
- 1MapReduce集群的安装与部署_mapreduce安装部署
- 2R语言上机例题_单位招聘2500人,按考试成绩从高到低依次录用,共有10000人报名,假设报名者的成绩
- 3Linux-解压缩文件命令(gzip、zip、unzip、tar、jar)_jar文件解压与压缩
- 4基于springboot生鲜交易商城微信小程序源码和论文
- 5【Hive---06】数据导入 与 数据导出_hive导出数据到本地
- 62024年网络安全最新网络安全学习笔记
- 7Django+uwsgi+nginx服务器部署后无法访问除首页外的其它页面_nginx django 打不开
- 8CSDN上该如何查看自己有多少积分?_csdn查看积分
- 9快速体验 Llama3 的 4 种方式,本地部署,800 tokens/s 的推理速度真的太快了!_llama 3 token就可以下各种软件输入你的token来操作了
- 10python linux运行环境,Linux平台Python运行环境配置
大数据毕业设计hadoop+spark+hive豆瓣图书数据分析可视化大屏 豆瓣图书爬虫 图书推荐系统 知识图谱 图书大数据 机器学习 计算机毕业设计 深度学习 人工智能_大数据专业毕业设计系统必须要增删改查吗
赞
踩
1.需求分析
1)系统总体目标
基于Spark的个性化书籍推荐系统是一种基于大数据技术的智能推荐系统,它可以根据用户的历史行为和偏好,为用户提供个性化的书籍推荐。该系统采用Spark技术,可以实现大数据的实时处理,从而提高推荐系统的准确性和可靠性。此外,该系统还可以根据用户的习惯和偏好,提供更加个性化的书籍推荐,从而满足用户的需求。
系统的使用者包含普通用户和管理员两类,普通用户是系统的主要服务对象,主流人群是经常查看书籍的互联网用户,这一类中以喜欢浏览书籍的年轻人群为主,同时也包括一部分其他年龄段的书籍爱好者;管理员是系统后台的管理者,负责管理书籍信息和用户信息,并在推荐和分类出现偏差时予以校正。
2)系统可行性分析
技术可行性:本系统采用Spark技术实现。Spark 是一种与 Hadoop 相似的开源集群计算环境,但 Spark 在部分工作负载方面表现得更加优越,更适合中小型系统,从使用场景和运算速度上说spark更适合本系统。Spark可以实现实时处理大量数据,提高推荐系统的准确性和可靠性,同时也可以支持多种推荐算法,如基于内容的推荐、基于协同过滤的推荐等,从而实现个性化的书籍推荐。
