
- 1【路径规划】多种算法无人机路径规划【含Matlab源码 1263期】_无人机群路径规划csdn
- 2oracle面试题及其答案
- 3百度api识别身份证 + 银行卡 + 驾驶证 + 行驶证 信息
- 4OOM异常原因几种类型分析_fd超限
- 5ARM学习之基本概念_寄存器为什么不能使用地址进行访问:
- 6【seeprettyface.com】开源源码:Video-Auto-Wipe_字幕去除模型
- 707微服务的事务管理机制_微服务 事务管理
- 8强到离谱!AI绘画Stable Diffusion让商业换装如此简单!AI一键换装,AI绘画教程_inpaint-web需要下载的模型
- 9Windows 安装Kafka_windows kafka安装
- 10『What‘s In PaddleNLP』多层次组网API-快递单信息抽取_paddlenlp http api
Flink系列三:Flink架构、独立集群搭建及Flink on YARN模式详解_flink独立集群
赞
踩
一、Flink架构
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如Hadoop yarn,但也可以设置作为独立集群甚至库运行。
Flink 集群剖析
Flink 运行时由两种类型的进程组成:一个 JobManager (作业管理器)和一个或者多个 TaskManager(任务管理器)。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为standalone 集群启动、在容器中启动、或者通过YARN等资源框架管理并启动。
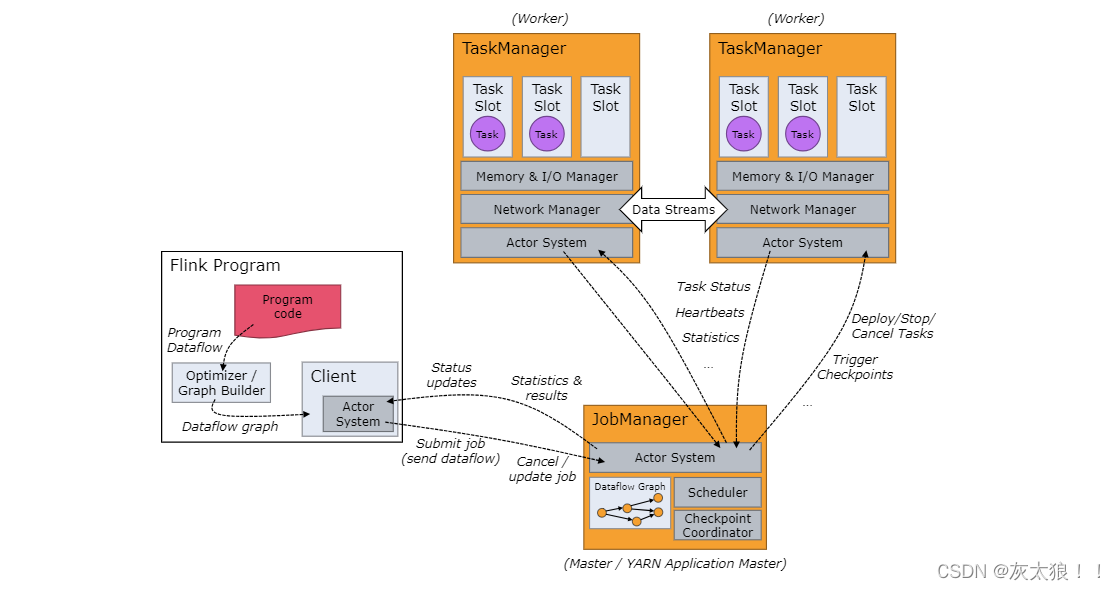
流程简要说明:
我们编写的flink代码在本地会被构建为一个数据流程图Dataflow graph(类似于spark中的DAG有向无环图,其实就是我们的代码逻辑),之后会将这个Dataflow graph提交给JobManager并被拆分为一个一个的个task,这些task会被发送到TaskManager中的TaskSlot执行,TaskManager也会返回task的状态信息给JobManager。
节点功能:
JobManager:决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等
TaskManagers(也称为 worker):执行作业流的 task,并且缓存和交换数据流。
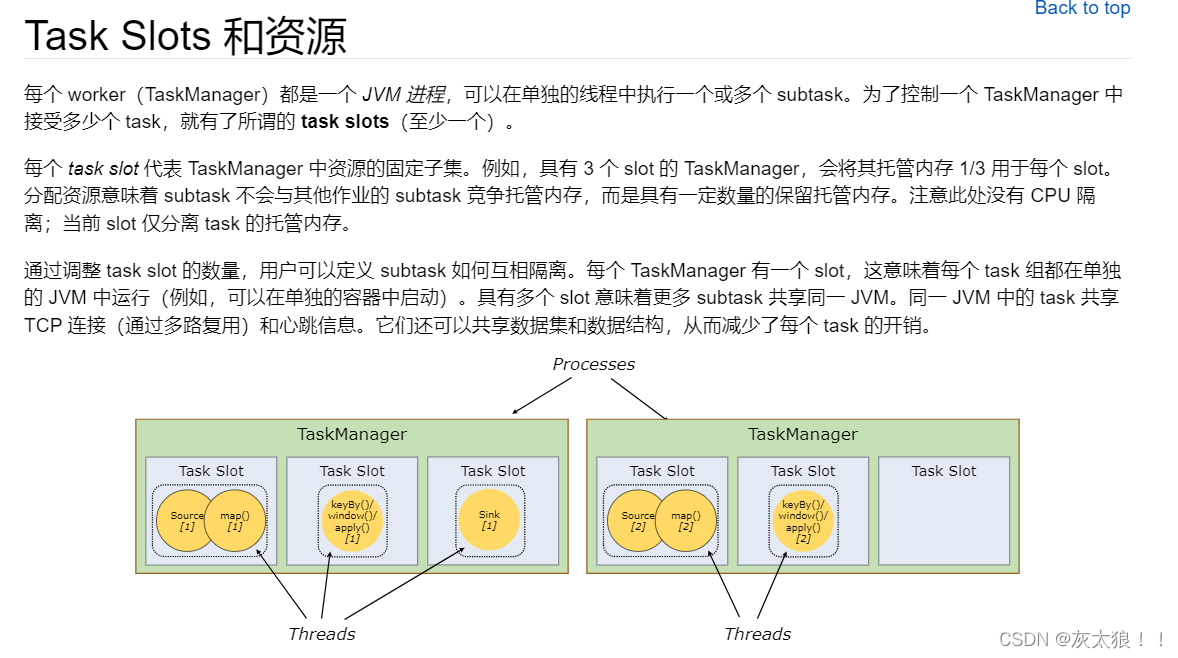
必须始终至少有一个 TaskManager,在 TaskManager 中资源调度的最小单位是 task slot(槽)。 task slot 的数量表示并发处理 task 的数量,意一个 task slot 中可以执行多个算子。
(可以将Task Slot类比为线程池,而将task类比为线程,便于理解)
下面是官方文档原文参考:
二、Flink独立集群搭建与使用(Standalone)
1、上传解压
在华为云镜像站下载flink-1.15.2安装包并上传到linux中解压
tar -xvf flink-1.15.2-bin-scala_2.12.tgz
2、配置环境变量
2.1 vim /etc/profile
export FLINK_HOME=/usr/local/soft/flink-1.15.2
export PATH=$PATH:$FLINK_HOME/bin
2.2 source /etc/profile (使得环境变量生效 )
3、修改配置文件
3.1 修改flink-conf.yaml文件
jobmanager.rpc.address: master
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: localhost #在分发后子节点需要分别修改为noe1和node2
taskmanager.numberOfTaskSlots: 4
rest.address: master
rest.bind-address: 0.0.0.0
3.2 修改 masters文件
master:8081
3.3 修改 workers 文件
node1
node2
4、同步到子节点
scp -r flink-1.15.2 node1:`pwd`
scp -r flink-1.15.2 node2:`pwd`# 修改node1和node2中地taskmanager.host
