
- 1nginx-ingress详解_ingress-nginx
- 22022-10-09 Android app禁止截屏方法 和 在禁止截屏的情况下录制屏幕_app安卓如何禁止用户截图
- 3Flink的安装部署_jobmanager.rpc.address
- 4uni-app 是一个使用 Vue.js 开发跨平台应用的前端框架_什么app用了vue前端
- 5Mac上有哪些虚拟机软件?性能兼容性都怎么样该如何下载安装_mac 虚拟机
- 6Java携带证书访问Https,Keytool+Tomcat实现SSL双向认证_java使用ssl携带证书访问
- 7SVM(三):对偶问题最直白解释_svm对偶问题
- 8振动信号的阶次分析(matlab)_matlab 阶次分析
- 9人工智能与地理大数据实验--出租车GPS数据—时空大数据Python处理基础(一)_taxidata-sample.csv 在哪下载
- 102010年第一届蓝桥杯省赛 —— 第二题_蓝桥杯省赛2010年多功能红外控制器
Kafka生产者优秀架构原理及发送流程剖析
赞
踩
点击上方蓝色“胖滚猪学编程”,选择“设为星标”
跟着胖滚猪学编程!好玩!有趣!
如果阅读了别网上找个demo就以为掌握了Kafka生产者一文,你肯定已经会玩Kafka生产者了:你知道怎么发送消息了,你知道怎么保证消息不丢失、不重复以及顺序性。那为什么还要有今天这篇文章?因为你会玩还不行,还得玩的6。
你会说"我又不当commiter,没必要研究这么深啊"
其实不然,作为应用者,如果你不研究透彻,很多生产问题你也无法解决,比如:
"为什么我的报表数据不准呢?和源头数据对不上是怎么回事?"
"为什么吞吐量提升不上来呢?怎么优化?"
那么今天就通过源码了解一下kafka生产者优秀的架构设计、以及完整的发送流程、参数调优。
Kafka发送流程
看源码是最直观的了解发送流程的方法,我删减了一部分,留下了最重要的并加以了注释,现在你只看我的注释就好,回去再自己对着idea一句句啃:
- private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
- TopicPartition tp = null;
-
- // 1、获取集群元信息
- ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
- Cluster cluster = clusterAndWaitTime.cluster;
-
- //2、序列化key和value
- byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
-
- //3、封装分区对象
- int partition = partition(record, serializedKey, serializedValue, cluster);
- tp = new TopicPartition(record.topic(), partition);
-
- //4、确认消息大小是否合法
- ensureValidRecordSize(serializedSize);
-
- // 5、给每一条消息绑定它的回调函数
- Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
-
- //6、把消息放到accumulator(32M的一个内存) 由accumulator把消息封装成一个一个批次去发送
- RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
- serializedValue, headers, interceptCallback, remainingWaitMs);
-
- //批次满了或者新创建出来一个批次
- if (result.batchIsFull || result.newBatchCreated) {
- //7、唤醒sender线程 它是真正发送数据的线程