系统可行性:本系统采用Mysql数据库存储用户数据,使用SQL语句进行调用和分析,节约了大数据背景下对数据的提取的工作时间,提高了对书籍数据推荐工作的运转效率,有效地提高系统的运行速度,同时也可以满足用户的需求。
经济可行性:本系统采用开源技术,Mysql和Spark都是当今大数据技术方面比较主流的,开发和运营成本较低,同时能提高系统的可靠性和稳定性。
社会可行性:本系统可以满足用户对书籍的需求,提供个性化的书籍推荐,从而提高用户的阅读体验,同时也可以提高用户的阅读兴趣,促进社会文化的发展。
综上所述,本系统的技术方案具有较高的可行性,可以有效地满足用户的需求,促进社会文化的发展,无论从系统技术角度、经济运营角度还是社会文化角度都能迎合当今的形势和诉求。
3)系统需求分析
本系统的主要使用场景是:普通浏览查询书籍,并根据用户的浏览查询信息推荐用户可能喜欢的其他书籍;管理员用户在需要时,可以对系统进行管理,如修改和删除错误信息等。基于这个使用场景可以得到系统的基本需求如下:
用户的浏览需求:用户需要可以查看指定的书籍,网站需要为用户展示对应的书籍名称、作者等基本信息。同时用户的行为数据将被系统后台记录,作为分析用户喜好的依据,进而为用户推荐可能喜欢的其他书籍;
用户的推荐需求:这是本系统的核心。从上述浏览过程中产生的访问行为将经过后台分析,从而得出针对不同用户的个性化定制推荐列表,帮助用户找到其他相似的可能感兴趣的书。
后台管理需求:系统需要设置管理员,给运行留下一些容错,遇到系统本身无法处理的问题或者误区时,需要有管理员人工介入修正,因此系统除了面向普通用户的部分以外,还要有单独的管理员界面。
2.系统设计
1)总体架构设计
针对系统的总体需求分析,对系统的架构和模块进行设计。本系统使用Python爬虫技术爬取互联网上的图书信息,经过基本的数据预处理之后存入MySQL数据库;后端使用Java开发而成,使用SpringBoot开发框架,然后通过Spark技术处理进行推荐,推荐算法拟采用协同过滤算法和基于内容的推荐算法,最后将推荐结果给用户展示出来。
2)系统功能结构设计
本系统的实现功能包括:
数据采集模块:获得书籍的基本信息,采集用户的历史行为和偏好数据,将其存储在数据库中;
数据处理模块:使用Spark技术对数据进行实时处理,过滤、修正缺失和错误数据,统一数据格式;
推荐算法模块:根据用户的历史行为和偏好,提供个性化的书籍推荐,本系统主要使用基于内容的推荐算法和协同过滤推荐算法实现;
用户界面模块:提供友好的用户交互界面,方便用户对喜欢的书籍进行操作,产生用户行为数据用于精准推荐,并查看推荐结果;
管理员管理模块:提供书籍管理、用户管理、分类管理以及推荐管理功能。
3)系统详细设计
数据采集模块:数据的采集分为两个方面,一是获得书籍信息,二是获得用户行为记录。
对书籍信息的获取,本系统拟采用爬虫技术,从网络上抓取书籍的相关信息,目标网站为书籍评论网站(如豆瓣)和书籍购买网站(如当当网、淘宝网等),爬取数据包括书籍的名称、作者、出版社、出版时间、价格等;取得的数据存入MySQL中。这一步需要一些容错率,因为要受网站翻新、网络不稳定等情况的影响。考虑将爬虫做成分布式,将爬虫任务分发到多台服务器上,提高采集效率,降低单个机器或程序故障时对整个系统产生的负面影响。
对用户行为记录的获取,直接在系统的使用过程中记录用户的历史行为记录,并将其保存入用户行为表即可。
数据处理模块:将数据采集模块中获取的数据进行预处理。本系统涉及的两类数据中,用户行为记录是系统在运行过程中自行生成的,格式较为规范,无需预处理;书籍信息来自网站,爬取的内容可能存在问题,需要进行一定的预处理。预处理的具体内容包括:去除无效数据、修改错误数据(如超过边界值的数据等)、填补缺失数据,并将数据转换为Spark可以处理的格式等。
推荐算法模块:根据用户的历史行为和书籍的相关信息,计算出用户的推荐列表。用户在使用此功能时,系统会调出该账号的历史行为,并根据其历史行为获得推荐结果,展现在前端网页中,推荐结果直接链接到对应的书籍详情页面,用户可以直接单机跳转。
为了尽量克服各种推荐算法存在的问题,本系统拟采用2种推荐算法同步使用,相互补足。对于新用户或行为数据较少(本系统判断为5条以下)使用基于内容的推荐算法,对于老用户(本系统判断为行为数据5条以上)使用基于用户的协同过滤的推荐算法。推荐算法模块为系统的主要模块,其流程图如图3所示。
用户界面模块:设计用户界面,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择。界面不友好、操作步骤繁琐、缺乏逻辑等问题会使用户的学习、使用成本上升,使用体验受到负面影响,因此整个UI设计要朝简洁明确、符合大众使用逻辑的方向靠拢,可以考虑借鉴部分已成型知名网站的设计风格。
