
- 1Qt之信号与槽
- 2深入了解Kimi:月之暗面科技有限公司的创新智能助手_kimi 的能力
- 3【数据结构】CH4 串_第1关:求子串
- 4MySQL从安装、配置到日常操作和管理的关键步骤_mysql安装教程8.4
- 5python 中使用opencv_python使用opencv
- 6python3+selenium爬取笔记本电脑详情信息_selenium可以爬取pc端数据吗
- 7【通信中间件】Fdbus HelloWorld实例
- 8搭建单机版伪分布式Hadoop+Spark+Scala
- 9基于MySQL Workbench的表操作_mysql workbench向表中添加数据
- 10苹果app退款_app退款理由写什么好?苹果退款理由怎么写才好?
将开源进行到底!小米新一代Kaldi荣获2022数博会“领先科技成果”奖
赞
踩
5月26日,数博会开幕式当天揭晓了“2022中国国际大数据产业博览会数博发布之领先科技成果”奖,小米公司“新一代Kaldi”项目,凭借全自研的创新成果和突出的社会价值,获得评委会一致认可,荣获“数博会领先科技成果奖·新技术”奖项!

中国国际大数据产业博览会(简称数博会),是全球首个以大数据为主题的博览会,自2015年创办以来发展至今,深受党和国家领导人重视,已成为引领行业发展的国际性盛会。今年,数博会领先科技成果奖是在国家科学技术奖励工作办公室备案,唯一以博览会名义设奖和唯一以大数据为主题的专业奖项,有力提升了“数博发布”的权威性和含金量。
继往开来,引领科技前沿
新一代Kaldi为何能获此殊荣?我们要从上一代Kaldi讲起……
Kaldi,当前最流行的开源语音识别工具。大多数人可能比较陌生,但对于语音识别的从业者来说,可谓是无人不晓。大量的语音团队都在使用Kaldi引擎来开发智能解决方案,人们所熟知的“小爱同学”、“苹果Siri”等语音产品,背后都离不开Kaldi。Kaldi集成了多种语音识别模型,包括隐马尔可夫和最新的深度学习神经网络,被认为是业界公认的语音识别框架的基石。

而新一代Kaldi项目则是从蜚声世界的语音识别开源项目Kaldi发展而来。
它由 Kaldi 之父Daniel Povey 领衔研发,Daniel Povey是国际语音识别和AI领域的知名教授,博士毕业于剑桥大学,先后任职于美国 IBM 和微软公司,后加入约翰斯·霍普金斯大学担任语言和语音处理中心副教授;2019年加入小米,担任小米集团首席语音科学家,组建团队研发“新一代 Kaldi”。

新一代Kaldi于2021年8月30日在语音识别国际顶级会议Interspeech上发布第一个正式版本,上线之初就获得众多国际知名专家的认可和关注。目前,至少7篇发布在Interspeech、ICASSP等国际顶级会议上的论文使用本项目进行实验或对本项目进行引用。
自主自研,凝聚核心技术
新一代Kaldi作为完全自主研发的原始创新成果,功能强大的背后,离不开大量的先进技术和创新点,可以简单概括为三个子项目、两项关键技术,四大创新点。
1、三个子项目

新一代Kaldi三个子项目
(1)核心算法库k2
