
- 1javaWeb前后台交互(Jdbc+Jsp+Servlet+mysql)_servlet+ mysql做的web项目前后端如何交互
- 22024Flutter面试题最新整理大全(含答案),金九银十Android热点知识
- 3php+Mysql注入详解 _php mysql 注入
- 4机器学习:基于线性回归、岭回归、xgboost回归、Lasso回归、随机森林回归预测卡路里消耗
- 5创建各种索引的语句_创建索引的语句
- 6jdk1.8新特性——方法引用、构造器引用及数组引用详解_vue3新特性支持jdk1.8吗
- 7企业车辆调度管理系统(论文+源码)_jsp_214
- 8Windows Server 2012 R2 WSUS-14:powershell管理WSUS
- 9Oracle Database 23ai Free版本体验
- 10C/C++ 变参函数_c++变参函数无参数时
使用计算机视觉实战项目精通 OpenCV:6~8_计算机视觉应用开发 项目6
赞
踩
原文:Mastering OpenCV with Practical Computer Vision Projects
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
六、非刚性人脸跟踪
非刚性人脸跟踪是视频流每一帧中一组准密集的人脸特征的估计,这是一个难题,现代方法从许多相关领域借鉴了思想,包括计算机视觉,计算几何 ,机器学习和图像处理。 这里的非刚性指的是以下事实:人脸特征之间的相对距离在面部表情和整个人群之间变化,并且不同于人脸检测和跟踪,后者仅旨在在每个帧中查找面部的位置,而不是配置人脸特征。 非刚性人脸跟踪是一个流行的研究主题,已经有二十多年的历史了,但是直到最近,各种方法才变得足够鲁棒,处理器也足够快,这使得构建商业应用成为可能。
尽管商业级的面部跟踪可能非常复杂,甚至对有经验的计算机视觉科学家来说都是一个挑战,但在本章中,我们将看到可以使用适度的数学工具和 OpenCV 来设计在受限设置下表现良好的面部跟踪器。 线性代数,图像处理和可视化方面的重要功能。 当提前知道要跟踪的人并且可以使用图像和地标形式的训练数据时,尤其如此。 此后描述的技术将作为有用的起点和指南,用于进一步追求更精细的面部跟踪系统。
本章概述如下:
- 概述:本节介绍面部跟踪的简要历史。
- 工具:本节概述了本章中使用的通用结构和约定。 它包括面向对象的设计,数据存储和表示,以及用于数据收集和标注的工具。
- 几何约束:本节描述如何从训练数据中学习面部几何及其变化,并在跟踪过程中利用面部几何约束其解决方案。 这包括将人脸建模为线性形状模型,以及如何将全局转换集成到其表示中。
- 人脸特征检测器:本节介绍如何学习人脸特征的外观,以便在要跟踪面部的图像中检测人脸特征。
- 人脸检测和初始化:本节介绍如何使用人脸检测初始化跟踪过程。
- 人脸跟踪:本节通过图像对齐过程将前面描述的所有组件组合到跟踪系统中。 还讨论了可以期望系统最佳工作的设置。
以下框图说明了系统各个组件之间的关系:
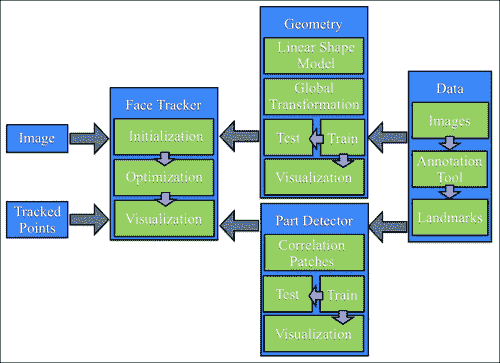
注意
请注意,本章中使用的所有方法都遵循数据驱动的范式,在该模型中,所使用的所有模型都是从数据中学习的,而不是在基于规则的设置中手动设计的。 因此,系统的每个组件都将包含两个组件:训练和测试。 训练从数据中构建模型,测试将这些模型应用于新的看不见的数据。
概述
随着 Cootes 和 Taylor 的活动形状模型(ASM)的出现,非刚性人脸追踪首次在 90 年代中期普及。 从那时起,大量的研究致力于解决通用人脸跟踪的难题,并且对 ASM 提出的原始方法进行了许多改进。 第一个里程碑是 2001 年,同样是 Cootes 和 Taylor,将 ASM 扩展到了活动外观模型(AAM)。 后来,贝克和各大学在 2000 年代中期通过对图像扭曲的原则性处理,使这种方法正式化。 沿着这些思路开展的另一项工作是 Blanz 和 Vetter 的 3D 可变形模型(3DMM),它与 AAM 一样,不仅为图像纹理建模,而且像 ASM 中一样沿对象边界进行轮廓剖析,但是通过使用从面部激光扫描中学到的高度密集的 3D 数据来表示模型,又向前迈了一步。 从 2000 年代中期到后期,人脸跟踪的研究重点从如何对人脸进行参数化转向如何设定和优化跟踪算法的目标。 应用了机器学习社区的各种技术,并获得了不同程度的成功。 自世纪之交以来,焦点再次转移,这一次是为了保证全局解决方案的联合参数和客观设计策略。
尽管对面部跟踪进行了持续的深入研究,但是使用面部跟踪的商业应用相对较少。 尽管有许多免费的源代码包可用于许多常用方法,但爱好者和爱好者的吸收也滞后。 但是,在过去的两年中,由于可能会使用面部跟踪,因此人们对公共领域重新产生了兴趣,并且商业级产品也开始出现。
工具
在深入了解复杂的面部跟踪之前,必须先引入所有面部跟踪方法共有的许多簿记任务和约定。 本节的其余部分将处理这些问题。 有兴趣的读者可能希望在初读时跳过本部分,直接进入有关几何约束的部分。
面向对象设计
与人脸检测和识别一样,人脸跟踪在程序上也包含两个部分:数据和算法。 该算法通常通过参考预存储(即离线)的数据作为指导,对传入(即在线)的数据执行某种操作。 这样,将算法与算法所依赖的数据相结合的面向对象设计是一种方便的设计选择。
在 OpenCV v2.x 中,引入了一种方便的 XML/YAML 文件存储类,该类大大简化了组织脱机数据以供算法使用的任务。 为了利用此功能,本章中描述的所有类都将实现读和写序列化功能。 虚类foo的示例如下所示:
#include <opencv2/opencv.hpp>
using namespace cv;
class foo{
public:
Mat a;
type_b b;
void write(FileStorage &fs) const{
assert(fs.isOpened());
fs << "{" << "a" << a << "b" << b << "}";
}
void read(const FileNode& node){
assert(node.type() == FileNode::MAP);
node["a"] >> a; node["b"] >> b;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在这里,Mat是 OpenCV 的矩阵类,type_b是(虚构的)用户定义的类,还定义了序列化功能。 I/O 函数read和write实现序列化。 FileStorage类支持两种可以序列化的数据结构。 为简单起见,在本章中,所有类都将仅使用映射,其中每个存储的变量都创建一个类型为FileNode::MAP的FileNode对象。 这要求将唯一的键分配给每个元素。 尽管此键的选择是任意的,但出于一致性的原因,我们将使用变量名作为标签。 如前面的代码片段所示,read和write函数采用特别简单的形式,从而使用流运算符(<<和>>)将数据插入和提取到FileStorage对象中 。 大多数 OpenCV 类都具有read和write函数的实现,从而可以轻松地存储它们包含的数据。
除了定义序列化功能之外,还必须定义两个附加函数,以使FileStorage类中的序列化起作用,如下所示:
void write(FileStorage& fs, const string&, const foo& x){
x.write(fs);
}
void read(const FileNode& node, foo& x,const foo& default){
if(node.empty())x = d; else x.read(node);
}
- 1
- 2
- 3
- 4
- 5
- 6
由于这两个函数的功能对于我们在本节中描述的所有类均保持不变,因此它们是在本章相关源代码中的ft.hpp头文件中进行模板化和定义的。 最后,为了轻松保存和加载利用序列化功能的用户定义的类,还可以在头文件中实现针对这些类的模板化函数,如下所示:
template <class T>
T load_ft(const char* fname){
T x; FileStorage f(fname,FileStorage::READ);
f["ft object"] >> x; f.release(); return x;
}
template<class T>
void save_ft(const char* fname,const T& x){
FileStorage f(fname,FileStorage::WRITE);
f << "ft object" << x; f.release();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
请注意,与对象关联的标签始终相同(即ft object)。 定义了这些函数后,保存和加载对象数据将轻松完成。 在以下示例的帮助下显示了此内容:
#include "opencv_hotshots/ft/ft.hpp"
#include "foo.hpp"
int main(){
...
foo A; save_ft<foo>("foo.xml",A);
...
foo B = load_ft<foo>("foo.xml");
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
请注意,.xml扩展名生成 XML 格式的数据文件。 对于其他任何扩展名,它默认为(更易理解的)YAML 格式。
数据收集:图像和视频标注
现代人脸跟踪技术几乎完全由数据驱动,也就是说,用于检测图像中人脸特征位置的算法依赖于一组示例中人脸特征的外观模型及其相对位置之间的几何相关性。 实例集越大,算法就越表现出鲁棒性,因为它们越来越了解面孔可能表现出的变化范围。 因此,构建面部跟踪算法的第一步是创建图像/视频标注工具,用户可以在其中指定每个示例图像中所需人脸特征的位置。
训练数据类型
用于训练面部跟踪算法的数据通常包含四个组件:
- 图像:该组件是包含整个面部的图像(静止图像或视频帧)的集合。 为了获得最佳结果,此集合应专门针对随后部署跟踪器的条件类型(即身份,照明,与摄像机的距离,捕获设备等)。 同样重要的是,集合中的面孔必须具有预期应用期望的各种头部姿势和面部表情。
- 标注:该组件在每个图像中按顺序排列了手工标记的位置,这些位置与要跟踪的每个人脸特征相对应。 更多的人脸特征通常会导致跟踪器更强大,因为跟踪算法可以使用它们的测量值来相互增强。 常见跟踪算法的计算成本通常与人脸特征的数量成线性比例。
- 对称性索引:该组件具有每个人脸特征点的索引,这些索引定义了其双边对称特征。 这可以用来镜像训练图像,有效地使训练集大小加倍,并使数据沿 y 轴对称。
- 连接性索引:该组件具有一组标注的索引对,这些标注对定义了人脸特征的语义解释。 这些连接对于可视化跟踪结果很有用。
下图显示了这四个组件的可视化,其中从左到右分别是原始图像,人脸特征标注,颜色编码的双边对称点,镜像图像以及标注和人脸特征连通性。

为了方便地管理此类数据,实现存储和访问功能的类是一个有用的组件。 OpenCV 的ml模块中的CvMLData类具有处理通常在机器学习问题中使用的常规数据的功能。 但是,它缺少面部跟踪数据所需的功能。 因此,在本章中,我们将使用在ft_data.hpp头文件中声明的ft_data类,该类是专门为面部跟踪数据而设计的。 所有数据元素都定义为类的公共成员,如下所示:
class ft_data{
public:
vector<int> symmetry;
vector<Vec2i> connections;
vector<string> imnames;
vector<vector<Point2f> > points;
…
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Vec2i和Point2f类型分别是两个整数和 2D 浮点坐标的向量的 OpenCV 类。 symmetry向量具有与面部上的特征点一样多的成分(由用户定义)。 connections中的每一个都定义了一个连接人脸特征的从零开始的索引对。 由于训练集可能非常大,而不是直接存储图像,因此该类将每个图像的文件名存储在imnames成员变量中(请注意,这要求图像必须位于文件名的相同相对路径中,来保持有效)。 最后,对于每个训练图像,将人脸特征位置的集合作为浮点坐标的向量存储在points成员变量中。
ft_data类实现了许多用于访问数据的便捷方法。 要访问数据集中的图像,get_image函数将图像加载到指定索引idx,并可选地围绕 y 轴进行镜像,如下所示:
Mat
ft_data::get_image(
const int idx, //index of image to load from file
const int flag){ //0=gray,1=gray+flip,2=rgb,3=rgb+flip
if((idx < 0) || (idx >= (int)imnames.size()))return Mat();
Mat img,im;
if(flag < 2)img = imread(imnames[idx],0);
else img = imread(imnames[idx],1);
if(flag % 2 != 0)flip(img,im,1); else im = img;
return im;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
传递给 OpenCV 的imread函数的(0和1)标志指定将图像加载为 3 通道彩色图像还是单通道灰度图像。 传递给 OpenCV 的flip函数的标志指定围绕 y 轴的镜像。
要访问与特定索引处的图像对应的点集,get_points函数返回浮点坐标的向量,并可以选择镜像其索引的方式,如下所示:
vector<Point2f>
ft_data::get_points(
const int idx, //index of image corresponding to pointsconst bool flipped){ //is the image flipped around the y-axis?
if((idx < 0) || (idx >= (int)imnames.size()))
return vector<Point2f>();
vector<Point2f> p = points[idx];
if(flipped){
Mat im = this->get_image(idx,0); int n = p.size();
vector<Point2f> q(n);
for(int i = 0; i < n; i++){
q[i].x = im.cols-1-p[symmetry[i]].x;
q[i].y = p[symmetry[i]].y;
}return q;
}else return p;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
请注意,指定了镜像标志后,此函数将调用get_image函数。 这是确定图像的宽度所必需的,以便正确地反映人脸特征坐标。 通过简单地将图像宽度作为变量传递,可以设计出一种更有效的方法。 最后,此函数说明了symmetry成员变量的工具。 特定索引的镜像特征位置只是symmetry变量中指定的索引的特征位置,其 x 坐标被翻转和偏置。
如果指定的索引超出数据集的索引,则get_image和get_points函数都将返回空结构。 也可能不是所有的图像都带有标注。 可以将面部跟踪算法设计为处理丢失的数据,但是,这些实现通常涉及面很广,并且超出了本章的范围。 ft_data类实现了一个用于从其集合中删除没有相应标注的样本的函数,如下所示:
void ft_data::rm_incomplete_samples(){ int n = points[0].size(),N = points.size(); for(int i = 1; i < N; i++)n = max(n,int(points[i].size())); for(int i = 0; i < int(points.size()); i++){ if(int(points[i].size()) != n){ points.erase(points.begin()+i); imnames.erase(imnames.begin()+i); i--; }else{ int j = 0; for(; j < n; j++){ if((points[i][j].x <= 0) || (points[i][j].y <= 0))break; } if(j < n){ points.erase(points.begin()+i); imnames.erase(imnames.begin()+i); i--; } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
具有最多标注的样本实例被假定为规范样本。 使用向量的erase函数从集合中删除所有点集少于点数的数据实例。 还要注意,坐标(x, y)小于 1 的点被认为在其对应的图像中丢失(可能是由于遮挡,可见性差或模糊不清)。
ft_data类实现了序列化函数read和write,因此可以轻松存储和加载。 例如,保存数据集可以很简单地完成:
ft_data D; //instantiate data structure
… //populate data
save_ft<ft_data>("mydata.xml",D); //save data
- 1
- 2
- 3
为了可视化数据集,ft_data实现了许多绘图函数。 在visualize_annotations.cpp文件中说明了它们的用法。 这个简单的程序加载存储在命令行指定文件中的标注数据,删除不完整的样本,并显示训练图像及其相应的标注,对称性和连接。 这里展示了 OpenCV 的highgui模块的一些显着功能。 尽管 OpenCV 的highgui模块非常简陋且不适合复杂的用户界面,但它的功能对于在计算机视觉应用中加载和可视化数据和算法输出非常有用。 与其他计算机视觉库相比,这也许是 OpenCV 的与众不同之处。
标注工具
为了帮助生成供本章代码使用的标注,可以在annotate.cpp文件中找到基本的标注工具。 该工具将来自文件或摄像机的视频流作为输入。 以下四个步骤列出了使用该工具的过程:
- 捕获图像:在第一步中,图像流显示在屏幕上,并且用户可以通过按
S键选择要标注的图像。 最好的标注特征集是最大程度地扩展了面部跟踪系统将要跟踪的面部行为范围的那些特征。 - 标注第一张图像:在此第二步中,向用户呈现在上一阶段中选择的第一张图像。 然后,用户继续在与需要跟踪的人脸特征有关的位置上单击图像。
- 标注连接:在此第三步中,为了更好地可视化形状,需要定义点的连接结构。 在此,向用户显示与上一阶段相同的图像,其中现在的任务是依次单击一组点对,以建立人脸模型的连接结构。
- 标注对称性:在此步骤中,仍然使用相同的图像,用户选择显示双边对称性的点对。
- 标注剩余图像:在此最后一步中,此处的过程与步骤 2 相似,不同之处在于用户可以浏览图像集并异步标注它们。
有兴趣的读者可能希望通过改善其可用性来改进此工具,甚至可能集成增量学习过程,从而在对每个附加图像添加标注后更新跟踪模型,然后将其用于初始化点以减轻标注负担。
尽管可以使用一些公开可用的数据集来与本章中开发的代码一起使用(例如,参见下一节中的描述),但是标注工具可以用于构建特定于人的面部跟踪模型,其效果通常要好于通用的,独立于人的,对应的东西。
预标注的数据(MUCT 数据集)
开发面部跟踪系统的阻碍因素之一是人工标注大量图像的繁琐且容易出错的过程,每个图像都有很多点。 为了简化此过程,以遵循本章中的工作,可以从以下位置下载公开可用的 MUCT 数据集。
该数据集包含 3755 张带有 76 点地标的面部图像。 数据集中的对象年龄和种族不同,并且在许多不同的光照条件和头部姿势下被捕获。
要将 MUCT 数据集与本章中的代码一起使用,请执行以下步骤:
- 下载图像集:在此步骤中,可以通过将文件
muct-a-jpg-v1.tar.gz下载到muct-e-jpg-v1.tar.gz并解压缩来获取数据集中的所有图像。 这将生成一个新文件夹,其中将存储所有图像。 - 下载标注:在此步骤中,下载包含标注
muct-landmarks-v1.tar.gz的文件。 将该文件保存并解压缩到与下载图像相同的文件夹中。 - 使用标注工具定义连接和对称性:在此步骤中,从命令行发出命令
./annotate -m $mdir -d $odir,其中$mdir表示保存 MUCT 数据集的文件夹,$odir表示将annotations.yaml文件(包含作为ft_data对象存储的数据)写入到的文件夹。
提示
鼓励使用 MUCT 数据集来快速介绍本章中描述的面部跟踪代码的功能。
几何约束
在面部跟踪中,几何形状是指一组预定义的点的空间配置,这些点对应于人脸在物理上一致的位置(例如眼角,鼻尖和眉毛边缘)。 这些点的特定选择取决于应用,其中一些应用需要超过 100 个点的密集集合,而其他应用只需要稀疏选择。 但是,人脸跟踪算法的鲁棒性通常会随着点数的增加而提高,因为它们的单独测量可以通过其相对的空间依赖性相互增强。 例如,知道眼角的位置很好地表明了鼻子的位置。 但是,通过增加点数获得的鲁棒性改进存在局限性,在这种情况下,表现通常会在大约 100 点之后停滞。 此外,增加用于描述人脸的点集会使计算复杂度线性增加。 因此,对计算负载有严格限制的应用可以用更少的点实现更好的表现。
在这种情况下,更快的跟踪通常会导致在线设置中的跟踪更加准确。 这是因为,当丢下帧时,帧之间的感知运动会增加,并且用于在每个帧中查找人脸的配置的优化算法必须搜索较大的特征点可能配置空间; 当帧之间的位移变得太大时,该过程通常会失败。 总而言之,尽管有关于如何最佳设计人脸特征点选择以获取最佳表现的通用指南,但该选择应专门针对应用领域。
面部几何形状通常被参数化为两个元素的组合:整体(刚性)变形和局部(非刚性)变形。 全局变换说明了脸部在图像中的整体位置,通常可以无限制地进行更改(即,脸部可以出现在图像中的任何位置)。 这包括图像中人脸的(x, y)位置,平面内头部旋转以及图像中人脸的大小。 另一方面,局部变形可解决不同身份的面部形状之间以及表情之间的差异。 与全局转换相反,这些局部变形通常在很大程度上由于人脸特征的高度结构化配置而受到更大的限制。 全局变换是 2D 坐标的通用函数,适用于任何类型的对象,而局部变形是特定于对象的,必须从训练数据集中学习。
在本节中,我们将描述面部结构的几何模型的构建,在此称为形状模型。 根据应用的不同,它可以捕获单个人的表情变化,整个人群的面部形状之间的差异或两者的组合。 该模型在shape_model.hpp和shape_model.cpp文件中找到的shape_model类中实现。 以下代码段是shape_model类标头的一部分,突出了其主要功能:
class shape_model{ //2d linear shape model public: Mat p; //parameter vector (kx1) CV_32F Mat V; //linear subspace (2nxk) CV_32F Mat e; //parameter variance (kx1) CV_32F Mat C; //connectivity (cx2) CV_32S ... void calc_params( const vector<Point2f> &pts, //points to compute parameters const Mat &weight = Mat(), //weight/point (nx1) CV_32F const float c_factor = 3.0); //clamping factor ... vector<Point2f> //shape described by parameters calc_shape(); ... void train( const vector<vector<Point2f> > &p, //N-example shapes const vector<Vec2i> &con = vector<Vec2i>(),//connectivity const float frac = 0.95, //fraction of variation to retain const int kmax = 10); //maximum number of modes to retain ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代表面部形状变化的模型被编码在子空间矩阵V和方差向量e中。 参数向量p存储关于模型的形状的编码。 连接矩阵C也存储在此类中,因为它仅与可视化脸部形状的实例有关。 此类中最受关注的三个函数是calc_params,calc_shape和train。 calc_params函数可将一组点投影到可能的脸部形状空间上。 可选地,它为要投影的每个点提供单独的置信度权重。 calc_shape函数通过使用面部模型(由V和e编码)对参数向量p进行解码来生成一组点。 train函数从面部形状的数据集中学习编码模型,每个面部形状由相同数量的点组成。 参数frac和kmax是训练过程的参数,可以专门用于手头的数据。
在以下各节中将详细介绍此类的功能,在此首先描述普氏分析法,这是一种用于刚性注册点集的方法,其后是用于表示局部变形的线性模型。 train_shape_model.cpp和visualize_shape_model.cpp文件中的程序分别训练和可视化形状模型。 它们的用法将在本节末尾概述。
普氏分析
为了建立面部形状的变形模型,我们必须首先处理原始的带标注的数据,以删除与整体刚性运动有关的分量。 在 2D 模型中对几何图形建模时,刚性运动通常表示为相似度转换。 这包括比例尺,平面内旋转和平移。 下图说明了相似变换下的一组允许的运动类型。 从点集合中删除整体刚体的过程称为 Procrustes 分析。

