- 1基于springboot+vue的医院信息管理系统_springboot+vue医院管理系统
- 2代码随想录day1-二分查找_代码随想录 二分查找
- 36.设计模式之代理模式Proxy_软件设计模式代理模式proxy
- 4【区块链与密码学】第2-5讲:区块链基础技术大剖析之共识算法(一)_区块链与密码学课件 何德彪
- 5Oracle中的时间戳转换操作_oracle时间戳转换成时间
- 6决定不卷了,入职字节测试岗一周果断离职....
- 7C语言---Xiyou_Linux2023纳新题解 -----详细版
- 8freeswitch tts_commandline模块介绍_freeswitchmodttscommandline
- 9Win10下python3和python2多版本同时安装并解决pip共存问题_同时安装python2和python3
- 10广城云服务抓包(Charles抓包)_云函数抓包
Optimization and Indexes_for comparisons of a string column with
赞
踩
Primary Key Optimization 8.3.2
The primary key for a table represents the column or set of columns that you use in your most vital
queries. It has an associated index, for fast query performance. Query performance benefits from
the NOT NULL optimization, because it cannot include any NULL values. With the InnoDB storage
engine, the table data is physically organized to do ultra-fast lookups and sorts based on the primary
key column or columns.
If your table is big and important, but does not have an obvious column or set of columns to use as a
primary key, you might create a separate column with auto-increment values to use as the primary key.
These unique IDs can serve as pointers to corresponding rows in other tables when you join tables
using foreign keys.
表的主键代表您最重要的列或一组列 查询。 它具有关联的索引,可提高查询性能。 查询性能受益于 NOT NULL优化,因为它不能包含任何NULL值。
使用InnoDB存储 引擎,物理上组织表数据以基于主数据库进行超快速查找和排序 关键列。 如果您的表又大又重要,但没有明显的列或一组列可以用作 主键,
则可以创建一个具有自动增量值的单独列以用作主键。 当您联接表时,这些唯一的ID可用作指向其他表中相应行的指针使用外键
Foreign Key Optimization 8.3.3
If a table has many columns, and you query many different combinations of columns, it might be
efficient to split the less-frequently used data into separate tables with a few columns each, and relate
them back to the main table by duplicating the numeric ID column from the main table. That way,
each small table can have a primary key for fast lookups of its data, and you can query just the set of
columns that you need using a join operation. Depending on how the data is distributed, the queries
might perform less I/O and take up less cache memory because the relevant columns are packed
together on disk. (To maximize performance, queries try to read as few data blocks as possible from
disk; tables with only a few columns can fit more rows in each data block.
如果一个表有许多列,并且您查询许多不同的列组合,则可能是可以将不常用的数据分割成单独的表,每个表有几列,并进行关联
通过复制主表中的数字ID列将它们返回到主表。 那样,每个小表可以有一个主键来快速查找其数据,并且您可以只查询一组
使用联接操作所需的列。 根据数据的分布方式,查询可能执行较少的I / O并占用较少的缓存,因为相关列已打包
一起在磁盘上。 (为了最大限度地提高性能,查询尝试从磁盘读取尽可能少的数据块;
只有几列的表可以在每个数据块中容纳更多的行
Column Indexes 8.3.4
The most common type of index involves a single column, storing copies of the values from that
column in a data structure, allowing fast lookups for the rows with the corresponding column values.
The B-tree data structure lets the index quickly find a specific value, a set of values, or a range of
values, corresponding to operators such as =, >, ≤, BETWEEN, IN, and so on, in a WHERE clause.
索引的最常见类型涉及单个列,将来自该列的值的副本存储在数据结构中,从而允许快速查找具有相应列值的行。
B树数据结构使索引可以在WHERE子句中快速找到特定值,一组值或范围值,这些值对应于=,>,≤,BETWEEN,IN等运算符
Index Prefixes
With col_name(N) syntax in an index specification for a string column, you can create an index that uses only the first N characters of the column. Indexing only a prefix of column values in this way can
make the index file much smaller. When you index a BLOB or TEXT column, you must specify a prefix length for the index
使用字符串列的索引规范中的col_name(N)语法,可以创建仅使用该列的前N个字符的索引。 以这种方式仅索引列值的前缀可以
使索引文件小得多。 对BLOB或TEXT列建立索引时,必须为索引指定前缀长度
CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)));Prefixes can be up to 1000 bytes long (767 bytes for InnoDB tables, unless you have innodb_large_prefix set)
FULLTEXT Indexes
FULLTEXT indexes are used for full-text searches. Only the InnoDB and MyISAM storage engines support FULLTEXT indexes and only for CHAR, VARCHAR, and TEXT columns. Indexing always takes place over the entire column and column prefix indexing is not supported
FULLTEXT索引用于全文搜索。 仅InnoDB和MyISAM存储引擎支持FULLTEXT索引,并且仅支持CHAR,VARCHAR和TEXT列。 索引总是在整个列上进行,并且不支持列前缀索引.
