
热门标签
热门文章
- 1自定义hooks获取本地时间_大麦网hook改时间
- 2第三章 字典和集合_字典与集合
- 3手把手教你学51单片机-c语言版,手把手教你学51单片机(第2版 C语言版)
- 4【DELM回归预测】人工兔算法改进深度学习极限学习机ARO-DELM数据回归预测【含Matlab源码 3835期】_深度极限学习机
- 5聊聊c#与Python以及IronPython
- 6Oracle Exists、 NOT Exists用法
- 7神经网络python包_实现连续时间递归神经网络(CTRNNs)的Python包
- 8如何在 Ubuntu 12.10 上使用 Python 创建 Nagios 插件
- 9ESP32设备驱动-PCA9685 LED控制器驱动_pca9626驱动程序
- 102023数字化转型案例集锦
当前位置: article > 正文
MuseTalk如何生成高质量视频(使用技巧)_musetalk 的步骤
作者:凡人多烦事01 | 2024-05-19 20:58:21
赞
踩
musetalk 的步骤
环境:
MuseTalk 2024.4.2
GPU:英伟达4070 12G
问题描述:
MuseTalk如何生成高质量视频(使用技巧)
解决方案:
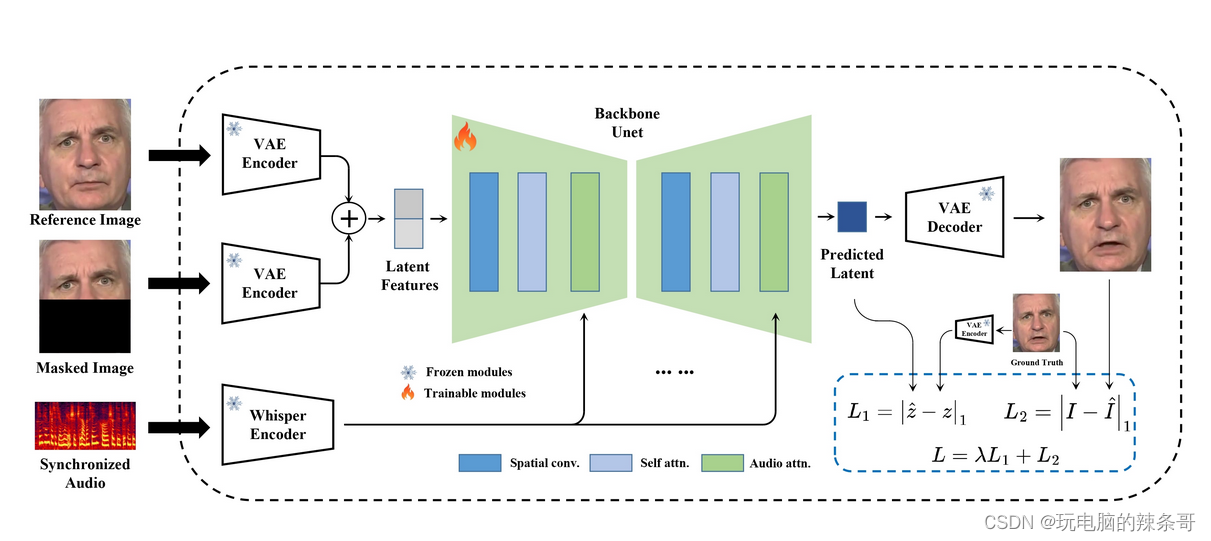
MuseTalk was trained in latent spaces, where the images were encoded by a freezed VAE. The audio was encoded by a freezed whisper-tiny model. The architecture of the generation network was borrowed from the UNet of the stable-diffusion-v1-4, where the audio embeddings were fused to the image embeddings by cross-attention.
MuseTalk在潜伏空间中进行训练,图像由冻结的VAE编码。音频由冻结 whisper-tiny 模型编码。生成网络的架构借鉴了 stable-diffusion-v1-4 的 UNet,其中音频嵌入通过交叉注意力融合到图像嵌入中。
Note that although we use a very similar architecture as Stable Diffusion, MuseTalk is distinct in that it is NOT a diffusion model. Instead, MuseTalk operates by inpainting in the latent space with a single
推荐阅读

相关标签