在数学上,Procrustes 分析的目的是同时找到一个规范的形状,并对每个数据实例进行相似性转换,使它们与规范的形状对齐。 此处,对齐方式是作为每个变形形状与规范形状之间的最小二乘距离测量的。 在shape_model类中,实现此目标的迭代过程如下:
#define fl at<float> Mat shape_model::procrustes( const Mat &X, //interleaved raw shape data as columns const int itol, //maximum number of iterations to try const float ftol) //convergence tolerance { int N = X.cols,n = X.rows/2; Mat Co,P = X.clone();//copy for(int i = 0; i < N; i++){ Mat p = P.col(i); //i'th shape float mx = 0,my = 0; //compute centre of mass... for(int j = 0; j < n; j++){ //for x and y separately mx += p.fl(2*j); my += p.fl(2*j+1); } mx /= n; my /= n; for(int j = 0; j < n; j++){ //remove center of mass p.fl(2*j) -= mx; p.fl(2*j+1) -= my; } } for(int iter = 0; iter < itol; iter++){ Mat C = P*Mat::ones(N,1,CV_32F)/N; //compute normalized... normalize(C,C); //canonical shape if(iter > 0){if(norm(C,Co) < ftol)break;} //converged? Co = C.clone(); //remember current estimate for(int i = 0; i < N; i++){ Mat R = this->rot_scale_align(P.col(i),C); for(int j = 0; j < n; j++){ //apply similarity transform float x = P.fl(2*j,i),y = P.fl(2*j+1,i); P.fl(2*j ,i) = R.fl(0,0)*x + R.fl(0,1)*y; P.fl(2*j+1,i) = R.fl(1,0)*x + R.fl(1,1)*y; } } }return P; //returned procrustes aligned shapes }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
该算法首先减去每个形状实例的质心,然后执行迭代过程,该迭代过程在计算规范形状(作为所有形状的归一化平均值)与旋转和缩放每个形状以最佳匹配规范形状之间交替进行。 估计规范形状的规范化步骤对于固定问题的规模并防止其将所有形状缩小为零是必需的。 锚定标度的选择是任意的,这里我们选择将规范形状向量C的长度强制为 1.0,这也是 OpenCV normalize函数的默认行为。 通过rot_scale_align函数,可以计算出最佳地将每个形状的实例与规范形状的当前估计对齐的平面内旋转和缩放,方法如下:
Mat shape_model::rot_scale_align(
const Mat &src, //[x1;y1;...;xn;yn] vector of source shape
const Mat &dst) //destination shape
{
//construct linear system
int n = src.rows/2; float a=0,b=0,d=0;
for(int i = 0; i < n; i++){
d+= src.fl(2*i)*src.fl(2*i )+src.fl(2*i+1)*src.fl(2*i+1);
a+= src.fl(2*i)*dst.fl(2*i )+src.fl(2*i+1)*dst.fl(2*i+1);
b+= src.fl(2*i)*dst.fl(2*i+1)-src.fl(2*i+1)*dst.fl(2*i );
}
a /= d; b /= d;//solve linear system
return (Mat_<float>(2,2) << a,-b,b,a);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
此函数可最大程度地减小旋转后的形状和标准形状之间的最小二乘方差。 从数学上讲,可以这样写:
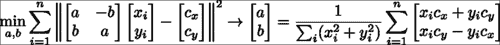
在这里,最小二乘问题的解决方案采用下式右侧等式中所示的封闭形式的解决方案。 请注意,我们求解变量(a, b)而不是求解在缩放的 2D 旋转矩阵中非线性相关的缩放和平面内旋转。 这些变量与比例尺和旋转矩阵有关,如下所示:
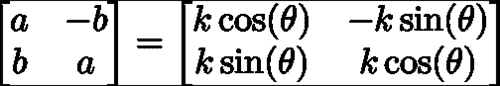
下图说明了 Procrustes 分析对原始带标注的形状数据的影响的可视化。 每个人脸特征都以独特的颜色显示。 平移规范化后,人脸结构变得明显,其中人脸特征的位置围绕其平均位置聚集。 经过迭代缩放和旋转归一化过程后,特征聚类变得更紧凑,并且它们的分布变得更能代表由面部变形引起的变化。 最后一点很重要,因为我们将在以下部分中尝试对这些变形进行建模。 因此,可以将 Procrustes 分析的作用视为对原始数据的预处理操作,从而可以更好地了解面的局部变形模型。

线性形状模型
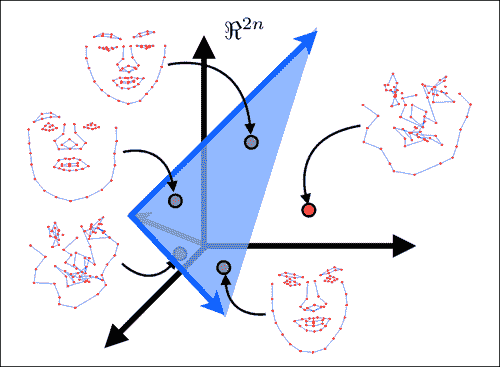
脸部变形建模的目的是找到一个紧凑的参数表示形式,以表示脸部的形状在不同身份之间以及表情之间如何变化。 有多种方法可以实现此目标,并且具有不同的复杂度。 其中最简单的方法是使用面部几何图形的线性表示。 尽管简单,但已显示它可以精确捕获面部变形的空间,特别是当数据集中的面部主要处于正面姿势时。 与它的非线性对应物相比,其优点还在于,推断其表示的参数是极其简单且廉价的操作。 在部署它以限制跟踪过程中的搜索过程时,这起着重要作用。
下图显示了线性建模面部形状的主要思想。 在此,将由N人脸特征组成的脸部形状建模为2N维空间中的单个点。 线性建模的目的是找到一个嵌入到所有脸部形状点(即图像中的绿色点)的2N维空间内的低维超平面。 由于此超平面仅跨越整个2N维空间的子集,因此通常称为子空间。 子空间的维数越低,人脸的表示越紧凑,并且它对跟踪过程施加的约束越强。 这通常会导致更强大的跟踪。 但是,在选择子空间的尺寸时应格外小心,以使其具有足够的能力来覆盖所有脸部的空间,但不要太大,以至于非脸部形状位于其范围内(即图像中的红点)。 应该注意的是,当对来自单个人的数据进行建模时,捕获面部变异性的子空间通常比对多个身份进行建模的子空间更为紧凑。 这就是特定于人的跟踪器的表现要比通用跟踪器好得多的原因之一。
查找跨数据集的最佳低维子空间的过程称为主成分分析(PCA)。 OpenCV 实现了用于计算 PCA 的类,但是,它需要预先指定保留的子空间维数。 由于这通常很难确定先验,因此一种常见的启发式方法是根据其占变异总量的比例来选择它。 在shape_model::train函数中,PCA 的实现如下:
SVD svd(dY*dY.t());
int m = min(min(kmax,N-1),n-1);
float vsum = 0; for(int i = 0; i < m; i++)vsum += svd.w.fl(i);
float v = 0; int k = 0;
for(k = 0; k < m; k++){
v += svd.w.fl(k); if(v/vsum >= frac){k++; break;}
}
if(k > m)k = m;
Mat D = svd.u(Rect(0,0,k,2*n));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在此,dY变量的每一列表示均值减去 Procrustes 对齐的形状。 因此,将奇异值分解(SVD)有效地应用于形状数据(即,dY.t()*dY)的协方差矩阵。 OpenCV 的SVD类的w成员存储数据变异性主要方向上的变异,从最大到最小顺序排列。 选择子空间维数的一种常见方法是选择最小的方向集,该方向集保留数据总能量的一部分frac,这由svd.w的条目表示。 由于这些条目是按从大到小的顺序排列的,因此可以通过贪婪地评估顶部k个可变方向上的能量来枚举子空间选择。 方向本身存储在SVD类的u成员中。 svd.w和svd.u组件通常分别称为特征谱和特征向量。 下图显示了这两个组件的可视化:
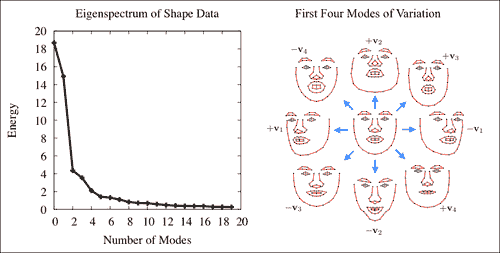
注意
注意,本征谱迅速减小,这表明可以用低维子空间对数据中包含的大多数变化进行建模。
组合的局部-全局表示
图像帧中的形状是由局部变形和整体变形的组合产生的。 从数学上讲,此参数化可能会出现问题,因为这些变换的组合会导致非线性函数不接受封闭形式的解决方案。 解决此问题的常用方法是将全局变换建模为线性子空间,并将其附加到变形子空间。 对于固定形状,可以使用以下子空间对相似性变换进行建模:
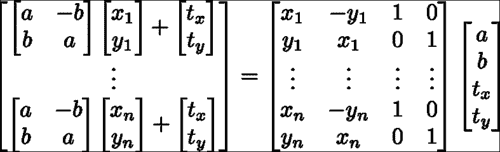
在shape_model类中,此子空间是使用calc_rigid_basis函数生成的。 从中生成子空间的形状(即前面方程中的x和y分量)是 Procustes 对齐的形状(即规范形状)的平均形状。 除了以上述形式构造子空间外,矩阵的每一列都被标准化为单位长度。 在shape_model::train函数中,上一节中描述的变量dY通过投影与刚性运动有关的数据分量来计算,如下所示:
Mat R = this->calc_rigid_basis(Y); //compute rigid subspace
Mat P = R.t()*Y; Mat dY = Y – R*P; //project-out rigidity
- 1
- 2
请注意,此投影被实现为简单的矩阵乘法。 这是可能的,因为刚性子空间的列已进行长度标准化。 这不会改变模型所跨越的空间,仅意味着R.t()*R等于单位矩阵。
由于在学习变形模型之前已将源自刚性变换的可变性方向从数据中删除,因此所得的变形子空间将与刚性变换子空间正交。 因此,连接两个子空间会导致组合的局部局部全局线性表示的脸部形状,这也是正交的。 通过在 OpenCV 的Mat类中实现的 ROI 提取机制,将两个子空间矩阵分配给组合子空间矩阵的子矩阵,可以执行以下连接操作:
V.create(2*n,4+k,CV_32F); //combined subspace
Mat Vr = V(Rect(0,0,4,2*n)); R.copyTo(Vr); //rigid subspace
Mat Vd = V(Rect(4,0,k,2*n)); D.copyTo(Vd); //nonrigid subspace
- 1
- 2
- 3
结果模型的正交性意味着可以很容易地计算出描述形状的参数,就像shape_model::calc_params函数中所做的那样:
p = V.t()*s;
- 1
这里s是向量化的脸部形状,p将坐标存储在代表它的脸部子空间中。
关于对面部形状进行线性建模的最后一点要注意的是如何约束子空间坐标,以使使用该子空间坐标生成的形状保持有效。 在下面的图像中,显示了子空间内的面部形状实例,这些坐标用于在可变方向之一上以四个标准差的增量递增坐标。 请注意,对于较小的值,生成的形状将保持类似面的形状,但随着这些值变得太大而恶化。

防止这种变形的一种简单方法是将子空间坐标值钳位在根据数据集确定的允许区域内。 对此的常见选择是在数据的±3 标准差内的框约束,占数据变化的 99.7%。 找到子空间后,将在shape_model::train函数中计算这些钳位值,如下所示:
Mat Q = V.t()*X; //project raw data onto subspace
for(int i = 0; i < N; i++){ //normalize coordinates w.r.t scale
float v = Q.fl(0,i); Mat q = Q.col(i); q /= v;
}
e.create(4+k,1,CV_32F); multiply(Q,Q,Q);
for(int i = 0; i < 4+k; i++){
if(i < 4)e.fl(i) = -1; //no clamping for rigid coefficients
else e.fl(i) = Q.row(i).dot(Mat::ones(1,N,CV_32F))/(N-1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意,在相对于第一维(即比例尺)的坐标进行归一化之后,在子空间坐标Q上计算了方差。 这样可以防止规模较大的数据样本主导估计。 另外,请注意,为刚性子空间(即V的前四列)的坐标的方差分配了负值。 夹紧函数shape_model::clamp检查特定方向的方差是否为负,并且仅在否时才应用夹紧,如下所示:
void shape_model::clamp(
const float c){ //clamping as fraction of standard deviation
double scale = p.fl(0); //extract scale
for(int i = 0; i < e.rows; i++){
if(e.fl(i) < 0)continue; //ignore rigid components
float v = c*sqrt(e.fl(i)); //c*standard deviations box
if(fabs(p.fl(i)/scale) > v){ //preserve sign of coordinate
if(p.fl(i) > 0)p.fl(i) = v*scale; //positive threshold
else p.fl(i) = -v*scale; //negative threshold
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这是因为训练数据通常是在人为设置的设置下捕获的,在该设置下,人脸直立并以特定比例在图像中居中。 夹紧形状模型的刚性组件以使其与训练集中的配置保持一致将过于严格。 最后,由于在比例尺归一化的框架中计算了每个可变形坐标的方差,因此在夹紧期间必须对坐标应用相同的比例尺。
训练和可视化
在train_shape_model.cpp中可以找到用于从标注数据中训练形状模型的示例程序。 在命令行参数argv[1]包含标注数据的路径的情况下,训练首先将数据加载到内存中并删除不完整的样本,如下所示:
ft_data data = load_ft<ft_data>(argv[1]);
data.rm_incomplete_samples();
- 1
- 2
然后,将每个示例的标注以及可选的镜像对应标注存储在向量中,然后将它们传递给训练函数,如下所示:
vector<vector<Point2f> > points;
for(int i = 0; i < int(data.points.size()); i++){
points.push_back(data.get_points(i,false));
if(mirror)points.push_back(data.get_points(i,true));
}
- 1
- 2
- 3
- 4
- 5
然后通过对shape_model::train的单个函数调用来训练形状模型,如下所示:
shape_model smodel; smodel.train(points,data.connections,frac,kmax);
- 1
尽管默认设置为 0.95 和 20,但是frac(即要保留的变化比例)和kmax(即要保留的特征向量的最大数量)也可以选择设置。 分别在大多数情况下往往效果很好。 最后,在命令行参数argv[2]包含将经过训练的形状模型保存到的路径的情况下,可以通过单个函数调用执行保存,如下所示:
save_ft(argv[2],smodel);
- 1
通过为shape_model类定义read和write序列化函数,可以简化此步骤。
为了可视化训练后的形状模型,visualize_shape_model.cpp程序依次对每个方向上学习到的非刚性变形进行动画处理。 首先将形状模型加载到内存中,如下所示:
shape_model smodel = load_ft<shape_model>(argv[1]);
- 1
将模型放置在显示窗口中心的刚性参数计算如下:
int n = smodel.V.rows/2;
float scale = calc_scale(smodel.V.col(0),200);
float tranx =
n*150.0/smodel.V.col(2).dot(Mat::ones(2*n,1,CV_32F));
float trany =
n*150.0/smodel.V.col(3).dot(Mat::ones(2*n,1,CV_32F));
- 1
- 2
- 3
- 4
- 5
- 6
在这里,calc_scale函数查找将生成宽度为 200 像素的面部形状的缩放系数。 通过查找产生 150 个像素的平移的系数来计算平移分量(也就是说,模型以均心为中心,显示窗口的大小为300 x 300像素)。
注意
请注意,shape_model::V的第一列分别对应于比例,第三列和第四列分别对应于 x 和 y 平移。
然后生成参数值的轨迹,该轨迹从零开始,移至正极值,移至负极值,然后返回零,如下所示:
vector<float> val;
for(int i = 0; i < 50; i++)val.push_back(float(i)/50);
for(int i = 0; i < 50; i++)val.push_back(float(50-i)/50);
for(int i = 0; i < 50; i++)val.push_back(-float(i)/50);
for(int i = 0; i < 50; i++)val.push_back(-float(50-i)/50);
- 1
- 2
- 3
- 4
- 5
在此,动画的每个阶段都由五十个增量组成。 然后使用该轨迹为人脸模型制作动画,并在显示窗口中呈现结果,如下所示:
Mat img(300,300,CV_8UC3); namedWindow("shape model"); while(1){ for(int k = 4; k < smodel.V.cols; k++){ for(int j = 0; j < int(val.size()); j++){ Mat p = Mat::zeros(smodel.V.cols,1,CV_32F); p.at<float>(0) = scale; p.at<float>(2) = tranx; p.at<float>(3) = trany; p.at<float>(k) = scale*val[j]`3.0` sqrt(smodel.e.at<float>(k)); p.copyTo(smodel.p); img = Scalar::all(255); vector<Point2f> q = smodel.calc_shape(); draw_shape(img,q,smodel.C); imshow("shape model",img); if(waitKey(10) == 'q')return 0; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
注意
注意,刚性系数(即与shape_model::V的前四列相对应的刚性系数)始终设置为先前计算的值,以将面部放置在显示窗口的中央。
人脸特征检测器
检测图像中的人脸特征与一般物体检测非常相似。 OpenCV 具有一组用于构建通用对象检测器的复杂功能,其中最著名的是用于实现著名的 Viola-Jones 人脸检测器的基于 Haar 的特征检测器的级联。 但是,有一些独特的因素使人脸特征检测变得独特。 这些如下:
- 精确度与鲁棒性:在一般物体检测中,目的是找到图像中物体的粗略位置。 人脸特征检测器需要对特征位置进行高度精确的估计。 几个像素的误差在对象检测中被认为是无关紧要的,但这可能意味着通过特征检测在面部表情估计中的微笑和皱眉之间的差异。
- 有限的支持空间带来的歧义:通常假设通用对象检测中的关注对象具有足够的图像结构,因此可以可靠地将其与不包含该对象的图像区域区分开。 对于通常具有有限空间支持的人脸特征通常不是这种情况。 这是因为不包含对象的图像区域通常会显示出与人脸特征非常相似的结构。 例如,从以特征为中心的小边界框看,脸部外围的特征可以很容易地与其他任何包含穿过其中心的强边缘的图像块混淆。
- 计算复杂度:通用对象检测旨在查找图像中对象的所有实例。 另一方面,脸部追踪需要所有脸部特征的位置,通常范围从 20 到 100 个左右。 因此,有效地评估每个特征检测器的能力对于构建可以实时运行的面部跟踪器至关重要。
由于这些差异,在面部跟踪中使用的人脸特征检测器通常是出于这一目的而专门设计的。 当然,在面部跟踪中,存在许多将通用对象检测技术应用于人脸特征检测器的实例。 但是,对于哪种代表最适合该问题,社区似乎尚未达成共识。
在本节中,我们将使用一种表示可能是最简单的模型:线性图像斑块来构建人脸特征检测器。 尽管它很简单,但在设计学习程序时要格外小心,我们将看到,这种表示实际上可以给出用于面部跟踪算法的人脸特征位置的合理估计。 此外,它们的简单性使得能够进行极其快速的评估,从而可以进行实时面部跟踪。 由于其表示为图像补丁,因此人脸特征检测器被称为补丁模型。 该模型在patch_model.hpp和patch_model.cpp文件中找到的patch_model类中实现。 以下代码段是patch_model类的标题,突出显示了其主要功能:
class patch_model{ public: Mat P; //normalized patch ... Mat //response map calc_response( const Mat &im, //image patch of search region const bool sum2one = false); //normalize to sum-to-one? ... void train(const vector<Mat> &images, //training image patches const Size psize, //patch size const float var = 1.0, //ideal response variance const float lambda = 1e-6, //regularization weight const float mu_init = 1e-3, //initial step size const int nsamples = 1000, //number of samples const bool visi = false); //visualize process? ... };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
用于检测人脸特征的补丁模型存储在矩阵P中。 此类中最受关注的两个函数是calc_response和train。 calc_response函数在搜索区域im上的每个整数位移处评估补丁模型的响应。 train函数学习大小为psize的补丁模型P,平均而言,它会在训练集上产生尽可能接近理想响应图的响应图。 参数var,lambda,mu_init和nsamples是训练过程的参数,可以对其进行调整以优化手头数据的表现。
在本节中将详细介绍此类的功能。 我们首先讨论相关补丁及其训练过程,这将用于学习补丁模型。 接下来,将描述patch_models类,该类是每个人脸特征的补丁模型的集合,并且具有说明全局转换的功能。 train_patch_model.cpp和visualize_patch_model.cpp中的程序分别训练和可视化补丁模型,其用法将在本部分末尾的人脸特征检测器上概述。
基于相关性的补丁模型
在学习检测器中,有两个主要的竞争范例:生成式和判别式。 生成方法学习图像补丁的基本表示形式,该形式可以最佳地以所有表现形式生成对象外观。 另一方面,区分性方法学习一种表示,该表示可以最好地将对象的实例与模型在部署时可能会遇到的其他对象区分开。 生成方法的优势在于,生成的模型对特定于对象的属性进行编码,从而可以从视觉上检查对象的新实例。 属于生成方法范式的一种流行方法是著名的 Eigenfaces 方法。 判别方法的优点是模型的全部特征直接针对当前的问题; 将对象的实例与所有其他实例区分开。 在所有判别方法中,最著名的也许就是支持向量机。 尽管这两种范例都可以在许多情况下很好地工作,但是我们将看到,将人脸特征建模为图像块时,判别范例要优越得多。
注意
请注意,EigenFace 和支持向量机方法最初是为分类而不是检测或图像对齐而开发的。 但是,它们的基本数学概念已显示适用于面部跟踪领域。
学习判别式补丁模型
给定带标注的数据集,可以彼此独立地学习特征检测器。 判别补丁模型的学习目标是构造一个图像补丁,当该补丁与包含人脸特征的图像区域互相关时,在特征位置产生强烈的响应,而在其他位置产生较弱的响应。 从数学上讲,这可以表示为:
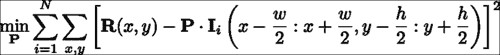
在这里,P表示补丁模型,I表示第i个训练图像,I(a:b, c:d)表示其左上和右下的矩形区域,角分别位于(a, c)和(b, d)。 周期符号表示内部乘积运算,R表示理想响应图。 该方程式的解决方案是一个补丁模型,该模型生成的响应图平均而言最接近使用最小二乘法标准测量的理想响应图。 理想响应图的一个显而易见的选择是R,除了中心处,其他任何地方都为零(假设训练图像块位于感兴趣的人脸特征的中心)。 实际上,由于图像是手工标记的,因此始终会出现标注错误。 为了解决这个问题,通常将R描述为距中心距离的衰减函数。 一个很好的选择是 2D-Gaussian 分布,它等效于假设标注错误是 Gaussian 分布。 下图显示了该设置的可视化,用于左外眼角:
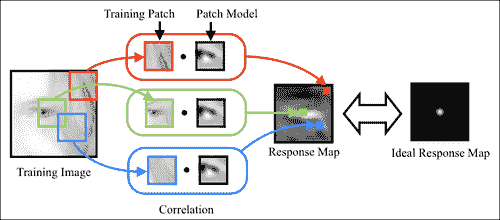
如先前所写的学习目标是以通常被称为线性最小二乘法的形式。 这样,它提供了封闭形式的解决方案。 但是,此问题的自由度(即变量可以改变以解决问题的方式的数量)等于补丁中的像素数量。 因此,即使对于中等大小的补丁或示例,40 x 40补丁模型也具有 1600 个自由度,但求解最佳补丁模型的计算成本和内存需求可能会令人望而却步。
解决学习问题的有效方法是线性方程组,它是一种称为随机梯度下降的方法。 通过将学习目标可视化为补丁模型自由度上的错误地形,随机梯度下降迭代地估计了地形的梯度方向,并在相反方向上走了一小步。 对于我们的问题,可以通过仅考虑针对训练集中的单个随机选择图像的学习目标的梯度来计算梯度的近似值:

在patch_model类中,此学习过程是在train函数中实现的:
void patch_model::train( const vector<Mat> &images, //featured centered training images const Size psize, //desired patch model size const float var, //variance of annotation error const float lambda, //regularization parameter const float mu_init, //initial step size const int nsamples, //number of stochastic samples const bool visi){ //visualise training process int N = images.size(),n = psize.width*psize.height; int dx = wsize.width-psize.width; //center of response map int dy = wsize.height-psize.height; //... Mat F(dy,dx,CV_32F); //ideal response map for(int y = 0; y < dy; y++){ float vy = (dy-1)/2 - y; for(int x = 0; x < dx; x++){float vx = (dx-1)/2 - x; F.fl(y,x) = exp(-0.5*(vx*vx+vy*vy)/var); //Gaussian } } normalize(F,F,0,1,NORM_MINMAX); //normalize to [0:1] range //allocate memory Mat I(wsize.height,wsize.width,CV_32F); Mat dP(psize.height,psize.width,CV_32F); Mat O = Mat::ones(psize.height,psize.width,CV_32F)/n; P = Mat::zeros(psize.height,psize.width,CV_32F); //optimise using stochastic gradient descent RNG rn(getTickCount()); //random number generator double mu=mu_init,step=pow(1e-8/mu_init,1.0/nsamples); for(int sample = 0; sample < nsamples; sample++){ int i = rn.uniform(0,N); //randomly sample image index I = this->convert_image(images[i]); dP = 0.0; for(int y = 0; y < dy; y++){ //compute stochastic gradient for(int x = 0; x < dx; x++){ Mat Wi=I(Rect(x,y,psize.width,psize.height)).clone(); Wi -= Wi.dot(O); normalize(Wi,Wi); //normalize dP += (F.fl(y,x) – P.dot(Wi))*Wi; } } P += mu*(dP - lambda*P); //take a small step mu *= step; //reduce step size ... }return; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
前面代码中的第一个突出显示的代码段是计算理想响应图的位置。 由于图像集中在感兴趣的人脸特征上,因此所有样本的响应图均相同。 在第二个突出显示的代码段中,确定步长的衰减率step,以便在nsamples迭代之后,步长将衰减到接近零的值。 第三个突出显示的代码段是计算随机梯度方向并用于更新补丁模型的位置。 这里有两件事要注意。 首先,将训练中使用的图像传递到patch_model::convert_image函数,该函数将图像转换为单通道图像(如果是彩色图像),并将自然对数应用于图像像素强度:
I += 1.0; log(I,I);
- 1
由于未定义零的对数,因此在应用对数之前,将偏置值 1 添加到每个像素。 在训练图像上执行此预处理的原因是,对数比例图像对对比度差异和照明条件的变化更鲁棒。 下图显示了面部区域中对比度不同的两个面部的图像。 在对数刻度图像中,图像之间的差异不如在原始图像中明显。