Spatial Indexes
You can create indexes on spatial data types. MyISAM and InnoDB support R-tree indexes on spatial types. Other storage engines use B-trees for indexing spatial types (except for ARCHIVE, which does
not support spatial type indexing).
您可以在空间数据类型上创建索引。 MyISAM和InnoDB支持空间类型上的R树索引。 其他存储引擎使用B树来索引空间类型(ARCHIVE除外,
不支持空间类型索引)。
Multiple-Column Indexes 8.3.5
MySQL can create composite indexes (that is, indexes on multiple columns). An index may consist
of up to 16 columns. For certain data types, you can index a prefix of the column.
MySQL can use multiple-column indexes for queries that test all the columns in the index, or queries
that test just the first column, the first two columns, the first three columns, and so on. If you specify the
columns in the right order in the index definition, a single composite index can speed up several kinds of queries on the same table.
A multiple-column index can be considered a sorted array, the rows of which contain values that are created by concatenating the values of the indexed columns.
MySQL可以创建复合索引(即,多列上的索引)。 索引可能包括最多16列。 对于某些数据类型,您可以创建前缀索引。
MySQL可以将多列索引用于测试索引中所有列的查询或查询
该测试仅测试第一列,前两列,前三列,依此类推。 如果您指定
在索引定义中以正确的顺序排列列时,单个组合索引可以加快对同一表的几种查询。
多列索引可以被认为是排序数组,其行包含通过串联索引列的值而创建的值。
- If the table has a multiple-column index, any leftmost prefix of the index can be used by the optimizer
- to look up rows. For example, if you have a three-column index on (col1, col2, col3), you have
- indexed search capabilities on (col1), (col1, col2), and (col1, col2, col3).
如果表具有多列索引,那么优化器可以使用索引的任何最左前缀查找行。
例如,如果在(col1,col2,col3)上有一个三列索引,则(col1),(col1,col2)和(col1,col2,col3)上的索引搜索功能。
Comparison of B-Tree and Hash Indexes
B-Tree Index Characteristics
A B-tree index can be used for column comparisons in expressions that use the =, >, >=, <, <=, or
BETWEEN operators. The index also can be used for LIKE comparisons if the argument to LIKE is a constant string that does not start with a wildcard character
B树索引可用于使用=,>,> =,<,<= 或 BETWEEN 。 如果LIKE的参数是不以通配符开头的常量字符串,则索引也可以用于LIKE比较
会使用索引
- SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';
- SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';
不会使用索引
SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%';Hash Index Characteristics
Hash indexes have somewhat different characteristics from those just discussed:
• They are used only for equality comparisons that use the = or <=> operators (but are very fast). They
are not used for comparison operators such as < that find a range of values. Systems that rely on
this type of single-value lookup are known as “key-value stores”; to use MySQL for such applications,
use hash indexes wherever possible.
• The optimizer cannot use a hash index to speed up ORDER BY operations. (This type of index cannot
be used to search for the next entry in order.)
• MySQL cannot determine approximately how many rows there are between two values (this is used
by the range optimizer to decide which index to use). This may affect some queries if you change a
MyISAM or InnoDB table to a hash-indexed MEMORY table.
• Only whole keys can be used to search for a row. (With a B-tree index, any leftmost prefix of the key
can be used to find rows.)
