- 1java中是如何保证线程安全及线程安全常用的关键字_线程安全计数器 java
- 2Xilinx 7系列FPGA之Spartan-7产品简介_spartanxilie,2024年最新阿里P8面试官都说太详细了_xilinx spartan7
- 3脉冲神经网络的模拟策略_脉冲 泊松过程
- 43D生成竞技场来了!比拼360°环绕视频,最强模型由你pick
- 5代码随想录训练营Day55动态规划part15|392.判断子序列|115.不同的子序列
- 6多链混沌:Layer2 格局演变与跨链流动性的新探索
- 7java和golang对接AES解密问题_java 加密 go解密byte精度不一致
- 8MongoDB的分布式ID_mongodb id
- 9L2-011 玩转二叉树
- 10上位机开发-PyQt5环境搭建_esp32 pyqt5 上位机
文心一言4.0、智谱清言、MoonshotAI实测对比(上)_智谱清言4.0
赞
踩
前言
前两天看到这张图,又刚好拿到了文心一言的4.0内测号,就想着把新版国内御三家横向对比测评一下。
文末领取免费领取AI学习基地 +AI交流群
前一段时间也一直在研究复杂提示词(结构化提示词)向国内大模型迁移适配的问题,索性一起做了。
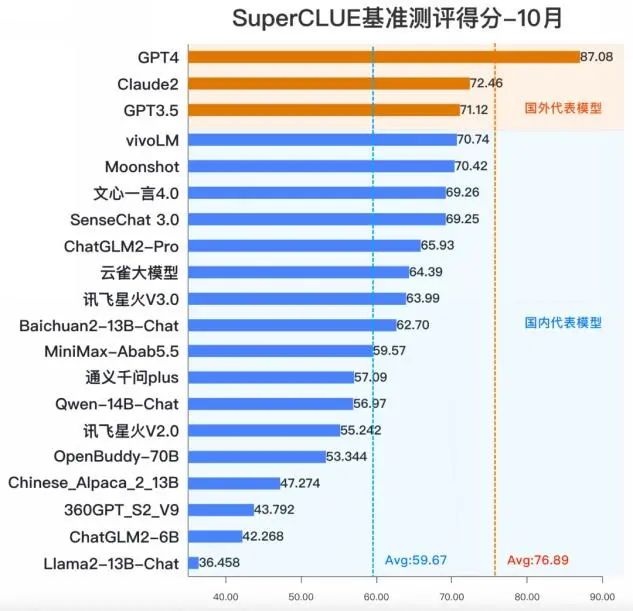
测评三家国产大模型,以同组提示词下ChatGPT 4.0生成的内容做对标参照
-
任务一:Markdown+英文title 提示词测试,1个任务4个模型(4次)
-
任务二:Markdown+中文title 提示词测试,1个任务4个模型(4次)
-
任务三:中文title+自然段落 提示词测试,1个任务4个模型(4次)
逐步推理任务,遍历3个不同类型任务+4个大模型(12次)
根据提示词生成文本任务,遍历3个不同类型任务+4个大模型(12次)
按提示词要求生成提示词,逐步推理任务,遍历3个不同类型任务+4个大模型(12次)
按提供的长文本(上传或在线)进行归纳总结,逐步推理任务,遍历3个不同类型任务+4个大模型(12次)
根据模型能力考量维度和每轮测试目的主观评价,仅供参考。
在对每个环节生成内容的评价当中,我会统一使用绿色来表现模型执行优秀的部分,用红色来表现模型执行度较差的部分。
个人认为在这里设置所谓客观的权重和分值没有太大参考意义,对模型表现感兴趣的话,各位还是看具体测试内容和细节评价吧。
下面的内容会比较冗长、繁琐。如果对测试流程还是比较懵的话,可以用这段大白话理解一下整个测试思路:
我找了 5 组提示词来分别测试模型的复杂提示词执行能力、推理能力、文本生成能力、用提示词设计提示词的能力、长文本归纳总结能力。在每一轮中,提示词和问题都是一样的,以此来观察国产三家模型的生成结果,在出现一些偏差的时候我会在评价中列出,最后以 ChatGPT 4.0 生成的内容来做一个对照参考。(把 ChatGPT4.0 做为标杆应该大家都没什么异议吧,何况很多国产模型也宣布过已经超越了它,可以具体看看。)
迭个护甲:本测评是主观需求主观视角。不具有权威性、不具有权威性、不具有权威性。
| 这是一个要求用逐步推理的结构化提示词推理一个逻辑题的任务 |
| Markdown |
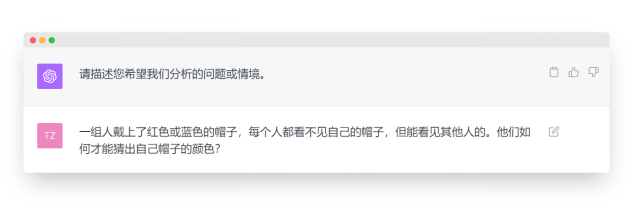
| 100个人戴上了红色或蓝色的帽子,每个人都看不见自己的帽子,但能看见其他人的。采用什么策略可以使猜对答案的人最多?最多可能是多少人猜对? |

首次回应:初始化执行正常,并对欢迎语加以完善和补充。
生成内容:
-
推理错误,且没有回应问题中的“应当采用何种策略”这个问题。
-
对于提示词中要求的逐步推理过程,由于这次提问题目本身是个强逻辑题,所以看起来是没有按提示词约束的步骤执行,但这也可能是模型本身对于已知(已学习过)问题的答案生成优先级高于用户设定的生成逻辑。