关于更新方程式要注意的第二点是从更新方向减去lambda*P。 这有效地使解决方案变得不会太大。 一种通常在机器学习算法中应用的过程,用于促进对看不见的数据进行泛化。 比例因子lambda是用户定义的,通常取决于问题。 但是,较小的值通常对于学习用于人脸特征检测的补丁模型非常有效。
生成式与判别式补丁模型
尽管如前所述可以轻松学习判别性补丁模型,但是值得考虑的是,生成性补丁模型及其相应的训练方式是否足够简单以实现相似的结果。 相关补丁模型的生成对应物是平均补丁。 该模型的学习目标是构建一个单个图像斑块,该图像块应尽可能接近通过最小二乘标准测量的人脸特征的所有示例:
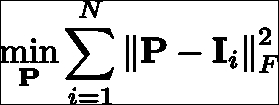
该问题的解决方案正是所有以特征为中心的训练图像补丁的平均值。 因此,以某种方式,该目标提供的解决方案要简单得多。
在下图中,显示了对响应图的比较,该响应图是通过将平均和相关补丁模型与示例图像互相关而获得的。 还示出了各自的平均值和相关补丁模型,其中像素值的范围被标准化以用于可视化目的。 尽管这两种补丁程序模型类型显示出一些相似之处,但是它们生成的响应图却大不相同。 尽管相关补丁模型生成的响应图在特征位置周围高度峰化,但平均补丁模型生成的响应图过于平滑,无法将特征位置与附近的特征区分开。 在检查补丁模型的外观时,相关补丁模型主要是灰色的,对应于未归一化像素范围内的零,在策略上围绕人脸特征的突出区域放置了强正负值。 因此,它仅保留了训练补丁的组件,可用于将其与未对齐的配置区分开来,从而导致响应出现高度峰值。 相反,平均补丁模型不编码未对齐数据的知识。 结果,它不太适合人脸特征定位的任务,在该任务中,将对齐的图像块与自身的本地移位版本区分开。
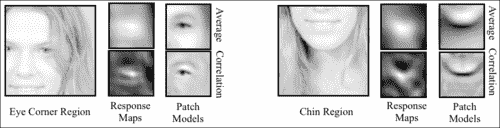
解释整体几何变换
到目前为止,我们已经假设训练图像以人脸特征为中心,并相对于全局比例和旋转进行了标准化。 实际上,在跟踪过程中,脸部可以在图像中以任意比例出现并旋转。 因此,必须设计一种机制来解决训练和测试条件之间的这种差异。 一种方法是在训练过程中期望遇到的范围内,以比例和旋转方式合成训练图像。 然而,作为相关性补丁模型的简单形式的检测器通常缺乏为这类数据生成有用的响应图的能力。 另一方面,相关补丁模型确实表现出一定程度的鲁棒性,可以抵抗规模和旋转方面的小扰动。 由于视频序列中连续帧之间的运动相对较小,因此可以利用前一帧中人脸的估计全局变换来针对缩放和旋转标准化当前图像。 启用此过程所需要做的只是选择一个参考框架,在该参考框架中学习相关补丁模型。
patch_models类存储每个人脸特征的相关补丁模型以及在其中训练它们的参考框架。 面部跟踪器代码直接与patch_models类(而不是patch_model类)联系以获取特征检测。 此类声明的以下代码片段突出了其主要功能:
class patch_models{ public: Mat reference; //reference shape [x1;y1;...;xn;yn] vector<patch_model> patches; //patch model/facial feature ... void train(ft_data &data, //annotated image and shape data const vector<Point2f> &ref, //reference shape const Size psize, //desired patch size const Size ssize, //training search window size const bool mirror = false, //use mirrored training data const float var = 1.0, //variance of annotation error const float lambda = 1e-6, //regularisation weight const float mu_init = 1e-3, //initial step size const int nsamples = 1000, //number of samples const bool visi = false); //visualise training procedure? ... vector<Point2f>//location of peak responses/feature in image calc_peaks( const Mat &im, //image to detect features in const vector<Point2f> &points, //current estimate of shape const Size ssize = Size(21,21)); //search window size ... };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
reference形状存储为(x, y)坐标的交错集,用于标准化训练图像的比例和旋转,以及随后在部署测试图像时对其进行标准化。 在patch_models::train函数中,这首先通过使用patch_models::calc_simil函数计算给定图像的reference形状和带标注的形状之间的相似度变换来解决,这解决了与shape_model::procrustes函数相似的问题 ,尽管只有一对形状。 由于旋转和缩放在所有人脸特征上都是通用的,因此图像标准化过程仅需要调整此相似度变换,以解决图像中每个特征的中心和标准化图像补丁的中心。 在patch_models::train中,实现方式如下:
Mat S = this->calc_simil(pt),A(2,3,CV_32F);
A.fl(0,0) = S.fl(0,0); A.fl(0,1) = S.fl(0,1);
A.fl(1,0) = S.fl(1,0); A.fl(1,1) = S.fl(1,1);
A.fl(0,2) = pt.fl(2*i ) - (A.fl(0,0)*(wsize.width -1)/2 +
A.fl(0,1)*(wsize.height-1)/2);
A.fl(1,2) = pt.fl(2*i+1) – (A.fl(1,0)*(wsize.width -1)/2 +
A.fl(1,1)*(wsize.height-1)/2);
Mat I; warpAffine(im,I,A,wsize,INTER_LINEAR+WARP_INVERSE_MAP);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
此处,wsize是归一化训练图像的总大小,是补丁大小和搜索区域大小的总和。 如前所述,从参考形状到带标注的形状pt的相似度变换的左上(2 x 2)块与变换的比例和旋转分量相对应,保留在传递的仿射变换中 OpenCV 的warpAffine函数。 仿射变换A的最后一列是一种调整,它将在翘曲(即归一化平移)后呈现第i个人脸特征位置在归一化图像中居中的位置。 最后,cv::warpAffine函数具有从图像到参考帧变形的默认设置。 由于计算了相似度转换以将reference形状转换为图像空间标注pt,因此需要设置WARP_INVERSE_MAP标志以确保函数在所需方向上应用扭曲。 在patch_models::calc_peaks函数中执行完全相同的过程,另外的步骤是重新使用参考帧和图像帧中当前形状之间的计算相似度变换来对检测到的人脸特征进行非标准化处理,并将其适当放置在图片中。
vector<Point2f> patch_models::calc_peaks(const Mat &im, const vector<Point2f> &points,const Size ssize){ int n = points.size(); assert(n == int(patches.size())); Mat pt = Mat(points).reshape(1,2*n); Mat S = this->calc_simil(pt); Mat Si = this->inv_simil(S); vector<Point2f> pts = this->apply_simil(Si,points); for(int i = 0; i < n; i++){ Size wsize = ssize + patches[i].patch_size(); Mat A(2,3,CV_32F),I; A.fl(0,0) = S.fl(0,0); A.fl(0,1) = S.fl(0,1); A.fl(1,0) = S.fl(1,0); A.fl(1,1) = S.fl(1,1); A.fl(0,2) = pt.fl(2*i ) - (A.fl(0,0)*(wsize.width -1)/2 + A.fl(0,1)*(wsize.height-1)/2); A.fl(1,2) = pt.fl(2*i+1) – (A.fl(1,0)*(wsize.width -1)/2 + A.fl(1,1)*(wsize.height-1)/2); warpAffine(im,I,A,wsize,INTER_LINEAR+WARP_INVERSE_MAP); Mat R = patches[i].calc_response(I,false); Point maxLoc; minMaxLoc(R,0,0,0,&maxLoc); pts[i] = Point2f(pts[i].x + maxLoc.x - 0.5*ssize.width, pts[i].y + maxLoc.y - 0.5*ssize.height); }return this->apply_simil(S,pts);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
在先前代码中的第一个突出显示的代码片段中,正向和逆向相似度转换都被计算。 这里需要逆变换的原因是,使得可以根据当前形状估计的归一化位置来调整每个特征的响应图的峰值。 必须先执行此操作,然后再重新应用相似度变换,以使用patch_models::apply_simil函数将人脸特征位置的新估计值重新放回图像帧中。
训练和可视化
在train_patch_model.cpp中可以找到用于从标注数据中训练补丁模型的示例程序。 在命令行参数argv[1]包含标注数据的路径的情况下,训练首先将数据加载到内存中并删除不完整的样本:
ft_data data = load_ft<ft_data>(argv[1]);
data.rm_incomplete_samples();
- 1
- 2
对于patch_models类中的参考形状,最简单的选择是训练集的平均形状,缩放到所需的大小。 假设先前已为此数据集训练了形状模型,则通过首先按如下方式加载存储在argv[2]中的形状模型来计算参考形状:
shape_model smodel = load_ft<shape_model>(argv[2]);
- 1
接下来是缩放的居中平均形状的计算:
smodel.p = Scalar::all(0.0);
smodel.p.fl(0) = calc_scale(smodel.V.col(0),width);
vector<Point2f> r = smodel.calc_shape();
- 1
- 2
- 3
calc_scale函数计算比例因子,以将平均形状(即shape_model::V的第一列)转换为宽度为width的形状。 定义参考形状r 后,可以通过单个函数调用来训练补丁模型集:
patch_models pmodel; pmodel.train(data,r,Size(psize,psize),Size(ssize,ssize));
- 1
参数width,psize和ssize的最佳选择取决于应用; 但是,通常分别使用默认值 100、11 和 11 可以得出合理的结果。
尽管训练过程非常简单,但仍需要一些时间才能完成。 根据人脸特征的数量,贴片的大小以及优化算法中随机样本的数量,训练过程可能需要几分钟到一个小时以上的时间。 但是,由于每个补丁的训练都可以独立于所有其他补丁执行,因此可以通过跨多个处理器核心或机器并行进行训练过程来大大加快此过程。
训练完成后,可以使用visualize_patch_model.cpp中的程序可视化生成的补丁模型。 与visualize_shape_model.cpp程序一样,此处的目的是目视检查结果,以验证在训练过程中是否出现任何问题。 该程序将生成所有补丁模型patch_model::P的合成图像,每个模型均以参考形状patch_models::reference中它们各自的特征位置为中心,并在当前索引处于活动状态的补丁周围显示一个边界矩形。 cv::waitKey函数用于获取用户输入,以选择有效的补丁索引并终止程序。 下图显示了为具有不同空间支持的补丁模型学习的复合补丁图像的三个示例。 尽管使用了相同的训练数据,但修改补丁模型的空间支持似乎会实质上改变补丁模型的结构。 以这种方式直观地检查结果可以直观地了解如何修改训练过程甚至训练过程本身的参数,以便针对特定应用优化结果。

人脸检测和初始化
到目前为止描述的用于面部跟踪的方法已经假设图像中的人脸特征位于与当前估计合理合理的范围内。 尽管此假设在跟踪过程中是合理的,帧之间的面部运动通常很小,但我们仍然面临着如何在序列的第一帧中初始化模型的难题。 一个明显的选择是使用 OpenCV 的内置级联检测器来找到人脸。 但是,模型在检测到的边界框中的放置将取决于对要跟踪的人脸特征所做的选择。 为了与本章到目前为止我们遵循的数据驱动范例保持一致,一个简单的解决方案是学习人脸检测的边界框和人脸特征之间的几何关系。
face_detector类完全实现了此解决方案。 声明其功能的摘录如下:
class face_detector{ //face detector for initialisation public: string detector_fname; //file containing cascade classifier Vec3f detector_offset; //offset from center of detection Mat reference; //reference shape CascadeClassifier detector; //face detector vector<Point2f> //points describing detected face in image detect(const Mat &im, //image containing face const float scaleFactor = 1.1,//scale increment const int minNeighbours = 2, //minimum neighborhood size const Size minSize = Size(30,30));//minimum window size void train(ft_data &data, //training data const string fname, //cascade detector const Mat &ref, //reference shape const bool mirror = false, //mirror data? const bool visi = false, //visualize training? const float frac = 0.8, //fraction of points in detection const float scaleFactor = 1.1, //scale increment const int minNeighbours = 2, //minimum neighbourhood size const Size minSize = Size(30,30)); //minimum window size ... };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
该类具有四个公共成员变量:称为detector_fname的cv::CascadeClassifier类型的对象的路径,从检测边界框到图像中人脸的位置和比例的一组偏移量detector_offset,放置在边界框reference和人脸检测器detector中的参考形状。 面部跟踪系统使用的主要函数是face_detector::detect,它以图像作为输入以及cv::CascadeClassifier类的标准选项,并返回图像中人脸特征位置的粗略估计。 其实现如下:
Mat gray; //convert image to grayscale and histogram equalize if(im.channels() == 1)gray = im; else cvtColor(im,gray,CV_RGB2GRAY); Mat eqIm; equalizeHist(gray,eqIm); vector<Rect> faces; //detect largest face in image detector.detectMultiScale(eqIm,faces,scaleFactor, minNeighbours,0 |CV_HAAR_FIND_BIGGEST_OBJECT |CV_HAAR_SCALE_IMAGE,minSize); if(faces.size() < 1){return vector<Point2f>();} Rect R = faces[0]; Vec3f scale = detector_offset*R.width; int n = reference.rows/2; vector<Point2f> p(n); for(int i = 0; i < n; i++){ //predict face placement p[i].x = scale[2]*reference.fl(2*i ) + R.x + 0.5 * R.width + scale[0]; p[i].y = scale[2]*reference.fl(2*i+1) + R.y + 0.5 * R.height + scale[1]; }return p;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
除了将CV_HAAR_FIND_BIGGEST_OBJECT标志设置为可以跟踪图像中最突出的脸部以外,按照通常的方式检测图像中的脸部。 高亮显示的代码是根据检测到的面部边界框将参考形状放置在图像中的位置。 detector_offset成员变量包含三个成分:面部中心相对于检测边界框中心的(x, y)偏移量,以及缩放比例因子,该比例因子调整参考形状的大小以最适合图像中的面部 。 所有这三个分量都是边界框宽度的线性函数。
边界框的宽度和detector_offset变量之间的线性关系是从face_detector::train函数中带标注的数据集中学习的。 通过将训练数据加载到内存中并分配参考形状来开始学习过程:
detector.load(fname.c_str()); detector_fname = fname; reference = ref.clone();
- 1
与patch_models类中的参考形状一样,参考形状的方便选择是数据集中的标准化平均脸部形状。 然后,将cv::CascadeClassifier应用于数据集中的每个图像(以及可选的镜像副本),并检查结果以确保足够的带标注的点位于检测到的边界框中(请参见本节末尾的图) 防止因误检而学习:
if(this->enough_bounded_points(pt,faces[0],frac)){
Point2f center = this->center_of_mass(pt);
float w = faces[0].width;
xoffset.push_back((center.x -
(faces[0].x+0.5*faces[0].width ))/w);
yoffset.push_back((center.y -
(faces[0].y+0.5*faces[0].height))/w);
zoffset.push_back(this->calc_scale(pt)/w);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果有frac个标注点的一部分位于边界框内,则其宽度与该图像的偏移参数之间的线性关系将作为新条目添加到 STL vector类对象中。 在此,face_detector::center_of_mass函数计算该图像的带标注点集的质心,face_detector::calc_scale函数计算将参考形状转换为带中心标注形状的比例因子。 处理完所有图像后,将detector_offset变量设置为所有特定于图像的偏移量的中值:
Mat X = Mat(xoffset),Xsort,Y = Mat(yoffset),Ysort,Z = Mat(zoffset),Zsort;
cv::sort(X,Xsort,CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
int nx = Xsort.rows;
cv::sort(Y,Ysort,CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
int ny = Ysort.rows;
cv::sort(Z,Zsort,CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
int nz = Zsort.rows;
detector_offset =
Vec3f(Xsort.fl(nx/2),Ysort.fl(ny/2),Zsort.fl(nz/2));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
与形状和补丁模型一样,train_face_detector.cpp中的简单程序是如何构建和保存face_detector对象以供以后在跟踪器中使用的示例。 它首先加载标注数据和形状模型,然后将参考形状设置为训练数据的均心平均值(即shape_model类的标识形状):
ft_data data = load_ft<ft_data>(argv[2]);
shape_model smodel = load_ft<shape_model>(argv[3]);
smodel.set_identity_params();
vector<Point2f> r = smodel.calc_shape();
Mat ref = Mat(r).reshape(1,2*r.size());
- 1
- 2
- 3
- 4
- 5
然后,训练和保存人脸检测器包含两个函数调用:
face_detector detector;
detector.train(data,argv[1],ref,mirror,true,frac);
save_ft<face_detector>(argv[4],detector);
- 1
- 2
- 3
为了测试所产生的形状放置程序的表现,visualize_face_detector.cpp中的程序为视频或摄像机输入流中的每个图像调用face_detector::detect函数,并将结果绘制在屏幕上。 下图显示了使用这种方法的结果示例。尽管放置的形状与图像中的个体不匹配,但是其放置位置足够接近,因此可以使用下一节中描述的方法进行面部跟踪:

人脸追踪
面部跟踪的问题可能是由于找到了一种有效且鲁棒的方式来组合各种人脸特征的独立检测与它们所表现出的几何相关性,以便在序列的每个图像中获得准确的人脸特征位置估计而存在的问题 。 考虑到这一点,也许值得考虑是否完全需要几何相关性。 在下图中,显示了在有和没有几何约束的情况下检测人脸特征的结果。 这些结果清楚地突出了捕获人脸特征之间的空间相互依赖性的好处。 这两种方法的相对表现是典型的,因此严格依赖检测会导致解决方案过于嘈杂。 这是因为不能期望每个人脸特征的响应图总是在正确的位置达到峰值。 无论是由于图像噪声,光线变化还是表情变化,克服人脸特征检测器局限性的唯一方法就是利用它们彼此共享的几何关系。

将面部几何图形合并到跟踪过程中的一种特别简单但出人意料的有效方法是将特征检测的输出投影到线性形状模型的子空间上。 这等于是最小化了原始点与其在子空间上最接近的合理形状之间的距离。 因此,当特征检测中的空间噪声接近于高斯分布时,投影会产生最大可能的解。 在实践中,有时检测错误的分布不遵循高斯分布,因此需要引入其他机制来解决这个问题。
人脸追踪器的实现
可以在face_tracker类中找到人脸跟踪算法的实现(请参见face_tracker.cpp和face_tracker.hpp)。 以下代码是其标题的摘要,突出了其主要功能:
class face_tracker{ public: bool tracking; //are we in tracking mode? fps_timer timer; //frames/second timer vector<Point2f> points; //current tracked points face_detector detector; //detector for initialisation shape_model smodel; //shape model patch_models pmodel; //feature detectors face_tracker(){tracking = false;} int //0 = failure track(const Mat &im, //image containing face const face_tracker_params &p = //fitting parameters face_tracker_params()); //default tracking parameters void reset(){ //reset tracker tracking = false; timer.reset(); } ... protected: ... vector<Point2f> //points for fitted face in image fit(const Mat &image,//image containing face const vector<Point2f> &init, //initial point estimates const Size ssize = Size(21,21),//search region size const bool robust = false, //use robust fitting? const int itol = 10, //maximum number of iterations const float ftol = 1e-3); //convergence tolerance };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
该类具有shape_model,patch_models和face_detector类的公共成员实例。 它使用这三个类的函数来实现跟踪。 timer变量是fps_timer类的实例,可跟踪调用face_tracker::track函数的帧速率,可用于分析效果补丁和形状模型配置对算法的计算复杂性 。 tracking成员变量是一个标志,用于指示跟踪过程的当前状态。 当此标志设置为false时,就像在构造器和face_tracker::reset函数中一样,跟踪器将进入检测模式,其中face_detector::detect函数将应用于下一个传入图像以初始化模型。 在跟踪模式下,用于推断下一个传入图像中的人脸特征位置的初始估计值只是它们在上一帧中的位置。 完整的跟踪算法的实现简单如下:
int face_tracker::
track(const Mat &im,const face_tracker_params &p){
Mat gray; //convert image to grayscale
if(im.channels()==1)gray=im;
else cvtColor(im,gray,CV_RGB2GRAY);
if(!tracking) //initialize
points = detector.detect(gray,p.scaleFactor,
p.minNeighbours,p.minSize);
if((int)points.size() != smodel.npts())return 0;
for(int level = 0; level < int(p.ssize.size()); level++)
points = this->fit(gray,points,p.ssize[level],
p.robust,p.itol,p.ftol);
tracking = true; timer.increment(); return 1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
除了簿记操作(例如设置适当的tracking状态并增加跟踪时间)外,跟踪算法的核心是多级拟合过程,该过程在前面的代码片段中突出显示。 在face_tracker::fit函数中实现的拟合算法,以face_tracker_params::ssize中存储的不同搜索窗口大小多次应用,其中前一级的输出用作下一级的输入。 在最简单的设置下,face_tracker_params::ssize函数在图像中当前估计的形状周围执行人脸特征检测:
smodel.calc_params(init);
vector<Point2f> pts = smodel.calc_shape();
vector<Point2f> peaks = pmodel.calc_peaks(image,pts,ssize);
- 1
- 2
- 3
还将结果投影到人脸形状的子空间上:
smodel.calc_params(peaks);
pts = smodel.calc_shape();
- 1
- 2
为了解决人脸特征检测位置中的总体异常值,可以通过将robust标志设置为true来使用鲁棒模型的拟合过程,而不是简单的投影。 但是,实际上,当使用递减的搜索窗口大小(即face_tracker_params::ssize中的设置)时,这通常是不必要的,因为总体异常值通常在投影形状中距离其对应点很远,并且很可能位于拟合过程的下一级搜索区域之外。 因此,减小搜索区域大小的速率充当增量离群值拒绝方案。
训练和可视化
与本章中详细介绍的其他类不同,训练face_tracker对象不涉及任何学习过程。 它在train_face_tracker.cpp中的实现方式很简单:
face_tracker tracker;
tracker.smodel = load_ft<shape_model>(argv[1]);
tracker.pmodel = load_ft<patch_models>(argv[2]);
tracker.detector = load_ft<face_detector>(argv[3]);
save_ft<face_tracker>(argv[4],tracker);
- 1
- 2
- 3
- 4
- 5
这里arg[1]至argv[4]分别包含指向shape_model,patch_model,face_detector和face_tracker对象的路径。 visualize_face_tracker.cpp中的面部跟踪器的可视化同样简单。 通过cv::VideoCapture类从摄像机或视频文件获取其输入图像流,该程序仅循环播放,直到流结束,或者直到用户按下Q键,在每一帧进来时跟踪它。 用户还可以通过随时按D键来重置跟踪器。
通用模型与个人模型
可以对训练和跟踪过程中的许多变量进行调整,以优化给定应用的表现。 但是,跟踪质量的主要决定因素之一是跟踪器必须建模的形状和外观变化范围。 作为一个适当的案例,请考虑一般案例与个人案例。 使用来自多个标识,表达式,光照条件和其他可变性来源的带标注数据训练通用模型。 相反,针对特定人的模型专门针对单个人进行训练。 因此,它需要考虑的可变性要小得多。 结果,特定于人的跟踪通常比其通用对应部分准确得多。
下图显示了对此的说明。 在这里,通用模型是使用 MUCT 数据集进行训练的。 特定于人的模型是从使用本章前面介绍的标注工具生成的数据中学习的。 结果清楚地表明,特定于人的模型提供了更好的跟踪功能,能够捕获复杂的表情和头部姿势的变化,而通用模型甚至对于某些简单的表情似乎也很挣扎:

应该注意的是,本章中描述的面部跟踪方法是一种准系统方法,用于突出显示大多数非刚性面部跟踪算法中使用的各种组件。 解决该方法某些缺点的多种方法超出了本书的范围,并且需要 OpenCV 功能尚不支持的专用数学工具。 可用的商业级面部跟踪包相对较少,这证明了在一般情况下此问题的难度。 但是,本章中描述的简单方法在受约束的环境中仍可以很好地工作。
总结
在本章中,我们构建了一个简单的面部跟踪器,仅使用适度的数学工具以及 OpenCV 用于基本图像处理和线性代数运算的实质功能,即可在受限设置中合理地工作。 可以通过在跟踪器的三个组件(形状模型,特征检测器和拟合算法)的每个组件中采用更复杂的技术来改进此简单的跟踪器。 本节中描述的跟踪器的模块化设计应允许修改这三个组件,而不会实质性破坏其他组件的功能。
参考
Procrustes Problems, Gower, John C. and Dijksterhuis, Garmt B, Oxford University Press, 2004.
七、使用 AAM 和 POSIT 的 3D 头部姿势估计
一个好的计算机视觉算法如果没有强大特征以及广泛的概括性和扎实的数学基础,就不可能完成。 所有这些功能都伴随着 Tim Cootes 主要用活动外观模型开发的工作。 本章将教您如何使用 OpenCV 创建自己的活动外观模型,以及如何使用它来搜索模型在给定框架中的最近位置。 此外,您还将学习如何使用 POSIT 算法以及如何在“摆姿势”的图像中拟合 3D 模型。 使用所有这些工具,您将能够实时跟踪视频中的 3D 模型。 这不是很好吗? 尽管示例着重于头部姿势,但实际上任何可变形模型都可以使用相同的方法。
阅读各节时,您会遇到以下主题:
- 活动外观模型概述
- 活动形状模型概述
- 模型实例化 - 玩转活动外观模型
- AAM 搜索和拟合
- POSIT
以下列表解释了本章将要遇到的术语:
- 活动外观模型(AAM):包含其形状和纹理的统计信息的对象模型。 这是一种捕获对象形状和纹理变化的有效方法。
- 活动形状模型(ASM):对象形状的统计模型。 这对于学习形状变化非常有用。
- 主成分分析(PCA):正交线性变换,将数据转换为新的坐标系,从而使任何数据投影的最大方差都位于第一个坐标上 (称为第一个主成分),第二个坐标上的第二大方差,依此类推。 此过程通常用于降维。 在减小原始问题的范围时,可以使用一种更快拟合的算法。
- Delaunay 三角剖分(DT):对于平面中的一组
P点,是三角剖分,因此P中的任何点都不在三角剖分中任何三角形的外接圆之内。 它倾向于避免骨感三角形。 纹理映射需要三角剖分。 - 仿射变换:可以以矩阵乘法和向量加法形式表示的任何变换。 这可以用于纹理映射。
- 比例正交投影迭代变换(POSIT):一种执行 3D 姿势估计的计算机视觉算法。
活动外观模型概述
简而言之,Active Appearance Models 是结合了纹理和形状的模型参数化,再加上有效的搜索算法,该算法可以准确指出模型在图片框中的位置和位置。 为此,我们将从“活动形状模型”部分开始,将看到它们与界标位置更紧密相关。 以下各节将更好地描述主成分分析和一些动手经验。 然后,我们将能够从 OpenCV 的 Delaunay 函数中获得一些帮助,并学习一些三角剖分。 从那时起,我们将逐步发展到在三角形纹理扭曲部分中应用分段仿射扭曲,在该部分中我们可以从对象的纹理中获取信息。
当我们有足够的背景知识来建立一个好的模型时,我们可以使用模型实例化部分中的技术。 然后,我们将能够通过 AAM 搜索和拟合来解决逆问题。 这些本身对于 2D 甚至 3D 图像匹配而言已经是非常有用的算法。 但是,当一个人能够使它工作时,为什么不将其桥接到 POSIT(比例正交投影迭代变换),这是另一种用于 3D 模型拟合的坚如磐石的算法? 进入 POSIT 部分将为我们提供足够的背景知识,以便在 OpenCV 中使用它,然后在下一部分中,我们将学习如何将头部模型与其耦合。 这样,我们可以使用 3D 模型来拟合已经匹配的 2D 框架。 而且,如果敏锐的读者想知道这将带给我们什么,这仅仅是将 AAM 和 Posit 逐帧组合起来,以通过检测变形模型获得实时 3D 跟踪的问题! 这些详细信息将在“从网络摄像头或视频文件进行跟踪”部分中介绍。
据说一张图片值一千字; 假设我们得到N张图片。 这样,我们之前提到的内容可以在以下屏幕截图中轻松找到:
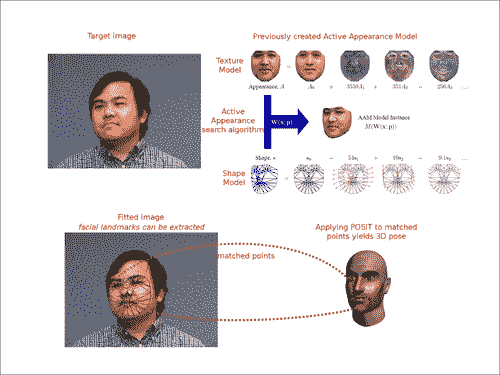
本章算法的概述:给定一个图像(前面的屏幕快照中的左上方图像),我们可以使用活动外观搜索算法来找到人头的 2D 姿势。 屏幕快照的右上图显示了在搜索算法中使用的先前训练的活动外观模型。 找到姿势后,可以应用 POSIT 将结果扩展到 3D 姿势。 如果将该程序应用于视频序列,则将通过检测获得 3D 跟踪。
活动形状模型
如前所述,AAM 需要一个形状模型,而此角色由活动形状模型(ASM)扮演。 在接下来的部分中,我们将创建一个 ASM,它是形状变化的统计模型。 形状模型是通过形状变化的组合生成的。 如 Timothy Cootes 的文章《有效形状模型–它们的训练和应用》中所述,需要一组带有标签的图像的训练。 为了构建脸部形状模型,需要在脸部关键位置标记几个点的图像来概述主要特征。 以下屏幕截图显示了这样的示例:

脸部有 76 个地标,取自 MUCT 数据集。 这些地标通常是用手工标记的,它们概述了一些人脸特征,例如嘴轮廓,鼻子,眼睛,眉毛和面部形状,因为它们更易于跟踪。
注意
普氏分析:一种统计形状分析的形式,用于分析一组形状的分布。 通过优化平移,旋转和均匀缩放对象来执行 Procrustes 叠加。
如果我们具有前面提到的图像集,则可以生成形状变化的统计模型。 由于对象上的标记点描述了该对象的形状,因此,如果需要,我们首先使用 Procrustes Analysis 将所有点集对齐到坐标系中,并通过x向量表示每种形状。 然后,我们对数据应用主成分分析(PCA)。 然后,我们可以使用以下公式近似任何示例:
x = x + ps bs
- 1
在前面的公式中,x是平均形状, Ps是一组正交变化模式,bs是一组形状参数。 好吧,为了更好地理解它,我们将在本节的其余部分中创建一个简单的应用,该应用将向我们展示如何处理 PCA 和形状模型。
为什么要完全使用 PCA? 因为 PCA 在减少模型参数数量方面将真正为我们提供帮助。 在本章的后面,我们还将看到在给定图像中进行搜索时有多大帮助。 应当为以下引用提供一个网页 URL:
PCA 可以为用户提供较低维度的图片,即从其(在某种意义上)信息最丰富的角度查看时该对象的“阴影”。 这是通过仅使用前几个主要成分来完成的,从而降低了转换数据的维数。
当我们看到如下屏幕截图时,这一点变得很清楚:

前面的屏幕截图显示了以(2, 3)为中心的多元高斯分布的 PCA。 所示的向量是协方差矩阵的特征向量,它们经过偏移,因此其尾部位于均值处。
这样,如果我们想用一个参数来表示模型,那么从特征向量指向屏幕截图右上角的方向是一个好主意。 此外,通过稍微改变参数,我们可以推断数据并获得与所需值相似的值。
感受 PCA
为了了解 PCA 如何帮助我们改善脸部模型,我们将从活动形状模型开始并测试一些参数。
由于人脸检测和跟踪已经研究了一段时间,因此可以在线使用多个面部数据库进行研究。 我们将使用 IMM 数据库中的几个样本。
首先,让我们了解一下 PCA 类在 OpenCV 中的工作方式。 我们可以从文档中得出结论,PCA 类用于计算向量集的特殊基础,该向量集由从向量输入集计算出的协方差矩阵的特征向量组成。 此类还可以使用project和backproject方法在新的坐标空间之间来回转换向量。 通过仅采用其前几个分量,就可以非常精确地近似此新坐标系。 这意味着我们可以用高得多的空间表示原始向量,而该向量要短得多,该向量由子空间中投影向量的坐标组成。
由于我们希望根据几个标量值进行参数化,因此我们将在类中使用的主要方法是backproject方法。 它采用投影向量的主成分坐标并重建原始向量。 如果保留所有分量,我们可以检索原始向量,但如果仅使用几个分量,则差异将很小。 这是使用 PCA 的原因之一。 由于我们希望原始向量周围有一些可变性,因此我们的参数化标量将能够外推原始数据。
此外,PCA 类可以将向量与基础定义的新坐标空间进行相互转换。 从数学上讲,这意味着我们可以将向量投影到一个子空间,该子空间由与协方差矩阵的主要特征值相对应的几个特征向量组成,正如从文档中可以看到的那样。
我们的方法是用地标标注人脸图像,从而为我们的点分布模型(PDM)设置训练集。 如果我们在二维中具有k对齐的界标,则我们的形状描述将变为:
X = {x1, y1, x2, y2, …, xk, yk}
- 1
重要的是要注意,我们需要在所有图像样本之间进行一致的标记。 因此,例如,如果嘴巴的左部分在第一个图像中是界标编号3,则在所有其他图像中都将是编号3。
这些地标序列现在将形成形状轮廓,并且可以将给定的训练形状定义为向量。 我们通常假定此散射在该空间中是高斯分布,并且我们使用 PCA 计算所有训练形状上的归一化特征向量和协方差矩阵的特征值。 使用顶部中心特征向量,我们创建尺寸为2k * m的矩阵,我们将其称为P。 这样,每个特征向量都描述了沿集合的主要变化模式。
现在,我们可以通过以下公式定义新形状:
X' = X' + Pb
- 1
在这里,X'是所有训练图像上的平均形状-我们只是对每个界标进行平均-b是每个主成分的缩放值向量。 这导致我们创建一个修改b值的新形状。 通常将b设置为在三个标准差内变化,以便生成的形状可以落入训练集中。
以下屏幕截图显示了三张不同图片的带点标注的嘴部界标:

从前面的屏幕快照中可以看出,形状由其界标序列描述。 可以使用 GIMP 或 ImageJ 之类的程序,也可以在 OpenCV 中构建一个简单的应用,以便对训练图像进行标注。 我们将假定用户已完成此过程,并将所有训练图像的点以x和y界标位置的顺序保存在文本文件中,这将在我们的 PCA 分析中使用 。 然后,我们将两个参数添加到该文件的第一行,即训练图像的数量和读取的列的数量。 因此,对于k2D 点,该数字将为2 * k。
在以下数据中,我们有此文件的实例,该文件是通过从 IMM 数据库中标注三张图像获得的,其中k等于 5:
3 10
265 311 303 321 337 310 302 298 265 311
255 315 305 337 346 316 305 309 255 315
262 316 303 342 332 315 298 299 262 316
- 1
- 2
- 3
- 4
现在我们已经为图像添加了标注,让我们将这些数据转换为形状模型。 首先,将该数据加载到矩阵中。 这将通过函数loadPCA实现。 以下代码段显示了loadPCA函数的用法:
PCA loadPCA(char* fileName, int& rows, int& cols,Mat& pcaset){ FILE* in = fopen(fileName,"r"); int a; fscanf(in,"%d%d",&rows,&cols); pcaset = Mat::eye(rows,cols,CV_64F); int i,j; for(i=0;i<rows;i++){ for(j=0;j<cols;j++){ fscanf(in,"%d",&a); pcaset.at<double>(i,j) = a; } } PCA pca(pcaset, // pass the data Mat(), // we do not have a pre-computed mean vector, // so let the PCA engine compute it CV_PCA_DATA_AS_ROW, // indicate that the vectors // are stored as matrix rows // (use CV_PCA_DATA_AS_COL if the vectors are // the matrix columns) pcaset.cols// specify, how many principal components to retain ); return pca; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
请注意,我们的矩阵是在pcaset = Mat::eye(rows,cols,CV_64F)行中创建的,并且为2 * k值分配了足够的空间。 在两个for循环将数据加载到矩阵中之后,如果我们希望只创建一次,则用数据(一个空矩阵)调用 PCA 构造器,该矩阵可以是我们预先计算的均值向量。 我们还指出,向量将存储为矩阵行,并且我们希望将给定的行数与组件数保持相同,尽管我们可以只使用少数几个。
现在我们已经用训练集填充了 PCA 对象,它具有根据给定参数对形状进行背投影所需的一切。 为此,我们调用PCA.backproject,将参数作为行向量传递,并将反投影的向量接收到第二个参数中。
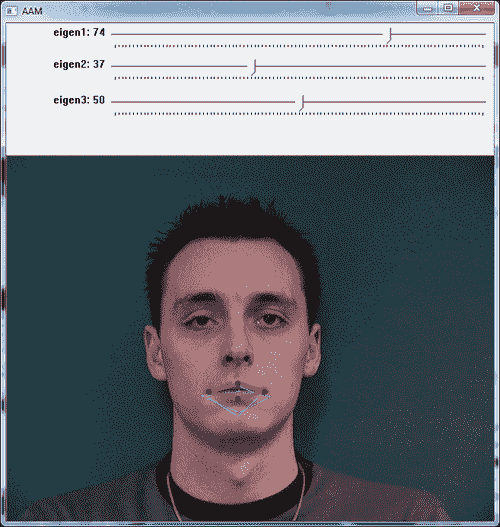
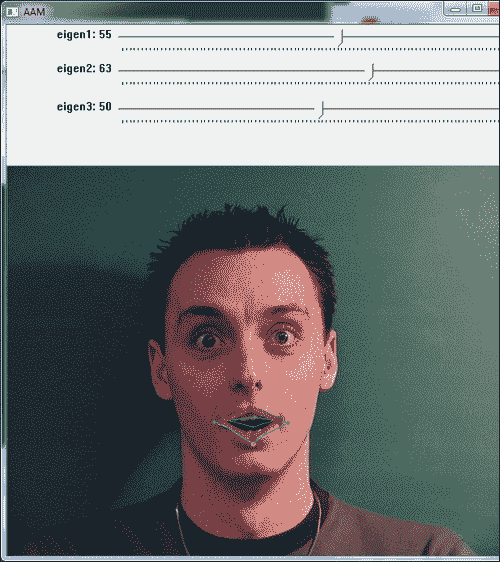
前两个截屏根据从滑块选择的所选参数显示了两种不同的形状配置。 黄色和绿色形状显示训练数据,而红色形状反映从所选参数生成的形状。
样本程序可用于试验活动形状模型,因为它允许用户为模型尝试不同的参数。 可以注意到,通过滑块仅改变前两个标量值(对应于第一和第二变化模式),我们可以获得的形状非常接近于受过训练的形状。 这种可变性在 AAM 中搜索模型时会有所帮助,因为它提供了插值形状。 在以下各节中,我们将讨论三角剖分,纹理化,AAM 和 AAM 搜索。
三角剖分
由于我们正在寻找的形状可能会变形,例如张开嘴,因此我们需要将纹理映射回平均形状,然后将 PCA 应用于此归一化纹理。 为此,我们将使用三角剖分。 这个概念非常简单:我们将创建包含标注点的三角形,然后从一个三角形映射到另一个三角形。 OpenCV 带有一个方便的函数cvCreateSubdivDelaunay2D,该函数创建一个空的 Delaunay 三角剖分。 您可以认为这是一个很好的三角剖分方法,可以避免出现三角形。
注意
在数学和计算几何学中,平面中点集P的 Delaunay 三角剖分是三角剖分DT(P),因此P位于DT(P)任何三角形的外接圆之内。 Delaunay 三角剖分将三角剖分中所有三角形的最小角度最大化。 他们倾向于避免瘦三角形。 三角剖分以 Boris Delaunay 的名字命名,因为他从 1934 年开始就此主题开展工作。
初始化 Delaunay 剖分后,将使用cvSubdivDelaunay2DInsert将点填充到该剖分中。 以下代码行将阐明直接使用三角剖分会是什么样子:
CvMemStorage* storage; CvSubdiv2D* subdiv; CvRect rect = { 0, 0, 640, 480 }; storage = cvCreateMemStorage(0); subdiv = cvCreateSubdivDelaunay2D(rect,storage); std::vector<CvPoint> points; //initialize points somehow ... //iterate through points inserting them in the subdivision for(int i=0;i<points.size();i++){ float x = points.at(i).x; float y = points.at(i).y; CvPoint2D32f floatingPoint = cvPoint2D32f(x, y); cvSubdivDelaunay2DInsert( subdiv, floatingPoint ); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
请注意,我们的点将位于一个矩形框架内,该矩形框架将作为参数传递给cvCreateSubdivDelaunay2D。 为了创建剖分,我们还需要创建和初始化内存存储结构。 这可以在前面的代码的前五行中看到。 然后,为了创建三角剖分,我们需要使用cvSubdivDelaunay2DInsert函数插入点。 这在前面的代码的循环的内部发生。 请注意,这些点应该已经初始化,因为它们通常是我们将用作输入的点。 以下屏幕截图显示了三角剖分的样子:
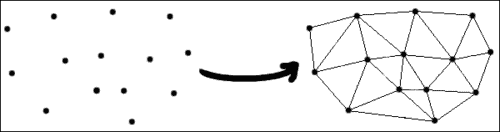
此屏幕快照是前面代码的一组点的输出,这些点使用 Delaunay 算法产生三角剖分。
尽管剖分创建是 OpenCV 的一个非常方便的功能,但是遍历所有三角形可能并不容易。 以下代码显示了如何遍历剖分的边缘:
void iterate(CvSubdiv2D* subdiv, CvNextEdgeType triangleDirection){ CvSeqReader reader; CvPoint buf[3]; int i, j, total = subdiv->edges->total; int elem_size = subdiv->edges->elem_size; cvStartReadSeq((CvSeq*)(subdiv->edges), &reader, 0); for(i = 0; i < total; i++){ CvQuadEdge2D* edge = (CvQuadEdge2D*)(reader.ptr); if(CV_IS_SET_ELEM(edge)){ CvSubdiv2DEdge t = (CvSubdiv2DEdge)edge; for(j=0;j<3;j++){ CvSubdiv2DPoint* pt = cvSubdiv2DEdgeOrg(t); if(!pt) break; buf[j] = cvPoint(cvRound(pt->pt.x), cvRound(pt->pt.y)); t = cvSubdiv2DGetEdge(t, triangleDirection); } } CV_NEXT_SEQ_ELEM(elem_size, reader); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
给定一个剖分,我们初始化其边缘读取器并调用cvStartReadSeq函数。 在 OpenCV 的文档中,我们具有以下引用的定义:
该函数初始化读取器状态。 之后,在向前读取的情况下,可以通过对宏
CV_READ_SEQ_ELEM(read_elem, reader)的后续调用来读取从第一个到最后一个的所有序列元素;对于以下情况,则可以使用CV_REV_READ_SEQ_ELEM(read_elem, reader)来读取: 反向阅读。 两个宏都将序列元素放入read_elem并将读取指针移至下一个元素。
获取以下元素的另一种方法是使用宏CV_NEXT_SEQ_ELEM( elem_size, reader ),如果序列元素较大,则首选此宏。 在这种情况下,我们使用CvQuadEdge2D* edge = (CvQuadEdge2D*)(reader.ptr)访问边缘,这仅仅是从读取器指针到CvQuadEdge2D指针的转换。 宏CV_IS_SET_ELEM仅检查指定的边是否被占用。 给定一条边,为了获得源点,我们需要调用cvSubdiv2DEdgeOrg函数。 为了绕三角形运行,我们反复调用cvSubdiv2DGetEdge并传递三角形方向,例如可以是CV_NEXT_AROUND_LEFT或CV_NEXT_AROUND_RIGHT。
三角形纹理变形
既然我们已经能够遍历剖分的三角形,我们就可以将一个三角形从原始带标注的图像扭曲到生成的变形图像中。 这对于将纹理从原始形状映射到变形的形状很有用。 以下代码将指导该过程:
void warpTextureFromTriangle(Point2f srcTri[3], Mat originalImage, Point2f dstTri[3], Mat warp_final){ Mat warp_mat(2, 3, CV_32FC1); Mat warp_dst, warp_mask; CvPoint trianglePoints[3]; trianglePoints[0] = dstTri[0]; trianglePoints[1] = dstTri[1]; trianglePoints[2] = dstTri[2]; warp_dst = Mat::zeros(originalImage.rows, originalImage.cols, originalImage.type()); warp_mask = Mat::zeros(originalImage.rows, originalImage.cols, originalImage.type()); /// Get the Affine Transform warp_mat = getAffineTransform(srcTri, dstTri); /// Apply the Affine Transform to the src image warpAffine(originalImage, warp_dst, warp_mat, warp_dst.size()); cvFillConvexPoly(new IplImage(warp_mask), trianglePoints, 3, CV_RGB(255,255,255), CV_AA, 0); warp_dst.copyTo(warp_final, warp_mask); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
前面的代码假定我们在srcTri数组中包装了三角形顶点,并在dstTri数组中包装了目标顶点。 2 x 3 warp_mat矩阵用于获得从源三角形到目标三角形的仿射变换。 可以从 OpenCV 的cvGetAffineTransform文档中引用更多信息:
函数cvGetAffineTransform计算仿射变换的矩阵,使得:
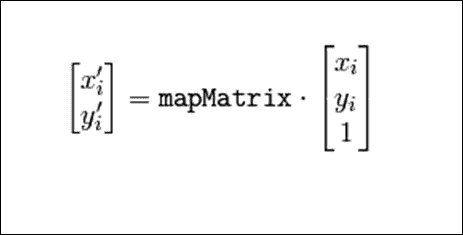
在前面的公式中,目标(i)等于(x'[i], y'[i]),源(i)等于(x[i], y[i]),并且i等于 0、1、2。
提取仿射矩阵后,我们可以将仿射变换应用于源图像。 这是通过warpAffine函数完成的。 由于我们不想在整个图像中都这样做(我们希望将注意力集中在三角形上),因此可以将遮罩用于此任务。 这样,最后一行仅使用我们通过cvFillConvexPoly调用创建的遮罩复制了原始图像中的三角形。
以下屏幕截图显示了将此过程应用于带标注的图像中的每个三角形的结果。 请注意,三角形被映射回到面向观察者的对齐框架。 此过程用于创建 AAM 的统计纹理。

前面的屏幕截图显示了将左侧图像中所有映射的三角形扭曲为平均参考帧的结果。
模型实例化 – 使用活动外观模型
AAM 的一个有趣的方面是它们能够轻松地插值我们训练图像的模型的能力。 通过调整几个形状或模型参数,我们可以适应它们惊人的表示能力。 当我们改变形状参数时,经纱的目的地会根据训练后的形状数据而变化。 另一方面,修改外观参数时,将修改基本形状上的纹理。 我们的翘曲变换将把从基本形状到修改后的目标形状的每个三角形都包含在内,因此我们可以在张口的顶部合成一张张口,如以下屏幕截图所示:

前面的屏幕截图显示了通过在另一个图像上进行活动外观模型实例化而获得的闭合的嘴巴。 它显示了如何将微笑的嘴巴和钦佩的脸相结合,从而推断出训练过的图像。
前面的屏幕快照是通过仅更改形状的三个参数和纹理的三个参数而获得的,这是 AAM 的目标。 已经开发了一个示例应用,可以在这个页面上找到,供读者试用 AAM。 实例化新模型只是滑动方程参数的问题,如在“获得 PCA 的感觉”一节中所定义。 您应该注意,AAM 搜索和拟合依靠这种灵活性来找到与训练模型不同位置的给定捕获模型的最佳匹配。 我们将在下一部分中看到这一点。
AAM 搜索和拟合
通过我们全新的形状和纹理组合模型,我们找到了一种很好的方式来描述面部不仅可以改变形状,而且可以改变外观。 现在,我们要查找哪一组p形状和λ外观参数将使我们的模型尽可能接近给定的输入图像I(x)。 我们自然可以在I(x)的坐标系中计算实例化模型与给定输入图像之间的误差,或者将这些点映射回基础外观并计算出那里的差异。 我们将使用后一种方法。 这样,我们要最小化以下函数:
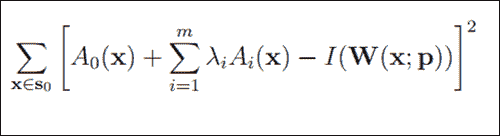
在前面的等式中,S0表示像素集x等于 AAM 基本网格中的(x, y)T。0(x)是我们的基本网格纹理,Ai(x)是 PCA 的外观图像,W(x; p)是将像素从输入图像返回到基本网格框架的扭曲。
通过多年的研究,已经提出了几种方法来使这种最小化。 第一个想法是使用加法,其中∆pi和∆λi被计算为误差图像的线性函数,然后将形状参数p和外观λ更新为pi ← pi + ∆pi和λi ← λi + Δλi,在第i个迭代中。 尽管有时会发生收敛,但是增量并不总是取决于当前参数,这可能会导致差异。 基于梯度下降算法进行研究的另一种方法非常慢,因此寻求寻找收敛的另一种方法。 代替更新参数,可以更新整个变形。 这样,伊恩·马修斯(Ian Mathews)和西蒙·贝克(Simon Baker)在著名的论文“活动外观模型回顾”中提出了一种合成方法。 可以在本文中找到更多详细信息,但是它对拟合的重要贡献是将最密集的计算带到了预计算步骤,如以下屏幕截图所示:

请注意,更新是根据合成步骤进行的,如步骤(9)所示(请参见上一个屏幕截图)。 本文的公式(40)和(41)可在以下屏幕截图中看到:
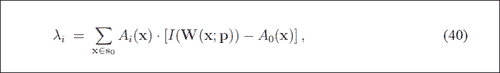
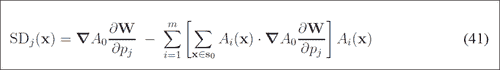
尽管刚刚提到的算法从最后一个位置开始的收敛效果非常好,但是当旋转,平移或缩放比例有很大差异时,情况可能并非如此。 通过全局 2D 相似度变换的参数化,我们可以为融合带来更多信息。 这是论文中的公式42,如下所示:
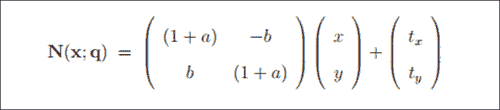
在前面的等式中,四个参数q = (a, b, tx, ty)^T具有以下解释。 第一对(a, b)与标度k和旋转角度有关:a = k cosθ - 1,b = k sinθ。 第二对(tx, ty)是x和y的平移,如《Active Appearance Models Revisited》文件中所建议。
通过更多的数学转换,最终可以使用前面的算法通过全局 2D 转换找到最佳图像。
由于翘曲合成算法具有多个性能优势,因此我们将使用 AAM Revisited 论文中描述的逆合成投影算法。 请记住,在这种方法中,可以预先计算出或预测拟合期间外观变化的影响,从而改善 AAM 拟合性能。
以下屏幕截图显示了使用逆成分投影 AAM 拟合算法对 MUCT 数据集中的不同图像进行收敛的情况。

上面的屏幕截图显示了使用逆成分投影 AAM 拟合算法成功收敛(在 AAM 训练集之外的面上)。
POSIT
找到地标点的 2D 位置后,我们可以使用 POSIT 导出模型的 3D 姿态。 将 3D 对象的姿态P定义为3 x 3旋转矩阵R和 3D 平移向量T,因此P等于[R | T]。
注意
本节的大部分内容基于 Javier Barandiaran 的《OpenCV POSIT》教程。
顾名思义,POSIT 使用正交和缩放姿势(POS)算法,因此它是带迭代的 POS 的首字母缩写。 其工作的假设是,我们可以在图像中检测并匹配对象的四个或更多非共面特征点,并且知道它们在对象上的相对几何形状。
该算法的主要思想是,我们假设所有模型点都在同一平面上,因此可以找到一个很好的对象姿态近似值,因为如果与从相机到脸的距离相比,它们的深度彼此之间并没有太大差异。 获得初始姿势后,通过求解线性系统找到对象的旋转矩阵和平移向量。 然后,迭代地使用近似姿势来更好地计算特征点的缩放正投影,然后将 POS 应用于这些投影,而不是原始投影。 有关更多信息,您可以参考 DeMenton 的论文,《25 行代码中的基于模型的对象姿势》。
深入 POSIT
为了使 POSIT 正常工作,您至少需要四个非共面 3D 模型点及其在 2D 图像中的各自匹配项。 此外,由于 POSIT 是迭代算法,因此终止条件通常是迭代次数或距离参数。 然后,我们调用函数cvPOSIT,它产生旋转矩阵和平移向量。
例如,我们将遵循 Javier Barandiaran 的教程,该教程使用 POSIT 获取立方体的姿势。 用四个点创建模型。 它使用以下代码初始化:
float cubeSize = 10.0;
std::vector<CvPoint3D32f> modelPoints;
modelPoints.push_back(cvPoint3D32f(0.0f, 0.0f, 0.0f));
modelPoints.push_back(cvPoint3D32f(0.0f, 0.0f, cubeSize));
modelPoints.push_back(cvPoint3D32f(cubeSize, 0.0f, 0.0f));
modelPoints.push_back(cvPoint3D32f(0.0f, cubeSize, 0.0f));
CvPOSITObject *positObject = cvCreatePOSITObject( &modelPoints[0], static_cast<int>(modelPoints.size()) );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
请注意,模型本身是使用cvCreatePOSITObject方法创建的,该方法返回CvPOSITObject方法,该方法将在cvPOSIT函数中使用。 请注意,将参照第一个模型点来计算姿势,因此最好将其放在原点。
然后,我们需要将 2D 图像点放置在另一个向量中。 请记住,必须按照插入模型点的相同顺序将它们放入数组中。 这样,第i个 2D 图像点与第i个 3D 模型点匹配。 这里要注意的是 2D 图像点的原点位于图像的中心,这可能需要您对其进行平移。 您可以插入以下 2D 图像点(当然,它们会根据用户的匹配而有所不同):
std::vector<CvPoint2D32f> srcImagePoints;
srcImagePoints.push_back( cvPoint2D32f( -48, -224 ) );
srcImagePoints.push_back( cvPoint2D32f( -287, -174 ) );
srcImagePoints.push_back( cvPoint2D32f( 132, -153 ) );
srcImagePoints.push_back( cvPoint2D32f( -52, 149 ) );
- 1
- 2
- 3
- 4
- 5
现在,您只需要为矩阵分配内存并创建终止条件,然后调用cvPOSIT即可,如以下代码片段所示:
//Estimate the pose
CvMatr32f rotation_matrix = new float[9];
CvVect32f translation_vector = new float[3];
CvTermCriteria criteria = cvTermCriteria(CV_TERMCRIT_EPS | CV_TERMCRIT_ITER, 100, 1.0e-4f);
cvPOSIT( positObject, &srcImagePoints[0], FOCAL_LENGTH, criteria, rotation_matrix, translation_vector );
- 1
- 2
- 3
- 4
- 5
迭代之后,cvPOSIT将结果存储在rotation_matrix和translation_vector中。 以下屏幕截图显示了插入的带有白色圆圈的srcImagePoints,以及显示旋转和平移结果的坐标轴:

参考前面的屏幕截图,让我们看一下运行 POSIT 算法的输入点和结果:
-
白色圆圈显示输入点,而坐标轴显示结果模型姿势。
-
确保使用通过校准过程获得的相机焦距。 您可能需要检查第 2 章“iPhone 或 iPad 上的基于标记的增强现实”的“相机校准”部分中可用的校准程序之一。 当前 POSIT 的实现仅允许正方形像素,因此在 x 和 y 轴上没有焦距的空间。
-
期望旋转矩阵采用以下格式:
[红色[0]红色[1]红色[2]]
[腐烂[3]腐烂[4]腐烂[5]]
[腐烂[6]腐烂[7]腐烂[8]]
-
平移向量将采用以下格式:
[trans [0]]
[trans [1]]
[trans [2]]
POSIT 和头部模型
为了将 POSIT 用作头部姿势的工具,您将需要使用 3D 头部模型。 科英布拉大学系统与机器人研究所提供了一种,可以在这个页面中找到。 请注意,可以从以下位置获得模型:
float Model3D[58][3]= {{-7.308957,0.913869,0.000000}, ...
- 1
该模型可以在以下屏幕截图中看到:
上面的屏幕截图显示了可用于 POSIT 的 58 点 3D 头部模型。
为了使 POSIT 正常工作,必须相应地匹配与 3D 头部模型相对应的点。 请注意,要使 POSIT 工作,至少需要四个非共面 3D 点及其对应的 2D 投影,因此必须将它们作为参数传递,几乎与“POSIT 简介”部分中所述。 注意,该算法在匹配点数方面是线性的。 以下屏幕截图显示了应如何进行匹配:
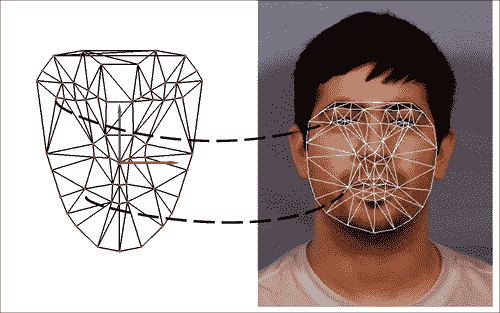
上面的屏幕截图显示了 3D 头部模型和 AAM 网格的正确匹配点。
从网络摄像头或视频文件进行跟踪
现在,所有工具都已经组装好,可以进行 6 个自由度的头部跟踪,我们可以将其应用于摄像机流或视频文件。 OpenCV 提供了VideoCapture类,可以按以下方式使用(请参阅第 1 章, “卡通化器和 Android 皮肤检测器”中的“访问网络摄像头”部分。 , 更多细节):
#include "cv.h" #include "highgui.h" using namespace cv; int main(int, char**) { VideoCapture cap(0);// opens the default camera, could use a // video file path instead if(!cap.isOpened()) // check if we succeeded return -1; AAM aam = loadPreviouslyTrainedAAM(); HeadModel headModel = load3DHeadModel(); Mapping mapping = mapAAMLandmarksToHeadModel(); Pose2D pose = detectFacePosition(); while(1) { Mat frame; cap >> frame; // get a new frame from camera Pose2D new2DPose = performAAMSearch(pose, aam); Pose3D new3DPose = applyPOSIT(new2DPose, headModel, mapping); if(waitKey(30) >= 0) break; } // the camera will be deinitialized automatically in VideoCapture // destructor return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
该算法的工作原理如下。 通过VideoCapture cap(0)初始化视频捕获,以便使用默认的网络摄像头。 现在我们已经进行了视频捕获,我们还需要加载经过训练的活动外观模型,该模型将在伪代码loadPreviouslyTrainedAAM映射中发生。 我们还将加载用于 POSIT 的 3D 头部模型,并将地标点映射到我们的映射变量中的 3D 头部点。
加载完所需的所有内容后,我们需要从已知的姿态(即已知的 3D 位置,已知的旋转度和已知的 AAM 参数集)初始化算法。 这可以通过 OpenCV 高度记录的 Haar 特征分类器人脸检测器自动完成(更多信息,请参见第 6 章,“非刚性人脸跟踪”的“人脸检测”部分), 或在 OpenCV 的级联分类器文档中),或者我们可以从先前标注的帧中手动初始化姿势。 也可以使用暴力方法,即为每个矩形运行 AAM 拟合,因为这种方法仅在第一帧期间会非常慢。 请注意,通过初始化,我们的意思是通过其参数找到 AAM 的 2D 界标。
加载完所有内容后,我们可以循环访问由while循环界定的主循环。 在此循环中,我们首先查询下一个抓取的帧,然后运行一个活动外观模型拟合,以便可以在下一帧上找到界标。 由于当前位置在此步骤中非常重要,因此我们将其作为参数传递给伪代码函数performAAMSearch(pose,aam)。 如果找到当前姿势(通过错误图像收敛发出信号),我们将获得下一个界标位置,以便将其提供给 POSIT。 这发生在下面的行applyPOSIT(new2DPose, headModel, mapping)中,新的 2D 姿态作为参数传递,我们先前加载的headModel和映射也是如此。 之后,我们可以在获得的姿势中渲染任何 3D 模型,例如坐标轴或增强现实模型。 当我们具有地标时,可以通过模型参数化来获得更有趣的效果,例如张开嘴或更改眉毛位置。
由于此过程依赖于先前的姿势进行下一次估计,因此我们可能会积累误差并偏离头部位置。 一种解决方法是,每次发生该过程时都要重新初始化,检查给定的错误图像阈值。 另一个要注意的因素是在跟踪时使用过滤器,因为可能会发生抖动。 对于每个平移和旋转坐标的简单均值过滤器可以给出合理的结果。
总结
在本章中,我们讨论了如何将活动外观模型与 POSIT 算法结合起来以获得 3D 头部姿势。 给出了有关如何创建,训练和操作 AAM 的概述,读者可以将此背景用于任何其他领域,例如医学,成像或工业。 除了处理 AAM 外,我们还熟悉 Delaunay 剖分,并学习了如何使用这种有趣的结构作为三角网格。 我们还展示了如何使用 OpenCV 函数在三角形中执行纹理映射。 在 AAM 拟合中提出了另一个有趣的话题。 尽管仅描述了逆成分投影算法,但仅通过使用其输出,我们就可以轻松获得多年研究的结果。
经过足够多的 AAM 理论和实践,我们深入研究了 POSIT,以便将 2D 测量与 3D 测量耦合起来,说明如何使用模型点之间的匹配来拟合 3D 模型。 在本章的结尾,我们展示了如何通过检测来使用在线面部跟踪器中的所有工具,从而产生 6 个自由度的头部姿势(旋转 3 度)和 3 个平移姿势。 可以从这个页面下载本章的完整代码。
参考
Active Appearance Models, T.F. Cootes, G. J. Edwards, and C. J. Taylor, ECCV, 2:484–498, 1998Active Shape Models – Their Training and Application, T.F. Cootes, C.J. Taylor, D.H. Cooper, and J. Graham, Computer Vision and Image Understanding, (61): 38–59, 1995The MUCT Landmarked Face Database, S. Milborrow, J. Morkel, and F. Nicolls, Pattern Recognition Association of South Africa, 2010The IMM Face Database – An Annotated Dataset of 240 Face Images, Michael M. Nordstrom, Mads Larsen, Janusz Sierakowski, and Mikkel B. Stegmann, Informatics and Mathematical Modeling, Technical University of Denmark, 2004Sur la sphère vide, B. Delaunay, Izvestia Akademii Nauk SSSR, Otdelenie Matematicheskikh i Estestvennykh Nauk, 7:793–800, 1934Active Appearance Models for Facial Expression Recognition and Monocular Head Pose Estimation Master Thesis, P. Martins, 2008Active Appearance Models Revisited, International Journal of Computer Vision, Vol. 60, No. 2, pp. 135 - 164, I. Mathews and S. Baker, November, 2004POSIT Tutorial, Javier BarandiaranModel-Based Object Pose in 25 Lines of Code, International Journal of Computer Vision, 15, pp. 123-141, Dementhon and L.S Davis, 1995
八、使用 EigenFace 或 Fisherfaces 的人脸识别
本章将介绍人脸检测和人脸识别的概念,并提供一个项目来检测面部并在再次看到它们时对其进行识别。 人脸识别既是一个热门话题,也是一个困难的话题,许多研究人员致力于人脸识别领域。 因此,本章将介绍人脸识别的简单方法,如果读者想探索更复杂的方法,则可以为他们提供一个良好的开端。
在本章中,我们涵盖以下内容:
- 人脸检测
- 人脸预处理
- 从收集的人脸中训练机器学习算法
- 人脸识别
- 画龙点睛
人脸识别和人脸检测简介
人脸识别是将标签粘贴到已知人脸的过程。 就像人类学会通过看他们的脸来认出家人,朋友和名人一样,计算机也有很多技术可以学会认出一张已知的脸。 这些通常包括四个主要步骤:
-
人脸检测:这是在图像中定位人脸区域的过程(以下屏幕快照中心附近的大矩形)。 此步骤并不关心人是谁,只关心它是人脸。
-
脸部预处理:这是调整脸部图像以使其看起来更清晰和与其他脸部相似的过程(以下屏幕快照顶部中心的小灰度脸部)。
-
收集和学习面部:保存许多预处理过的面部(对于每个应该识别的人),然后学习如何识别它们的过程。
-
人脸识别: 该过程将检查哪些被收集人员与相机中的脸部最相似(以下屏幕截图右上角的小矩形)。
注意
请注意,“脸部识别”一词通常被公众用来查找脸部位置(即,如步骤 1 中所述的脸部检测),但是本书将使用脸部识别的正式定义,参考步骤 4,和脸部检测的正式定义,请参阅步骤 1。
以下屏幕快照显示了最终的 WebcamFaceRec 项目,其中包括位于右上角的一个小矩形,突出显示了所识别的人。 还要注意位于预处理过的脸(矩形的顶部中心的小脸)旁边的置信度条,在这种情况下,这大约表明已识别出正确的人的置信度为 70%。

当前的人脸检测技术在现实环境中非常可靠,而当在现实环境中使用时,当前的人脸识别技术则可靠性低得多。 例如,很容易找到显示人脸识别准确率超过 95% 的研究论文,但是当您自己测试这些算法时,您可能经常会发现准确率低于 50%。 这源于以下事实:当前的人脸识别技术对图像中的确切条件非常敏感,例如照明的类型,照明和阴影的方向,面部的确切方向,面部表情以及当前的情感。 人。 如果在训练(收集图像)和测试(从摄像机图像)时它们都保持恒定,则人脸识别应该可以正常工作,但是如果该人站在房间左侧的灯光下, 训练,然后在用相机进行测试时站在右侧,这可能会产生非常差的结果。 因此,用于训练的数据集非常重要。
脸部预处理(步骤 2)旨在减少这些问题,例如通过确保脸部始终看起来具有相似的亮度和对比度,并可能确保脸部特征始终处于相同位置(例如对齐眼睛) 和/或鼻子到某些位置)。 一个好的人脸预处理阶段将有助于提高整个人脸识别系统的可靠性,因此本章将重点介绍人脸预处理方法。
尽管在媒体安全方面对人脸识别提出了很高的要求,但仅当前的人脸识别方法不可能对任何真正的安全系统都具有足够的可靠性,但是它们可用于不需要高可靠性的目的,例如播放个性化的音乐,适合不同人进入房间或看到您时会说出您名字的机器人。 人脸识别也有各种实用的扩展,例如性别识别,年龄识别和情感识别。
步骤 1:人脸检测
直到 2000 年,人们使用了许多不同的技术来查找人脸,但是它们要么都很慢,要么很不可靠,要么两者都很慢。 一个重大的变化发生在 2001 年,Viola 和 Jones 发明了基于 Haar 的级联分类器进行对象检测;而 2002 年,Lienhart 和 Maydt 对其进行了改进。 结果是既快速(可以在具有 VGA 网络摄像头的典型台式机上实时检测人脸)又可靠(可以正确检测到大约 95% 的正面)的物体检测器。 该对象检测器彻底改变了人脸识别领域(以及机器人技术和计算机视觉领域),因为它最终实现了实时人脸检测和人脸识别,尤其是 Lienhart 使用 OpenCV 自己编写了免费的对象检测器! 它不仅适用于正面,而且适用于侧面(称为侧面),眼睛,嘴巴,鼻子,公司徽标和许多其他对象。
该对象检测器在 OpenCV v2.0 中进行了扩展,还基于 Ahonen,Hadid 和 Pietikäinen 在 2006 年的工作,还使用 LBP 功能进行检测,因为基于 LBP 的检测器可能比基于 Haar 的检测器快几倍,并且没有许多 Haar 探测器都有的许可问题。
基于 Haar 的脸部检测器的基本思想是,如果您看大多数正面,则眼睛区域应比额头和脸颊暗,而嘴部区域应比脸颊暗,依此类推。 它通常执行大约 20 个这样的比较阶段,以决定是否是一张脸,但是必须在图像中的每个可能位置以及脸的每个可能大小上执行此操作,因此实际上它经常要检查每个图片数千次。 基于 LBP 的人脸检测器的基本思想类似于基于 Haar 的人脸检测器,但它使用像素强度比较的直方图,例如边缘,角点和平坦区域。
基于 Haar 和 LBP 的人脸检测器都可以自动训练以从大量图像中查找人脸,并将信息存储为 XML 文件,以供以后使用,而不必由人来决定哪个比较最能定义人脸。 这些级联分类器检测器通常使用至少 1,000 个唯一的面部图像和 10,000 个非面部图像(例如,树木,汽车和文本的照片)进行训练,并且即使在多核台式机上,训练过程也可能花费很长时间。 (LBP 通常需要几个小时,而 Haar 则需要一个星期!)。 幸运的是,OpenCV 随附了一些经过训练的 Haar 和 LBP 检测器供您使用! 实际上,只需将不同的层叠分类器 XML 文件加载到对象检测器,然后根据选择的 XML 文件在 Haar 或 LBP 检测器之间进行选择,就可以检测正面,侧面(侧面),眼睛或鼻子。
使用 OpenCV 实现人脸检测
如前所述,OpenCV v2.4 附带了各种预训练的 XML 检测器,您可以将它们用于不同的目的。 下表列出了一些最受欢迎的 XML 文件:
| 级联分类器的类型 | XML 文件名 |
|---|---|
| 人脸检测器(默认) | haarcascade_frontalface_default.xml |
| 人脸检测器 | haarcascade_frontalface_alt2.xml |
| 人脸检测器(快速 LBP) | lbpcascade_frontalface.xml |
| 人脸检测器(侧面) | haarcascade_profileface.xml |
| 眼睛检测器(左右分离) | haarcascade_lefteye_2splits.xml |
| 嘴部检测器 | haarcascade_mcs_mouth.xml |
| 鼻子检测器 | haarcascade_mcs_nose.xml |
| 全人检测器 | haarcascade_fullbody.xml |
基于 Haar 的检测器存储在文件夹data\haarcascades中,基于 LBP 的检测器存储在 OpenCV 根文件夹的文件夹data\lbpcascades中,例如C:\opencv\data\lbpcascades\。
对于我们的人脸识别项目,我们要检测正面人脸,所以让我们使用 LBP 人脸检测器,因为它是最快的并且没有专利许可问题。 请注意,OpenCV v2.x 附带的这种经过预训练的 LBP 人脸检测器并未像经过预训练的 Haar 人脸检测器那样进行调整,因此,如果您想要更可靠的人脸检测,则可能需要训练自己的 LBP 人脸检测器或使用 Haar 面部探测器。
加载用于物体或人脸检测的 Haar 或 LBP 检测器
要执行对象或人脸检测,首先必须使用 OpenCV 的CascadeClassifier类加载经过预先训练的 XML 文件,如下所示:
CascadeClassifier faceDetector;
faceDetector.load(faceCascadeFilename);
- 1
- 2
仅提供不同的文件名即可加载 Haar 或 LBP 检测器。 使用此错误时,一个非常常见的错误是提供了错误的文件夹或文件名,但根据您的构建环境,load()方法将返回false或生成 C++ 异常(并以断言错误退出程序)。 因此,最好用try/catch块围住load()方法,如果出现问题,最好向用户显示错误消息。 许多初学者会跳过检查错误的步骤,但是在某些内容未正确加载时向用户显示帮助消息至关重要,否则,您可能会花很长时间调试代码的其他部分,最后才意识到某些内容未加载。 一条简单的错误消息可以显示如下:
CascadeClassifier faceDetector;
try {
faceDetector.load(faceCascadeFilename);
} catch (cv::Exception e) {}
if ( faceDetector.empty() ) {
cerr << "ERROR: Couldn't load Face Detector (";
cerr << faceCascadeFilename << ")!" << endl;
exit(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
访问网络摄像头
要从计算机的网络摄像机甚至从视频文件中抓取帧,您只需使用摄像机编号或视频文件名调用VideoCapture::open()函数,然后使用 C++ 流运算符抓取帧,如第 1 章,“卡通化器和适用于 Android 的换肤器”中的“网络摄像头”部分中所述。
使用 Haar 或 LBP 分类器检测物体
现在,我们已经加载了分类器(初始化期间仅一次),我们可以使用它来检测每个新相机帧中的人脸。 但是首先,我们应该执行以下步骤,对照相机图像进行一些初始处理,以仅用于人脸检测:
- 灰度颜色转换:人脸检测仅适用于灰度图像。 因此,我们应该将彩色相机的框架转换为灰度。
- 缩小相机图像:人脸检测的速度取决于输入图像的大小(对于大图像来说非常慢,而对于小图像来说很快),但是即使在低分辨率下,检测仍然相当可靠 。 因此,我们应将相机图像缩小到更合理的尺寸(或在检测器中为
minFeatureSize使用较大的值,如稍后所述)。 - 直方图均衡:在弱光条件下人脸检测不那么可靠。 因此,我们应该执行直方图均衡化以提高对比度和亮度。
灰度颜色转换
我们可以使用cvtColor()函数将 RGB 彩色图像轻松转换为灰度。 但是,只有在知道有彩色图像(即不是灰度相机)的情况下,才应该这样做,并且必须指定输入图像的格式(通常是台式机上的 3 通道 BGR 或台式机上的 4 通道 BGRA 移动)。 因此,我们应该允许三种不同的输入颜色格式,如以下代码所示:
Mat gray;
if (img.channels() == 3) {
cvtColor(img, gray, CV_BGR2GRAY);
}
else if (img.channels() == 4) {
cvtColor(img, gray, CV_BGRA2GRAY);
}
else {
// Access the grayscale input image directly.
gray = img;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
缩小相机图像
我们可以使用resize()函数将图像缩小到一定的尺寸或比例因子。 人脸检测通常适用于任何大于240 x 240像素的图像(除非您需要检测距离相机较远的人脸),因为它会查找比minFeatureSize大的人脸(通常为20 x 20像素)。 因此,让我们将相机图像缩小到 320 像素宽; 输入是 VGA 网络摄像头还是 5 兆像素高清摄像头都没有关系。 记住并放大检测结果也很重要,因为如果您检测到缩小图像中的脸部,那么结果也会缩小。 请注意,您可以在检测器中使用较大的minFeatureSize值,而不是缩小输入图像。 我们还必须确保图像不会变胖或变薄。 例如,缩小到240 x 240的240 x 240宽屏图像会使人看起来很瘦。 因此,我们必须保持输出的长宽比(宽高比)与输入相同。 让我们计算缩小图像宽度多少,然后对高度也应用相同的比例因子,如下所示:
const int DETECTION_WIDTH = 320;
// Possibly shrink the image, to run much faster.
Mat smallImg;
float scale = img.cols / (float) DETECTION_WIDTH;
if (img.cols > DETECTION_WIDTH) {
// Shrink the image while keeping the same aspect ratio.
int scaledHeight = cvRound(img.rows / scale);
resize(img, smallImg, Size(DETECTION_WIDTH, scaledHeight));
}
else {
// Access the input directly since it is already small.
smallImg = img;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
直方图均衡
我们可以使用equalizeHist()函数轻松进行直方图均衡化,以提高图像的对比度和亮度(如《学习 OpenCV:使用 OpenCV 库的计算机视觉》中所述)。 有时这会使图像看起来很奇怪,但通常它应该提高亮度和对比度,并有助于人脸检测。 equalizeHist()函数的用法如下:
// Standardize the brightness & contrast, such as
// to improve dark images.
Mat equalizedImg;
equalizeHist(inputImg, equalizedImg);
- 1
- 2
- 3
- 4
- 5
检测脸部
现在,我们已经将图像转换为灰度,缩小图像并均衡了直方图,我们准备使用CascadeClassifier::detectMultiScale()特征检测面部! 我们将许多参数传递给此函数:
minFeatureSize:此参数确定我们关注的最小脸部尺寸,通常为20 x 20或20 x 20像素,但这取决于您的使用情况和图像尺寸。 如果要在网络摄像头或智能手机上执行人脸检测,而面部总是非常靠近相机,则可以将其放大到20 x 20以更快地进行检测,或者要检测较远的面部,例如和朋友一起去海滩,然后将其保留为20 x 20。searchScaleFactor:该参数确定要查找多少个不同大小的面孔; 通常,1.1不能很好地检测到脸部,或者1.2可以更快地检测到脸部。minNeighbors:此参数确定检测器应如何确定其已检测到人脸,通常为3值,但是即使您希望检测到更多人脸,也可以将其设置得更高,即使未检测到很多人脸 。flags:此参数允许您指定是查找所有面孔(默认)还是仅查找最大的面孔(CASCADE_FIND_BIGGEST_OBJECT)。 如果只寻找最大的脸,它应该运行得更快。 您可以添加其他几个参数来使检测速度提高大约 1% 或 2%,例如CASCADE_DO_ROUGH_SEARCH或CASCADE_SCALE_IMAGE。
detectMultiScale()函数的输出将是cv::Rect类型对象的std::vector。 例如,如果检测到两个脸部,则它将在输出中存储两个矩形的数组。 detectMultiScale()函数的用法如下:
int flags = CASCADE_SCALE_IMAGE; // Search for many faces.
Size minFeatureSize(20, 20); // Smallest face size.
float searchScaleFactor = 1.1f; // How many sizes to search.
int minNeighbors = 4; // Reliability vs many faces.
// Detect objects in the small grayscale image.
std::vector<Rect> faces;
faceDetector.detectMultiScale(img, faces, searchScaleFactor,
minNeighbors, flags, minFeatureSize);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通过查看存储在矩形向量中的元素数量(即使用objects.size()函数),我们可以查看是否检测到任何面部。
如前所述,如果将缩小的图像提供给人脸检测器,结果也会缩小,因此如果我们想知道原始图像的面部区域,则需要将其放大。 我们还需要确保图像边框上的脸完全位于图像内,因为如果发生这种情况,OpenCV 现在将引发异常,如以下代码所示:
// Enlarge the results if the image was temporarily shrunk. if (img.cols > scaledWidth) { for (int i = 0; i < (int)objects.size(); i++ ) { objects[i].x = cvRound(objects[i].x * scale); objects[i].y = cvRound(objects[i].y * scale); objects[i].width = cvRound(objects[i].width * scale); objects[i].height = cvRound(objects[i].height * scale); } } // If the object is on a border, keep it in the image. for (int i = 0; i < (int)objects.size(); i++ ) { if (objects[i].x < 0) objects[i].x = 0; if (objects[i].y < 0) objects[i].y = 0; if (objects[i].x + objects[i].width > img.cols) objects[i].x = img.cols - objects[i].width; if (objects[i].y + objects[i].height > img.rows) objects[i].y = img.rows - objects[i].height; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
请注意,前面的代码将查找图像中的所有面孔,但是如果您只关心一个面孔,则可以如下更改flag变量:
int flags = CASCADE_FIND_BIGGEST_OBJECT |
CASCADE_DO_ROUGH_SEARCH;
- 1
- 2
WebcamFaceRec 项目包括 OpenCV 的 Haar 或 LBP 检测器周围的包装器,以便更轻松地在图像中查找人脸或眼睛。 例如:
Rect faceRect; // Stores the result of the detection, or -1.
int scaledWidth = 320; // Shrink the image before detection.
detectLargestObject(cameraImg, faceDetector, faceRect,
scaledWidth);
if (faceRect.width > 0)
cout << "We detected a face!" << endl;
- 1
- 2
- 3
- 4
- 5
- 6
现在我们有了一个面部矩形,我们可以通过多种方式使用它,例如从原始图像中提取或裁剪面部图像。 以下代码允许我们访问面部:
// Access just the face within the camera image.
Mat faceImg = cameraImg(faceRect);
- 1
- 2
下图显示了人脸检测器给出的典型矩形区域:

步骤 2:人脸预处理
如前所述,人脸识别极易受到光照条件,人脸方向,人脸表情等变化的影响,因此,尽可能减少这些差异非常重要。 否则,人脸识别算法通常会认为在相同条件下两个不同人的面孔之间的相似度要比同一人的两个面孔之间的相似度高。
人脸预处理的最简单形式就是使用equalizeHist()函数应用直方图均衡化,就像我们对人脸检测所做的那样。 对于某些照明和位置条件变化不大的项目,这可能就足够了。 但是,为了在现实环境中保持可靠性,我们需要许多复杂的技术,包括人脸特征检测(例如,检测眼睛,鼻子,嘴巴和眉毛)。 为了简单起见,本章将仅使用眼睛检测,而忽略其他不太有用的人脸特征,例如嘴和鼻子。 下图显示了使用本节介绍的技术处理的典型预处理面的放大视图:

眼睛检测
眼睛检测对于面部预处理非常有用,因为对于正面的面部,尽管面部表情有所变化,但您始终可以假设一个人的眼睛应该是水平的并且在面部的相对位置,并且在面部中应该具有相当标准的位置和大小, 光照条件,相机属性,到相机的距离等等。 当人脸检测器说已检测到面部并且实际上是其他事物时,丢弃误报也很有用。 脸部检测器和两个眼睛检测器都被同时欺骗是非常罕见的,因此,如果仅处理带有检测到的脸部和两只检测到的眼睛的图像,那么它不会有很多假正例(但也会产生更少的人脸) 处理,因为眼睛检测器不会像人脸检测器那样频繁工作。
OpenCV v2.4 随附的一些经过预训练的眼睛检测器可以检测到眼睛是张开还是闭合,而其中一些只能检测到张开的眼睛。
探测睁眼或闭眼的眼部探测器如下:
haarcascade_mcs_lefteye.xml(和haarcascade_mcs_righteye.xml)haarcascade_lefteye_2splits.xml(和haarcascade_righteye_2splits.xml)
仅检测睁开眼睛的眼睛探测器如下:
haarcascade_eye.xmlhaarcascade_eye_tree_eyeglasses.xml
注意
当睁眼或闭眼探测器指定要训练哪只眼睛时,您需要为左眼和右眼使用不同的探测器,而仅睁眼的探测器可以对左眼或右眼使用同一探测器。
如果人戴着眼镜,检测器haarcascade_eye_tree_eyeglasses.xml可以检测到眼睛,但是如果不戴眼镜,检测器haarcascade_eye_tree_eyeglasses.xml不可靠。
如果 XML 文件名显示“左眼”,则表示人的实际左眼,因此在相机图像中,它通常会出现在脸部的右侧,而不是左侧!
提到的四个眼睛探测器的列表按从最可靠到最不可靠的大致顺序排列,因此如果您不需要找戴眼镜的人,那么第一个探测器可能是最佳选择。
眼睛搜索区域
对于眼睛检测,重要的是裁剪输入图像以仅显示大致的眼睛区域,就像进行人脸检测,然后裁剪为左眼应该位于的小矩形(如果您使用的是左眼检测器)一样, 右眼检测器的右矩形相同。 如果只对整个脸部或整个照片进行眼睛检测,则速度会慢得多,可靠性也会降低。 不同的眼睛检测器更适合面部的不同区域,例如,haarcascade_eye.xml检测器仅在实际眼睛周围非常狭窄的区域中搜索时效果最佳,而haarcascade_mcs_lefteye.xml和haarcascade_lefteye_2splits.xml检测器在眼睛周围有一个很大的区域时效果最佳。
下表使用检测到的面部矩形内的相对坐标,列出了针对不同眼睛检测器(使用 LBP 人脸检测器时)的面部的一些良好搜索区域:
| 级联分类器 | EYE_SX | EYE_SY | EYE_SW | EYE_SH |
|---|---|---|---|---|
haarcascade_eye.xml | 0.16 | 0.26 | 0.30 | 0.28 |
haarcascade_mcs_lefteye.xml | 0.10 | 0.19 | 0.40 | 0.36 |
haarcascade_lefteye_2splits.xml | 0.12 | 0.17 | 0.37 | 0.36 |
以下是从检测到的脸部提取左眼和右眼区域的源代码:
int leftX = cvRound(face.cols * EYE_SX);
int topY = cvRound(face.rows * EYE_SY);
int widthX = cvRound(face.cols * EYE_SW);
int heightY = cvRound(face.rows * EYE_SH);
int rightX = cvRound(face.cols * (1.0-EYE_SX-EYE_SW));
Mat topLeftOfFace = faceImg(Rect(leftX, topY, widthX,
heightY));
Mat topRightOfFace = faceImg(Rect(rightX, topY, widthX,
heightY));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
下图显示了适用于不同眼图检测器的理想搜索区域,其中haarcascade_eye.xml和haarcascade_eye_tree_eyeglasses.xml对于较小的搜索区域是最佳的,而haarcascade_mcs_*eye.xml和haarcascade_*eye_2splits.xml对于较大的搜索区域是最佳的。 请注意,还显示了检测到的面部矩形,以了解将眼睛搜索区域与检测到的面部矩形相比有多大:

当使用上表中给出的眼睛搜索区域时,以下是不同眼睛检测器的近似检测属性:
| 级联分类器 | 可靠性 [1] | 速度 [2] | 发现眼睛 | 眼镜 |
|---|---|---|---|---|
haarcascade_mcs_lefteye.xml | 80% | 18 毫秒 | 打开或关闭 | 否 |
haarcascade_lefteye_2splits.xml | 60% | 7 毫秒 | 打开或关闭 | 否 |
haarcascade_eye.xml | 40% | 5 毫秒 | 只打开 | 否 |
haarcascade_eye_tree_eyeglasses.xml | 15% | 10 毫秒 | 只打开 | 是 |
[1] 可靠性值显示了在没有佩戴眼镜且睁开双眼的情况下,在 LBP 正面检测后双眼检测的频率。 如果眼睛闭合,则可靠性可能会下降,或者如果戴眼镜,则可靠性和速度都会下降。
在 Intel Core i7 2.2 GHz 上,图像缩放到320 x 240像素大小时的速度值(以毫秒为单位)(在 1000 张照片中平均)。 当发现眼睛时,速度通常要比没有发现眼睛时快得多,因为它必须扫描整个图像,但是haarcascade_mcs_lefteye.xml仍然比其他眼睛检测器慢得多。
例如,如果将照片缩小到320 x 240像素,对其进行直方图均衡化,请使用 LBP 正面人脸检测器获取人脸,然后使用以下方法从人脸中提取左眼区域和右眼区域haarcascade_mcs_lefteye.xml值,然后对每个眼睛区域执行直方图均衡。 然后,如果您用左眼的haarcascade_mcs_lefteye.xml检测器(实际上位于图像的右上角)并用右眼的haarcascade_mcs_righteye.xml检测器(图像的左上角), 探测器应能在 90% 带有 LBP 检测到的正面的照片中工作。 因此,如果您希望两只眼睛都被检测到,那么它应该可以在 80% 具有 LBP 检测到的前脸的照片中工作。
请注意,虽然建议在检测到脸部之前先缩小相机图像,但您应该以完整的相机分辨率来检测眼睛,因为眼睛显然会比脸部小很多,因此需要尽可能多的分辨率。
注意
根据表,似乎在选择要使用的眼睛检测器时,应该决定是要检测闭合的眼睛还是仅检测睁开的眼睛。 请记住,您甚至可以使用一只眼睛检测器,如果它无法检测到眼睛,则可以尝试使用另一只。
对于许多任务,检测眼睛是否睁开是很有用的,因此,如果速度不是很关键,最好先使用mcs_*eye检测器进行搜索,如果失败,则使用eye_2splits检测器进行搜索。
但是对于人脸识别,如果人闭着眼睛会出现很大的不同,因此最好先使用普通的haarcascade_eye检测器进行搜索,如果失败,则使用haarcascade_eye_tree_eyeglasses检测器进行搜索。
我们可以使用与人脸检测相同的detectLargestObject()函数来搜索眼睛,但是我们无需指定在眼睛检测之前缩小图像的大小,而是指定整个眼睛区域的宽度以获得更好的眼睛检测。 使用一个检测器搜索左眼很容易,如果检测失败,则尝试使用另一个检测器(与右眼相同)。 眼睛检测如下:
CascadeClassifier eyeDetector1("haarcascade_eye.xml"); CascadeClassifier eyeDetector2("haarcascade_eye_tree_eyeglasses.xml"); ... Rect leftEyeRect; // Stores the detected eye. // Search the left region using the 1st eye detector. detectLargestObject(topLeftOfFace, eyeDetector1, leftEyeRect, topLeftOfFace.cols); // If it failed, search the left region using the 2nd eye // detector. if (leftEyeRect.width <= 0) detectLargestObject(topLeftOfFace, eyeDetector2, leftEyeRect, topLeftOfFace.cols); // Get the left eye center if one of the eye detectors worked. Point leftEye = Point(-1,-1); if (leftEyeRect.width <= 0) { leftEye.x = leftEyeRect.x + leftEyeRect.width/2 + leftX; leftEye.y = leftEyeRect.y + leftEyeRect.height/2 + topY; } // Do the same for the right-eye ... // Check if both eyes were detected. if (leftEye.x >= 0 && rightEye.x >= 0) { ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
在检测到面部和双眼的情况下,我们将通过组合以下步骤进行面部预处理:
- 几何变换和裁剪:此过程将包括缩放,旋转和平移图像,以使眼睛对齐,然后从脸部去除前额,下巴,耳朵和背景图片。
- 左侧和右侧的单独直方图均衡:此过程可标准化脸部左侧和右侧的亮度和对比度。
- 平滑:此过程使用双边过滤器减少图像噪声。
- 椭圆遮罩:椭圆遮罩从面部图像上去除了一些残留的头发和背景。
下图显示了应用于检测到的脸部的脸部预处理步骤 1 至 4。 请注意,最终图像在脸部两边如何具有良好的亮度和对比度,而原始图像却没有:

几何变换
将面部全部对齐在一起非常重要,否则人脸识别算法可能会将鼻子的一部分与眼睛的一部分进行比较,依此类推。 刚刚看到的人脸检测输出将在某种程度上给出对齐的面部,但是它不是很准确(也就是说,面部矩形将不会总是从前额的同一点开始)。
为了更好地对齐,我们将使用眼睛检测来对齐面部,以便检测到的两只眼睛的位置在所需位置完美对齐。 我们将使用warpAffine()函数进行几何变换,这是一个单一的操作,它将完成四件事:
- 旋转脸部,使两只眼睛保持水平。
- 缩放脸部,使两只眼睛之间的距离始终相同。
- 平移脸部,使眼睛始终水平居中并处于所需高度。
- 修剪脸部的外部,因为我们要修剪掉图像的背景,头发,额头,耳朵和下巴。
仿射扭曲使用仿射矩阵,将两个检测到的眼睛位置转换为两个所需的眼睛位置,然后裁剪为所需的大小和位置。 要生成此仿射矩阵,我们将获取两眼之间的中心,计算出两只被检测到的眼睛出现的角度,并如下看它们的距离:
// Get the center between the 2 eyes. Point2f eyesCenter; eyesCenter.x = (leftEye.x + rightEye.x) * 0.5f; eyesCenter.y = (leftEye.y + rightEye.y) * 0.5f; // Get the angle between the 2 eyes. double dy = (rightEye.y - leftEye.y); double dx = (rightEye.x - leftEye.x); double len = sqrt(dx*dx + dy*dy); // Convert Radians to Degrees. double angle = atan2(dy, dx) * 180.0/CV_PI; // Hand measurements shown that the left eye center should // ideally be roughly at (0.16, 0.14) of a scaled face image. const double DESIRED_LEFT_EYE_X = 0.16; const double DESIRED_RIGHT_EYE_X = (1.0f – 0.16); // Get the amount we need to scale the image to be the desired // fixed size we want. const int DESIRED_FACE_WIDTH = 70; const int DESIRED_FACE_HEIGHT = 70; double desiredLen = (DESIRED_RIGHT_EYE_X – 0.16); double scale = desiredLen * DESIRED_FACE_WIDTH / len;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
现在,我们可以对脸部进行变形(旋转,缩放和平移),以使两只检测到的眼睛处于理想脸部中所需的眼睛位置,如下所示:
// Get the transformation matrix for the desired angle & size.
Mat rot_mat = getRotationMatrix2D(eyesCenter, angle, scale);
// Shift the center of the eyes to be the desired center.
double ex = DESIRED_FACE_WIDTH * 0.5f - eyesCenter.x;
double ey = DESIRED_FACE_HEIGHT * DESIRED_LEFT_EYE_Y –
eyesCenter.y;
rot_mat.at<double>(0, 2) += ex;
rot_mat.at<double>(1, 2) += ey;
// Transform the face image to the desired angle & size &
// position! Also clear the transformed image background to a
// default grey.
Mat warped = Mat(DESIRED_FACE_HEIGHT, DESIRED_FACE_WIDTH,
CV_8U, Scalar(128));
warpAffine(gray, warped, rot_mat, warped.size());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
左侧和右侧的单独直方图均衡
在现实环境中,通常在脸的一半上有强光,而在另一半上有弱光。 这对人脸识别算法有巨大的影响,因为同一张脸的左右两侧看起来就像是完全不同的人。 因此,我们将在脸部的左右两边分别进行直方图均衡化,以使脸部的每一侧具有标准化的亮度和对比度。
如果我们仅在左半部分然后再在右半部分上应用直方图均衡化,则由于中间的平均亮度可能会有所不同,因此我们会在中间看到一个非常明显的边缘,因此删除该边缘 ,我们将从左侧或右侧向中心逐渐应用两个直方图均衡化,然后将其与整个面部直方图均衡化混合,以便最左侧使用左侧直方图均衡化,最右侧 -手侧将使用右侧直方图均衡化,而中心将使用左侧或右侧值与整个面部均衡值的平滑混合。
下图显示了左平衡,整体平衡和右平衡图像如何融合在一起:

为此,我们需要均衡整个脸部的副本以及均衡的左半部分和右半部分,方法如下:
int w = faceImg.cols;
int h = faceImg.rows;
Mat wholeFace;
equalizeHist(faceImg, wholeFace);
int midX = w/2;
Mat leftSide = faceImg(Rect(0,0, midX,h));
Mat rightSide = faceImg(Rect(midX,0, w-midX,h));
equalizeHist(leftSide, leftSide);
equalizeHist(rightSide, rightSide);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
现在,我们将三个图像组合在一起。 由于图像较小,因此即使速度较慢,我们也可以使用image.at<uchar>(y,x)函数轻松直接访问像素。 因此,让我们通过直接访问三个输入图像和输出图像中的像素来合并三个图像,如下所示:
for (int y=0; y<h; y++) { for (int x=0; x<w; x++) { int v; if (x < w/4) { // Left 25%: just use the left face. v = leftSide.at<uchar>(y,x); } else if (x < w*2/4) { // Mid-left 25%: blend the left face & whole face. int lv = leftSide.at<uchar>(y,x); int wv = wholeFace.at<uchar>(y,x); // Blend more of the whole face as it moves // further right along the face. float f = (x - w*1/4) / (float)(w/4); v = cvRound((1.0f - f) * lv + (f) * wv); } else if (x < w*3/4) { // Mid-right 25%: blend right face & whole face. int rv = rightSide.at<uchar>(y,x-midX); int wv = wholeFace.at<uchar>(y,x); // Blend more of the right-side face as it moves // further right along the face. float f = (x - w*2/4) / (float)(w/4); v = cvRound((1.0f - f) * wv + (f) * rv); } else { // Right 25%: just use the right face. v = rightSide.at<uchar>(y,x-midX); } faceImg.at<uchar>(y,x) = v; }// end x loop }//end y loop
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这种分离的直方图均衡化应显着帮助减少脸部左右两侧的不同照明效果,但我们必须了解,由于脸部是单侧照明,因此无法完全消除单侧照明的效果。 具有许多阴影的复杂 3D 形状。
平滑
为了减少像素噪声的影响,我们将在脸上使用双向过滤器,因为双向过滤器非常擅长平滑大部分图像,同时保持边缘清晰。 直方图均衡化会显着增加像素噪声,因此我们将使过滤器强度20覆盖较重的像素噪声,但由于我们要严重平滑微小的像素噪声而不是较大的图像区域,因此仅使用两个像素的邻域, 如下:
Mat filtered = Mat(warped.size(), CV_8U);
bilateralFilter(warped, filtered, 0, 20.0, 2.0);
- 1
- 2
- 3
椭圆形遮罩
尽管在进行几何变换时我们已经去除了大部分图像背景,额头和头发,但是我们可以应用椭圆遮罩去除一些角落区域(例如脖子),该区域可能在脸部阴影中,尤其是在脸部无法完全对准相机时。 要创建遮罩,我们将在白色图像上绘制黑色填充的椭圆。 执行此操作的一个椭圆的水平半径为 0.5(即,它完美地覆盖了脸部宽度),垂直半径为 0.8(因为脸部通常比其宽高),并且以坐标 0.5、0.4 为中心。 如下图所示,其中椭圆遮罩已去除了面部的一些不需要的角:

我们可以在调用cv::setTo()函数时应用遮罩,该函数通常会将整个图像设置为某个像素值,但是由于我们将给出一个遮罩图像,因此它只会将某些部分设置为给定的像素值。 我们将用灰色填充图像,以使其与脸部其余部分的对比度降低:
// Draw a black-filled ellipse in the middle of the image.
// First we initialize the mask image to white (255).
Mat mask = Mat(warped.size(), CV_8UC1, Scalar(255));
double dw = DESIRED_FACE_WIDTH;
double dh = DESIRED_FACE_HEIGHT;
Point faceCenter = Point( cvRound(dw * 0.5),
cvRound(dh * 0.4) );
Size size = Size( cvRound(dw * 0.5), cvRound(dh * 0.8) );
ellipse(mask, faceCenter, size, 0, 0, 360, Scalar(0),
CV_FILLED);
// Apply the elliptical mask on the face, to remove corners.
// Sets corners to gray, without touching the inner face.
filtered.setTo(Scalar(128), mask);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
以下放大图像显示了所有面部预处理阶段的样本结果。 请注意,在不同的亮度,面部旋转,与相机的角度,背景,灯光位置等方面,人脸识别更加一致。 在收集要训练的脸部以及尝试识别输入脸部时,都将使用此经过预处理的脸部作为脸部识别阶段的输入:

步骤 3:收集人脸并从中学习
收集人脸就像将每个新预处理过的人脸放入相机中经过预处理的人脸数组,以及将标签放入数组中(指定要从哪个人那里获取人脸)一样简单。 例如,您可以使用第一个人的 10 张预处理过的面孔和第二个人的 10 张预处理过的面孔,因此人脸识别算法的输入将是 20 个预处理过的面孔和 20 个整数的数组(其中前 10 个数字为 0,接下来的 10 个数字为 1)。
然后,人脸识别算法将学习如何区分不同人的面部。 这被称为训练阶段,并且所收集的面部被称为训练集。 人脸识别算法完成训练后,您可以将生成的知识保存到文件或内存中,以后再使用它来识别在相机前面看到了哪个人。 这称为测试阶段。 如果直接从摄像机输入中使用它,则预处理的面部将被称为测试图像,并且如果您对许多图像(例如,来自图像文件的文件夹)进行了测试,则其将被称为测试集。
重要的是,您必须提供一个良好的训练集,以涵盖您期望在测试集中发生的变化类型。 例如,如果您仅测试正面朝前的脸部(例如证件照片),则仅需提供正面朝上的脸部训练图像。 但是,如果该人可能是向左看或向左看,则应确保训练集也包括执行此操作的那个人的脸部,否则脸部识别算法将很难识别他们,因为他们的脸部看起来会大不相同。 这也适用于其他因素,例如面部表情(例如,如果该人始终在训练集中微笑着而不在测试集中微笑着)或照明方向(例如,强光指向左侧) 训练集(但位于测试集的右侧),则人脸识别算法将很难识别它们。 我们刚刚看到的人脸预处理步骤将有助于减少这些问题,但是它肯定不会消除这些因素,特别是不会影响人脸的外观方向,因为它会对人脸中所有元素的位置产生很大影响。
注意
获得涵盖多种不同现实条件的良好训练集的一种方法是,每个人从左向左旋转,向上,向右,向下旋转然后直接直视。 然后,该人侧向倾斜头部,然后向上和向下倾斜,同时还改变了面部表情,例如在微笑,生气和中性之间交替。 如果每个人在收集面部表情时都遵循这样的常规,那么在现实世界中识别每个人的机会就更大。
为了获得更好的效果,应该在一个或两个以上的位置或方向上再次执行此操作,例如通过将摄像机旋转 180 度并沿与摄像机相反的方向行走,然后重复整个例程,以便训练集可以包括许多不同的照明条件。
因此,总的来说,与每个人只有 10 个训练脸相比,每个人拥有 100 个训练脸可能会产生更好的结果,但是如果所有 100 个脸看起来几乎相同,那么它仍然会表现不佳,因为训练集具有足够的多样性来覆盖测试集更重要,而不仅仅是拥有大量的面孔。 因此,为确保训练集中的人脸不太相似,我们应该在每个收集到的人脸之间添加明显的延迟。 例如,如果摄像头以每秒 30 帧的速度运行,那么当人没有时间走动时,它可能会在短短几秒钟内收集 100 张脸,因此最好每秒拍摄一幅脸,同时人们移动他们的脸。 改善训练集变化的另一种简单方法是仅在面部与先前收集的面部明显不同的情况下收集面部。
收集经过预处理的人脸来训练
为了确保收集新面孔之间至少有一秒钟的间隔,我们需要测量已花费了多少时间。 这样做如下:
// Check how long since the previous face was added.
double current_time = (double)getTickCount();
double timeDiff_seconds = (current_time –
old_time) / getTickFrequency();
- 1
- 2
- 3
- 4
为了逐像素比较两个图像的相似性,您可以找到相对的 L2 误差,它只涉及从另一幅图像中减去一张图像,将其平方值相加,然后求出其平方根。 因此,如果该人根本没有移动,则将当前人脸与前一个人脸相减应在每个像素处给出一个很小的数字,但是如果他们只是在任何方向上略微移动,则减去像素将给出一个较大的数字,因此 L2 错误会很高。 由于将所有像素的结果相加,因此该值将取决于图像分辨率。 因此,要获得平均误差,我们应将此值除以图像中的像素总数。 让我们将其放在方便的函数getSimilarity()中,如下所示:
double getSimilarity(const Mat A, const Mat B) { // Calculate the L2 relative error between the 2 images. double errorL2 = norm(A, B, CV_L2); // Scale the value since L2 is summed across all pixels. double similarity = errorL2 / (double)(A.rows * A.cols); return similarity; } ... // Check if this face looks different from the previous face. double imageDiff = MAX_DBL; if (old_prepreprocessedFaceprepreprocessedFace.data) { imageDiff = getSimilarity(preprocessedFace, old_prepreprocessedFace); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
如果图像移动不多,相似度通常小于 0.2;如果图像移动不动,则相似度大于 0.4,因此让我们使用 0.3 作为收集新面孔的阈值。
我们可以通过许多技巧来获取更多训练数据,例如使用镜像的面部,添加随机噪声,将面部移动几个像素,按比例缩放面部或将面部旋转几度(即使我们专门尝试在预处理面部时消除这些效果! 在训练过程中向左或向右移动,但不进行测试。 这样做如下:
// Only process the face if it's noticeably different from the // previous frame and there has been a noticeable time gap. if ((imageDiff > 0.3) && (timeDiff_seconds > 1.0)) { // Also add the mirror image to the training set. Mat mirroredFace; flip(preprocessedFace, mirroredFace, 1); // Add the face & mirrored face to the detected face lists. preprocessedFaces.push_back(preprocessedFace); preprocessedFaces.push_back(mirroredFace); faceLabels.push_back(m_selectedPerson); faceLabels.push_back(m_selectedPerson); // Keep a copy of the processed face, // to compare on next iteration. old_prepreprocessedFace = preprocessedFace; old_time = current_time; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这将收集经过预处理的人脸的std::vector数组preprocessedFaces和faceLabels以及该人的标签或 ID 号(假设它在整数m_selectedPerson变量中)。
为了使用户更清楚地知道我们已经将其当前面孔添加到了集合中,您可以通过以下方式提供视觉通知:在整个图像上显示一个大的白色矩形,或者仅将他们的脸栈式一秒钟,因此他们意识到拍了张照片。 使用 OpenCV 的 C++ 接口,您可以使用+重载的cv::Mat运算符向图像中的每个像素添加一个值,并将其裁剪为 255(使用saturate_cast,这样它不会从白色溢出到黑色 !)假设displayedFrame是应该显示的彩色相机帧的副本,请将其插入到前面的面部收集代码之后:
// Get access to the face region-of-interest.
Mat displayedFaceRegion = displayedFrame(faceRect);
// Add some brightness to each pixel of the face region.
displayedFaceRegion += CV_RGB(90,90,90);
- 1
- 2
- 3
- 4
从收集到的人脸中训练人脸识别系统
收集到足以让每个人识别的面孔后,您必须使用适合面孔识别的机器学习算法训练系统以学习数据。 文献中有许多不同的人脸识别算法,其中最简单的是 EigenFace 和人工神经网络。 EigenFace 倾向于比人工神经网络更好地工作,尽管它很简单,但它却几乎可以与许多更复杂的脸部识别算法一起工作,因此,它作为初学者和新算法的基础人脸识别算法已经非常流行。 相比。
建议任何希望进一步研究人脸识别的读者阅读其背后的理论:
- EigenFace(也称为主成分分析(PCA))
- Fisherfaces(也称为线性判别分析(LDA))
- 其他经典的人脸识别算法(这个页面中提供了许多算法)
- 最近的计算机视觉研究论文(例如这个页面上的 CVPR 和 ICCV)中更新的人脸识别算法,因为每年都会发布数百篇人脸识别论文
但是,您无需了解这些算法的原理即可使用本书中所示的这些算法。 感谢 OpenCV 团队和 Philipp Wagner 的libfacerec贡献,OpenCV v2.4.1 提供了cv::Algo rithm作为使用几种不同算法(甚至在运行时可以选择)中的一种来执行人脸识别的简单通用方法。 必须了解它们是如何实现的。 您可以使用Algorithm::getList()函数在您的 OpenCV 版本中找到可用的算法,例如以下代码:
vector<string> algorithms;
Algorithm::getList(algorithms);
cout << "Algorithms: " << algorithms.size() << endl;
for (int i=0; i<algorithms.size(); i++) {
cout << algorithms[i] << endl;
}
- 1
- 2
- 3
- 4
- 5
- 6
以下是 OpenCV v2.4.1 中提供的三种人脸识别算法:
FaceRecognizer.Eigenfaces:EigenFace,也称为 PCA,在 1991 年由 Turk 和 Pentland 首次使用。FaceRecognizer.Fisherfaces:Fisherfaces,也称为 LDA,由 Belhumeur,Hespanha 和 Kriegman 于 1997 年发明。FaceRecognizer.LBPH:Ahonen,Hadid 和 Pietikäinen 于 2004 年发明的局部二值模式直方图。
注意
可以在 Philipp Wagner 的网站和这个页面上找到有关这些人脸识别算法实现的更多信息,并附带文档,示例和 Python 等效项。
这些人脸识别算法可通过 OpenCV 的contrib模块中的FaceRecognizer类获得。 由于动态链接,您的程序可能已链接到contrib模块,但实际上并未在运行时加载(如果认为不是必需的话)。 因此,建议在尝试访问FaceRecognizer算法之前先调用cv::initModule_contrib()函数。 该函数仅在 OpenCV v2.4.1 中可用,因此它还确保至少在编译时对人脸识别算法可用:
// Load the "contrib" module is dynamically at runtime.
bool haveContribModule = initModule_contrib();
if (!haveContribModule) {
cerr << "ERROR: The 'contrib' module is needed for ";
cerr << "FaceRecognizer but hasn't been loaded to OpenCV!";
cerr << endl;
exit(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
要使用一种人脸识别算法,我们必须使用cv::Algorithm::create<FaceRecognizer>()函数创建一个FaceRecognizer对象。 我们将要使用的人脸识别算法的名称作为字符串传递给此create函数。 如果该算法在 OpenCV 版本中可用,则将使我们能够使用该算法。 因此,它可以用作运行时错误检查,以确保用户具有 OpenCV v2.4.1 或更高版本。 例如:
string facerecAlgorithm = "FaceRecognizer.Fisherfaces";
Ptr<FaceRecognizer> model;
// Use OpenCV's new FaceRecognizer in the "contrib" module:
model = Algorithm::create<FaceRecognizer>(facerecAlgorithm);
if (model.empty()) {
cerr << "ERROR: The FaceRecognizer [" << facerecAlgorithm;
cerr << "] is not available in your version of OpenCV. ";
cerr << "Please update to OpenCV v2.4.1 or newer." << endl;
exit(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
加载FaceRecognizer算法后,我们只需使用收集到的面部数据调用FaceRecognizer::train()函数,如下所示:
// Do the actual training from the collected faces.
model->train(preprocessedFaces, faceLabels);
- 1
- 2
- 3
这段代码将运行您选择的整个人脸识别训练算法(例如,Eigenfaces,Fisherfaces 或其他可能的算法)。 如果只有几个人的面孔少于 20 个,则此训练应该很快返回,但是如果您有很多人的面孔却很多,train()函数可能需要几秒钟甚至几分钟来处理所有数据。
查看所学知识
虽然没有必要,但是在学习训练数据时查看人脸识别算法生成的内部数据结构非常有用,特别是如果您了解所选算法背后的理论并想验证其是否有效或找出其原因的话,不能如您所愿。 对于不同的算法,内部数据结构可能有所不同,但是幸运的是,对于 Eigenfaces 和 Fisherfaces,它们的内部数据结构是相同的,因此让我们仅看一下这两个。 它们都基于一维特征向量矩阵,当以 2D 图像查看时,它们看起来有点像人脸,因此在使用 EigenFace 算法时通常将特征向量称为 EigenFace,在使用 Fisherface 算法时通常将其称为 fisherfaces。
简单来说,EigenFace 的基本原理是它将计算出一组特殊图像(EigenFace)和混合比率(特征值),当以不同方式组合时,它们可以生成训练集中的每个图像,但也可以用于区分训练集中的许多人脸图像。 例如,如果训练集中的某些脸部有胡须,而有些脸部没有胡须,那么至少会有一个 EigenFace 出现胡须,因此带有胡须的训练面将具有较高的混合比例。 表示它有胡须,而没有胡须的脸对于该特征向量的混合比率较低。 如果训练集有 5 个人,每个人有 20 张脸,那么将有 100 个 EigenFace 和特征值来区分训练集中的 100 张总脸,实际上,这些将被排序,因此前几个 EigenFace 和特征值将是最关键的区分器,最后几个特征面和特征值只是随机的像素噪声,实际上并不能帮助区分数据。 因此,通常的做法是丢弃一些最后的特征面,而只保留前 50 个左右的特征面。
相比之下,Fisherfaces 的基本原理是,与其为训练集中的每个图像计算一个特殊的特征向量和特征值,不如为每个人计算一个特殊的特征向量和特征值。 因此,在前面的示例中有 5 个人,每个人有 20 张脸,EigenFace 算法将使用 100 个 EigenFace 和特征值,而 Fisherfaces 算法将仅使用 5 个渔夫脸和特征值。
要访问 Eigenfaces 和 Fisherfaces 算法的内部数据结构,我们必须使用cv::Algorithm::get() 函数在运行时获取它们,因为在编译时无法访问它们。 数据结构在内部用作数学计算的一部分,而不是用于图像处理,因此通常将它们存储为浮点数,通常在 0.0 到 1.0 之间,而不是在 0 到 255 之间的 8 位uchar像素,类似于常规图像中的像素。 同样,它们通常是一维行或列矩阵,或者它们构成较大矩阵的许多一维行或列之一。 因此,在显示许多内部数据结构之前,必须将它们重新整形为正确的矩形形状,并将它们转换为 0 到 255 之间的 8 位uchar像素。因为矩阵数据的范围可能是 0.0 到 1.0 或 -1.0 到 1.0 或其他值,您可以将cv::normalize()函数与cv::NORM_MINMAX选项一起使用,以确保无论输入范围是多少,它都输出 0 到 255 之间的数据。 让我们创建一个函数来执行此整形为矩形并为我们转换为 8 位像素,如下所示:
// Convert the matrix row or column (float matrix) to a
// rectangular 8-bit image that can be displayed or saved.
// Scales the values to be between 0 to 255.
Mat getImageFrom1DFloatMat(const Mat matrixRow, int height)
{
// Make a rectangular shaped image instead of a single row.
Mat rectangularMat = matrixRow.reshape(1, height);
// Scale the values to be between 0 to 255 and store them
// as a regular 8-bit uchar image.
Mat dst;
normalize(rectangularMat, dst, 0, 255, NORM_MINMAX,
CV_8UC1);
return dst;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
为了更轻松地调试 OpenCV 代码,甚至在内部调试cv::Algorithm数据结构时,我们可以使用ImageUtils.cpp和ImageUtils.h文件轻松显示有关cv::Mat结构的信息,如下所示:
Mat img = ...;
printMatInfo(img, "My Image");
- 1
- 2
您将在控制台上看到类似于以下内容的内容:
My Image: 640w480h 3ch 8bpp, range[79,253][20,58][18,87]
- 1
这告诉您,它的宽度为 640 个元素,高度为 480 个(即640 x 480图像或640 x 480矩阵,具体取决于您查看的方式),每个像素具有三个通道,每个通道为 8 位(即 ,是常规的 BGR 图像),并显示每个颜色通道在图像中的最小值和最大值。
注意
通过使用printMat()函数代替printMatInfo()函数,也可以打印图像或矩阵的实际内容。 这对于查看矩阵和多通道浮点矩阵非常方便,因为对于初学者而言,查看起来非常棘手。
ImageUtils 代码主要用于 OpenCV 的 C 接口,但是随着时间的推移,它逐渐包含了更多的 C++ 接口。 可以在这个页面中找到最新版本。
平均人脸
Eigenfaces 和 Fisherfaces 算法都首先计算平均脸部,即所有训练图像的数学平均值,因此它们可以从每个脸部图像中减去平均图像,以获得更好的脸部识别结果。 因此,让我们从训练集中查看平均面孔。 在 Eigenfaces 和 Fisherfaces 实现中,平均人脸名为mean,如下所示:
Mat averageFace = model->get<Mat>("mean");
printMatInfo(averageFace, "averageFace (row)");
// Convert a 1D float row matrix to a regular 8-bit image.
averageFace = getImageFrom1DFloatMat(averageFace, faceHeight);
printMatInfo(averageFace, "averageFace");
imshow("averageFace", averageFace);
- 1
- 2
- 3
- 4
- 5
- 6
现在,您应该在屏幕上看到平均的人脸图像,类似于下面的(放大的)男人,女人和婴儿的图像。 您还应该在控制台上看到类似的文本:
averageFace (row): 4900w1h 1ch 64bpp, range[5.21,251.47]
averageFace: 70w70h 1ch 8bpp, range[0,255]
- 1
- 2
- 3
该图像将显示为以下屏幕快照所示:

请注意, averageFace (row)是 64 位浮点数的单行矩阵,而averageFace是具有 8 位像素的矩形图像,覆盖了从 0 到 255 的整个范围。
特征值,EigenFace 和 Fisherfaces
让我们查看特征值中的实际组件值(作为文本):
Mat eigenvalues = model->get<Mat>("eigenvalues");
printMat(eigenvalues, "eigenvalues");
- 1
- 2
对于 EigenFace,每个脸都有一个特征值,因此如果我们有三个人,每个人有四个脸,我们将获得一个列向量,该列向量具有 12 个特征值,从最佳到最差按如下顺序排序:
eigenvalues: 1w18h 1ch 64bpp, range[4.52e+04,2.02836e+06]
2.03e+06
1.09e+06
5.23e+05
4.04e+05
2.66e+05
2.31e+05
1.85e+05
1.23e+05
9.18e+04
7.61e+04
6.91e+04
4.52e+04
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
对于 Fisherfaces,每个额外的人只有一个特征值,因此,如果有三个人,每个人有四个脸,我们将得到一个具有两个特征值的行向量,如下所示:
eigenvalues: 2w1h 1ch 64bpp, range[152.4,316.6]
317, 152
- 1
- 2
要查看特征向量(作为 EigenFace 或 Fisherface 图像),我们必须从大特征向量矩阵中将它们提取为列。 由于 OpenCV 和 C/C++ 中的数据通常使用行优先顺序存储在矩阵中,这意味着要提取列,我们应该使用Mat::clone()函数来确保数据将是连续的,否则我们将无法重塑数据为一个矩形。 一旦有了连续的列Mat,就可以使用getImageFrom1DFloatMat()函数显示特征向量,就像我们对普通人脸所做的一样:
// Get the eigenvectors
Mat eigenvectors = model->get<Mat>("eigenvectors");
printMatInfo(eigenvectors, "eigenvectors");
// Show the best 20 eigenfaces
for (int i = 0; i < min(20, eigenvectors.cols); i++) {
// Create a continuous column vector from eigenvector #i.
Mat eigenvector = eigenvectors.col(i).clone();
Mat eigenface = getImageFrom1DFloatMat(eigenvector,
faceHeight);
imshow(format("Eigenface%d", i), eigenface);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下图将特征向量显示为图像。 您可以看到,对于具有四个脸的三个人,有 12 个本征脸(图的左侧)或两个 Fisherface(脸部)。
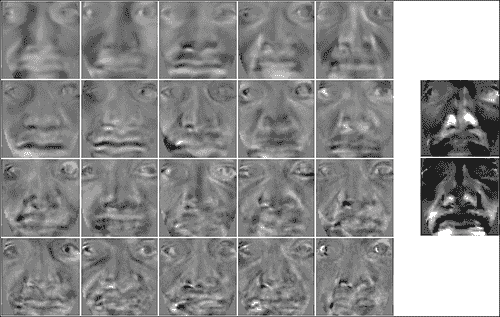
请注意,EigenFace 和 Fisherfaces 似乎都具有某些人脸特征的相似之处,但它们看起来并不像面孔。 这仅仅是因为从它们中减去了平均脸,所以它们只是显示出每个 EigenFace 与平均脸的差异。 编号会显示它是哪个 EigenFace,因为它们总是从最重要的 EigenFace 到最不重要的 EigenFace 排列,并且如果您有 50 个或更多的 EigenFace,则后面的 EigenFace 通常只会显示随机图像噪声,因此应将其丢弃。
步骤 4:人脸识别
现在,我们已经使用我们的一组训练图像和面部标签训练了 EigenFace 或 Fisherfaces 机器学习算法,我们终于准备好从面部图像中找出一个人是谁! 最后一步称为人脸识别或人脸识别。
人脸识别:从人脸识别人
多亏了 OpenCV 的FaceRecognizer类,我们可以通过在面部图像上调用FaceRecognizer::predict()函数来简单地识别照片中的人,如下所示:
int identity = model->predict(preprocessedFace);
- 1
该identity值将是我们在收集用于训练的脸部时最初使用的标签号。 例如,第一个人为 0,第二个人为 1,依此类推。
这种识别的问题在于,即使输入的照片是不知名的人或汽车,它也总是可以预测给定的人之一。 它仍然会告诉您该照片中哪个人是最有可能的人,因此很难相信结果! 解决方案是获取置信度度量,以便我们可以判断结果的可靠性,如果置信度似乎过低,则可以假定它是未知身份的人。
脸部验证:确认它是声称的人
为了确认预测结果是否可靠,或者是否应将其视为陌生人,我们进行了人脸验证(也称为人脸验证),以获取置信度指标,它显示单个人脸图像是否与声称的人相似(相对于我们刚刚进行的人脸识别,即将单张人脸图像与许多人进行比较)。
当您调用predict()函数时,OpenCV 的FaceRecognizer类可以返回置信度量度,但是不幸的是,该置信度度仅基于本征子空间中的距离,因此不是很可靠。 我们将使用的方法是使用特征向量和特征值重建面部图像,并将此重建图像与输入图像进行比较。 如果该人的训练集中包含许多面部,则重构应从学习的特征向量和特征值中很好地进行,但是如果该人在训练集中没有任何面部(或没有相似的面部) 照明和面部表情作为测试图像),则重建后的面部看起来与输入面部非常不同,表明它可能是未知的面部。
记得我们之前说过,EigenFace 和 Fisher 脸算法是基于这样的概念,即图像可以粗略地表示为一组特征向量(特殊面部图像)和特征值(混合比)。 因此,如果我们将所有特征向量与训练集中其中一张脸的特征值结合在一起,则应该获得该原始训练图像的相当接近的副本。 对于与训练集相似的其他图像也是如此—如果将训练后的特征向量与相似测试图像中的特征值结合起来,我们应该能够重建出与测试图像有些相似的图像。
通过使用subspaceProject()函数投影到本征空间,并使用subspaceReconstruct()函数从特征空间投影到图像空间。 诀窍是我们需要将其从浮点行矩阵转换为矩形的 8 位图像(就像我们在显示平均人脸和 EigenFace 时一样),但是我们不想对数据进行归一化,因为它已经处于理想的比例,可以与原始图像进行比较。 如果我们对数据进行归一化,它将具有与输入图像不同的亮度和对比度,并且仅通过使用 L2 相对误差来比较图像相似度将变得困难。 这样做如下:
// Get some required data from the FaceRecognizer model. Mat eigenvectors = model->get<Mat>("eigenvectors"); Mat averageFaceRow = model->get<Mat>("mean"); // Project the input image onto the eigenspace. Mat projection = subspaceProject(eigenvectors, averageFaceRow, preprocessedFace.reshape(1,1)); // Generate the reconstructed face back from the eigenspace. Mat reconstructionRow = subspaceReconstruct(eigenvectors, averageFaceRow, projection); // Make it a rectangular shaped image instead of a single row. Mat reconstructionMat = reconstructionRow.reshape(1, faceHeight); // Convert the floating-point pixels to regular 8-bit uchar. Mat reconstructedFace = Mat(reconstructionMat.size(), CV_8U); reconstructionMat.convertTo(reconstructedFace, CV_8U, 1, 0);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
下图显示了两个典型的重构面。 左侧的脸很好地重建,因为它来自一个已知的人,而右侧的脸则严重地重建,因为它来自一个未知的人或一个已知的人,但光照条件/面部表情未知 /面方向。

