使用阿里云AIGC和Megatron-Deepspeed高效训练GPT-2:文本生成实战
赞
踩
本文介绍如何使用GPU云服务器,使用
Megatron-Deepspeed框架
训练GPT-2模型并生成文本。
背景信息
GPT-2模型是OpenAI于
2018年在GPT模型
的基础上发布的新的
无监督NLP模型
,当时被称为“史上最强通用NLP模型”。该模型可以生成
连贯的文本段落
,并且能在
未经预训练
的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。GPT-2模型尤其在文本生成上有着惊艳的表现,其生成的文本在上下文连贯性和情感表达上都超过了人们的预期。
GPT-2模型由
多层单向Transformer的解码器
部分构成,根据模型层次规模,GPT-2模型有以下几个规格:

Megatron-Deepspeed框架结合了两种主要技术:
- Megatron-LM是由NVIDIA开源的Transformer 模型框架。
- DeepSpeed
是由Microsoft开源的一个
深度学习优化库
。
DeepSpeed团队通过将
DeepSpeed库中的
ZeRO分片(ZeRO sharding)
数据并行(Data Parallelism)和
管道并行(Pipeline Parallelism
)与Megatron-LM中的
张量并行(Tensor
Parallelism)相结合,开发了一种
基于3D并行
的实现,这就是Megatron-Deepspeed,它使得千亿级参数量以上的大规模语言模型(LLM)的分布式训练变得更简单、高效和有效。
本文基于阿里云GPU服务器,使用Megatron-Deepspeed框架训练GPT-2模型并生成文本。
重要
- 阿里云不对第三方模型“GPT-2”的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
- 您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
创建ECS实例
在
ECS实例创建页面
,创建ECS实例。
关键参数说明如下,其他参数的配置,请参见
自定义购买实例
。
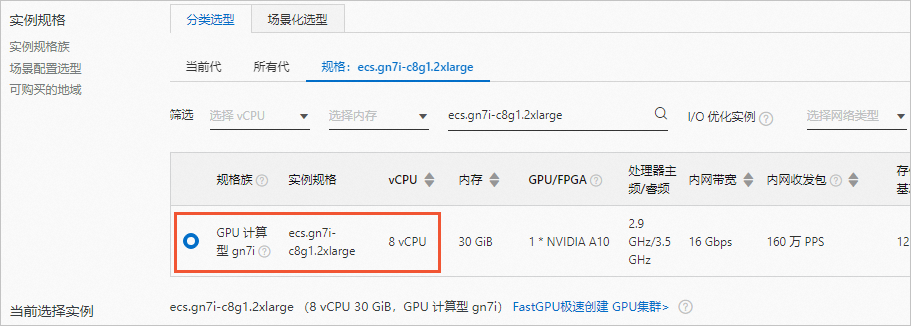
- 实例规格
:选择
ecs.gn7i-c8g1.2xlarge
(单卡NVIDIA A10)。
- 镜像
:使用云市场镜像,名称为
aiacc-train-solution
,您可以直接通过名称搜索该镜像,选择最新版本即可。