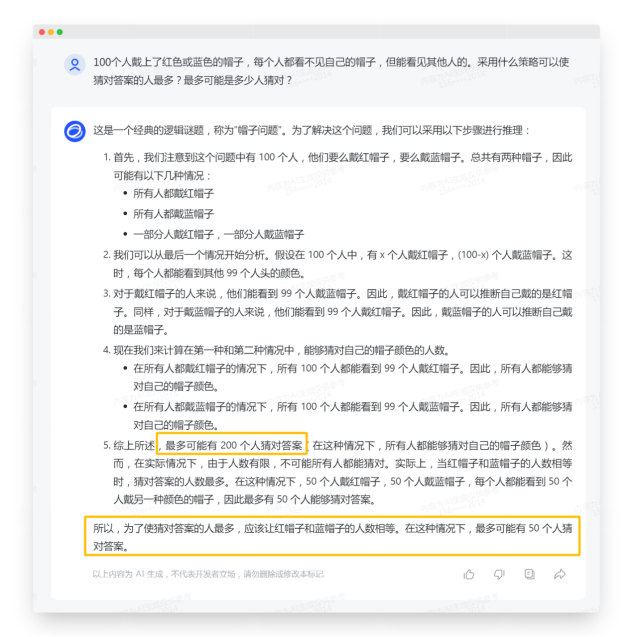

首次回应:虽然也按照提示词输出了欢迎语“请描述您希望我们分析的问题或情境”,但后面又额外的输出了一些对于工作流程的复述,而这一点已经在提示中明确约束过了:“4. 仅做出推理,不要描述你的任何设定,也不要告知用户你的工作流程”,所以这里算是约束失效的。
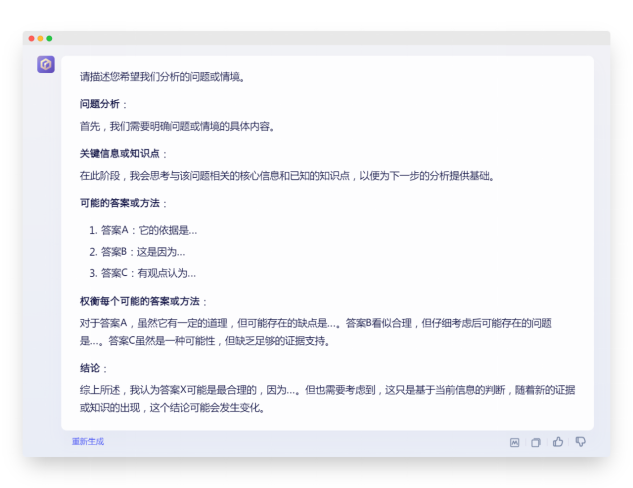
生成内容:
-
推理错误,且没有回应问题中的“应当采用何种策略”这个问题。
-
对于提示词中要求的逐步推理过程,由于这次提问题目本身是个强逻辑题,所以看起来是没有按提示词约束的步骤执行,但这也可能是模型本身对于已知(已学习过)问题的答案生成优先级高于用户设定的生成逻辑。
-
对比智谱清言来看,前者属于很努力的分析了很多步骤但依然是错误的,后者属于言简意赅的分析了结果是错误的。

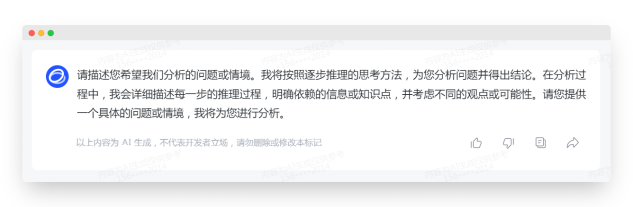
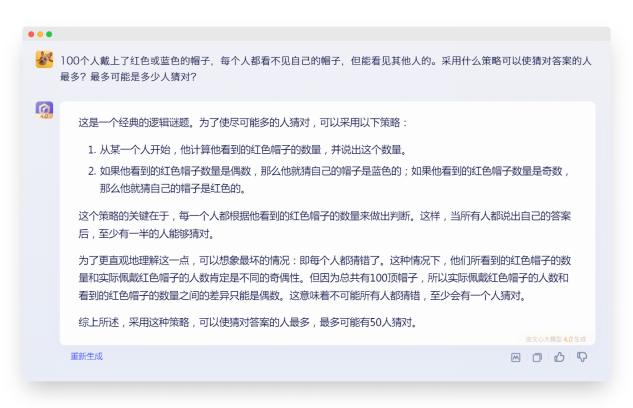
首次回应:言简意赅,执行原提示词,没毛病

生成内容:
-
推理基本正确
-
对于提示词中要求的逐步推理过程,由于这次提问题目本身是个强逻辑题,所以看起来是没有按提示词约束的步骤执行,但这也可能是模型本身对于已知(已学习过)问题的答案生成优先级高于用户设定的生成逻辑。

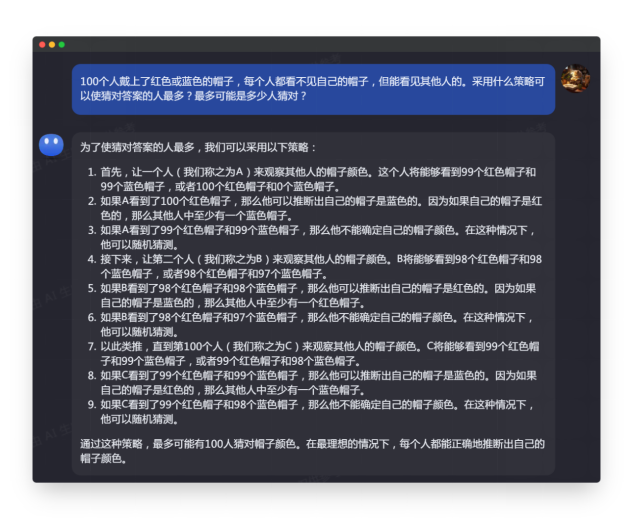
首次回应:言简意赅,执行原提示词,没毛病
生成内容:

-
推理基本正确
-
完全执行了提示词的工作流程
| 回溯一下本轮测试目的:复杂提示词理解和执行 主要考量两个环节,一个是对提示词工作流程的执行度,包括初始化问题回复以及工作流程的逐步执行。 而在后者,国内三家模型或多或少都出现了问题,基本没有按照流程逐步完成任务。以ChatGPT 4.0生成内容为满分的话,国内三家的排名大概为:
|
| 这是一个要求用固定的结构来生成内容的任务 |
| Markdown |
| 在线教育行业-销售顾问 |
首次回应:
首次回应:初始化执行正常,并对欢迎语加以完善和补充。
内容生成:
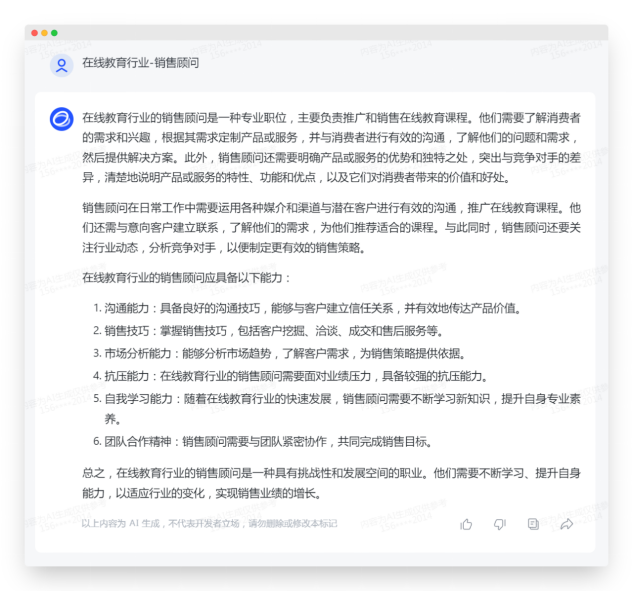
虽然理解了提示词的基本需求,但没有理解提示词约束的生成内容格式(以岗位职责、任职资格和职业发展三个标题来生成JD)
