
- 1金字塔思维学习总结
- 2vue报错:[vuex] Do not mutate vuex store state outside mutation handlers
- 3Java使用easyExcel生成excel文件直接写入邮件附件并发送_easyexcel生成分批成附件发送邮箱
- 4使用友盟实现第三方登录_fcl_login_kakao_auth_syn
- 5笔记: 排序算法——合并排序(C++实现)_c++合并排序
- 6第十二届蓝桥杯 2021年国赛真题 C完全日期(Calendar类 日期遍历)_怎么遍历从2001年到2021年的日期
- 7大数据毕业设计 深度学习图像检索算法研究与实现 - python
- 8git及项目部署_gitstats 需要和仓库部署一起吗
- 9数据结构与算法三:栈和队列_ctrl z 基于那种数据结构
- 10linux环境docker安装mysql(安装mysql客户端)_linux 安装mysql客户端
class常量池、运行时常量池和字符串常量池的关系_2".equals(flag)
赞
踩
类常量池、运行时常量池和字符串常量池这三种常量池,在Java中扮演着不同但又相互关联的角色。理解它们之间的关系,有助于深入理解Java虚拟机(JVM)的内部工作机制,尤其是在类加载、内存分配和字符串处理方面。
类常量池(Class Constant Pool)
每个Java类文件(.class文件)都具有自己的类常量池,它用于存储编译期生成的常量,包括各种字面量(字面量就是指由字母、数字等构成的字符串或者数值)和符号引用(比如类和接口的全名、字段的名称和描述符、方法的名称和描述符)。类常量池在编译期间就已经被确定,并被保存在.class文件中。
Class常量池是用来保存常量的一个中间场所。在JVM真的运行时,需要把类常量池中的常量加载到内存中的运行时常量池中。
运行时常量池(Runtime Constant Pool)
运行时常量池是类被加载到JVM时类常量池的内存版本:当Java类被加载到JVM时,各个类文件中的类常量池内容被读取并存入到运行时常量池中,其中字符串的部分直接进到字符串池,其他常量进入到运行时常量池。
根据Java虚拟机规范约定:每一个运行时常量池都在Java虚拟机的方法区中分配,在加载类和接口到虚拟机后,就创建对应的运行时常量池。
规范中规定了运行时常量池属于方法区,但是没规定方法区属于哪。于是虚拟机在各自实现的时候就各显神通了。在不同版本的JDK中,运行时常量池所处的位置也不一样。以HotSpot虚拟机为例:
在JDK 1.7之前,方法区位于永久代,运行时常量池作为方法区的一部分,处于永久代中,字符串常量池位于运行时常量池的一部分也处于永久代中。
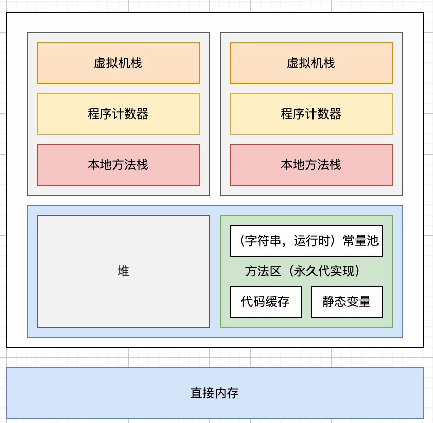
因为使用永久代实现方法区可能导致内存泄露问题,所以,从JDK1.7开始,JVM尝试解决这一问题。
在JDK 1.7中,静态变量和运行时常量池中的字符串常量池转移到了堆内存中,其他类型的常量还保留在方法区中。
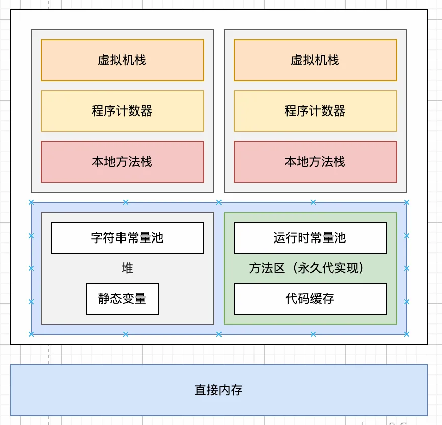
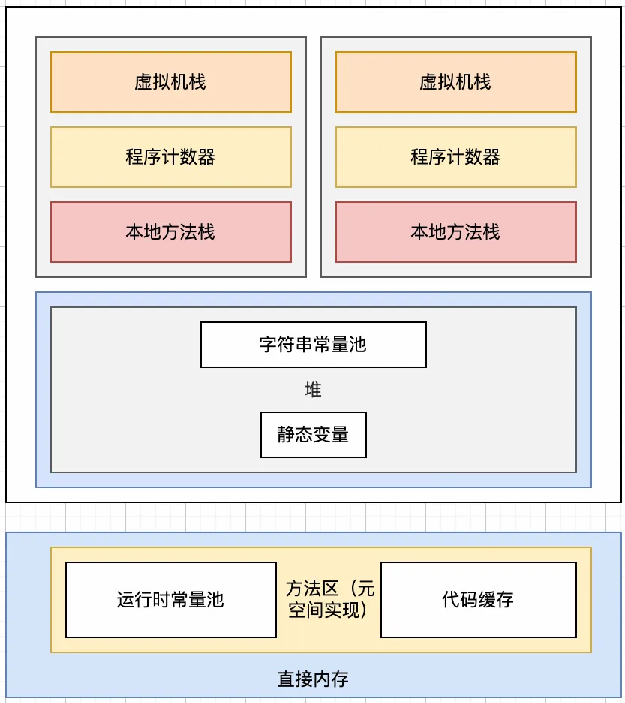
在JDK 1.8中,彻底移除了永久代,方法区通过元空间的方式实现,元空间是使用本地内存(Native Memory)来存储类的元数据信息的。随之,运行时常量池也在元空间中实现。
运行时常量池中包含了若干种不同的常量,他的来源主要有两种:
-
编译期可知的字面量和符号引用(来自Class常量池)
-
运行期解析后可获得的常量(如String的intern方法)
字符串常量池(String Constant Pool)
字符串常量池专门用于存储字符串常量。对于 Hotspot 虚拟机来说,类加载时,字符串字面量作为类常量池的一部分信息被载入运行时常量池中,它们以特殊的形式存储在运行时常量池中,此时它们并未被实例化为Java堆中的String对象。只有当这个字符串字面量被调用时,才会对其进行解析,即检查字符串常量池中是否已经存在相同内容的字符串对象。如果存在,就直接返回指向该对象的引用,如果不存在,虚拟机会在字符串常量池中创建一个对应的String实例,并返回这个新实例的引用。
这种处理方式的优势在于,可以减少在类加载阶段对内存的需求和降低开销,因为不是所有的字符串字面量在类的使用周期内都会被用到。同时,此方法延迟了String对象的实例化,直到它们真正被需要,这有助于提高性能并减少内存的无谓占用。
为什么从JDK 1.7开始,字符串常量池从永久代中挪到堆(Heap)中?
主要原因是因为永久代的 GC 回收效率太低,只有在FulIGC的时候才会被执行回收。但是Java中往往会有很多字符串的生命周期都很短暂,将字符串常量池放到堆中,能够更高效及时地回收字符串内存。
字符串常量池中的常量有以下几个来源:
1、字面量常量。
在代码中直接使用双引号括起来的字符串字面值(如 strings="hello”)会被认为是常量,并且会在编译后进入class文件的常量池,并且在运行阶段,进入字符串常量池。这是最常见的字符串常量来源。
2、intern()方法
String类提供了一个intern方法,用于将字符串对象手动添加到字符串常量池中。调用intern()方法时,如果字符串常量池中已经存在相同内容的字符串,将会返回常量池中的引用;如果不存在,则会在常量池中添加该字符串在堆中的引用。
以下有几个非常值得我们注意的地方:
(1)字符串常量池是一个固定大小的Hashtable,默认值大小长度是1009,如果放进字符串常量池的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找,以此判断字符串常量在不在字符串常量池中)。在jdk6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。在jdk7中,StringTable的长度可以通过一个参数指定:
-XX:StringTableSize=99991
- 1
(2)对于字符串的拼接,纯字面量和字面量的拼接,会把拼接结果作为常量保存到字符串池。如果在字符串拼接中,有一个参数是非字面量,而是一个变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的。只有在运行期才能确定。
比如这段代码:
string s1 = "Hollis";
string s2 = "Chuang";
string s3 = s1 + s2;
string s4 = "Hollis" + "Chuang";
- 1
- 2
- 3
- 4
在经过反编译后得到代码如下:
String s1 = "Hollis";
string s2 = "chuang" ;
string s3 = (new stringBuilder() ).append(s1).append(s2).toString( );
String s4 = "Hollischuang";
- 1
- 2
- 3
- 4
(3)jdk7版本在修改了常量池的基础上,也对intern函数做了修改:
在jdk7之前,字符串常量池位于永久代中,使用intern函数,如果字符串常量池中没有该字符串对象,会在字符串常量池中创建一个该对象,但是在jdk7及之后,字符串常量池移到了堆中,使用intern函数,如果字符串常量池中没有该字符串对象,则不会在字符串常量池中创建对象,而是保存堆中该对象的引用。 比如:
String s = new String("hello") + new String("world");
s.intern();
- 1
- 2
在第一句代码中,我们创建了一个引用变量s,其指向堆中字符串对象"helloworld",而后调用intern函数,此时字符串常量池中没有"helloworld"字符串对象,如果是在jdk7之前,jvm会在位于永久代的字符串常量池中创建一个"helloworld"字符串对象,但是jdk7之后,字符串常量池位于堆中,不再需要重新创建字符对象,而是在字符串常量池中保存堆中"helloworld"对象的引用。
关于intern函数可以学习这篇文章,讲解非常通透:深入解析String#intern