taskmanager.host: node1
taskmanager.host: node2
5、启动Flink独立集群
在主节点启动:
start-cluster.sh # stop-cluster.sh(关闭命令)
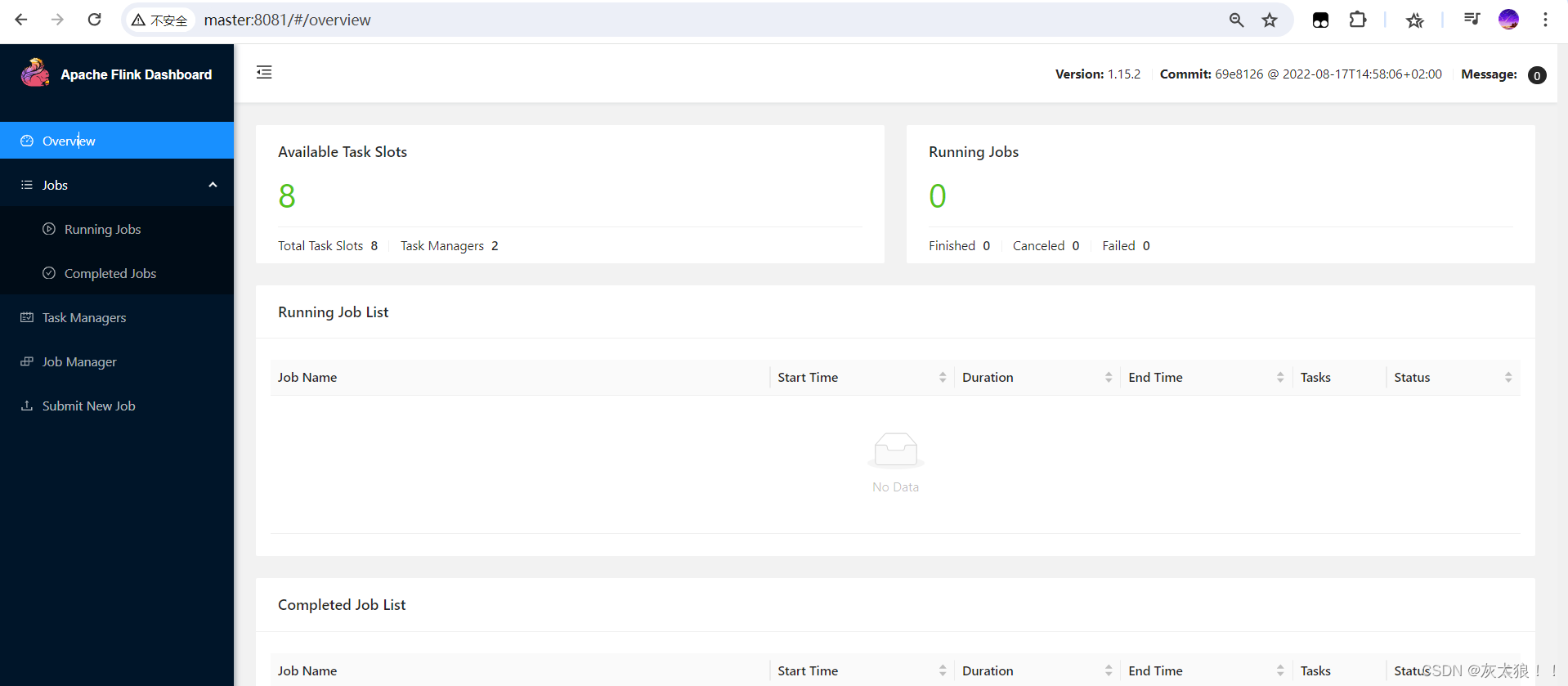
flink web ui 界面:
http://master:8081

6、提交任务
以Flink系列一写的入门案例代码为例子:
6.1 方式一:将代码打包上传到服务器提交
flink run -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
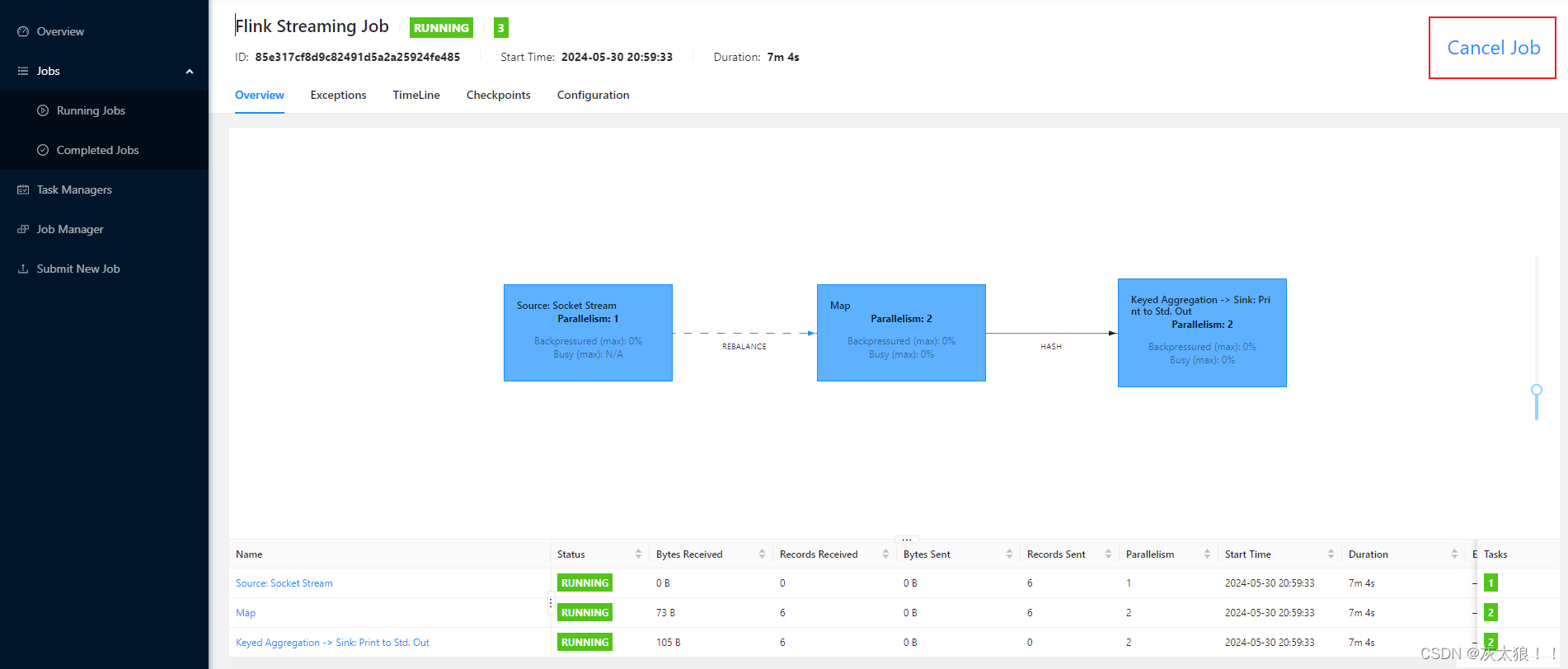
注意:任务运行成功的话会一直存在,如果想要取消,可以点击右上角的cancle job停止任务。
6.2 在flink web ui中直接提交
三、Flink on Yarn模式
flink on yarn模式:将flink地任务提交到yarn上运行
首先要启动hadoop集群
1、整合
# 在环境变量中配置HADOOP_CLASSSPATH
vim /etc/profile
export HADOOP_CLASSPATH=`hadoop classpath`
注意: 要放在最后面,不要放在配置的HADOOP_HOME环境变量之前。
source /etc/profile
2、Flink on yarn的三种部署模式
2.1 Application Mode(应用模式)
特点:
(1)将任务提交到yarn上运行,yarn会为每一个flink地任务启动一个jobmanager和一个或者多个taskmanasger
(2)代码main函数不再本地运行,dataFlow不再本地构建,如果代码报错在本地看不到详细地错误日志,类似于spark中的spark yarn cluster。
提交命令:
flink run-application -t yarn-application -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