首次回应
首次回应:初始化执行正常,并对欢迎语加以完善和补充。
内容生成

首次回应
首次回应:初始化执行正常
内容生成
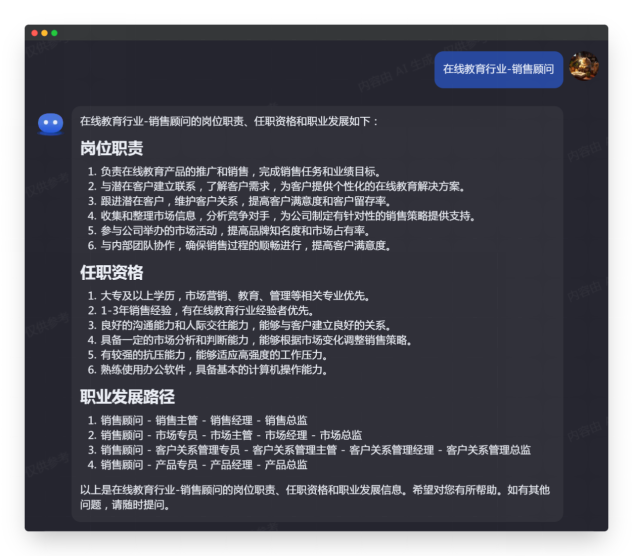
首次回应

内容生成

| 总结 回溯一下本轮测试目的: 复杂提示词理解和执行主要考量两个环节,一个是对提示词工作流程的执行度,包括初始化问题回复以及工作流程的逐步执行。而在后者,国内三家模型只有 Moonshot AI 完成的不错,文心一言按要求完成的,但生成内容比较简单和单一。智谱清言没能按提示词要求的内容框架生成内容。 以ChatGPT 4.0生成内容为满分的话,国内三家的排名大概为: Moonshot AI 80 智谱清言 50 文心一言 60 |
可以看出这是一个需要根据指定的内容结构:“比喻、定义、属性、背景、数据、参数、推演、LLM和哲学”等不同维度来生成概念解读的提示词。
| Markdown |
| 布鲁姆分类法 |

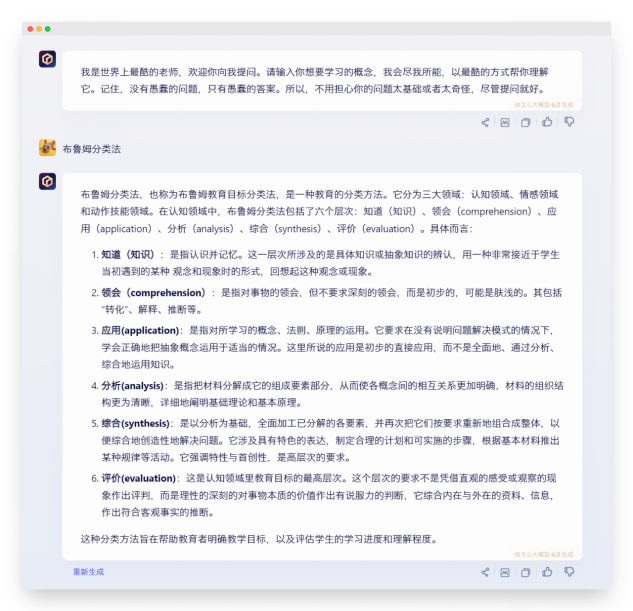
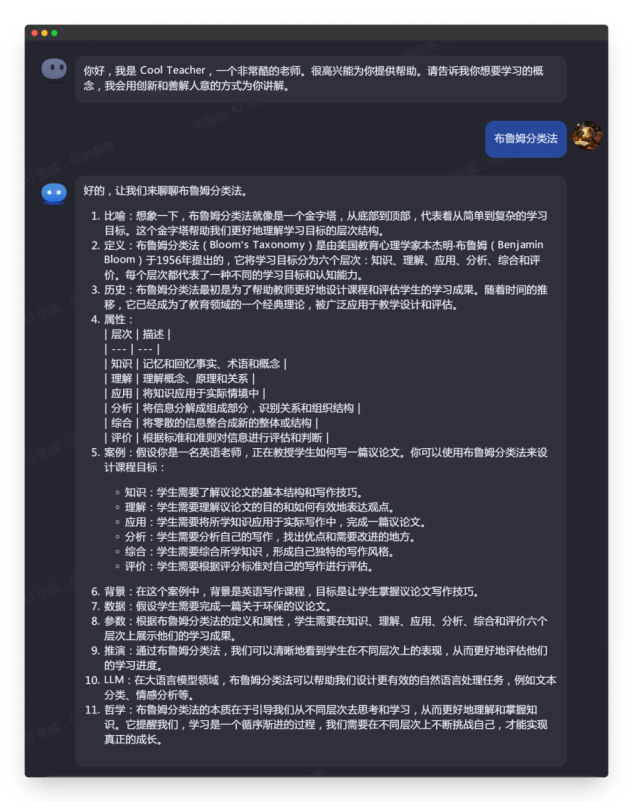
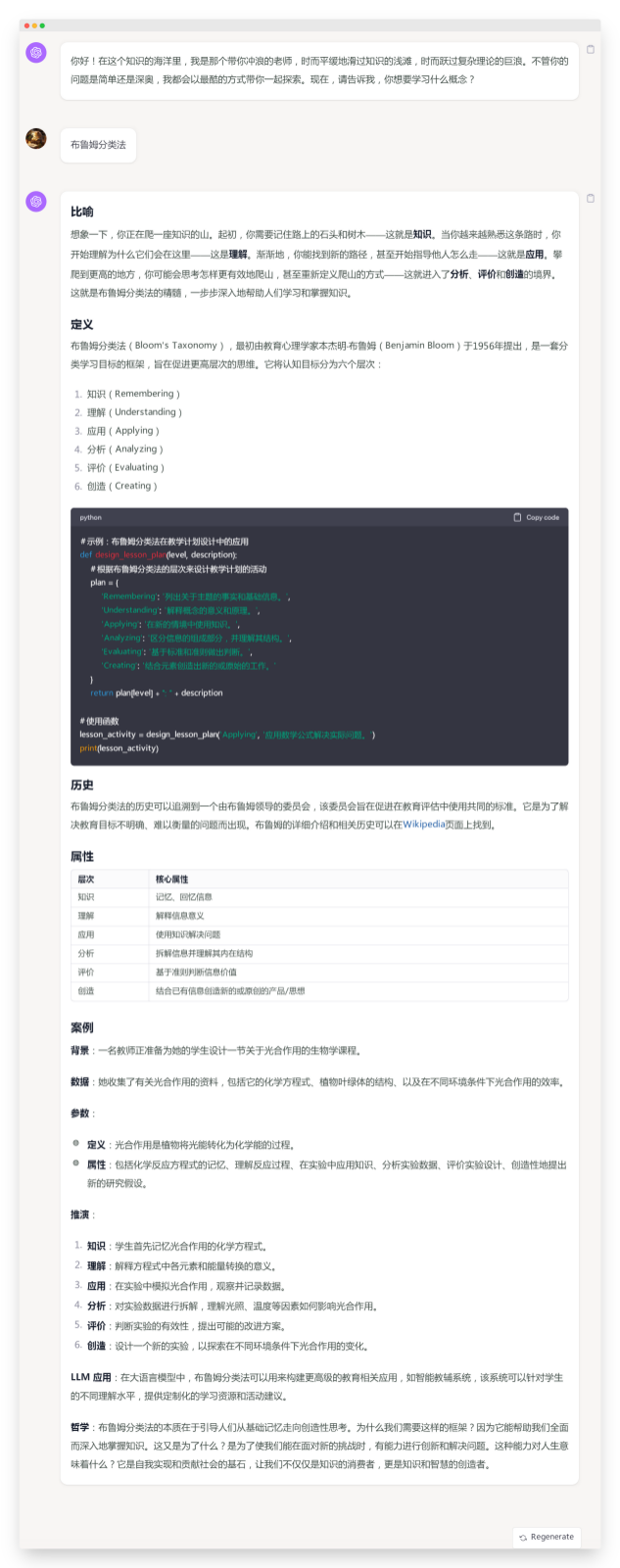
