
- 1设计模式-享元模式
- 2linux redis-trib.rb,linux 关于redis-trib.rb构建redis集群
- 3扩散模型DDPM:先前向加噪后反向去噪从而建立噪声估计模型_扩散模型中的增噪与去噪
- 4电大搜题微信公众号:福建开放大学学子的学习新篇章
- 5FPGA实现串口收发的八字节数据报文Modbus Crc校验_fpga modbus
- 6图解辗转相除法(欧几里得算法)求解最大公约/最小公倍数_辗转相除法推导过程
- 7Apache POI对Excel进行读写操作
- 8[Linux] IP绑定解释 BindIp
- 9MySQL对表操作_update和笛卡尔积查询
- 10基于stm32的小车毕业设计_基于stm32智能小车毕业设计
Hive常见的压缩格式_lz4 lzo deflate
赞
踩
压缩格式
Hive支持的压缩格式有bzip2、gzip、deflate、snappy、lzo等。Hive依赖Hadoop的压缩方法,所以Hadoop版本越高支持的压缩方法越多,可以在$HADOOP_HOME/conf/core-site.xml中进行配置:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec
</value>
</property>
- 1
- 2
- 3
- 4
- 5
常见的压缩格式有:
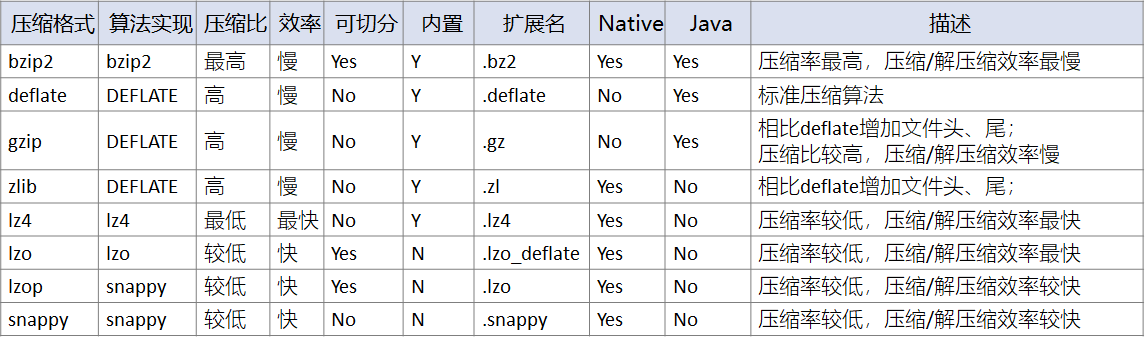
其中压缩比bzip2 > zlib > gzip > deflate > snappy > lzo > lz4,在不同的测试场景中,会有差异,这仅仅是一个大概的排名情况。bzip2、zlib、gzip、deflate可以保证最小的压缩,但在运算中过于消耗时间。
从压缩性能上来看:lz4 > lzo > snappy > deflate > gzip > bzip2,其中lz4、lzo、snappy压缩和解压缩速度快,压缩比低。
所以一般在生产环境中,经常会采用lz4、lzo、snappy压缩,以保证运算效率。
Native Libraries
Hadoop由Java语言开发,所以压缩算法大多由Java实现;但有些压缩算法并不适合Java进行实现,会提供本地库Native Libraries补充支持。Native Libraries除了自带bzip2, lz4, snappy, zlib压缩方法外,还可以自定义安装需要的功能库(snappy、lzo等)进行扩展。
而且使用本地库Native Libraries提供的压缩方式,性能上会有50%左右的提升。
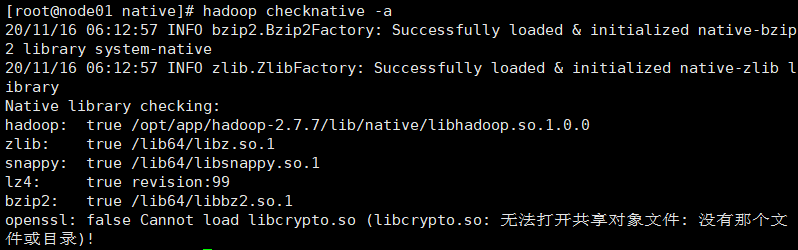
使用命令可以查看native libraries的加载情况:
hadoop checknative -a
- 1
完成对Hive表的压缩,有两种方式:配置MapReduce压缩、开启Hive表压缩功能。因为Hive会将SQL作业转换为MapReduce任务,所以直接对MapReduce进行压缩配置,可以达到压缩目的;当然为了方便起见,Hive中的特定表支持压缩属性,自动完成压缩的功能。
结束语
如果有帮助的,记得点赞、关注。在公众号《数舟》中,可以免费获取专栏《数据仓库》配套的视频课程、大数据集群自动安装脚本,并获取进群交流的途径。
我所有的大数据技术内容也会优先发布到公众号中。如果对某些大数据技术有兴趣,但没有充足的时间,在群里提出,我为大家安排分享。
公众号自取:


