
- 1android 7.1 屏蔽按压两次电源键(KEYCODE_POWER)打开相机_android keyguardviewmediator: camera gesture was t
- 2Java类和对象(二)—— 封装,static 关键字与代码块
- 3京东商品接口加解密算法解析_某东web端h5st
- 4新思科技:部署数据安全战略,更好地实现合规性_安全策略与合规性
- 5springboot项目导成jar包部署至Linux,图片上传时保存至jar包外的目录问题的解决方案_liunx 系统保存图片springboot
- 6解决PermissionError: [Errno 13] Permission denied: './data\\mnist\\train-images-idx3-ubyte'_运行yolov3中train.py时报错:permissionerror:[errno 13]per
- 7C++ 遍历文件夹_c++遍历文件夹
- 8git pull(拉取) push(上传)详解_git 传入和传出是什么意思
- 9单目图像深度估计 - 泛化篇:S2R-DepthNet
- 10天池-AI美年健康大赛初赛-xgboost模型_使用xgboost的数模美赛
Next-Level Agents:释放动态上下文(Dynamic Context)的巨大潜力
赞
踩
编者按: 本文深入探讨了如何通过优化动态上下文信息(Dynamic Context)来提升 AI Agents 的工作效率和准确性。文章首先概述了五种常见的技术策略,包括信息标识(Message Labeling)、针对不同需求设定不同上下文、优化系统提示词(System Prompts)、精简 RAG 系统中冗余信息,以及其他处理上下文的高级策略。
随后,作者分享了一些技术实施细节和经验教训,这些教训虽然源自与 Multi-agent 团队在实际生产环境中的长期合作实践,但对于 single agent 系统也具有广泛的适用性和指导意义。
文中强调,AI Agents 不应仅局限于使用固定提示词指令来定义,还应包含自己的动态上下文配置。通过简明的上下文类型划分,为每个 AI Agent 量身打造不同的上下文配置,将极大拓展其应用潜能。本文所述的动态上下文配置(Dynamic Context)仅是 AI Agents 系统架构的冰山一角,欢迎各位读者就此主题深入交流探讨。
作者 | Frank Wittkampf
编译 | 岳扬

AI Agents 之间往往存在很大差异(配图源自 MidJourney)
01 内容简介 Introduction
AI Agents 的行为主要由两点决定: (1) 它所运行的基础模型,以及 (2) 输入给该模型的上下文信息。上下文信息输入的方式直接影响着 Agents 任务执行效果。甚至可以说,即使使用同一模型,不同的上下文内容输入也能造就各具特色的 Agents 行为模式。那么,何为 Agents 所需的“上下文信息”呢?可通过查阅下方的 “Types of Context” 图示了解相关信息。
本文将深入探讨一系列 Agents 进阶策略,依据 AI Agents 的具体需求优化上下文信息,从而提升其工作效率与准确性。本文首先将概述五种常见技术策略,然后会分享一些实施细节。 文中总结的经验教训,虽源自于和 multi-agent 团队在实际生产环境中合作的长期实践经验,但这些经验对于 single agent 系统亦具有广泛的适用性和指导意义。
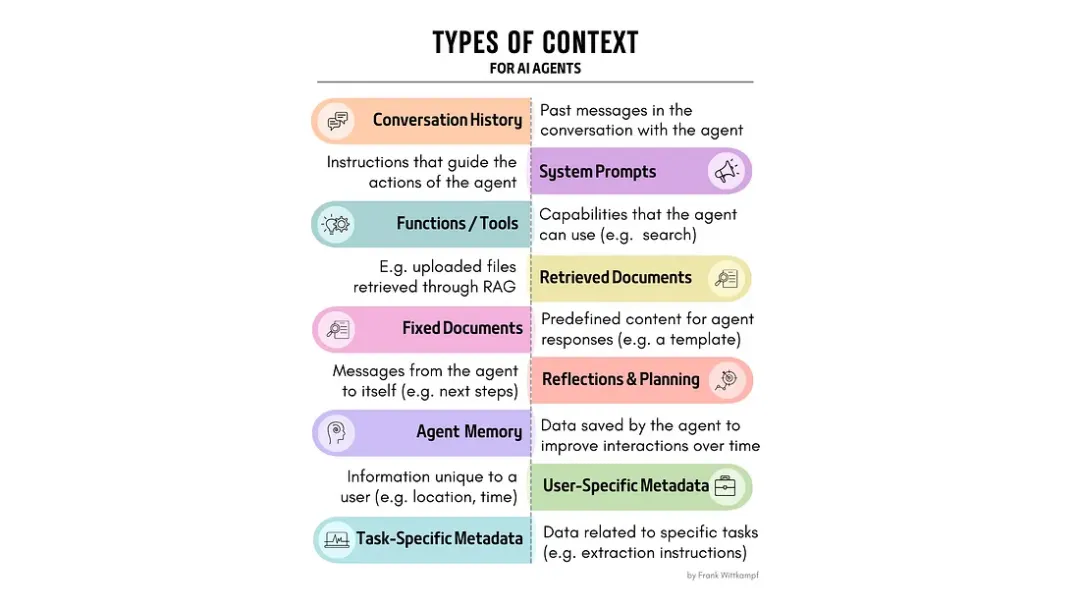
AI Agents 所涉及的上下文类别(图片由原文作者提供)
02 理解上下文信息需求
网络上大多数在线示例及教程都倾向于采取简化手段处理上下文信息(例如设定一个固定的上下文长度限制)。然而,在实际的 AI 应用中需要更加细腻和成熟的方法。
依据手头任务的不同,各种 Agents 对上下文信息的需求大相径庭。 有的 Agents 或许只需当前的信息,而有些 Agents 为了确保回答精准,则可能需要依靠大量的历史数据。因为存在这种差异性,需要针对每一个 Agent 制定个性化的上下文管理策略。
下面是一位用户与两个 Agents(用于软件开发的 Agent 和用于软件测试的 Agent)间的交流场景:
1 User: “Please improve the sorting function I wrote from the uploaded file”
2 System_prompt_for_coder: “You are a SW developer, you help the user to
develop …”
3 Coding_agent: “read_file_function”
4 Function_response: “coding snippet: ```some returned code```”
5 System_prompt_for_coder: “You are a SW developer, you help the user to
develop …”
6 Coding_agent: “I’ve improved your code by adding … and … to your code,
here is the new function …”
7 System_prompt_for_reviewer: “you are a SW code reviewer, you …”
8 Code_reviewer_agent: “After reviewing the improved code, there
are a few more things that I would add to the code …"
9 System_prompt_for_coder: “you are a SW developer, you help the user to
develop …”
10 Coding_agent: “ … ”
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在上述案例中,上下文的组织方式显然存在冗余且效率不高。多条对话内容都存在不必要的信息重复(比如 system prompts),同时每个 Agent 都接收到了超出其范围的上下文内容。为此,我们有必要了解改进上下文管理的几种策略。
03 策略 1:Message Labeling(信息标识)
Message labeling 是调控并提升 AI Agents 任务执行互动效能的重要手段。借由为每次交谈的信息附加元数据标识(metadata),可以智能地筛选出对 Agents 手头任务最为关键的信息。此策略围绕几个关键方法展开:
- Relevance Labeling(相关性信息标识) :每一条信息均应被赋予能够体现其与当前互动乃至未来交流相关性的标签。这一操作包括深入剖析信息内容,并评估其对 Agents 的决策路径是否可能存在益处。譬如,那些含有疑问句、决策节点或独到见解的信息,理应都被标识为极高度相关。
- Permanence Labeling:根据信息的时效性和实用性进行分类这一步极为重要。有些信息,比如含有 foundational decisions (译者注:“foundational decisions” 指的是那些构成行为规划或讨论交流基础的核心决策,通常对后续步骤有深远影响,确立了基本原则、目标或方向。)或 milestone communications (译者注:“milestone communications” 如同国道上的里程牌,指示项目已达成某个重要目标或正进入新阶段。)的信息,因其存在长远价值,应在不同对话环节中持续保存。相比之下,仅供一次性使用的系统通知类信息(system messages),仅在特定上下文下短暂需要。一旦它们的即刻相关性(immediate relevance)消逝,便应从 AI Agents 的存储记忆库(memory)中予以剔除。
- Source and Association Labeling:此步骤会明确每条信息的发出源头,不论是来自某个特定的 Agent 、用户交互过程、功能执行流程或其他程序过程。这种标识有利于建立一个条理清晰、便于追踪的历史记录体系,确保 Agents 能够根据信息的源头或与当前任务的关联度,迅速定位并参考所需资料。
在相关信息的元数据上应用智能标识(smart labels),就能启用智能化选取功能(smart selection)。接下来,我们将进一步列举几个实用示例。
04 策略 2:针对 AI Agents 的不同需求设定不同的上下文
各 Agent 因为任务各异,其上下文需求自然也大不相同。有的 Agent 仅凭少量信息就能执行,而有的则需大量的上下文信息才能确保操作无误。这一策略是对之前所述的信息标识策略的深化应用。