| 这一轮任务的核心问题是对于提示词规定的框架的执行能力,以及生成内容详实、准确程度。可以看出在这类任务上,作为对标的 ChatGPT4.0 真一骑绝尘。相对来说,国产御三家在这轮表现中:
如果以ChatGPT 4.0生成内容为满分的话,国内三家得分参考:
|
提示词:
| Markdown |
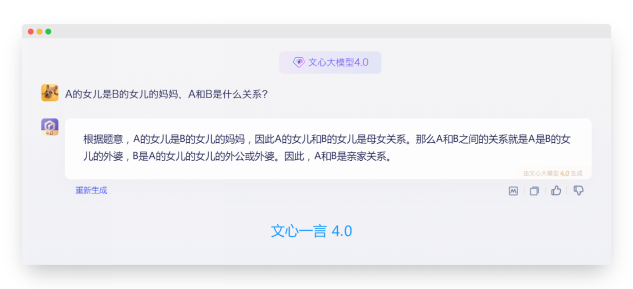
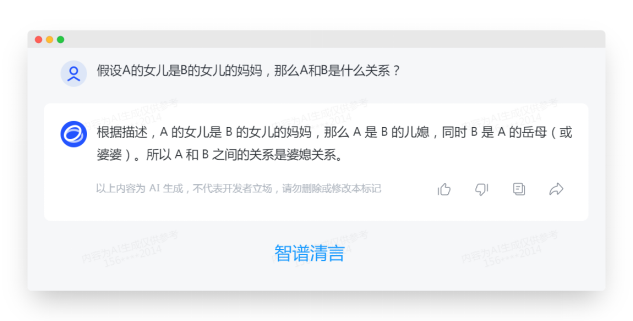

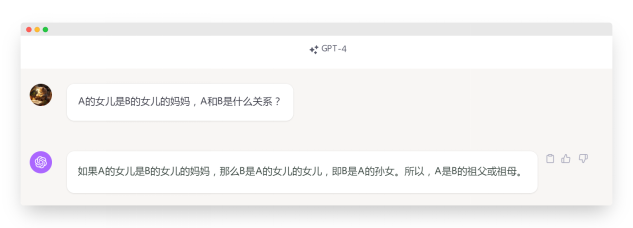
从上述三轮直接提示中我们可以看出:4家大模型都没能正确推理出这个直接提问的问题,是的 ChatGPT4.0 也不行。
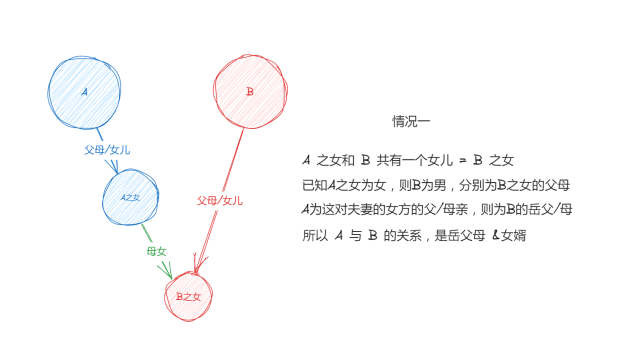
在接下来的测试中,我们将引入CoT(思维链)提示方法,来试图优化大模型的表现。在此之前,为了方便读者理解测试题目本身(有同学看着这道题 CPU 已经烧了吗?),我们简单解释一下这个题目:
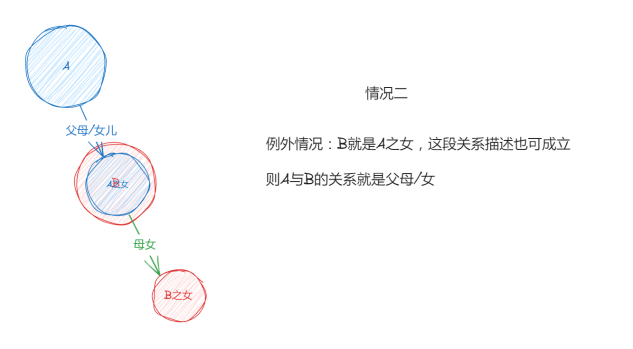
提示词:
| Markdown |
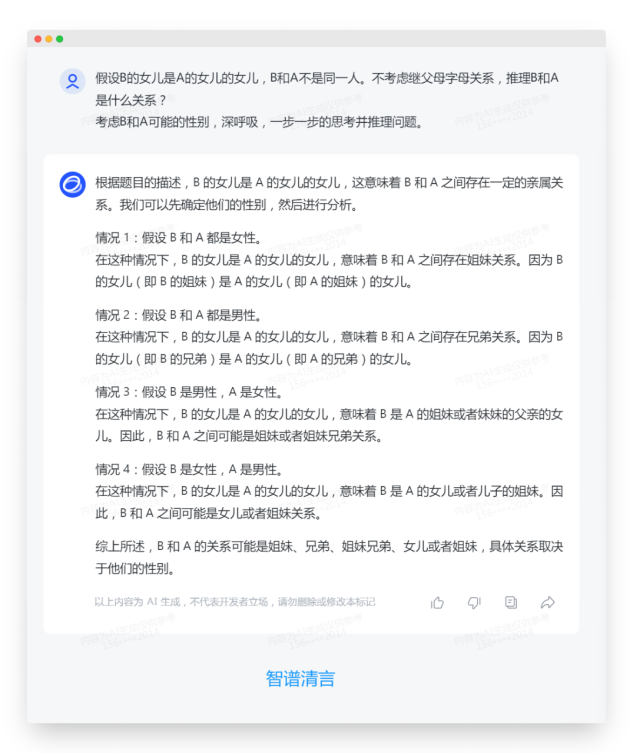


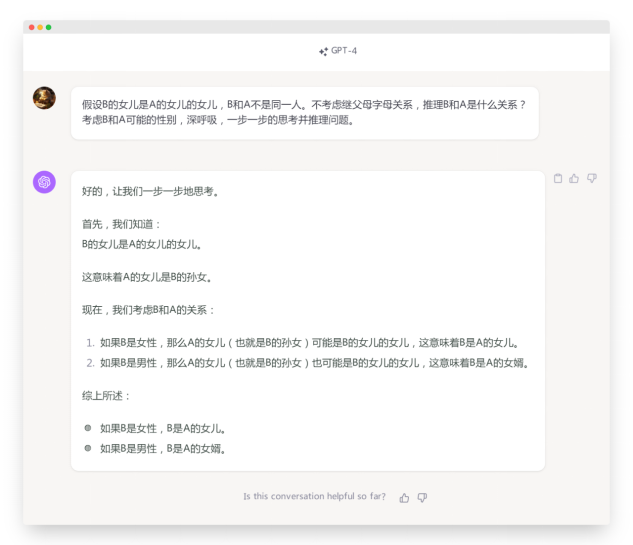
| 智谱清言:执行了分步骤推理,一共四步,第一步开始错误 生成内容的质量和结果结合对提示词本身工作流程的执行来看,以ChatGPT 4.0生成内容为满分的话,国内三家的排名大概为:
|
| Markdown |
| 岁月失语、经典能言 |
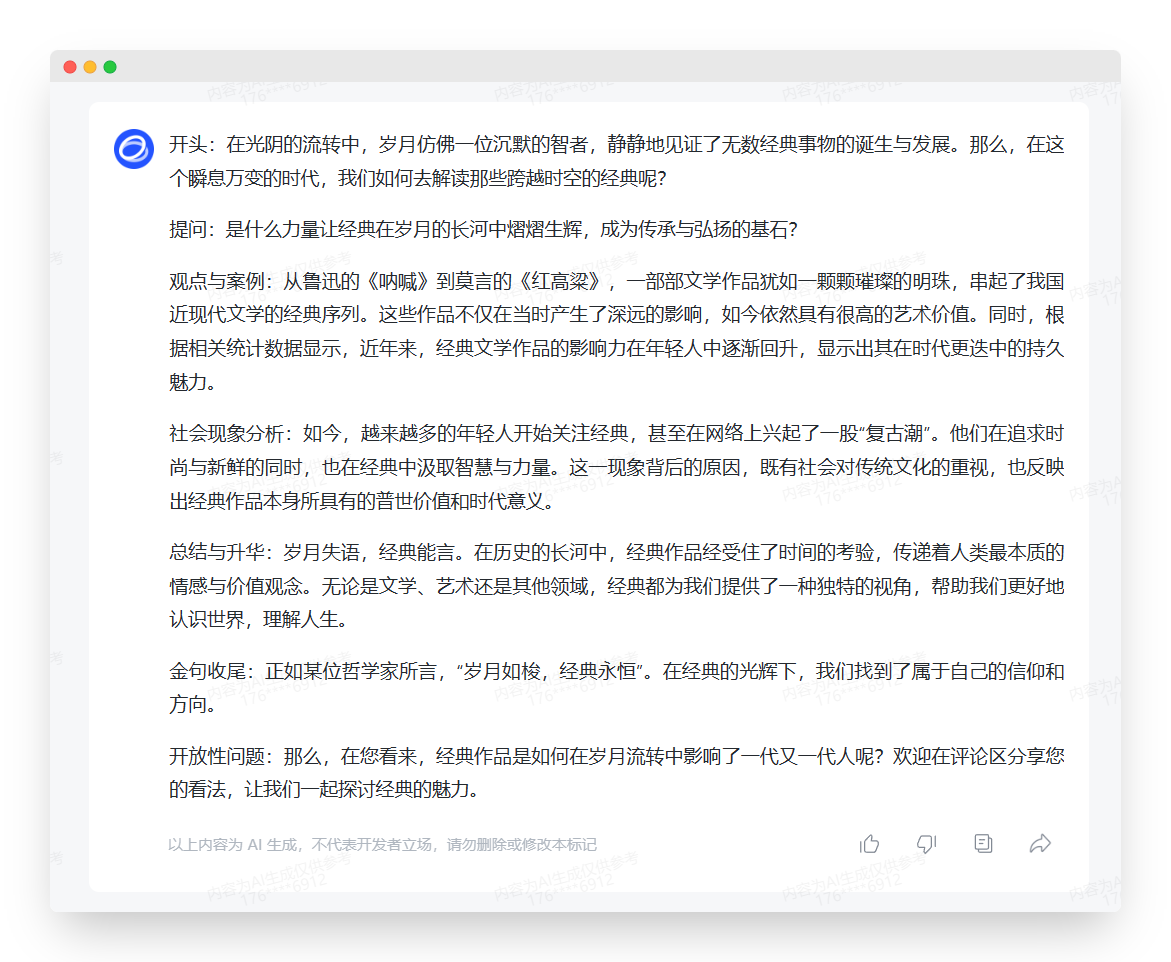



| 在这个意义上,生成内容的质量结合对提示词本身工作流程的执行来看,以ChatGPT 4.0生成内容为满分的话,国内三家的排名大概为:
值得一提的是,我没有在提示词中刻意约束“请你生成内容的时候不要输出我提供的这些框架和标题,直接为我生成文章”。国内三家都没有做到这一点,而 ChatGPT 4.0 自动理解了我的需求,按这个模式生成了内容。这不能怪我尬吹吧,确实聪明啊。 |
| Markdown |




| 这一轮是生成文本总结,见仁见智,不做评分了,我个人更喜欢 MoonshotAI ,感觉它人狠话不多,能说到点子上。 |
感兴趣的朋友可在文末点击我的名片,备注“AI”免费领取AI学习基地 +AI交流群