
- 1Linux防火墙之“四链五表”_raw规则链
- 2深入浅出讲解Python库的五种安装方法_python安装库
- 3Go (二) 函数部分1 -- 函数定义,传参,返回值,作用域,函数类型,defer语句,匿名函数和闭包,panic_go func () 函数名称()()
- 4C语言实现学生选课系统完整版_#include
#include int n1,n2,kk - 5微软发布新的Copilot+ PCs 是微软推出的一系列高性能、智能化的 Windows 个人电脑。
- 6【数据结构】-大O计法_大o运算规则
- 7微信表白代码大全,微信满屏表情代码大全,现在知道还不算晚
- 8ESP-AT 系列: AT+MQTT 使用_at+mqttusercfg
- 9Error in v-on handler: “TypeError: Cannot read property ‘get‘ of undefined“解决办法_typeerror: cannot read property 'get' of undefined
- 10银河麒麟GCC编译升级_银河麒麟升级gcc
NLP 前置知识3 —— 预训练模型_预训练方法的好处
赞
踩
一. Pre-training & Fine - tuning 机制
1.定义
Pre-training: 在大规模数据集上学习尽可能好的通用表示
Fine-tuning : 利用学习好的通用表示初始化下游任务网络
- 加速收敛
- 减少任务相关监督数据的需求
二.预训练模型发展总概

来源:百度NLP
三.预训练模型简介
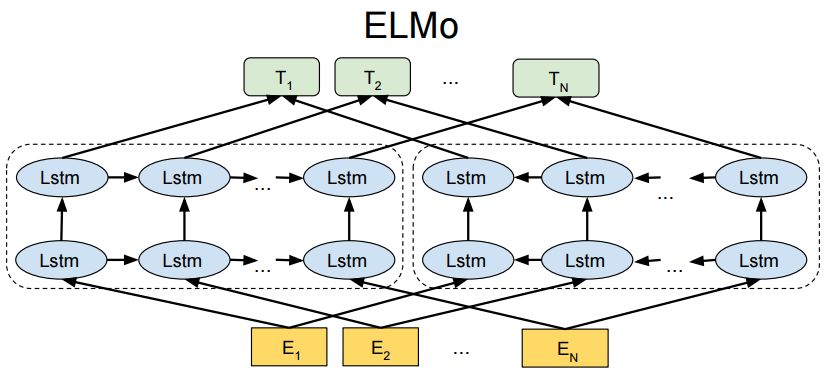
1. ELMo
Pre-training:
(1)Bi-LSTM (两层/双向(LR, RL))
(2) 无监督训练,训练数据1B Word
(3) 只预训练language model, word embedding 是通过输入的句子实时输出
Fine- tuning
1.Feature -Based
- Pretraining 输出语义特征,句法特征、单词特征用于下游任务
- 需要进行(下游)任务相关网络结构设计
缺点:
1)不完全双向预训练: 前后向LSTM是分开训练的,仅在loss function阶段结合
2) 每种下游任务都要重新设计网络结构
3) pre-training阶段进学习了语言模型,无句向量学习任务
2.GPT
Pre-training:
(1)model: Transformer
(2) 训练数据1B Word &BooksCorpus(+0.8 billion)
(3) Pretraining 阶段的目标是:根据前几个字预测下一个字(自回归预训练/无马尔科夫假设)
(4) 支持大规模数据下的自监督学习
Fine-tuning:
(1)Model-Based
优缺点:
(1) 优点:model-based,简化了任务相关网络结构的设计
(2) 缺点: 单向预训练模型/仅有词向量,无句向量
3.BERT
Pre-training:
(1)model: Transformer
(2) Auto-Encoder 交互式双向语言模型建模
(3) Pre-training :
- 同时训练 token-level & sentence-level task
- 自编码语言模型 ,15% mask概率
- 预测当句的下一句话
Fine-tuning:
(1)Model Based
优缺点:
(1) 优点:无交互式双向语言模型建模/ 有句向量
(2) 缺点:sub-word预测可以通过word的局部信息完成,模型缺乏全局建模的信息的动力,难以学到词、短语、实体的完整语义
4.ERINE
百度NLP神器
Pre-training:
(1)model: Transformer
(2) Auto-Encoder 交互式双向语言模型建模
(3) Pre-training :
- 同时训练 token-level & sentence-level task
- 自编码语言模型 ,15% mask概率
- 预测当句的下一句话 (强迫模型通过全局信息去预测mask掉的内容)(与BERT最大的区别)
(4) ERNIE 2.0 : 更多的预训练模型,捕获更丰富的语义知识
Fine-tuning:
(1)Model Based