本地看不到日志,但是可以查看yarn的日志:
yarn logs -applicationId application_1717039073374_0001
2.2 Per-Job Cluster Mode(单作业模式)
特点:
(1)将任务提交到yarn上运行,yarn会为每一个flink地任务启动一个jobmanager和一个或者多个taskmanasger
(2)代码地main函数在本地启动,在本地构建dataflow,再将dataflow提交给jobmanager,如果代码报错再本地可以看到部分错误日志,类似于spark中的spark yarn client模式,
提交命令:
flink run -t yarn-per-job -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
2.3 Session Mode(会话模式)
特点:
(1)先再yarn中启动一个jobmanager, 不启动taskmanager
(2)提交任务地时候再动态申请taskmanager
(3)所有使用session模式提交的任务共享同一个jobmanager
(4)类似独立集群,只是集群在yarn中启动了,可以动态申请资源
(5)一般用于测试
提交命令:
# 1、先启动会话集群
yarn-session.sh -d可选参数解释:
-d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
-jm(--jobManagerMemory):配置JobManager所需内存,默认单位MB。
-nm(--name):配置在YARN UI界面上显示的任务名。
# 2、再提交任务
flink run -t yarn-session -Dyarn.application.id=application_1717075266296_0004 -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0-SNAPSHOT.jar#或者 在网页中直接提交
杀死yarn集群任务命令:
yarn application -kill application_1717075266296_0004

