
- 1SpringAI集成本地AI大模型ollama(调用篇)非常简单!!_springboot ollama
- 2DotNetGuide新增C#/.NET/.NET Core充电站(让你学习不迷路)
- 3SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】_springboot lucene
- 4使用 Dify 和 AWS Bedrock 玩转 Anthropic Claude 3_bedrock claudw 3
- 5华为OD机试C卷-- 机场航班调度程序(Java & JS & Python & C)
- 6人工智能法律专业知识库:构建法律知识的基础设施
- 7网站运营最全总结_地方门户网站运营计划书
- 8linux系统日志message 分析,Linux系统日志及日志分析
- 9axios 封装 http 请求详解_axios封装请求
- 10coding:Permission denied (publickey)._coding permission denied (keyboard-interactive,pub
【论文笔记】Air Combat Strategy using Approximate Dynamic Programming 基于近似动态规划的空战策略
赞
踩
论文:Air Combat Strategy using Approximate Dynamic Programming (2010年)
目录
I.A. Approach Summary 论文思路方法总结
II. Approximate Dynamic Programming Method 近似动态规划方法
II.A. Dynamic Programming Example 动态规划案例
II.B. Approximate Dynamic Programming Example 近似动态规划
III. ADP Applied to Air Combat
III.A. States, Goal, Control Inputs and Dynamics
III.C. Feature Development 状态特征
III.F. On-line Policy Extraction
IV. Simulation and Flight Tests
论文阅读总结
1、近似动态规划的主要还是根据状态对状态值的拟合,使用函数拟合将离散状态扩展到连续状态。可以参考强化学习中值函数的参数拟合法
2、
3、
论文阅读分析
I. Introduction
尽管导弹技术发展进步,但近距空战依旧重要。目前无人机在军事和商业任务中逐渐取代了有人机,但由于空战动态性的本质,使得无人机依旧依托有人平台。例如2002年远程操控MQ-1进行combat,这种方法是一个飞行员对应一个无人机,并没有发挥出无人机的优势,自动控制决策的能力成为了一种需求。
论文的目的在于提出一种在线计算近似优化的决策方案。这要求一个较长的规划域,例如,人类飞行员在长期目标的框架内做出近期机动决策,这对成功进行空战至关重要,但是目前的方法无法满足这种复杂的计算。文中使用近似动态规划approximate dynamic programming (ADP)来解决空战问题。文中的方法比当前的方法改进了18.7%,比专家性能改进了6.9%。
I.A. Approach Summary 论文思路方法总结
The goal of air combat is to maneuver your aircraft into a position of advantage on the other aircraft,
from either an offensive or defensive starting position, while minimizing risk to your own aircraft.
空战的目标是使己方的飞行器从进攻或者防御的初始位置,机动到相比对方飞行器占优的位置,同时使自身风险最小化。
论文的目标是提出一种实时在线计算的方法,能够融合一个长规划时域,在没有专家经验知识的前提下计算机动控制时序,并可以完成攻防角色的相互转化。DP有计算机动策略的潜力,但exact的DP方法很难完成复杂的博弈问题,一个近似的方法可以得到较好的结果。在实现ADP算法中,论文提出了四个创新点,extensive feature development, trajectory sampling, reward shaping and an improved policy extraction technique。
I.B. Literature Review 文献回顾
Virtanen et al.[6]使用影响图方法建模,使用动态规划来解决,这种方法使用有限的规划域,只是缓解了计算的复杂度。
其他方法例如有限搜索、基于规则、非线性模型预测控制。
Austin et al[7,8]提出了博弈论递归搜索,这种方法在短的规划域中得到最优,而且必须使用一个启发式打分矩阵,这种方法得到的机动策略与专家经验类似。
Burgin and Sidor[9]提出了一个基于规则的自适应机动项目,在仿真实验中成功的与人进行对抗。但这种方法时间消耗太大,并且经验进行编码和人工评估以及机动选择的参数调整比较复杂。
文献[10,11]提出了一种非线性模型预测轨迹控制发方法,可以提供一种实时的方法实现躲避控制,算法没有能力实现追逃角色的转换。
II. Approximate Dynamic Programming Method 近似动态规划方法
由于离散状态空间及其参数变量的指数增长,动态规划无法实现大量的计算。该部分利用一个简单的实例(最短路径)来说明动态规划和近似动态规划。
II.A. Dynamic Programming Example 动态规划案例
最短路径动态规划问题,如图4*4的方格,机器人一步移动一格,四种动作{up, down, left, right}. 机器人的位置表示[行,列]([row; column]),状态转移函数

定义
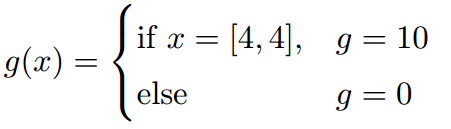
贝尔曼方程:
![]()
优化动作为:
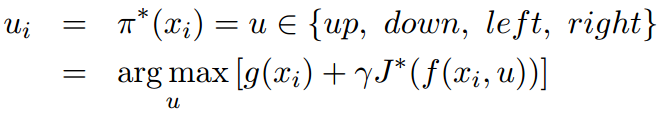
【问题】
根据文中对回报值的设计,使用动态规划算法得到的结果与Figure1(b)的结果不同,得到的结果如下:
| k = 0 | k = 1 | k = 2 | k = 3 | k = 4 | k=100 | ||||||||||||||||||||||||
| < | |||||||||||||||||||||||||||||