- this.sender.wakeup();
- }
- return result.future;
- }

用一张图归纳吧,图形才是最直观的: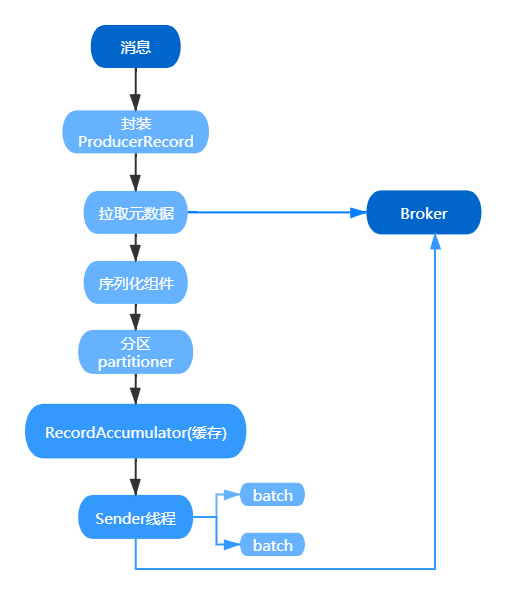
如上图所示:
步骤一:一条消息过来首先会被封装成为一个 ProducerRecord 对象。
步骤二:会拉取集群的元数据,分区的时候需要获取集群的元数据。
步骤三:对这个对象进行序列化,因为 Kafka 的消息需要从客户端传到服务端,涉及到网络传输,所以需要实现序列。Kafka 提供了默认的序列化机制,也支持自定义序列化(这种设计也值得我们积累,提高项目的扩展性)。
步骤四:消息序列化完了以后,对消息要进行分区。分区的这个过程很关键,因为这个时候就决定了,我们的这条消息会被发送到 Kafka 服务端到哪个主题的哪个分区了。
步骤五:分好区的消息不是直接被发送到服务端,而是放入了生产者的一个缓存里面。accumulator(32M的一个内存)。在这个缓存里面,多条消息会被封装成为一个批次(batch),默认一个批次的大小是 16K。
步骤六:Sender 线程启动以后会从缓存里面去获取可以发送的批次。把一个一个批次发送到服务端。
我觉得大家唯一不明白的可能就是那个accumulator以及batch,它也正是kafka生产者优秀的架构设计。在 Kafka0.8 版本以前,Kafka 生产者的设计是来一条数据,就往服务端发送一条数据,频繁的发生网络请求,结果性能很差。后面的版本再次架构演进的时候把这儿改成了批处理的方式,性能指数级的提升。我们来分析一下这种设计吧。
Kafka优秀的架构设计
生产者架构设计的精华就在于刚刚说到的缓存,消息会先放到一个缓存里,达到一定批次再发送,这样可以提高吞吐量,那么这个缓存是啥呢?
我们先看一张图,看不懂没关系,你只需要大概知道,这个缓存块里面有一个重要的数据结构:batches,这个数据结构是 key-value,key 就是消息主题的分区,value 是一个队列,即一个分区会对应一个队列,队列里面存的是发送到对应分区的批次,批次肯定要开辟内存空间的,所以还有了内存池负责开辟空间。Sender 会把这些批次发送到服务端。
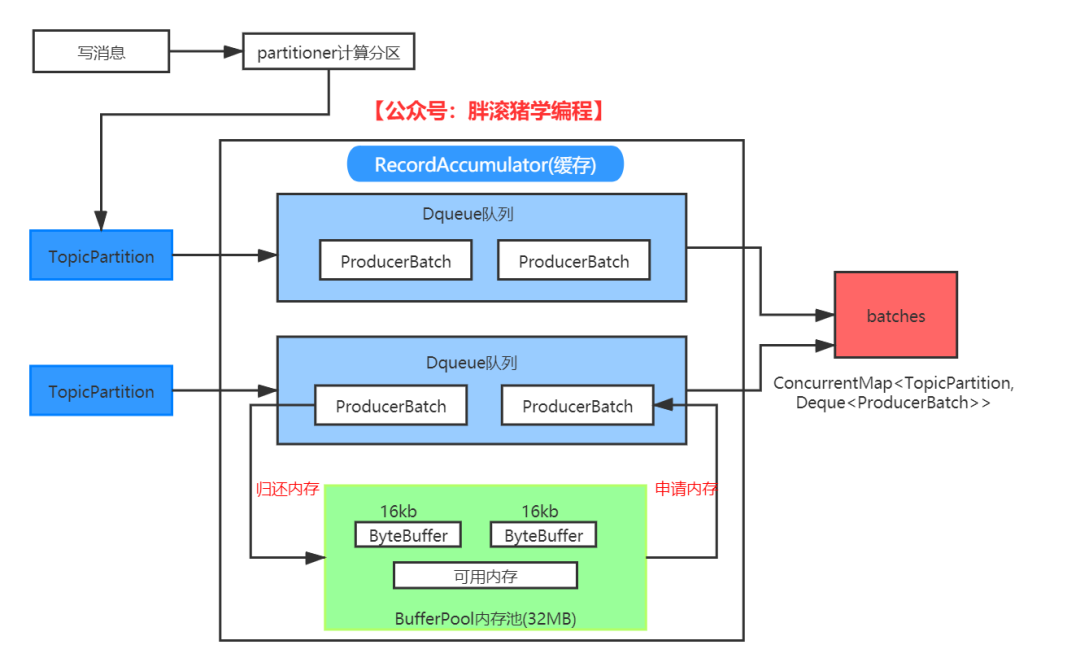
具体我们还得根据源码一句句抠,点击accumulator.append进入源码里,我们删减了一部分,留下来最重要的
- // 步骤一:根据分区找到应该插入到哪个队列里 有则使用 无则创建
- Deque<ProducerBatch> dq = getOrCreateDeque(tp);
- synchronized (dq) {
- if (closed)
- throw new KafkaException("Producer closed while send in progress");
- //步骤二:尝试往队列里面添加数据 第一次肯定是失败的 会为null
- RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
- if (appendResult != null)
- return appendResult;
- }
-
-
- byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
- //步骤三:计算一个批次的大小 取消息大小和批次大小的最大值 因此我们应该根据消息大小设置批次大小 不然批次就没作用了
- int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
-
- //步骤四:根据批次大小去内存池分配内存
- buffer = free.allocate(size, maxTimeToBlock);
- synchronized (dq) {
- RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
- if (appendResult != null) {
