
热门标签
热门文章
- 1Oracle数据库恢复时要建库吗_Oracle数据ASM实例不能mount怎么恢复数据
- 2Docker基础、进阶笔记,为k8s的学习预预热_下器好3ee5b1
- 3Kerberos安全认证-连载11-HBase Kerberos安全配置及访问_kerberos hbase(4)
- 4rabbitmq 清理消息队列 解决 启动消费者报错_由于队列不存在,启动消费者报错的这个问题
- 5vue videojs视频播放插件 动态资源
- 6Android13 适配指南_android 13适配
- 7Kimi创始人套现4000万美元疑云|「商汤」大模型一体机可节约80%推理成本,完成云端边全栈布局|中国AI活化石,熬成AIGC第一股| 谁在制造小米汽车?_月之暗面 推理成本
- 8python 主题5 字符串及正则表达式 单元作业_输入一个1000以内的正整数 n,在同一行内输出 [0,n] 之间各位数字之和为5的数,数字
- 9C++ 实现对战AI五子棋_c++五子棋实现ai下法
- 10别再分库分表了,试试TiDB!
当前位置: article > 正文
kafka搭建kraft集群模式_kafka kraft集群
作者:凡人多烦事01 | 2024-05-21 00:10:20
赞
踩
kafka kraft集群
kafka2.8之后不适用zookeeper进行leader选举,使用自己的controller进行选举
1.准备工作
准备三台服务器 192.168.3.110 192.168.3.111 192.168.3.112,三台服务器都要先安装好jdk1.8,配置好环境变量, 下载好kafka3.0.0二进制压缩包
解压后进入conf/kraft目录下,修改server.properties文件

