
- 1职场中,那些35岁以上的测试员到底去哪了?_35测试转行
- 2虚拟化技术 分布式资源调度_vm分布式资源调配
- 3Nginx安装_systemctl 启动nginx 找不到命令
- 4nmap常用扫描命令_nmap扫描网段内的所有ip
- 5Leetcode之回溯法专题-131. 分割回文串(Palindrome Partitioning)
- 6flink入门_Flink入门实战(1)
- 7hbase-site.xml的配置文件_怎么进入hbsae的配置文件hbsae-site.xml
- 8大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统_bert+lstm_深度学习在知识图谱最新进展
- 91688店铺所有商品API接口、店铺列表API接口_爬虫 1688 绕过验证码
- 10线程安全集合类概述
Python 爬取百万网易云音乐热门评论
赞
踩
点击上方“程序员大咖”,选择“置顶公众号”
关键时刻,第一时间送达!


前言
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧。获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据。但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据。那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据。利用计算机的高效,我们可以轻松快速地获取数据。
关于爬虫
那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,python 等,我个人比较喜欢使用python。因为python不仅有着内置的功能强大的网络库,还有诸多优秀的第三方库,别人直接造好了轮子,我们直接拿过来用就可以了,这为写爬虫带来了极大的方便。不夸张地说,使用不到10行python代码其实就可以写一个小小的爬虫,而使用其他的语言可以要多写很多代码,简洁易懂正是python的巨大的优势。
好了废话不多说,进入今天的正题。最近几年网易云音乐火了起来,我自己就是网易云音乐的用户,用了几年了。以前用的是QQ音乐和酷狗,通过我自己的亲身经历来看,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论(郑重声明!!!这不是软文,非广告!!!仅代表个人观点,非喜勿喷!)。经常一首歌曲下面会有一些被点赞众多的神评论。加上前些日子网易云音乐将精选用户评论搬上了地铁,网易云音乐的评论又火了一把。所以我想对网易云的评论进行分析,发现其中的规律,特别是分析一些热评具有什么共同的特点。带着这个目的,我开始了对网易云评论的抓取工作。
Python内置了两个网络库urllib和urllib2,但是这两个库使用起来不是特别方便,所以在这里我们使用一个广受好评的第三方库requests。使用requests只用很少的几行代码就可以实现设置代理,模拟登陆等比较复杂的爬虫工作。如果已经安装pip的话,直接使用pip install requests 即可安装。
中文文档地址在此 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
大家有什么问题可以自行参考官方文档,上面会有非常详细的介绍。至于urllib和urllib2这两个库也是比较有用的,以后如果有机会我会再给大家介绍一下。
在正式开始介绍爬虫之前,首先来说一下爬虫的基本工作原理,我们知道我们打开浏览器访问某个网址本质上是向服务器发送了一定的请求,服务器在收到我们的请求之后,会根据我们的请求返回数据,然后通过浏览器将这些数据解析好,呈现在我们的面前。
如果我们使用代码的话,就要跳过浏览器的这个步骤,直接向服务器发送一定的数据,然后再取回服务器返回的数据,提取出我们想要的信息。
但是问题是,有的时候服务器需要对我们发送的请求进行校验,如果它认为我们的请求是非法的,就会不返回数据,或者返回错误的数据。所以为了避免发生这种情况,我们有的时候需要把程序伪装成一个正常的用户,以便顺利得到服务器的回应。
如何伪装呢?
这就要看用户通过浏览器访问一个网页与我们通过程序访问一个网页之间的区别。
通常来说,我们通过浏览器访问一个网页,除了发送访问的url之外,还会给服务发送额外的信息,比如headers(头部信息)等,这就相当于是请求的身份证明,服务器看到了这些数据,就会知道我们是通过正常的浏览器访问的,就会乖乖地返回数据给我们了。
所以我们程序就得像浏览器一样,在发送请求的时候,带上这些标志着我们身份的信息,这样就能顺利拿到数据。有的时候,我们必须在登录状态下才能得到一些数据,所以我们必须要模拟登录。
本质上来说,通过浏览器登录就是post一些表单信息给服务器(包括用户名,密码等信息),服务器校验之后我们就可以顺利登录了,利用程序也是一样,浏览器post什么数据,我们原样发送就可以了。
关于模拟登录,我后面会专门介绍一下。当然事情有的时候也不会这么顺利,因为有些网站设置了反爬措施,比如如果访问过快,有时候会被封ip(典型的比如豆瓣)。这个时候我们还得要设置代理服务器,即变更我们的ip地址,如果一个ip被封了,就换另外一个ip,具体怎么做,这些话题以后慢慢再说。
最后,再介绍一个我认为在写爬虫过程中非常有用的一个小技巧。如果你在使用火狐浏览器或者chrome的话,也许你会注意到有一个叫作开发者工具(chrome)或者web控制台(firefox)的地方。这个工具非常有用,因为利用它,我们可以清楚地看到在访问一个网站的过程中,浏览器到底发送了什么信息,服务器究竟返回了什么信息,这些信息是我们写爬虫的关键所在。下面你就会看到它的巨大用处。
如何爬取评论
首先打开网易云音乐的网页版,随便选择一首歌曲打开它的网页,这里我以周杰伦的《晴天》为例。如下图:

接下来打开web控制台(chrome的话打开开发者工具,如果是其他浏览器应该也是类似),如下图:
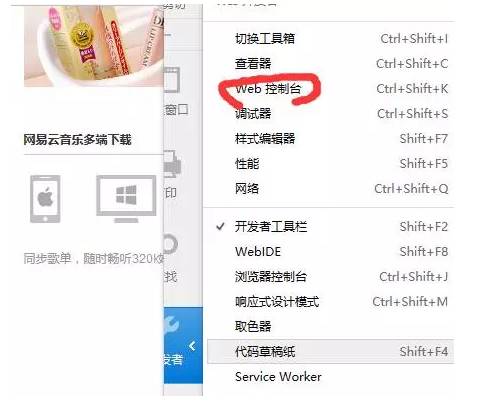
然后这个时候我们需要点选网络,清除所有的信息,然后点击重新发送(相当于是刷新浏览器),这样我们就可以直观看到浏览器发送了什么信息以及服务器回应了什么信息。如下图:
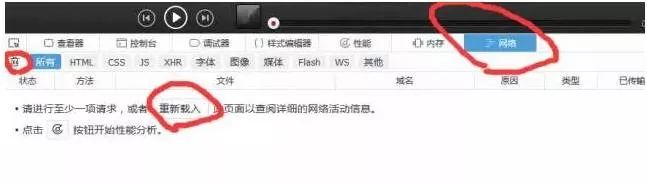
刷新之后得到的数据如下

可以看到浏览器发送了非常多的信息,那么哪一个才是我们想要的呢?这里我们可以通过状态码做一个初步的判断,status code(状态码)标志了服务器请求的状态,这里状态码为200即表示请求正常,而304则表示不正常(状态码种类非常多,如果要想详细了解可以自行搜索,这里不说304具体的含义了)。所以我们一般只用看状态码为200的请求就可以了,还有就是,我们可以通过右边栏的预览来粗略观察服务器返回了什么信息(或者查看响应)。如下图:
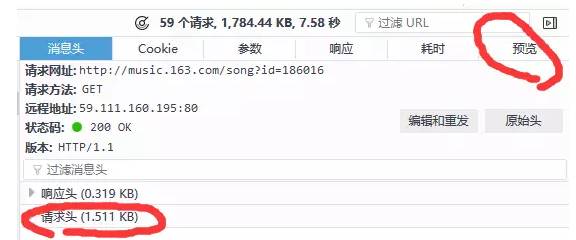
通过这两种方法结合一般我们就可以快速找到我们想要分析的请求。注意图5中的请求网址一栏即是我们想要请求的网址,请求的方法有两种:get和post,还有一个需要重点关注的就是请求头,里面包含了user-Agent(客户端信息),refrence(从何处跳转过来)等多种信息,一般无论是get还是post方法我们都会把头部信息带上。头部信息如下图:

另外还需要注意的是:get请求一般就直接把请求的参数以 ?parameter1=value1¶meter2=value2 等这样的形式发送了,所以不需要带上额外的请求参数,而post请求则一般需要带上额外的参数,而不直接把参数放在url当中,所以有的时候我们还需要关注参数这一栏。经过仔细寻找,我们终于找到原来与评论相关的请求在http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= 这个请求当中,如下图:
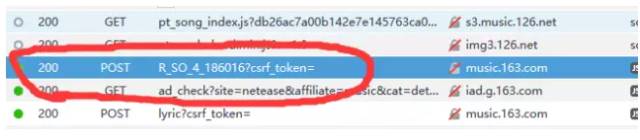
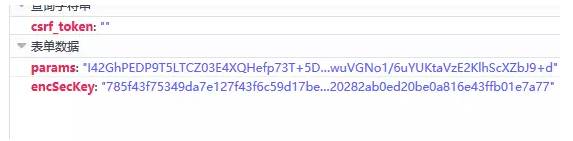
点开这个请求,我们发现它是一个post请求,请求的参数有两个,一个是params,还有一个是encSecKey,这两个参数的值非常的长,感觉应该像是加密过的。如下图:
服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),如下图9所示:(其实hotComments为热门评论,comments为评论数组)

至此,我们已经确定了方向了,即只需要确定params和encSecKey这两个参数值即可,这个问题困扰了我一下午,我弄了很久也没有搞清楚这两个参数的加密方式,但是我发现了一个规律,http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= 中 R_SO_4_ 后面的数字就是这首歌的id值,而对于不同的歌曲的param和encSecKey值,如果把一首歌比如A的这两个参数值传给B这首歌,那么对于相同的页数,这种参数是通用的,即A的第一页的两个参数值传给其他任何一首歌的两个参数,都可以获得相应歌曲的第一页的评论,对于第二页,第三页等也是类似。
但是遗憾的是,不同的页数参数是不同的,这种办法只能抓取有限的几页(当然抓取评论总数和热门评论已经足够了),如果要想抓取全部数据,就必须搞明白这两个参数值的加密方式。
以为没有搞明白,昨天晚上我带着这个问题去知乎搜索了一下,居然真的被我找到了答案。@平胸小仙女 这位知友详细说明了如何破解这两个参数的加密过程,我研究了一下,发现还是有点小复杂的,按照知友写的方法,我改动了一下,就成功得到了全部的评论。这里要对知乎@平胸小仙女 表示感谢。
到此为止,如何抓取网易云音乐的评论全部数据就全部讲完了。按照惯例,最后上代码,亲测有效:
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py '''
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章
来源:知乎
''' from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
'Host':"music.163.com",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
'Connection':"keep-alive",
'Referer':'http://music.163.com/' }
# 设置代理服务器
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
# offset的取值为:
(评论页数-1)*20,total第一页为true,其余页为false # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第一个参数 second_param = "010001"
# 第二个参数
# 第三个参数 third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数 forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数 def get_params(page):
# page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict['hotComments'] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userID'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u""
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict['total'])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict['comments']:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userId'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u""
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,'a',encoding='utf-8') as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016/?csrf_token="
filename = u"晴天.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))
我利用上述代码跑了一下,抓了两首周杰伦的热门歌曲《晴天》(有130多万评论)和《告白气球》(有20多万评论),前者跑了大概有20多分钟,后者有6600多秒(也就是将近2个小时),截图如下:
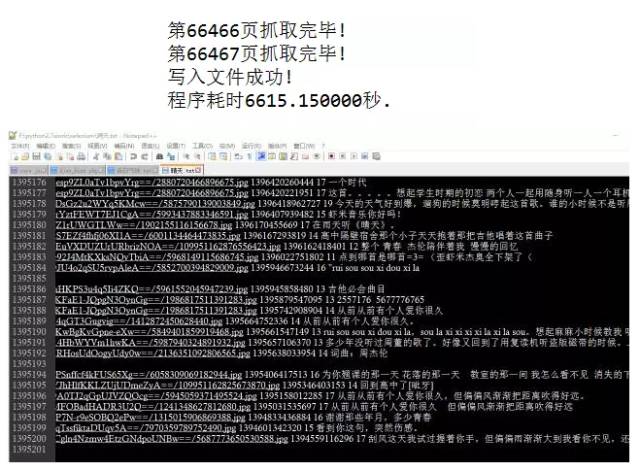
注意我是按照空格来分隔的,每一行分别有用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容 这些内容。同学们自己跑代码抓取的时候,注意不要开太多线程给网易云的服务器太大压力哦(中间有一段时间服务器返回数据特别慢,不知道是不是限制访问了,后来又好了)。我后面也许会自己去对评论数据进行可视化分析,敬请期待!




来自:lyrichu - 博客园
原文:www.cnblogs.com/lyrichu/p/6635798.html
程序员大咖整理发布,转载请联系作者获得授权