哈希索引与刚刚讨论的索引具有一些不同的特征:
•它们仅用于使用=或<=>运算符的相等比较(但非常快)。 他们
不用于比较运算符,例如<用来查找值范围的比较运算符。 依赖的系统
这种类型的单值查找称为“键值存储”; 将MySQL用于此类应用程序,
尽可能使用哈希索引。
•优化器无法使用哈希索引来加快ORDER BY操作。 (此索引类型不能用于按顺序搜索下一个条目。)
•MySQL无法确定两个值之间大约有多少行(用于由范围优化器决定要使用哪个索引)。 如果您更改一个,这可能会影响某些查询
将MyISAM或InnoDB表转换为哈希索引的MEMORY表。
•仅整个键可用于搜索行。 (使用B树索引,键的任何最左前缀可用于查找行。)
Use of Index Extensions 8.3.9
InnoDB automatically extends each secondary index by appending the primary key columns to it.
InnoDB通过将主键列附加到辅助索引来自动扩展每个辅助索引。
- CREATE TABLE t1 (
- i1 INT NOT NULL DEFAULT 0,
- i2 INT NOT NULL DEFAULT 0,
- d DATE DEFAULT NULL,
- PRIMARY KEY (i1, i2),
- INDEX k_d (d)
- ) ENGINE = InnoDB;
This table defines the primary key on columns (i1, i2). It also defines a secondary index k_d on
column (d), but internally InnoDB extends this index and treats it as columns (d, i1, i2).
The optimizer takes into account the primary key columns of the extended secondary index when
determining how and whether to use that index. This can result in more efficient query execution plans
and better performance.
The optimizer can use extended secondary indexes for ref, range, and index_merge index access,
for Loose Index Scan access, for join and sorting optimization, and for MIN()/MAX() optimization.
The following example shows how execution plans are affected by whether the optimizer uses
extended secondary indexes
MySQL InnoDB的二级索引(Secondary Index)会自动补齐主键,将主键列追加到二级索引列后面。
该表定义了列(i1,i2)上的主键。 它还在上定义了二级索引k_d 列(d),但InnoDB在内部扩展此索引并将其视为列(d,i1,i2)。 在以下情况下,优化器会考虑扩展二级索引的主键列: 确定如何以及是否使用该索引。 这可以导致更有效的查询执行计划 和更好的性能 优化程序可以使用扩展的二级索引来进行ref,range和index_merge索引访问, 用于宽松的索引扫描访问,用于连接和排序优化,以及用于MIN()/ MAX()优化。 以下示例显示了优化程序是否使用扩展二级索引如何影响执行计划
因此在设计主键的时候,常见的一条设计原则是要求主键字段尽量简短
- INSERT INTO t1 VALUES
- (1, 1, '1998-01-01'), (1, 2, '1999-01-01'),
- (1, 3, '2000-01-01'), (1, 4, '2001-01-01'),
- (1, 5, '2002-01-01'), (2, 1, '1998-01-01'),
- (2, 2, '1999-01-01'), (2, 3, '2000-01-01'),
- (2, 4, '2001-01-01'), (2, 5, '2002-01-01'),
- (3, 1, '1998-01-01'), (3, 2, '1999-01-01'),
- (3, 3, '2000-01-01'), (3, 4, '2001-01-01'),
- (3, 5, '2002-01-01'), (4, 1, '1998-01-01'),
- (4, 2, '1999-01-01'), (4, 3, '2000-01-01'),
- (4, 4, '2001-01-01'), (4, 5, '2002-01-01'),
- (5, 1, '1998-01-01'), (5, 2, '1999-01-01'),
- (5, 3, '2000-01-01'), (5, 4, '2001-01-01'),
- (5, 5, '2002-01-01');
Now consider this query:
EXPLAIN SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01'
In both cases, key indicates that the optimizer will use secondary index k_d but the EXPLAIN output shows these improvements from using the extended index:
• key_len goes from 4 bytes to 8 bytes, indicating that key lookups use columns d and i1, not just d.
• The ref value changes from const to const,const because the key lookup uses two key parts, not one.
• The rows count decreases from 5 to 1, indicating that InnoDB should need to examine fewer rows to produce the result.
• The Extra value changes from Using where; Using index to Using index. This means that
rows can be read using only the index, without consulting columns in the data row.