管理员管理模块:设计管理员管理模块,采用可视化的管理界面,完善系统内管理员用户的职能和工作逻辑,使管理员可以方便地对系统进行管理和维护。
3.算法设计
推荐系统的设计思路如下:
本系统的核心功能是推荐,解决数据的存取问题之后,下一步需要完善推荐算法。通过查阅相关文献和调查市面上相似的产品可知,根据推荐原理的不同,常见的推荐算法有:基于热度、社交网络、标签、人口统计学、内容、协同过滤等的推荐算法。其中,基于热度和标签的推荐算法过于笼统,不满足系统“个性化”的要求;基于社交网络、人口统计学的推荐算法更适合微博之类具有社交性的平台,在本系统中缺乏条件无法使用。对比之下,基于内容的推荐算法适合分析文本,在系统中可以通过书籍名称、标签类型分类等进行推荐,可以缓解冷启动问题,在面对新用户和新书籍的情况下依旧可以使用;基于协同过滤的推荐算法思路简明、搭建难度低,推荐效果好,在有大量用户行为数据的情况下优势十分明显。综上所述,基于内容的推荐算法和基于协同过滤的推荐算法最适合用于本系统中。
基于内容的推荐算法基于用户的历史行为和物品的特征来推荐相似的物品。其基本思想是:如果用户喜欢某个物品,那么该用户可能还喜欢与这个物品相似的物品。
基于内容的推荐算法通常会分析用户的历史行为和物品的特征,并将它们用向量表示。然后通过计算相似度来推荐相似的物品。系统可以分别对用户和产品建立配置文件(profile),通过分析已经购买或浏览过的商品内容,建立或更新用户的配置文件。系统可以比较用户与产品配置文件之间的相似度,并直接向用户推荐与其配置文件最相似的产品。该算法可以分析某位用户已经标记喜欢的书籍的共性,如作者(表明用户喜欢该作者的作品风格)、标题(如标题中都含有“心理学”则可以推荐其他心理学的书籍)等,进行精准的用户行为分析和推荐。
相似度的计算方式有很多种,比较主流的是欧式距离和余弦相似度两种。欧式距离即平面内两点的距离,对于平面内两点A(x1,y1)和B(x2,y2),其欧式距离即线段AB的长度。
余弦相似度更能反映两组数据的变动趋势,而欧式距离更能反映两者的数值差距。
该算法提炼共性有以下几种方法:直接对比登记信息(如作者、出版时间)和提炼关键词(从书名、作者等之中)。前者无需赘述,后者可通过对源内容的分词、出现频率统计得到该本书的内容关键词,中文分词相关的开源技术已经很多并且成熟,因此实现难度也较低。