关键上下文要素辨识(Critical Context Identification) :识别哪些信息对 Agents 来说比较重要,并集中精力优化这些要素的处理流程,提升模型响应的精确度,这一点至关重要。以先前交流场景上下文中的第8行为例,用于代码审查的 Agent 仅需少量的特定上下文即可准确完成工作。事实上,若提供给它的上下文超出必要范围,其处理结果反而可能不尽人意。
那么,它究竟需要什么样的上下文呢?粗略一看便可知,用于代码审查的 Agent 仅需关注其 system prompt 及紧邻其前、含有最新版本代码的最后一条 Agent 消息(第6行)。
换言之,每个 AI Agent 都应配置为只选择自己需要的对话历史(上下文)。比如,代码审查 Agent 仅查看最近的两条消息,而代码编写 Agent 则需要更长的上下文历史作为支持。
05 策略 3:优化 System Prompts
指令位置的相关策略(Placement) :当探讨 Agents 及其 system prompts 时,不难发现 Agents 的 system prompts 位置非常重要。它该置于对话序列的起始,还是末尾?对此,目前尚无定论,实际效果依具体应用场景而异。试想,哪种位置设计能更好地促进信息的处理与反馈?
1) user: "I visited dr. Fauci on Thursday, and got diagnosed with …"
2) system: "Extract all medically relevant info from the user prompt"
- 1
- 2
或者
1) system: "Extract all medically relevant info from the user prompt"
2) user: "I visited dr. Fauci on Thursday, and got diagnosed with …"
- 1
- 2
若在更大规模且复杂多变的对话历史中进行尝试,你会观察到即便是相同的引导语,由于位置不同,最终效果也会有所区别。不过有一点显而易见,system prompts 应当有意识地被放置在某一特定位置,而这一决策需依据 Agents 特性和实际应用场景来决定。
注意:从我的实践经验来看,system prompt 是否应当设置为对话序列的最后一条信息,很大程度上取决于所使用的大语言模型(LLM)。通常情况下,将其置于末位是个不错的选择(当然也有例外,比如信息抽取(information extraction)任务中)。
持久性考量策略(Permanence) :此外,除了 system prompts 的位置安排外,大多数情况下,还必须确保 system prompts 被标记为 “fleeting” 。这里说的“fleeting message(瞬态消息)”,意味着一旦其作用发挥完毕,就不会在对话记录(上下文)中继续留存。
以 agent1 为例,它可能首先接收到一条指令(prompt),要求其暂时搁置问题进行反思(step back and reflect on the problem)。紧接着的下一轮交互环节,agent1 又被要求依据之前的反思来解决问题。在这种情况下,第二次交互时初始的提示词(反思)不仅多余,反而可能干扰 Agents ,导致解答质量下滑。因此,如若那条初始的 system prompt 能够设定为非持久性的,即在之后的交互中不再重复发送给 Agents ,处理效果将会更佳。具体到下述例子,这意味着当第二次向 Agents 发起 LLM 查询请求时,应将第 2 行信息剔除在外。
#1 User: "What is the meaning of the universe?" #2 System: "You're a philosopher; before you answer, step back and reflect on what the user's question implies." #3 Agent_philo: "Reflecting on this question, one can consider the universe through various philosophical lenses - existentialism views it as a canvas for creating personal meaning, while cosmology sees it as a playground for understanding physical laws. This interplay between human perception and scientific exploration