在这两种情况下,key都表明优化器将使用二级索引k_d,但是EXPLAIN输出显示了使用扩展索引的以下改进:
• key_len从4字节变为8字节,表明key查找使用的是d和i1,而不仅仅是d
• ref值从const变为const,const,因为键查找使用两个键部分,不是一个
• 行数从5减少到1,表明InnoDB应该需要检查的行数更少产生结果
• 额外值从使用where改变; 使用索引到使用索引。 这意味着可以仅使用索引读取行,而无需查阅数据行中的列
Differences in optimizer behavior for use of extended indexes can also be seen with SHOW STATUS:
还可以通过SHOW STATUS看到使用扩展索引的优化器行为的差异
- FLUSH TABLE t1;
- FLUSH STATUS;
- SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
- SHOW STATUS LIKE 'handler_read%'
The use_index_extensions flag of the optimizer_switch system variable permits control over whether the optimizer takes the primary key columns into account when determining how to use an InnoDB table's secondary indexes. By default, use_index_extensions is enabled. To check whether disabling use of index extensions will improve performance
Optimizer_switch系统变量的use_index_extensions标志允许控制在确定如何使用InnoDB表的二级索引时优化器是否考虑了主键列。 默认情况下,启用use_index_extensions。 检查禁用索引扩展是否可以提高性能
SHOW VARIABLES LIKE 'OPTIMIZER_SWITCH'SET optimizer_switch = 'use_index_extensions=off';

Use of index extensions by the optimizer is subject to the usual limits on the number of key parts in an
index (16) and the maximum key length (3072 bytes).

Optimizer Use of Generated Column Indexes 8.3.10
CREATE TABLE t2 (f1 INT, gc INT AS (f1 + 1) STORED, INDEX (gc));The generated column, gc, is defined as the expression f1 + 1. The column is also indexed and the optimizer can take that index into account during execution plan construction. In the following query,
the WHERE clause refers to gc and the optimizer considers whether the index on that column yields a more efficient plan
生成的列gc定义为表达式f1 +1。该列也已建立索引,优化器可以在执行计划构建期间考虑该索引。 在以下查询中,
WHERE子句引用gc,优化程序考虑该列上的索引是否产生更有效的计划
SELECT * FROM t2 WHERE gc = 900;
The optimizer can use indexes on generated columns to generate execution plans, even in the absence of direct references in queries to those columns by name. This occurs if the WHERE, ORDER BY, or GROUP BY clause refers to an expression that matches the definition of some indexed generated column. The following query does not refer directly to gc but does use an expression that matches the definition of gc.
- # 索引会启用作用
- SELECT * FROM t1 WHERE f1 + 1 = 900;
-
- # 索引不起作用
- SELECT * FROM t1 WHERE 1 + f1 = 900;
-
- # 索引不起作用
- SELECT * FROM t2 WHERE f1 + 1 = '900';
f1+1起作用
For a query expression to match a generated column definition, the expression must be identical and it must have the same result type.
为了使查询表达式与生成的列定义匹配,表达式必须相同并且它必须具有相同的结果类型

1+f1 不起作用
optimizer will not recognize a match if the query uses 1 + f1, or if f1 + 1 (an integer expression) is compared with a string.
如果查询使用1 + f1,或者将f1 + 1(整数表达式)与字符串进行比较,则优化器将无法识别匹配项.


The optimizer recognizes that the expression f1 + 1 matches the definition of gc and that gc is indexed, so it considers that index during execution plan construction.
优化器认识到表达式f1 +1与gc的定义匹配,并且gc已建立索引,因此它在执行计划构建期间会考虑该索引。
The optimization applies to these operators: =, <, <=, >, >=, BETWEEN, and IN().
For operators other than BETWEEN and IN(), either operand can be replaced by a matching generated column.
优化适用于以下运算符:=,<,<=,>,> =,BETWEEN和IN()。
对于BETWEEN和IN()以外的运算符,可以用匹配的生成列替换任何一个操作数。
没有使用表达式
The expression cannot consist of a simple reference to another column. For example, gc INT AS (f1) STORED consists only of a column reference, so indexes on gc are not considered.