基于用户的协同过滤推荐算法的基本原理是,根据所有用户对物品或者信息的偏好,对比产生与当前用户口味和偏好相似的“邻居”用户群。在本系统中,通过收集用户的历史行为(如对某个书籍的标记喜欢),发现用户和推荐对象之间的兴趣爱好关系,然后利用这种关系进行推荐。该算法是非常成熟的推荐算法,在商城推荐、音乐视频平台兴趣推荐等领域已得到广泛应用,可以找到大量的参考案例。
该算法以用户评分为基础构建数学模型,计算读者用户之间的相似度,将相似度高的读者用户作为相互的邻居用户,最后根据邻居用户的兴趣爱好找到邻居书籍,然后根据邻居书籍对读者进行书籍推荐.该算法主要有以下三个步骤:
1)构建读者-书籍评分矩阵;
2)计算相似度,根据需要选择合适的相似度计算方法,将用户对书籍的操作以评分形式展现,找到邻居用户。
3)根据与邻居用户的相似性对书籍进行评分预测,然后向目标用户推荐其没有阅读过的书籍。
协同过滤算法的算法步骤如下:
算法输入:用户行为日志。
算法输出:推荐列表。
1)对于用户u1,获取其行为信息,计算用户相似矩阵(相似度算法与前文基于内容的推荐算法相同);
2)依据相似度矩阵,找到与该用户u1最相似的另一位用户u2;
3)调取用户u2的行为日志,读取其浏览记录;
4)将二者行为日志进行比较,不重合的部分作为推荐结果输出。
基于内容的推荐算法只考虑物品的特征,对个人的兴趣偏好照顾不够,推荐结果不够精确,并且对大批量的数据使用较为乏力,这两点正是协同过滤算法的优势,协同过滤算法可以补足个性化和大批量的需求;同时,协同过滤算法虽然具有实现简单、自动化程度高、内容新颖等优点,但存在着稀疏性和冷启动问题。由于新用户缺少行为信息,新书籍和冷门书籍缺少被选信息,协同过滤算法无法使用,此时基于内容的推荐系统可以根据用户和产品的配置文件进行相应的推荐,避免出现冷门书籍一直冷门和新用户无法使用该系统的情况。综上所述,二者相互补足,推荐系统会更加完整,推荐结果更加智能。
毕业设计工作存在的问题及解决方案(不少于1000字)
在本系统的开发过程中,发现了一些问题,问题叙述及解决方案如下:
1.本系统的重点是推荐算法,两个推荐算法都高度依赖相似度的计算,而相似度是根据用户行为来的。用户的行为在某种程度上形成打分,不同的用户打分标准不同(有的人觉得还可以就给予反馈,有的人要到非常满意的程度才会给予反馈),推荐的结果就容易产生偏差。对于这种情况,可以考虑使用皮尔逊相关系数。皮尔逊相关系数通过用户平均分对每个独立评分进行修正,减少了用户评分偏置的影响,即将每个向量都减去他们的平均值后在计算余弦相似度。