k2是整个项目的核心。通过k2可以非常容易实现(置信度逐渐提高的)多轮解码过程,如消除以往语音识别任务中训练跟解码过程不匹配的问题、多轮(可求导)的语音识别过程、在声学网络中嵌入任意辅助信息等。
k2也可以用来很方便地实现很多现有的语音识别模型,如 CTC、LF-MMI、 RNN-T 等。相较于其他一些语音识别库的优势,k2速度更快,通用性强(可以用来建模多种语音识别算法)。
k2更多信息请点击链接查看详情:
https://github.com/k2-fsa/k2
(2)通用语音数据处理工具包Lhotse
Lhotse(训练数据准备部分)将替代以前Kaldi中所有数据准备相关的工作,操作各种音频和文本的元数据。Lhotse除了Kaldi本身,也适用于其他应用。而且Lhotse纯Python代码,方便易用。
Lhotse,不仅可以用在 Icefall 项目里,也可以用在任意其他语音识别库里来处理音频和文本数据。随着新一代 Kaldi 的推广和普及,Lhotse 甚至有可能成为语音领域使用最为广泛的数据准备工具。
Lhotse更多信息请点击链接查看详情:
https://github.com/lhotse-speech/lhotse
(3)语音识别完整解决方案Icefall
Icefall(示例脚本集合部分)将代替Kaldi中的示例脚本集合,并独立成为一个单独的子项目。之所以要把示例脚本集合与核心算法分开,是考虑到示例脚本可能会非常庞大,且经常变动。
Icefall 项目只需要关注语音识别模型的结构定义部分,这大大降低了整个语音识别过程的耦合性,也方便了网络结构的复用。
Icefall更多信息请点击链接查看详情:
https://github.com/k2-fsa/icefall
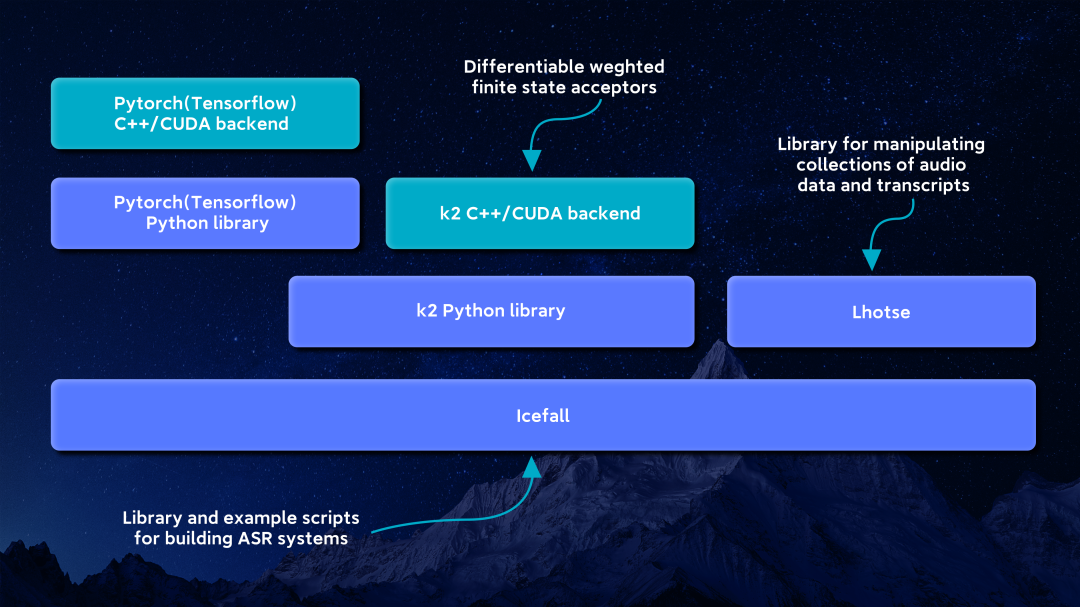
新一代Kaldi系统架构图
2、两项关键技术
(1)支持GPU的不规则张量
在不规则张量上进行高效运算一直以来是一个难点,本项目提出了一种不规则张量的实现方法,并且在 CPU/GPU 上实现了与其相关的各种与规则张量相似的操作方法。作为一种通用的数据结构,我们实现的不规则张量可适用于各种不规则数据的高效运算。
(2)可微分的加权有限状态自动转换器
有限自动状态转化器是序列建模的有力工具,支持有限自动状态转化器可微分,意味着自动状态转化器可以参与到神经网络的训练中,使实现语音识别系统不仅更加灵活高效,本项目创造性的把有限自动状态转换器无缝集成到了可自动微分的 Pytorch 工具包中,并且基于上述的不规则张量在 GPU 做了高效实现,使其可以和 Pytorch 联合运行,极大的简化了序列建模的任务。
3、四大创新点
新一代Kaldi针对“上一代Kaldi神经网络定制难”、“端到端模型研发过程中训练和解码不一致”以及“如何进行端到端模型的高效训练和部署”等问题进行了攻克。其引入的解决方案是极具创新性的。主要分为以下四个部分。
(1)运用可微分的加权有限状态自动转换器进行序列建模