is central to understanding our query." #4 System: "You're a philosopher, and you just reflected deeply on the question posed by the user. Use that insightful reflection to craft a comprehensive answer." #5 Agent_philo: "From an existentialist perspective, the meaning of the universe is a personal journey, where each individual constructs their own meaning through choices and life experiences. In contrast, from a cosmological viewpoint, it is about exploring and understanding the vast, intricate laws that govern the cosmos. These perspectives help us grasp the multifaceted nature of our universe, blending our existential quests with scientific inquiry."

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
通过这种方法,所有陈旧的 system prompt 都将从对话序列中清理出去,每条 system prompt 都会被安排在最合适的位置。这样一来,对话记录(上下文记录)将会变得干净而有序,为双方提供了更精确与更可预测的互动环境。
06 策略 4:精简 RAG 系统中的冗余信息
关于如何通过优化 RAG 系统来增强 Agents 效率的话题,我们足以撰写一系列文章详述,但在此仅简明扼要地概述几条。由于 RAG 操作可能导致大量的 tokens 消耗,掌握一些管理此问题的技巧显得尤为重要。 若你对该技术方向尚不够熟悉,强烈建议你投入足够的时间深入研究。
初级的 RAG 教程往往假定用户上传的文档简洁、直白、明了,但在实际应用中,大多数文档结构复杂且内容多变。 根据我的经验,许多文档具有大量重复信息,比如同一份 PDF 文章的引言、正文和结论中经常会复述同一内容;一份医疗记录中可能会频繁出现几乎雷同的医疗信息;或是系统日志记录中不断重复的日志记录。尤其在生产环境下,面对海量文件检索时,标准 RAG 流程返回的内容往往会异常冗余,重复度极高。
合理应对重复内容(Dealing with Duplicates) :优化 RAG 系统上下文的第一步是识别并剔除检索文档片段中的确切重复内容及近似重复内容,以防信息冗余。确切的重复内容(Exact duplicates)易于辨认,而近似重复内容(Near duplicates)则可通过语义相似性分析(semantic similarity)、向量嵌入的多样性(diversity of vector embeddings)度量(差异大的文档片段其向量间距离较远)等多种技术来检测。如何执行这一操作极大程度上取决于具体应用情景。这里[1]提供了一些按困惑度(perplexity)分类的实例。
模型响应内容多样化(Diversity in Responses) :确保 RAG 系统输出多样性的方式主要是巧妙地整合来自多个文件的内容。其中一种简便且高效的策略是,在检索时不单纯依据语义相似度(similarity)选取最高的 N 篇文档,而是在检索查询(retrieval query)中使用 GROUP BY 语句。再次强调,是否采取这一策略,高度取决于具体需求场景。这里[2]也提供了一个按困惑度分类的实例。
动态检索(Dynamic Retrieval) :既然本文聚焦于动态上下文的构建,那么如何将这一思想融入 RAG 流程中呢?传统的 RAG 流程通常只提取排名前 N 的结果,比如最相关的 10 段文档片段。但这并不符合人们检索信息的方式。在搜索信息时,人们一般会使用搜索引擎持续探索,直至找到满意答案,可能想要的内容就在搜索结果的第一页,也可能在第二页甚至更后。当然,这取决于个人的耐心与运气

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