2.将上面的问题进行反推:X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性。针对这种情况,考虑使用改良后的修正余弦相似度。调整的余弦相似度计算即用用户均值中心化后的向量进行余弦相似度计算,因为中心化后的值才相对真实反映用户的喜好,即把矩阵中的分数,减去对应用户分数的均值;先计算每一个用户的评分均值,然后把他打过的所有分数都减去这个均值——用户中心化。通过此种改良,可以对余弦相似度进行归一化处理。
下一步工作预测及可能存在的问题(不少于500字)
目前已有的两种推荐算法虽然在一定程度上已经可以相互补足,但在推荐的准确度上还有待改良,而且只能对已登录已有行为的用户进行推荐,对游客(未登录用户)等无法进行推荐。在目前的基于内容和协同过滤两种推荐算法基础上,可以采用深度学习技术进行改进,提高推荐结果的准确性和推荐效率。目前认为比较可行的是基于深度学习的序列推荐算法。
序列推荐是一种通过建模用户行为与项目在时间序列上的模式,以给用户推荐相关物品的一种推荐系统范式。序列推荐系统将交互行为按照时间次序依次排列,利用多种不同的建模方法挖掘其中的序列化模式,并用于支持下一时刻的一个或多个物品的推荐。序列推荐可以分为三类:
时序推荐指的是给定特定用户u在t时刻之前的历史行为序列,为其推荐下一个或者下一组用户所感兴趣的物品。这个原理体现在本书籍推荐系统里,就可以实现用户浏览了某书籍之后,系统就会推荐该书籍的第二部、姊妹篇等。
会话推荐则是在更短的时间内,比如根据用户上一本或上两本看过的书作出的迅速反应。在会话推荐中,一般序列长度较短,且无法关联更久远之前的用户历史交互行为。这可用于未登录用户的推荐实现。
第三种则是将上述两种混合使用,系统会考虑已登录用户的当前会话中的短期浏览行为与长期历史行为,进行综合推荐。

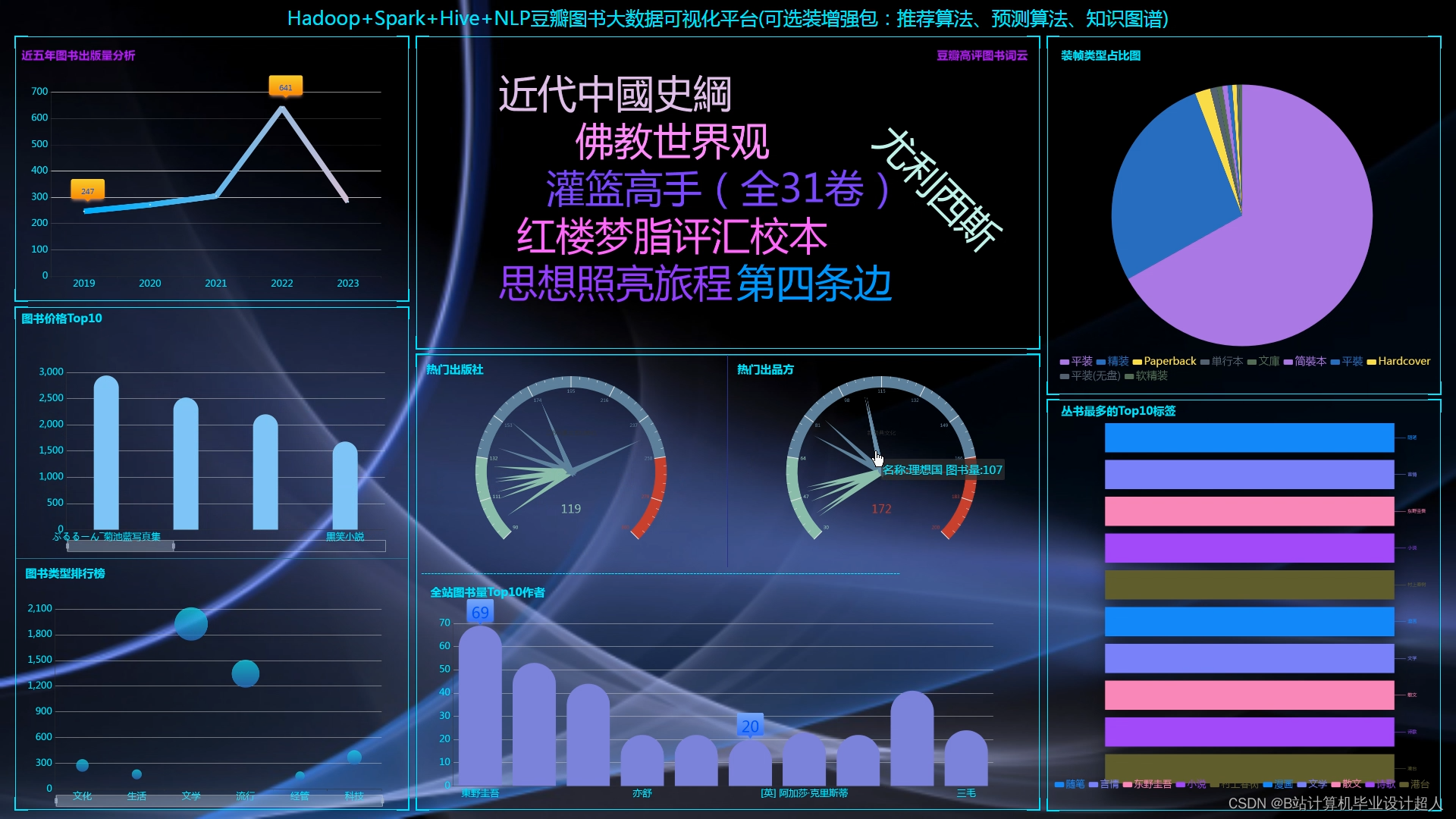
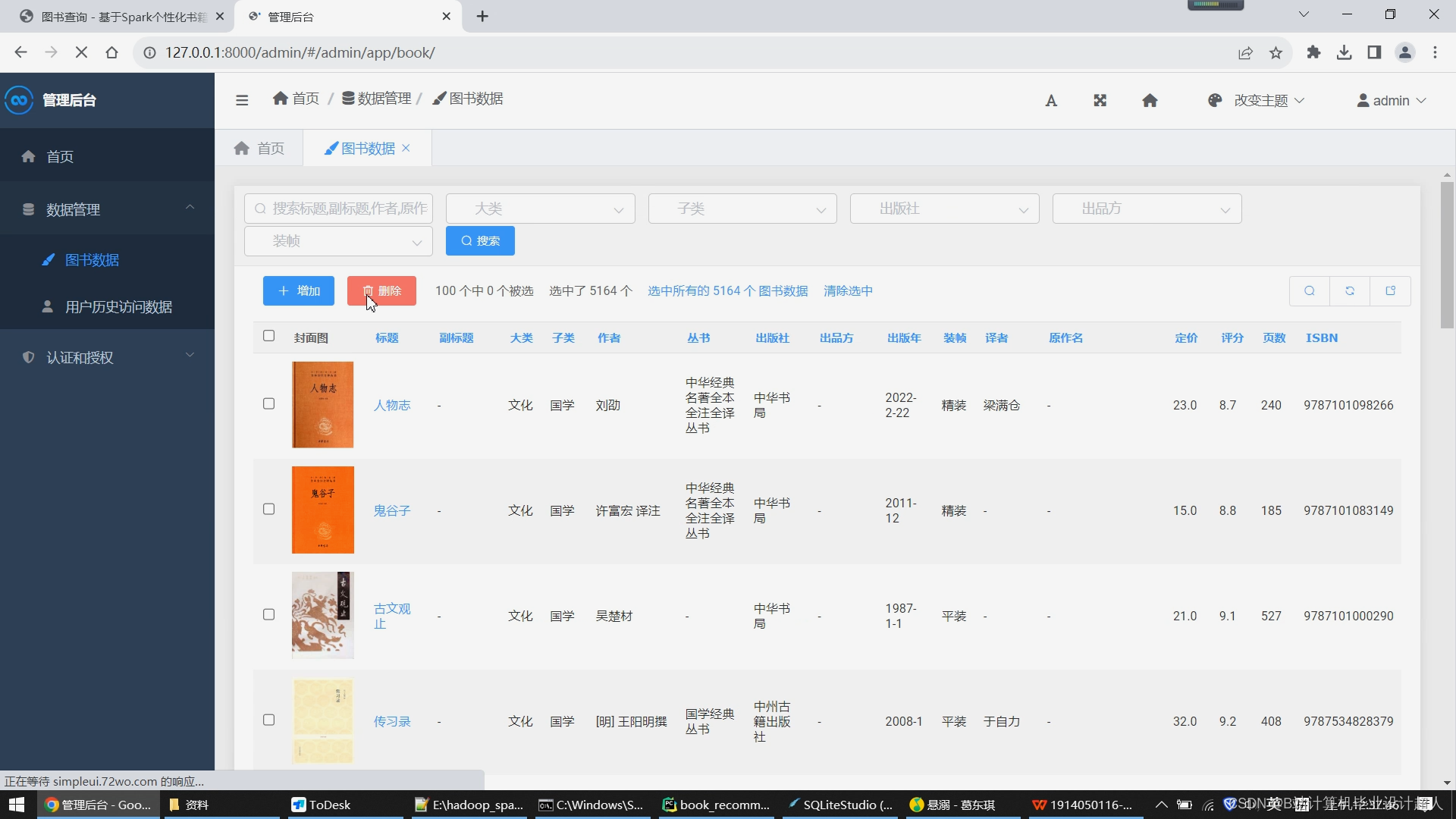
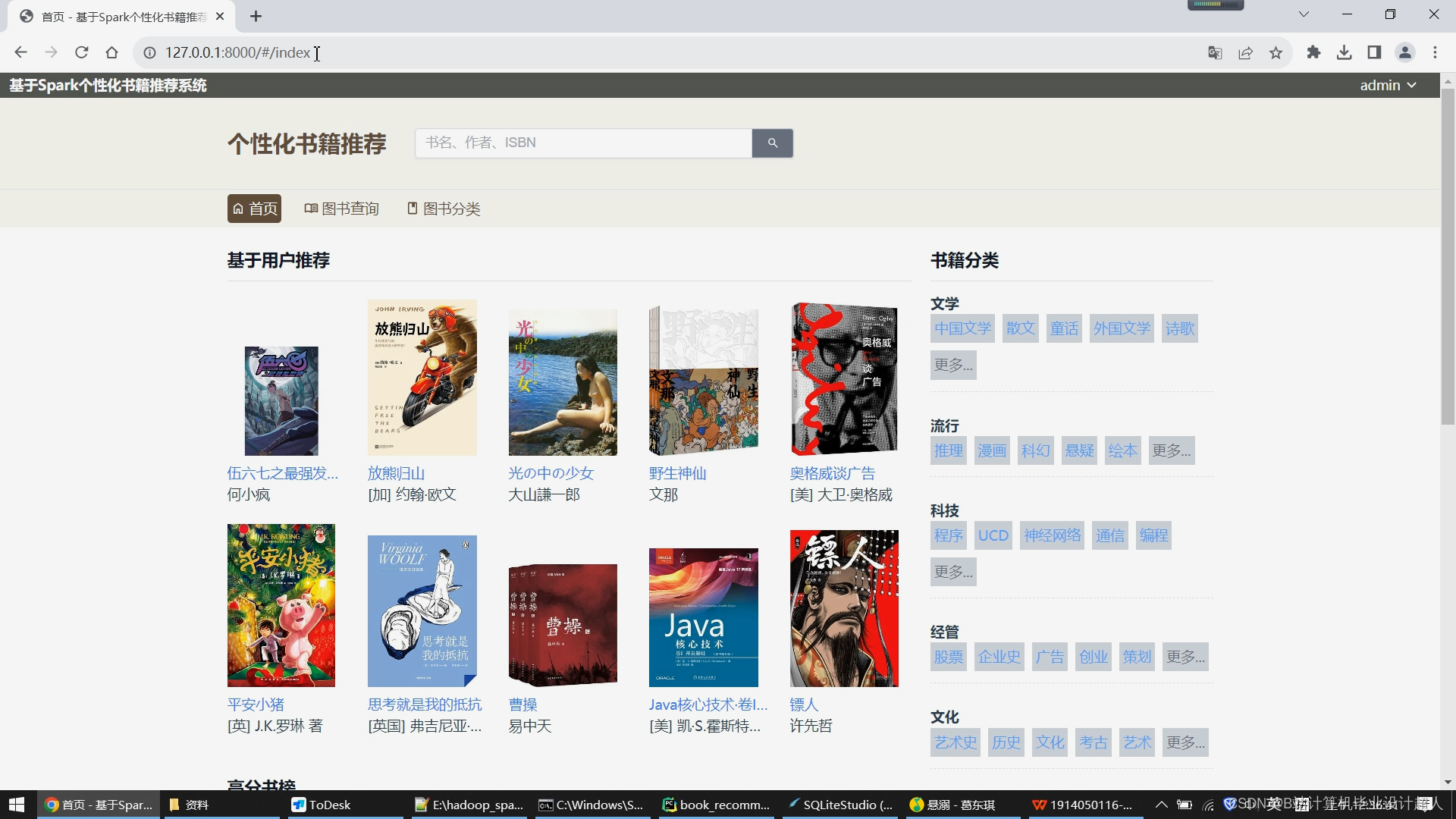
核心算法代码分享如下:
- import os
- import django
- from django.db import connection
- import pandas as pd
- import numpy as np