- return appendResult;
- }
- //真正分配出一个批次来
- MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
- ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
- //线程往这个批次写数据、就写入成功了
- FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
- //把这个批次放入队列的队尾
- dq.addLast(batch);
- incomplete.add(batch);
那么这段代码有什么值得我们学习的架构设计呢?
CopyOnWriteMap读写分离设计典范
我们来研究一下batches到底是个什么东西:
ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches = new CopyOnWriteMap<>();
如果了解Java J.U.C包的话,你会知道有个叫做CopyOnWriteArrayList但是没有CopyOnWriteMap,这个是Kafka自己开发出来的数据结构。
CopyOnWrite,顾名思义就是写的时候会将共享变量新复制一份出来,完成操作后将副本数组引用赋值给容器。而读操作是完全无锁的。实现了读写分离。
我们根据图形看一下CopyOnWriteArrayList的实现原理:
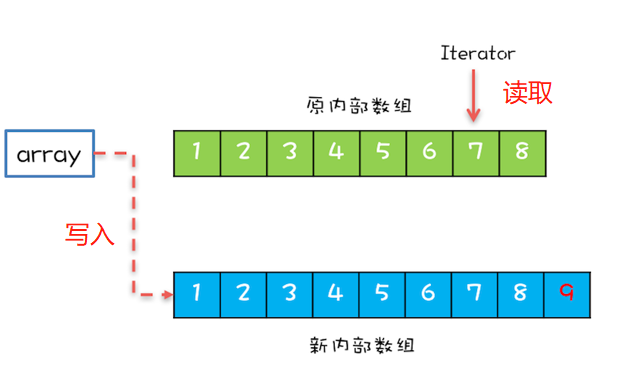
现在你已经了解这种思想了,那我们看看Kafka中的CopyOnWriteMap是怎么实现的,以put为例:
- @Override
- //synchronized保证线程安全
- public synchronized V put(K k, V v) {
- //每次都开辟一块新的内存空间 做到了读写分离
- //往新的内存空间里面插入 读数据是从老的里面
- Map<K, V> copy = new HashMap<K, V>(this.map);
- V prev = copy.put(k, v);
- this.map = Collections.unmodifiableMap(copy);
- return prev;
- }
而get操作不需要加锁,因此性能很高:
- @Override
- public V get(Object k) {
- return map.get(k);
- }
没有最好的数据结构只有最适合的数据结构,显然CopyOnWriteMap适合读多写少的情况。那么在这里是不是读多写少呢?显然是的。
什么情况下会写:当要创建新的队列的时候才会写(putIfAbsent),一个分区只会创建一个队列,你能有几个分区呀?一般不会过百吧。
- private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
- //直接从batches里面获取当前分区对应的存储队列
- Deque<ProducerBatch> d = this.batches.get(tp);
- if (d != null)
- return d;
- //创建出来一个新的队列
- d = new ArrayDeque<>();
- //把这个空的队列存入batches数据结构里
- Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
- if (previous == null)
- return d;
- else
- return previous;
- }
什么情况下会读:还是上面那段代码,每来一条消息都要执行this.batches.get(tp),你能有多少消息?成千上万都不止啊。
内存池
我们可能比较熟悉线程池?线程池有哪些好处?没有线程池每次都要 new Thread 新建对象,性能差,而利用线程池,重用存在的线程,减少对象创建、消亡的开销,性能好!
