- // 指定key的序列化方式, key是用于存放数据对应的offset
- prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
- // 指定value的序列化方式
- prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
- // 配置超时时间
- prop.put("request.timeout.ms", "60000")
-
- val producer = new KafkaProducer[String, String](prop)
-
- // 发送给kafka
- for (i <- 1 to 25) {
- val msg = s"${i}: this is a linys ${i} kafka data"
- println("send -->" + msg)
- val rmd: RecordMetadata = producer.send(new ProducerRecord[String, String]("ceshi", msg)).get()
- println(rmd.toString)
- Thread.sleep(500)
- }
-
- producer.close()
- }
-
- }
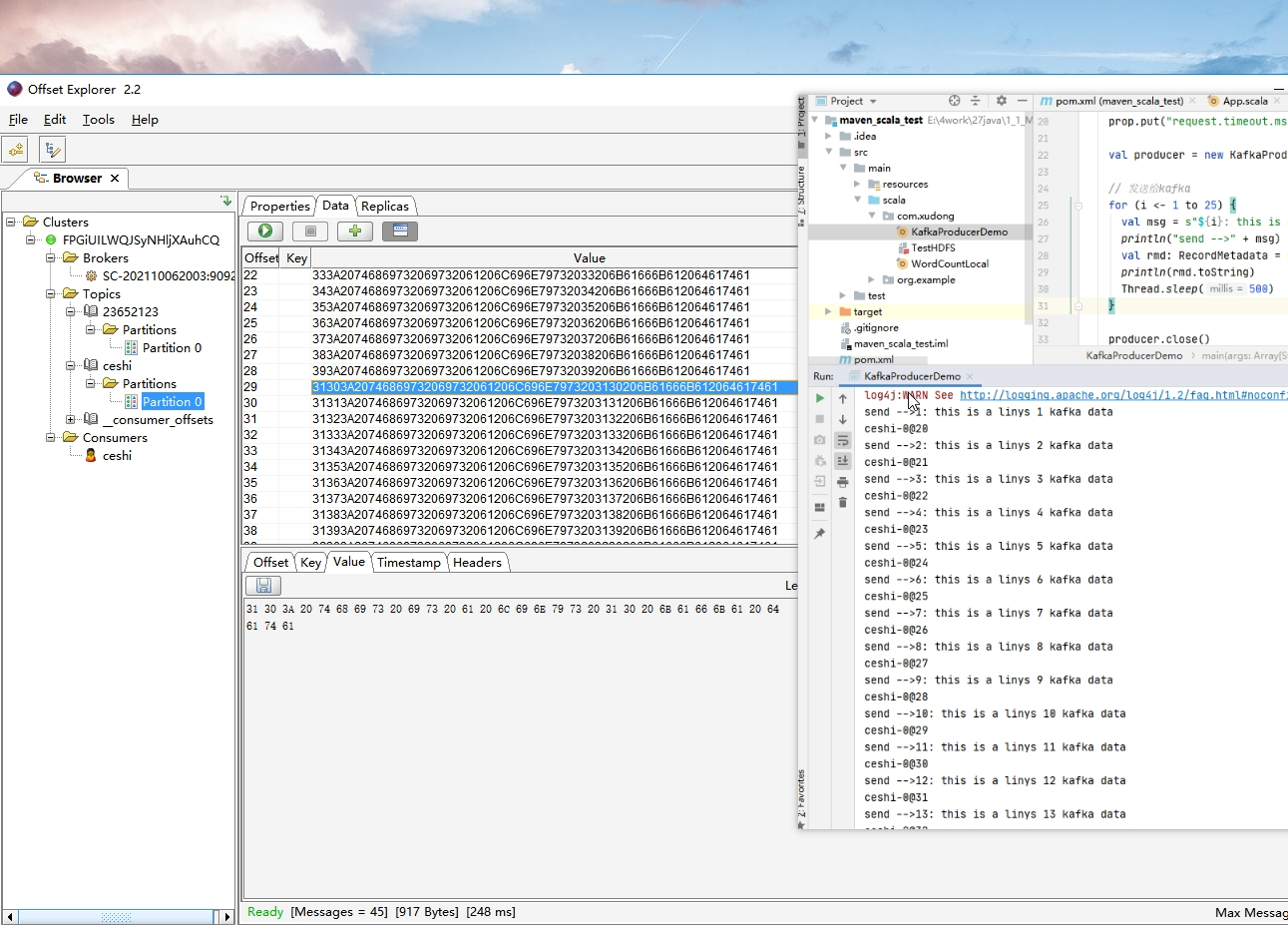
5. 创建消费者
- package com.xudong
-
- import java.util.{Collections, Properties}
- import org.apache.kafka.clients.consumer.{ConsumerRecords, KafkaConsumer}
-
- object KafkaConsumerDemo {
-
- def main(args: Array[String]): Unit = {
- val prop = new Properties
- prop.put("bootstrap.servers", "127.0.0.1:9092")
- prop.put("group.id", "group01")
- prop.put("auto.offset.reset", "earliest")
- prop.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
- prop.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
- prop.put("enable.auto.commit", "true")
- prop.put("session.timeout.ms", "30000")
- val kafkaConsumer = new KafkaConsumer[String, String](prop)
- kafkaConsumer.subscribe(Collections.singletonList("ceshi"))
- // 开始消费数据
- while (true) {
- val msgs: ConsumerRecords[String, String] = kafkaConsumer.poll(2000)
- // println(msgs.count())
- val it = msgs.iterator()
- while (it.hasNext) {
- val msg = it.next()
- println(s"partition: ${msg.partition()}, offset: ${msg.offset()}, key: ${msg.key()}, value: ${msg.value()}")
- }
- }
- }
-
- }

学习交流