- from pyspark.sql import SparkSession
- from pyspark.sql.dataframe import DataFrame
- import pyspark.sql.functions as func
- from pyspark.mllib.recommendation import ALS
-
- spark = SparkSession.builder.getOrCreate()
- sc = spark.sparkContext
- sc.setLogLevel("ERROR")
-
- os.environ.setdefault("DJANGO_SETTINGS_MODULE", "book_recommend_system.settings")
- django.setup()
-
- sql = """
- SELECT
- u.id AS uid,
- b.id AS bid,
- count( h.id ) AS `rating`
- FROM
- book b,
- auth_user u
- LEFT JOIN history h ON h.user_id = uid
- AND h.book_id = bid
- GROUP BY
- bid,
- uid
- ORDER BY
- bid;
- """
- cursor = connection.cursor()
- cursor.execute(sql)
- columns = ("uid", "pid", "rating")
- rdd = sc.parallelize(cursor)
- model = ALS.train(rdd, 10)
- print([i.product for i in model.recommendProducts(3, 10)])
- # sdf: DataFrame = spark.createDataFrame(pdd, schema=columns)
- # # print(df)
- # # df.printSchema()
- # pivot: DataFrame = sdf.groupby("pid").pivot("uid").sum("rating").orderBy("pid")
- # cols, d = pivot.select()
- # pivot.show(5)