内存池也是一样的。刚刚我们看到 batches 里面存储的是批次,批次默认的大小是 16K,生产者每封装一个批次都需要去申请内存,正常情况下如果一个批次发送出去了以后,那么这 16K 的内存就等着 GC 来回收了。但是如果是这样的话,就可能会频繁的引发 FullGC,故而影响生产者的性能。
所以在缓存里面设计了一个内存池,一个 16K 的内存用完了以后,把数据清空,放入到内存池里,下个批次用的时候直接从里面获取就可以。这样大大的减少了 GC 的频率,保证了生产者的稳定和高效。Java 的 GC 问题是一个头疼的问题,所以这种设计也非常值得我们去学习。
分段加锁
我们可以看到上面这段代码中有多次用到了synchronized加锁:
- synchronized (dq) {
-
-
- }
为什么不直接在方法头加锁呢?这就是一种优秀的架构设计:分段加锁,减小锁的粒度。
Kafka生产者参数
生产者参数很重要,除了上一篇文章我们提到的,序列化参数、消息可靠性的参数(acks、retries)、分区参数(partitioner.class)、幂等参数(enable.idempotence)。
还有很多非常重要的参数,那么我今天想告诉你,到底该怎么去寻找这些参数、怎么配置、怎么看默认值。显然我不会告诉你去"百度"、因为百度到的是别人的答案,不一定符合你的业务需求。
首先我们回到上文源码中,有这么一句话:
- //4、确认消息大小是否合法
- ensureValidRecordSize(serializedSize);
这里就涉及到两个重要参数了:
- /**
- * Validate that the record size isn't too large
- */
- private void ensureValidRecordSize(int size) {
- if (size > this.maxRequestSize)
- throw new RecordTooLargeException("The message is " + size +
- " bytes when serialized which is larger than the maximum request size you have configured with the " +
- ProducerConfig.MAX_REQUEST_SIZE_CONFIG +
- " configuration.");
- if (size > this.totalMemorySize)
- throw new RecordTooLargeException("The message is " + size +
- " bytes when serialized which is larger than the total memory buffer you have configured with the " +
- ProducerConfig.BUFFER_MEMORY_CONFIG +
- " configuration.");
- }
我们看到首先会判断消息的大小是否超过ProducerConfig.MAX_REQUEST_SIZE_CONFIG,即"max.request.size",那么它的默认值是多少呢,我先告诉你是1mb,假如你的消息比较大,超过这个数,那就直接报错了,因此你需要根据业务需求来调整这个参数。(另外注意一下broker端同样有个参数是必须要设置的,max.message.bytes,它决定了 Kafka Broker 能够正常 接收该 Topic 的最大消息大小)。
那我调整成50mb吧,不行!看下面还有一段话,不能超过缓存内存大小,刚刚我们说到了是32mb,如果你消息真有50mb,那么这个参数你同样需要调整。
那么我怎么知道这个参数是什么意思,怎么知道它的默认值呢?其实都参考ProducerConfig这个类就可以了。我们进去这个类,再看一个重要参数:
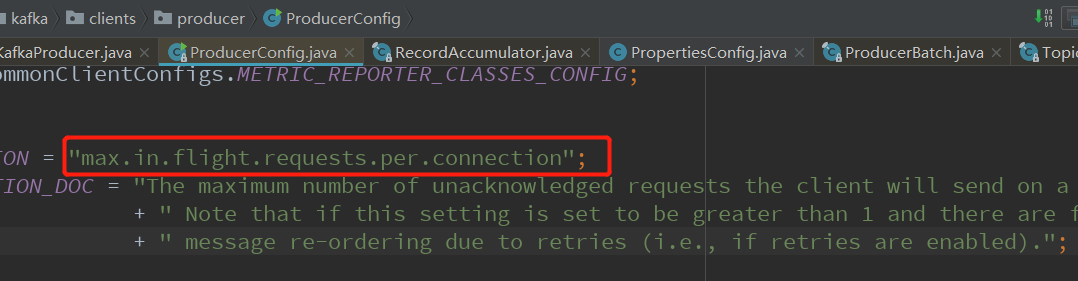
参数下面就对应着_DOC,它的参数说明。而默认值全部在define里,我们可以看到默认是5:
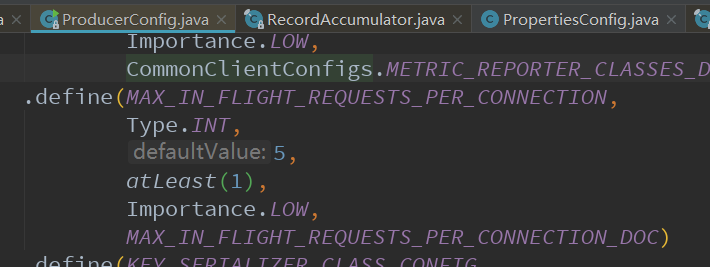
所以啊,别每次配置参数或者找默认值都靠百度, 完全一个类就可以告诉你全部信息啊。
我为啥要说这个参数?涉及到一个很重要的乱序问题。首先你已经明白kafka只能保证分区内的顺序性。那么同一分区消息乱序怎么办?假设a,b两条消息,a先发送后由于发送失败重试,这时顺序就会在b的消息后面,可以设置max.in.flight.requests.per.connection=1来避免,它限制客户端在单个连接上能够发送的未响应请求的个数。设置此值为1表示kafka broker在响应请求之前client不能再向同一个broker发送请求,但吞吐量会下降。
好了,写到这里,我归纳一下Kafka生产端那些参数吧:
acks: 设置为all是最可靠的保证。
buffer.memory: 生产者可以用来缓冲等待发送到服务器的记录的内存的总字节数,简单说就是缓冲区大小。默认32M,可以调大一点。
max.request.size: 发送一条消息的最大大小
compression.type :设置压缩,压缩的好处不用多说,减少磁盘IO、减少存储所需空间等等。比如可以设置为snappy。
retries: 重试次数,将值设置为大于零将导致客户端重新发送任何发送失败的记录。默认是0,我们可以设置为100。
batch.size: 批处理大小(字节为单位)。发送消息会一个批次一个批次的发,这有助于提高客户机和服务器的性能。此参数就是设置批次大小。默认16384(16k)。务必根据业务消息大小来设置。比如一条消息1mb,那么你批次大小起码设置2mb以上,才是批次发送。
linger.ms:kafka.producer 会将两个请求发送时间间隔内到达的记录合并到一个单独的批处理请求中。这个设置为批处理的延迟提供了上限:一旦我们接受到记录超过了分区的 batch.size ,Producer 会忽略这个参数,立刻发送数据。但是如果累积的字节数少于 batch.size ,那么我们将在指定的时间内“逗留”(linger),以等待更多的记录出现。
request.timeout.ms :配置控制客户端等待请求响应的最大时间量。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,如果重试结束,则将失败请求。经验:跟超时时间有关的,都调大几倍。
delivery.timeout.ms:报告成功或失败的时间上限。应该大于linger.ms + request.timeout.ms。
max.block.ms:控制了KafkaProducer.send()和KafkaProducer.partitionsFor()将会阻塞多长时间。由于缓冲区已满或元数据不可用,可以阻塞这些方法。建议调大一点此参数。
max.in.flight.requests.per.connection:防止乱序可以配置该参数为1来避免,它限制客户端在单个连接上能够发送的未响应请求的个数。
enable.idempotence:需要幂等性可配置该参数
现在你应该可以对开头提到的两个问题迎刃而解了吧?为什么吞吐量低?看下是不是batchsize参数没配置好,要充分利用批次发送带来的高性能。为什么数据对不上?看下是不是乱序了,如果是的话限制一下客户端在单个连接上能够发送的未响应请求的个数。其实通过参数还可以优化非常多的问题,靠你自己去发现了哦!
END
点击查看往期内容回顾
原创声明:本文为公众号【胖滚猪学编程】原创博文,转载注明出处!
点个“在看”表示朕
已阅
本人只是kafka小学生,如果有任何不对的地方,请各位大学生一定要指正我,留言写起来!
写留言