新一代Kaldi引入可自动求导的 FSA 算法库进行建模,这极大地扩充了语音识别建模方式的可能性,建模中损失函数的使用也不再仅限于标准的 CTC 准则,而是可以根据需要设计不同的拓扑结构,借助高效的可导的 FSA 算法来计算损失函数,并实现梯度的回传。
(2)实现置信度逐步提升的多级解码方法
新一代Kaldi包含了诸如CTC 解码、HLG 解码、语言模型重打分、神经网络语言模型重打分等多种不同层次的解码方法,并且这些解码方法是完全解耦的,用户可以根据产品对性能和效率的要求选择使用对应层级的解码方式。
(3)支持语音识别全流程的GPU加速
新一代Kaldi的各个阶段的流程都支持 GPU 的加速,有效利用了硬件技术进步带来的便利,提升算力的使用率,减小系统的反应时间。解决了当前端到端模型必须将声学模型和解码器分开在不同设备运行的难题,进一步降低系统延时。
(4)提供端到端语音识别系统的构建范式
新一代Kaldi构建了一套完整的端到端语音识别的流程,包含数据处理、深度学习模型构建、模型训练、模型解码、错误率评估等各个阶段的工具集,这将是一个开箱即用的系统,模型和脚本都将具有极大的普适性,产品开发人员将只需要替换数据就可以开发属于自己的系统,极大简化了端到端语音识别系统构建的工作,从技术和规范层面形成更先进的生产力。
开源共享,助力行业发展
新一代 Kaldi 作为开源项目,是一个开箱即用的软件,兼具“易用性”和“实用性”。在工业界和学术界已产生了重要影响,同时也为普通老百姓带来更加美好的语音识别产品体验。
1、显著降低研发成本
新一代Kaldi的大量代码都是基于 C++实现,且支持 GPU 的高效运算,将所有的核心算法都封装在了k2 这个核心模块,且提供了 Python 接口。用户只需要基于项目提供的脚本示例就可以很很容易地基于自己公司产品的数据集进行修改,迅速搭建适合自己业务的语音识别系统,进而快速地搭建线上数据反馈和模型自动迭代更新的流程,极大的缩短模型更新的周期,使原本需要一个大研发团队才能做到的事情,现在只需要几个研发维护人员就可以,显著降低开发和人力成本。
与其他开源语音工具包相比,新一代Kaldi在建设之初就以产品化落地为首要目标,致力于打造语音识别领域最有影响力的开源语音识别库,助力整个行业更加高效地构建AI语音系统。
2、全面提升产品体验
新一代Kaldi目前已在中英文数据集上均取得了优异的识别性能,具有极高的识别准确率。在开源英文数据集Librispeech上的词错率低至2%,中文数据集AIshell上字错率已达到4.26%,在大规模开源数据集(10000小时)GigaSpeech和WenetSpeech上均取得业内最好效果。并且,新一代Kaldi的解码效率极高,解码速度已达到实时解码的400倍。
相信随着新一代Kaldi的全面落地,高效的解码速度和低WER(词错误率)将会帮助“小爱同学”等同类语音产品朝着更为智能的方向发展,为每一个人带来更加美好的语音识别产品体验,大大方便了普通用户和家庭的生活。
开源的本质是技术共享。作为一家坚持“技术为本”的公司,未来,我们希望新一代 Kaldi 项目能够惠及全球的开发者、各大中小企业,以及每一位用户,让智能语音更加触手可及!