该表达式不能包含对另一列的简单引用。 例如,gc INT AS(f1)STORED仅由列引用组成,因此不考虑gc上的索引。
CREATE TABLE t3 (f1 INT, gc INT AS (f1) STORED, INDEX (gc));会使用索引
- # 会使用索引
- SELECT * FROM t3 WHERE gc > 900;

不会使用索引
- # 不会使用索引
- SELECT * FROM t3 WHERE f1 > 900;

Indexed Lookups from TIMESTAMP Columns 8.3.11
Temporal values are stored in TIMESTAMP columns as UTC values, and values inserted into and
retrieved from TIMESTAMP columns are converted between the session time zone and UTC. (This is
the same type of conversion performed by the CONVERT_TZ() function. If the session time zone is
UTC, there is effectively no time zone conversion.)
时间值作为UTC值存储在TIMESTAMP列中,并将值插入到和从TIMESTAMP列检索的数据将在会话时区和UTC之间转换。
(这是与CONVERT_TZ()函数执行的转换类型相同。 如果会话时区是UTC,实际上没有时区转换。)
Due to conventions for local time zone changes such as Daylight Saving Time (DST), conversions between UTC and non-UTC time zones are not one-to-one in both directions. UTC values that are
distinct may not be distinct in another time zone. The following example shows distinct UTC values that become identical in a non-UTC time zone
由于诸如夏令时(DST)等本地时区更改的约定,UTC和非UTC时区之间的转换在两个方向上都不是一对一的。 UTC值是
与另一个时区不同。 以下示例显示了不同的UTC值,它们在非UTC时区中变得相同
- CREATE TABLE tstable (ts TIMESTAMP);
-
- SET time_zone = 'UTC'; -- insert UTC values
-
- INSERT INTO tstable VALUES
- ('2018-10-28 00:30:00'),('2018-10-28 01:30:00');
-
- SELECT ts FROM tstable;
-
- # 查看时区
- show variables like '%time_zone%';
默认时区


Note
To use named time zones such as 'MET' or 'Europe/Amsterdam', the time zone tables must be properly set up. For instructions, see Section 5.1.13, “MySQL Server Time Zone Support”.注意
要使用诸如“ MET”或“ Europe / Amsterdam”之类的时区,必须正确设置时区表。 有关说明,请参见第5.1.13节“ MySQL服务器时区支持”。
You can see that the two distinct UTC values are the same when converted to the 'MET' time zone. This phenomenon can lead to different results for a given TIMESTAMP column query, depending on whether the optimizer uses an index to execute the query.
Suppose that a query selects values from the table shown earlier using a WHERE clause to search the ts column for a single specific value such as a user-provided timestamp literal:
您会看到两个不同的UTC值在转换为“ MET”时区时是相同的。 对于给定的TIMESTAMP列查询,此现象可能导致不同的结果,具体取决于优化器是否使用索引来执行查询。
假设查询使用WHERE子句从前面显示的表中选择值,以在ts列中搜索单个特定值,例如用户提供的时间戳文字:
SELECT ts FROM tstable WHERE ts = 'literal';uppose further that the query executes under these conditions: The session time zone is not UTC and has a DST shift. For example:
进一步假设查询在以下条件下执行: 会话时区不是UTC,并且具有DST偏移。 例如:
SET time_zone = 'MET';Unique UTC values stored in the TIMESTAMP column are not unique in the session time zone due to DST shifts. (The example shown earlier illustrates how this can occur.)
The query specifies a search value that is within the hour of entry into DST in the session time zone.
由于DST偏移,存储在TIMESTAMP列中的唯一UTC值在会话时区中不是唯一的。 (前面显示的示例说明了这种情况的发生。)
该查询指定在会话时区中输入DST小时内的搜索值。
Under those conditions, the comparison in the WHERE clause occurs in different ways for nonindexed and indexed lookups and leads to different results:
If there is no index or the optimizer cannot use it, comparisons occur in the session time zone. The optimizer performs a table scan in which it retrieves each ts column value, converts it from UTC to the session time zone, and compares it to the search value (also interpreted in the session time zone):
在这些情况下,WHERE子句中的比较对于未索引和索引查找以不同的方式发生,并导致不同的结果:
如果没有索引或优化器无法使用它,则会在会话时区中进行比较。 优化器执行表扫描,其中检索每个ts列值,将其从UTC转换为会话时区,然后将其与搜索值(也在会话时区中解释)进行比较:
SELECT ts FROM tstable WHERE ts = '2018-10-28 02:30:00'; 
Because the stored ts values are converted to the session time zone, it is possible for the query to return two timestamp values that are distinct as UTC values but equal in the session time zone: One value that occurs before the DST shift when clocks are changed, and one value that was occurs after the DST shift.