现在,我们可以使用先前创建的用于比较两个图像的相同getSimilarity()函数,来计算此重构脸与输入脸的相似程度,其中小于 0.3 的值表示这两个图像非常相似。 对于 EigenFace,每个脸部都有一个特征向量,因此重建往往会很好地工作,因此我们通常可以将阈值设为 0.5,但是 Fisherfaces 对于每个人只有一个特征向量,因此重建将无法正常工作,因此需要较高的阈值,例如 0.7。 这样做如下:
similarity = getSimilarity(preprocessedFace,
reconstructedFace);
if (similarity > UNKNOWN_PERSON_THRESHOLD) {
identity = -1; // Unknown person.
}
- 1
- 2
- 3
- 4
- 5
现在,您可以将身份打印到控制台,或者将其用于您想像不到的任何地方! 请记住,这种脸部识别方法和脸部验证方法仅在您为其训练的某些条件下才是可靠的。 因此,要获得良好的识别准确率,您需要确保每个人的训练集都涵盖了要测试的所有照明条件,面部表情和角度。 面部预处理阶段有助于减少与光照条件和平面内旋转(如果人将头向左或右肩膀倾斜)之间的某些差异,而对于其他差异(例如面外旋转(如果人旋转头)) 朝向左侧或右侧),则只有在训练集中正确覆盖它的情况下它才起作用。
修饰:保存和加载文件
您可能会添加基于命令行的方法,该方法可处理输入文件并将其保存到磁盘,甚至可以执行脸部检测,脸部预处理和/或脸部识别作为 Web 服务,等等。 对于这些类型的项目,使用FaceRecognizer类的save和load函数添加所需的功能非常容易。 您可能还需要保存经过训练的数据,然后将其加载到程序的启动程序中。
将训练后的模型保存到 XML 或 YML 文件非常容易:
model->save("trainedModel.yml");
- 1
- 2
如果以后要向训练集中添加更多数据,则可能还需要保存预处理过的面部和标签的数组。
例如,以下是一些示例代码,用于从文件中加载经过训练的模型。 请注意,您必须指定最初用于创建训练模型的人脸识别算法(例如FaceRecognizer.Eigenfaces或FaceRecognizer.Fisherfaces):
string facerecAlgorithm = "FaceRecognizer.Fisherfaces";
model = Algorithm::create<FaceRecognizer>(facerecAlgorithm);
Mat labels;
try {
model->load("trainedModel.yml");
labels = model->get<Mat>("labels");
} catch (cv::Exception &e) {}
if (labels.rows <= 0) {
cerr << "ERROR: Couldn't load trained data from "
"[trainedModel.yml]!" << endl;
exit(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
画龙点睛:制作漂亮的交互式 GUI
尽管本章到目前为止给出的代码对于整个人脸识别系统已经足够了,但仍然需要一种将数据放入系统中以及使用它的方法。 许多用于研究的人脸识别系统会选择理想的输入作为文本文件,列出静态图像文件在计算机上的存储位置,以及其他重要数据,例如人的真实姓名或身份以及区域的真实像素坐标。 面部表情(例如面部和眼睛中心实际位置的真实情况)。 这可以由另一个人脸识别系统手动收集。
理想的输出将是一个文本文件,将识别结果与基本事实进行比较,以便获得统计信息以将人脸识别系统与其他人脸识别系统进行比较。
但是,由于本章中的人脸识别系统是为学习和实际娱乐目的而设计的,而不是与最新的研究方法竞争,因此拥有一个易于使用的 GUI 来进行人脸收集,训练和测试的界面很有用 ,通过网络摄像头实时进行交互。 因此,本节将提供提供这些功能的交互式 GUI。 希望读者使用本书随附的提供的 GUI,或者出于自己的目的修改 GUI,或者忽略此 GUI 并设计自己的 GUI 以执行到目前为止讨论的人脸识别技术。
由于我们需要 GUI 来执行多个任务,因此让我们创建 GUI 所具有的一组模式或状态,并通过按钮或鼠标单击来让用户更改模式:
- 启动:此状态加载并初始化数据和网络摄像头。
- 检测:此状态检测面部并进行预处理,直到用户单击添加人员按钮。
- 收集:此状态收集当前人的脸部,直到用户单击窗口中的任何位置。 这也显示了每个人的最新面孔。 用户单击现有人员之一或单击添加人员按钮,以收集不同人员的面孔。
- 训练:在这种状态下,借助所有被收集人员的所有被收集面孔对系统进行训练。
- 识别:这包括突出显示已识别的人并显示置信度表。 用户单击人员之一或单击添加人员按钮,以返回到模式 2(收藏夹)。
要退出,用户可以随时单击窗口中的Esc。 我们还添加一个删除全部模式以重新启动一个新的人脸识别系统,以及一个Debug按钮,以切换其他调试信息的显示。 我们可以创建一个枚举的mode变量来显示当前模式。
绘制 GUI 元素
要在屏幕上显示当前模式,让我们创建一个轻松绘制文本的功能。 OpenCV 带有带有多个字体和抗锯齿的cv::putText()函数,但是将文本放置在所需的正确位置可能很棘手。 幸运的是,还有一个cv::getTextSize()函数可以计算文本周围的边框,因此我们可以创建一个包装器函数,以使其更容易放置文本。 我们希望能够将文本沿窗口的任何边缘放置,并确保其完全可见,并且还允许将多行文本或多个单词彼此相邻放置而不会相互覆盖。 因此,这里有一个包装函数,可让您指定左对齐或右对齐,以及指定上对齐或下对齐,并返回边界框,因此我们可以轻松地在窗口的角落或边缘上绘制多行文本:
// Draw text into an image. Defaults to top-left-justified
// text, so give negative x coords for right-justified text,
// and/or negative y coords for bottom-justified text.
// Returns the bounding rect around the drawn text.
Rect drawString(Mat img, string text, Point coord, Scalar
color, float fontScale = 0.6f, int thickness = 1,
int fontFace = FONT_HERSHEY_COMPLEX);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在,要在 GUI 上显示当前模式,因为窗口的背景将是摄像机的提要,所以很可能如果我们仅在摄像机的提要上绘制文本,则其颜色可能与摄像机的背景颜色相同! 因此,让我们绘制一个黑色阴影,与要绘制的前景文本仅相距 1 像素。 让我们还在其下方绘制一条有用的文本行,以便用户知道要执行的步骤。 这是一个使用drawString()函数绘制一些文本的示例:
string msg = "Click [Add Person] when ready to collect faces.";
// Draw it as black shadow & again as white text.
float txtSize = 0.4;
int BORDER = 10;
drawString(displayedFrame, msg, Point(BORDER, -BORDER-2),
CV_RGB(0,0,0), txtSize);
Rect rcHelp = drawString(displayedFrame, msg, Point(BORDER+1,
-BORDER-1), CV_RGB(255,255,255), txtSize);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以下部分屏幕截图显示了 GUI 窗口底部的模式和信息,该模式和信息覆盖在摄像机图像的顶部:

我们提到需要一些 GUI 按钮,因此让我们创建一个函数来轻松绘制 GUI 按钮,如下所示:
// Draw a GUI button into the image, using drawString(). // Can give a minWidth to have several buttons of same width. // Returns the bounding rect around the drawn button. Rect drawButton(Mat img, string text, Point coord, int minWidth = 0) { const int B = 10; Point textCoord = Point(coord.x + B, coord.y + B); // Get the bounding box around the text. Rect rcText = drawString(img, text, textCoord, CV_RGB(0,0,0)); // Draw a filled rectangle around the text. Rect rcButton = Rect(rcText.x - B, rcText.y – B, rcText.width + 2*B, rcText.height + 2*B); // Set a minimum button width. if (rcButton.width < minWidth) rcButton.width = minWidth; // Make a semi-transparent white rectangle. Mat matButton = img(rcButton); matButton += CV_RGB(90, 90, 90); // Draw a non-transparent white border. rectangle(img, rcButton, CV_RGB(200,200,200), 1, CV_AA); // Draw the actual text that will be displayed. drawString(img, text, textCoord, CV_RGB(10,55,20)); return rcButton; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
现在,我们使用drawButton()函数创建几个可单击的 GUI 按钮,这些按钮将始终显示在 GUI 的左上方,如以下部分屏幕截图所示:

正如我们所提到的,GUI 程序具有一些模式(从有限模式机开始),它们从启动模式开始切换。 我们将当前模式存储为m_mode变量。
启动模式
在启动模式下,我们只需要加载 XML 检测器文件以检测人脸和眼睛并初始化网络摄像头(我们已经介绍过)。 让我们还创建一个带有鼠标回调函数的 GUI 主窗口,只要用户在窗口中移动或单击其鼠标,OpenCV 就会调用该窗口。 如果相机支持,则可能需要将相机分辨率设置为合理的值,例如640 x 480。 这样做如下:
// Create a GUI window for display on the screen.
namedWindow(windowName);
// Call "onMouse()" when the user clicks in the window.
setMouseCallback(windowName, onMouse, 0);
// Set the camera resolution. Only works for some systems.
videoCapture.set(CV_CAP_PROP_FRAME_WIDTH, 640);
videoCapture.set(CV_CAP_PROP_FRAME_HEIGHT, 480);
// We're already initialized, so let's start in Detection mode.
m_mode = MODE_DETECTION;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
检测模式
在“检测”模式下,我们要连续检测面部和眼睛,在它们周围绘制矩形或圆形以显示检测结果,并显示当前经过预处理的面部。 实际上,无论我们处于哪种模式,我们都希望它们显示。检测模式的唯一特殊之处在于,当用户单击添加人员按钮。
如果您还记得本章前面的检测步骤,那么检测阶段的输出将是:
Mat preprocessedFace:预处理过的脸部(如果检测到脸部和眼睛)Rect faceRect:检测到的面部区域坐标Point leftEye,rightEye:检测到的左右眼中心坐标
因此,我们应该检查是否返回了经过预处理的面部,如果检测到它们,请在面部和眼睛周围绘制一个矩形和圆形,如下所示:
bool gotFaceAndEyes = false; if (preprocessedFace.data) gotFaceAndEyes = true; if (faceRect.width > 0) { // Draw an anti-aliased rectangle around the detected face. rectangle(displayedFrame, faceRect, CV_RGB(255, 255, 0), 2, CV_AA); // Draw light-blue anti-aliased circles for the 2 eyes. Scalar eyeColor = CV_RGB(0,255,255); if (leftEye.x >= 0) { // Check if the eye was detected circle(displayedFrame, Point(faceRect.x + leftEye.x, faceRect.y + leftEye.y), 6, eyeColor, 1, CV_AA); } if (rightEye.x >= 0) { // Check if the eye was detected circle(displayedFrame, Point(faceRect.x + rightEye.x, faceRect.y + rightEye.y), 6, eyeColor, 1, CV_AA); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我们将在窗口的顶部中心覆盖当前的预处理面部,如下所示:
int cx = (displayedFrame.cols - faceWidth) / 2; if (preprocessedFace.data) { // Get a BGR version of the face, since the output is BGR. Mat srcBGR = Mat(preprocessedFace.size(), CV_8UC3); cvtColor(preprocessedFace, srcBGR, CV_GRAY2BGR); // Get the destination ROI. Rect dstRC = Rect(cx, BORDER, faceWidth, faceHeight); Mat dstROI = displayedFrame(dstRC); // Copy the pixels from src to dst. srcBGR.copyTo(dstROI); } // Draw an anti-aliased border around the face. rectangle(displayedFrame, Rect(cx-1, BORDER-1, faceWidth+2, faceHeight+2), CV_RGB(200,200,200), 1, CV_AA);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
以下屏幕截图显示了在“检测”模式下显示的 GUI。 预处理的脸部显示在顶部中心,并且检测到的脸部和眼睛被标记为:

收集模式
当用户单击添加人员按钮以表示他们要开始收集新人的面孔时,我们进入收集模式。 如前所述,我们将人脸收集限制为每秒一张人脸,然后才将其与以前收集的人脸相比发生了显着变化。 记住,我们决定不仅要收集经过预处理的脸部,还要收集经过预处理的脸部的镜像。
在“收集”模式下,我们要显示每个已知人物的最新面孔,并让用户单击其中一个人以向他们添加更多面孔,或单击添加人员按钮向集合中添加新人员。 用户必须单击窗口中间的某个位置才能继续到下一个(训练)模式。
因此,首先我们需要参考为每个人收集的最新面孔。 我们将通过更新大整数preprocessedFaces数组(即所有人的所有面孔的集合)中的m_latestFaces整数数组来完成此操作,该整数数组仅存储每个人的数组索引。 由于我们还将镜像的面存储在该数组中,因此我们要引用倒数第二个面,而不是最后一个面。 该代码应附加到代码上,该代码为preprocessedFaces数组添加新的面孔(和镜像的面孔),如下所示:
// Keep a reference to the latest face of each person.
m_latestFaces[m_selectedPerson] = preprocessedFaces.size() - 2;
- 1
- 2
我们只需要记住,无论何时添加或删除新人员(例如,由于用户单击添加人员按钮),都必须始终增大或缩小m_latestFaces数组。 现在,让我们在窗口的右侧(分别处于收集模式和稍后的识别模式)显示每个被收集人员的最新面孔,如下所示:
m_gui_faces_left = displayedFrame.cols - BORDER - faceWidth; m_gui_faces_top = BORDER; for (int i=0; i<m_numPersons; i++) { int index = m_latestFaces[i]; if (index >= 0 && index < (int)preprocessedFaces.size()) { Mat srcGray = preprocessedFaces[index]; if (srcGray.data) { // Get a BGR face, since the output is BGR. Mat srcBGR = Mat(srcGray.size(), CV_8UC3); cvtColor(srcGray, srcBGR, CV_GRAY2BGR); // Get the destination ROI int y = min(m_gui_faces_top + i * faceHeight, displayedFrame.rows - faceHeight); Rect dstRC = Rect(m_gui_faces_left, y, faceWidth, faceHeight); Mat dstROI = displayedFrame(dstRC); // Copy the pixels from src to dst. srcBGR.copyTo(dstROI); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
我们还想使用脸部周围的红色粗框突出显示当前正在收集的人。 这样做如下:
if (m_mode == MODE_COLLECT_FACES) {
if (m_selectedPerson >= 0 &&
m_selectedPerson < m_numPersons) {
int y = min(m_gui_faces_top + m_selectedPerson *
faceHeight, displayedFrame.rows –
faceHeight);
Rect rc = Rect(m_gui_faces_left, y, faceWidth,
faceHeight);
rectangle(displayedFrame, rc, CV_RGB(255,0,0), 3,
CV_AA);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以下部分屏幕截图显示了收集到多个人的面孔后的典型显示。 用户可以单击右上角的任何人,以收集该人的更多面孔。

训练模式
当用户最终在窗口中间单击时,人脸识别算法将开始对所有收集的面部进行训练。 但重要的是要确保收集到足够的面孔或人,否则程序可能会崩溃。 通常,这仅需要确保训练集中至少有一张脸(这意味着至少有一个人)。 但是 Fisherfaces 算法会寻找人与人之间的比较,因此,如果训练集中的人数少于两个,它也会崩溃。 因此,我们必须检查所选的人脸识别算法是否为 Fisherfaces。 如果是这样,那么我们至少需要两个人的脸,否则,我们至少需要一个人的脸。 如果没有足够的数据,则程序将返回“收集”模式,以便用户可以在训练之前添加更多的面孔。
要检查是否至少有两个人有收集的面孔,我们可以确保当用户单击添加人员按钮时,仅当没有空人时才添加新人( 是被添加但尚未收集到任何面孔的人)。 然后,我们还可以确保如果只有两个人并且正在使用 Fisherfaces 算法,则必须确保在收集模式期间为最后一个人设置了m_latestFaces引用。 当尚未向该人添加任何面孔时,m_latestFaces[i]初始化为-1,然后在添加该人的面孔后将其变为0或更高。 这样做如下:
// Check if there is enough data to train from. bool haveEnoughData = true; if (!strcmp(facerecAlgorithm, "FaceRecognizer.Fisherfaces")) { if ((m_numPersons < 2) || (m_numPersons == 2 && m_latestFaces[1] < 0) ) { cout << "Fisherfaces needs >= 2 people!" << endl; haveEnoughData = false; } } if (m_numPersons < 1 || preprocessedFaces.size() <= 0 || preprocessedFaces.size() != faceLabels.size()) { cout << "Need data before it can be learnt!" << endl; haveEnoughData = false; } if (haveEnoughData) { // Train collected faces using Eigenfaces or Fisherfaces. model = learnCollectedFaces(preprocessedFaces, faceLabels, facerecAlgorithm); // Now that training is over, we can start recognizing! m_mode = MODE_RECOGNITION; } else { // Not enough training data, go back to Collection mode! m_mode = MODE_COLLECT_FACES; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
训练可能需要几分之一秒,也可能需要几秒钟甚至几分钟,这取决于收集了多少数据。 一旦完成对收集到的面部的训练,人脸识别系统将自动进入识别模式。
识别模式
在识别模式下,在经过预处理的人脸旁边会显示一个置信度计,因此用户知道识别的可靠性。 如果置信度高于未知阈值,它将在识别的人周围绘制一个绿色矩形,以轻松显示结果。 如果用户单击添加人员按钮或现有人员之一,则可以添加更多面部以进行进一步的训练,这会使程序返回到“收集”模式。
现在,我们已经获得了与先前提到的重建脸部的识别身份和相似性。 要显示置信度表,我们知道 L2 相似度值通常对于高置信度在 0 到 0.5 之间,对于低置信度在 0.5 到 1.0 之间,因此我们可以从 1.0 中减去它来获得 0.0 到 1.0 之间的置信度。 然后,我们仅使用置信度水平作为如下所示的比率绘制一个填充的矩形:
int cx = (displayedFrame.cols - faceWidth) / 2; Point ptBottomRight = Point(cx - 5, BORDER + faceHeight); Point ptTopLeft = Point(cx - 15, BORDER); // Draw a gray line showing the threshold for "unknown" people. Point ptThreshold = Point(ptTopLeft.x, ptBottomRight.y - (1.0 - UNKNOWN_PERSON_THRESHOLD) * faceHeight); rectangle(displayedFrame, ptThreshold, Point(ptBottomRight.x, ptThreshold.y), CV_RGB(200,200,200), 1, CV_AA); // Crop the confidence rating between 0 to 1 to fit in the bar. double confidenceRatio = 1.0 - min(max(similarity, 0.0), 1.0); Point ptConfidence = Point(ptTopLeft.x, ptBottomRight.y - confidenceRatio * faceHeight); // Show the light-blue confidence bar. rectangle(displayedFrame, ptConfidence, ptBottomRight, CV_RGB(0,255,255), CV_FILLED, CV_AA); // Show the gray border of the bar. rectangle(displayedFrame, ptTopLeft, ptBottomRight, CV_RGB(200,200,200), 1, CV_AA);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
为了突出显示已识别的人,我们在他们的脸周围绘制了一个绿色矩形,如下所示:
if (identity >= 0 && identity < 1000) {
int y = min(m_gui_faces_top + identity * faceHeight,
displayedFrame.rows - faceHeight);
Rect rc = Rect(m_gui_faces_left, y, faceWidth, faceHeight);
rectangle(displayedFrame, rc, CV_RGB(0,255,0), 3, CV_AA);
}
- 1
- 2
- 3
- 4
- 5
- 6
以下部分屏幕截图显示了在“识别”模式下运行时的典型显示,在顶部中间位置的预处理过的面孔旁边显示了置信度计,并在右上角突出显示了被识别的人。

检查和处理鼠标单击
现在我们已经绘制了所有 GUI 元素,我们只需要处理鼠标事件。 初始化显示窗口时,我们告诉 OpenCV 我们想要鼠标事件回调到onMouse函数。 我们不在乎鼠标的移动,仅关心鼠标的单击,因此首先我们跳过不是鼠标左键单击所不涉及的鼠标事件,如下所示:
void onMouse(int event, int x, int y, int, void*)
{
if (event != CV_EVENT_LBUTTONDOWN)
return;
Point pt = Point(x,y);
... (handle mouse clicks) ...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在绘制按钮时获得绘制的矩形边界时,我们只需调用 OpenCV 的inside()函数来检查鼠标单击位置是否在我们的任何按钮区域中。 现在我们可以检查我们创建的每个按钮。
当用户单击添加人员按钮时,我们只需向m_numPersons变量添加 1,在m_latestFaces变量中分配更多空间,选择要收集的新人员,然后开始收集模式(不管我们以前处于哪种模式)。
但是有一个并发症。 为确保训练时每个人至少有一张脸,我们只会在新人没有面孔的情况下为新人分配空间。 这将确保我们始终可以检查m_latestFaces[m_numPersons-1]的值,以查看是否已为每个人收集了一张脸。 这样做如下:
if (pt.inside(m_btnAddPerson)) {
// Ensure there isn't a person without collected faces.
if ((m_numPersons==0) ||
(m_latestFaces[m_numPersons-1] >= 0)) {
// Add a new person.
m_numPersons++;
m_latestFaces.push_back(-1);
}
m_selectedPerson = m_numPersons - 1;
m_mode = MODE_COLLECT_FACES;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
此方法可用于测试其他按钮的单击情况,例如如下切换调试标志:
else if (pt.inside(m_btnDebug)) {
m_debug = !m_debug;
}
- 1
- 2
- 3
要处理删除全部按钮,我们需要清空主循环本地的各种数据结构(即,无法从鼠标事件回调函数访问),因此我们将其更改为删除全部模式,然后我们可以从主循环中删除所有内容。 我们还必须处理用户单击主窗口(即不是按钮)的问题。 如果他们单击右侧的某个人,则我们要选择该人并切换到“收集”模式。 或者,如果他们在“收集”模式下在主窗口中单击,则我们想更改为“训练”模式。 这样做如下:
else { // Check if the user clicked on a face from the list. int clickedPerson = -1; for (int i=0; i<m_numPersons; i++) { if (m_gui_faces_top >= 0) { Rect rcFace = Rect(m_gui_faces_left, m_gui_faces_top + i * faceHeight, faceWidth, faceHeight); if (pt.inside(rcFace)) { clickedPerson = i; break; } } } // Change the selected person, if the user clicked a face. if (clickedPerson >= 0) { // Change the current person & collect more photos. m_selectedPerson = clickedPerson; m_mode = MODE_COLLECT_FACES; } // Otherwise they clicked in the center. else { // Change to training mode if it was collecting faces. if (m_mode == MODE_COLLECT_FACES) { m_mode = MODE_TRAINING; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
总结
本章介绍了创建实时人脸识别应用所需的所有步骤,并进行了充分的预处理,仅使用基本算法即可对训练设置条件和测试设置条件进行一些区别。 我们使用人脸检测来找到人脸在相机图像中的位置,然后进行多种形式的人脸预处理,以减少不同光照条件,相机和人脸方向以及人脸表情的影响。 然后,我们使用收集到的经过预处理的面部训练了 Eigenfaces 或 Fisherfaces 机器学习系统,最后,我们进行了人脸识别,以了解该人是谁,并通过面部验证提供了一个可信度度量(如果该人是未知人)。
我们没有提供以离线方式处理图像文件的命令行工具,而是将前面的所有步骤组合为一个独立的实时 GUI 程序,以允许立即使用人脸识别系统。 您应该能够根据自己的目的修改系统的行为,例如允许自动登录计算机,或者如果您对提高识别可靠性感兴趣,那么您可以阅读有关人脸识别最新进展的会议论文以,来改进程序的每个步骤,直到它足以满足您的特定需求为止。 例如,您可以根据这个页面和这个页面中的方法,改善面部预处理阶段,或使用更高级的机器学习算法,甚至使用更好的面部验证算法。
参考
Rapid Object Detection using a Boosted Cascade of Simple Features, P. Viola and M.J. Jones, Proceedings of the IEEE Transactions on CVPR 2001, Vol. 1, pp. 511-518
An Extended Set of Haar-like Features for Rapid Object Detection, R. Lienhart and J. Maydt, Proceedings of the IEEE Transactions on ICIP 2002, Vol. 1, pp. 900-903
Face Description with Local Binary Patterns: Application to Face Recognition, T. Ahonen, A. Hadid and M. Pietikäinen, Proceedings of the IEEE Transactions on PAMI 2006, Vol. 28, Issue 12, pp. 2037-2041
Learning OpenCV: Computer Vision with the OpenCV Library, G. Bradski and A. Kaehler, pp. 186-190, O'Reilly Media.
Eigenfaces for recognition, M. Turk and A. Pentland, Journal of Cognitive Neuroscience 3, pp. 71-86
Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection, P.N. Belhumeur, J. Hespanha and D. Kriegman, Proceedings of the IEEE Transactions on PAMI 1997, Vol. 19, Issue 7, pp. 711–720
Face Recognition with Local Binary Patterns, T. Ahonen, A. Hadid and M. Pietikäinen, Computer Vision - ECCV 2004, pp. 469–48
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13


{kind=link}