2.修改配置文件
先修改110节点,主要修改下面的几个参数 node.id要唯一,跟leader选举有关系
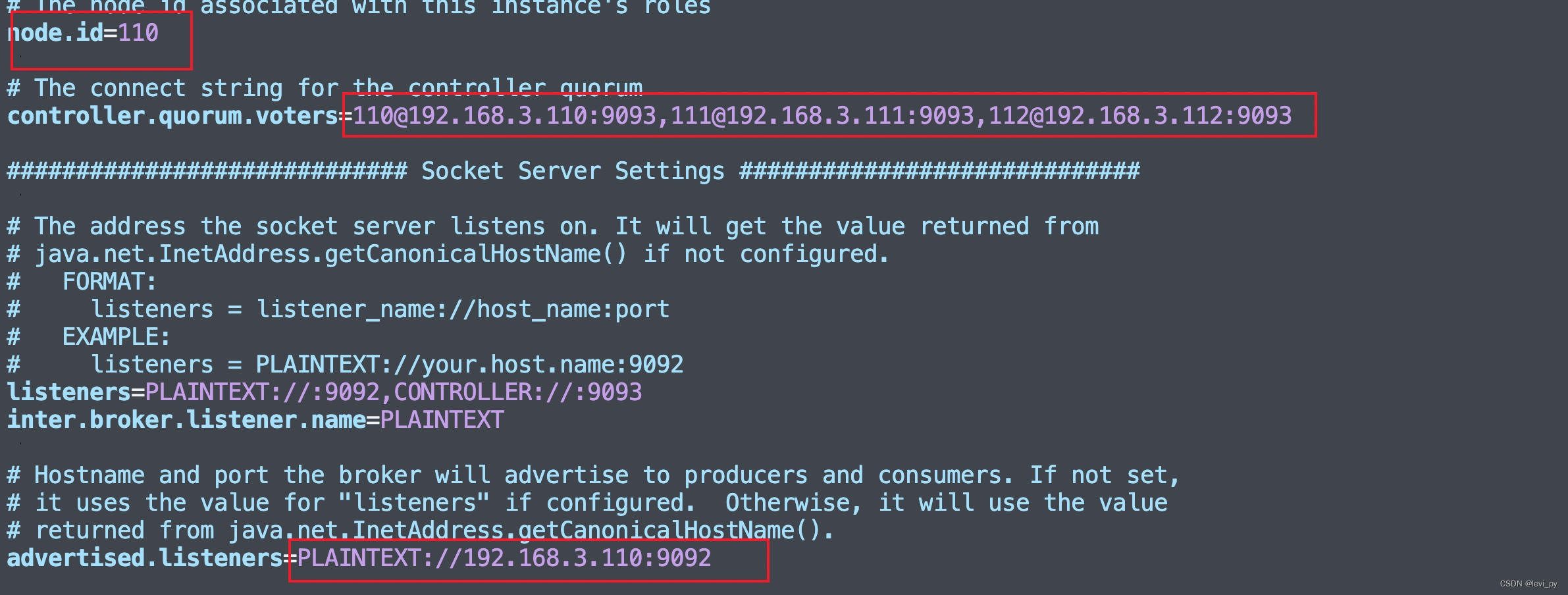
数据存储位置也要改一下
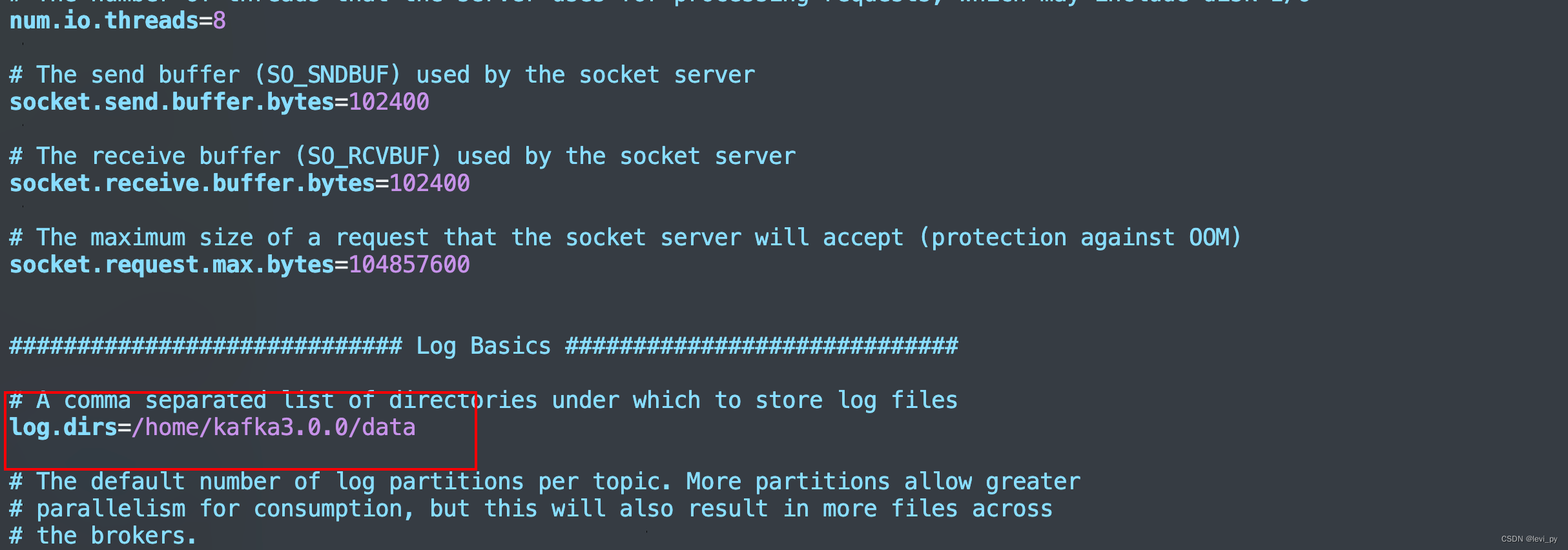
其他111和112服务器也按照改一下,把node.id改一下,ip也要改成对应的ip
3.初始化集群
在其中一台服务器上执行下面命令生成一个uuid
sh kafka3.0.0/bin/kafka-storage.sh random-uuid
- 1

用该uuid格式化kafka存储目录,三台服务器都要执行以下命令
sh kafka3.0.0/bin/kafka-storage.sh format -t 5Wr3UWh9SPGFUfX1WQlzAA -c kafka3.0.0/config/kraft/server.properties
- 1

三台服务器都启动kafka
sh kafka3.0.0/bin/kafka-server-start.sh -daemon kafka3.0.0/config/kraft/server.properties
- 1

集群启动之后,创还能一个tipic测试,在哪一台服务器上创建都行
sh kafka3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic kafka --partitions 3 --replication-factor 3
- 1

查看tipoc分区情况
sh kafka3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe kafka
- 1

这时候把111节点kafka关掉,会重新选举,从ar里面第一个,并且在isr中存活的副本成为leader,112成为分区2的leader

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/600017
推荐阅读
相关标签