由于已存储的ts值已转换为会话时区,因此查询有可能返回两个时间戳值,这些值与UTC值不同,但在会话时区中相等:更改时钟后,DST移位之前出现的一个值 ,以及DST移位后出现的一个值。
If there is a usable index, comparisons occur in UTC. The optimizer performs an index scan, first converting the search value from the session time zone to UTC, then comparing the result to the UTC index entries:
如果有可用的索引,则以UTC进行比较。 优化器执行索引扫描,首先将搜索值从会话时区转换为UTC,然后将结果与UTC索引条目进行比较:
- CREATE TABLE tstable1 (ts TIMESTAMP);
-
- SET time_zone = 'UTC'; -- insert UTC values
-
- INSERT INTO tstable1 VALUES
- ('2018-10-28 00:30:00'),('2018-10-28 01:30:00');
-
- ALTER TABLE tstable1 ADD INDEX (ts);
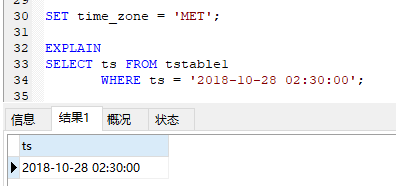
In this case, the (converted) search value is matched only to index entries, and because the index entries for the distinct stored UTC values are also distinct, the search value can match only one of them.
在这种情况下,(转换后的)搜索值仅与索引条目匹配,并且由于不同存储的UTC值的索引条目也不同,因此搜索值只能匹配其中之一。
Due to different optimizer operation for nonindexed and indexed lookups, the query produces different results in each case. The result from the nonindexed lookup returns all values that match in the session time zone.
由于针对非索引和索引查找的优化器操作不同,因此在每种情况下查询都会产生不同的结果。非索引查找的结果将返回在会话时区中匹配的所有值。
The indexed lookup cannot do so: It is performed within the storage engine, which knows only about UTC values.
索引查找不能这样做:仅在了解UTC值的存储引擎内执行。
For the two distinct session time zone values that map to the same UTC value, the indexed lookup matches only the corresponding UTC index entry and returns only a single row.
对于映射到相同UTC值的两个不同的会话时区值,索引查找仅匹配相应的UTC索引条目,并且仅返回单行。
In the preceding discussion, the data set stored in tstable happens to consist of distinct UTC values. In such cases, all index-using queries of the form shown match at most one index entry.
在前面的讨论中,存储在tstable中的数据集恰好由不同的UTC值组成。 在这种情况下,所示形式的所有使用索引的查询最多匹配一个索引条目。
If the index is not UNIQUE, it is possible for the table (and the index) to store multiple instances of a given UTC value. For example, the ts column might contain multiple instances of the UTC value '2018-10-28 00:30:00'. In this case, the index-using query would return each of them (converted to the MET value '2018-10-28 02:30:00' in the result set). It remains true that index-using queries match the converted search value to a single value in the UTC index entries, rather than matching multiple UTC values that convert to the search value in the session time zone.
如果索引不是UNIQUE,则表(和索引)可以存储给定UTC值的多个实例。 例如,ts列可能包含UTC值'2018-10-28 00:30:00'的多个实例。 在这种情况下,使用索引的查询将返回它们中的每一个(在结果集中转换为MET值'2018-10-28 02:30:00')。 仍然使用索引的查询将转换后的搜索值与UTC索引条目中的单个值进行匹配,而不是将在会话时区中转换为搜索值的多个UTC值进行匹配。
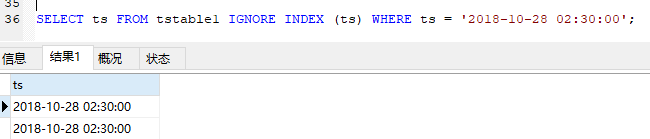
If it is important to return all ts values that match in the session time zone, the workaround is to suppress use of the index with an IGNORE INDEX hint:
如果返回在会话时区中匹配的所有ts值很重要,则解决方法是禁止使用索引(IGNORE INDEX):
SELECT ts FROM tstable1 IGNORE INDEX (ts) WHERE ts = '2018-10-28 02:30:00';