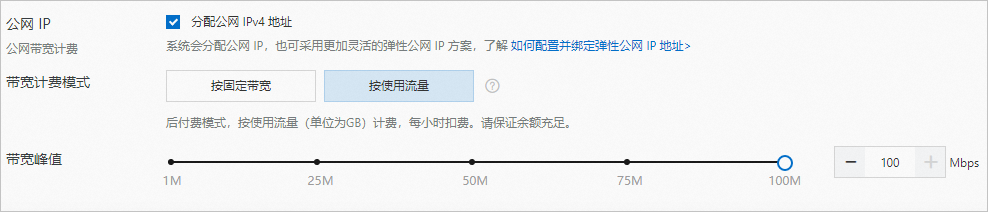
- 公网IP
:选中
分配公网IPv4地址
,带宽计费方式选择
按使用流量
,带宽峰值选择
100
Mbps,以加快模型下载速度。
安装Megatron-Deepspeed框架
- 使用root用户远程登录ECS实例。具体操作,请参见
通过密码或密钥认证登录Linux实例
。 - 执行以下命令,启动容器。
docker run -d -t --network=host --gpus all --privileged --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --name megatron-deepspeed -v /etc/localtime:/etc/localtime -v /root/.ssh:/root/.ssh nvcr.io/nvidia/pytorch:21.10-py3
- 1
- 执行以下命令,进入容器终端。
docker exec -it megatron-deepspeed bash
- 1
- 执行以下命令,下载Megatron-DeepSpeed框架。
git clone https://github.com/bigscience-workshop/Megatron-DeepSpeed
- 1
- 执行以下命令,安装Megatron-DeepSpeed框架。
cd Megatron-DeepSpeed
pip install -r requirements.txt
- 1
- 2
处理数据
本指南使用1GB 79K-record的JSON格式的OSCAR数据集。
- 执行以下命令,下载数据集。
wget https://huggingface.co/bigscience/misc-test-data/resolve/main/stas/oscar-1GB.jsonl.xz
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt
- 1
- 2
- 3
- 执行以下命令,解压数据集。
xz -d oscar-1GB.jsonl.xz
- 1
- 执行以下命令,预处理数据。
python3 tools/preprocess_data.py \
--input oscar-1GB.jsonl \
--output-prefix meg-gpt2 \
--vocab gpt2-vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file gpt2-merges.txt \
--append-eod \
--workers 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果回显信息类似如下所示,表示预处理数据完成。
4. 执行以下命令,新建data目录。
mkdir data
- 1
- 执行以下命令,将处理好的数据移动到data目录下。
mv meg-gpt2* ./data
mv gpt2* ./data
- 1
- 2
预训练
本示例使用单机单卡的GPU实例完成GPT-2 MEDIUM模型的预训练。
-
创建预训练脚本文件。
- 执行以下命令,创建预训练脚本文件。
vim pretrain_gpt2.sh- 1
- 按
i
键,进入编辑模式,在文件中添加以下信息。
#! /bin/bash # Runs the "345M" parameter model GPUS_PER_NODE=1 # Change for multinode config MASTER_ADDR=localhost MASTER_PORT=6000 NNODES=1 NODE_RANK=0 WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES)) DATA_PATH=data/meg-gpt2_text_document CHECKPOINT_PATH=checkpoints/gpt2 DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT" python -m torch.distributed.launch $DISTRIBUTED_ARGS \ pretrain_gpt.py \ --tensor-model-parallel-size 1 \ --pipeline-model-parallel-size 1 \ --num-layers 24 \ --hidden-size 1024 \ --num-attention-heads 16 \ --micro-batch-size 4 \ --global-batch-size 8 \ --seq-length 1024 \ --max-position-embeddings 1024 \ --train-iters 5000 \ --lr-decay-iters 320000 \ --save $CHECKPOINT_PATH \ --load $CHECKPOINT_PATH \ --data-path $DATA_PATH \ --vocab-file data/gpt2-vocab.json \ --merge-file data/gpt2-merges.txt \ --data-impl mmap \ --split 949,50,1 \ --distributed-backend nccl \ --lr 0.00015 \ --lr-decay-style cosine \ --min-lr 1.0e-5 \ --weight-decay 1e-2 \ --clip-grad 1.0 \ --lr-warmup-fraction .01 \ --checkpoint-activations \ --log-interval 10 \ --save-interval 500 \ --eval-interval 100 \ --eval-iters 10 \ --fp16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 按
Esc
键,输入
:wq
后,按
Enter
键保存文件。
-
修改测试代码。
Megatron源码有一个断言需要注释掉,以保证代码正常运行。
1. 执行以下命令,打开测试代码文件。 ``` vim /workspace/Megatron-DeepSpeed/megatron/model/fused_softmax.py +191 ``` 2. 按 `i` 键,进入编辑模式,在 `assert mask is None, "Mask is silently ignored due to the use of a custom kernel"` 前加 `#` 。  3. 按 `Esc` 键,输入 `:wq` 后,按 `Enter` 键保存文件。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
预训练。
- 执行以下命令,开始预训练。
nohup sh ./pretrain_gpt2.sh &- 1

2. 执行如下命令,可以持续的查看nohup.out的输出,达到监控程序的效果。tail -f nohup.out- 1
如果回显信息类似如下所示,表示预训练完成。
说明
预训练完成大概需要1小时30分钟,如果超时断开了ECS连接,重新远程登录ECS实例后,执行以下命令,继续查看预训练进度。预训练完成后,可以执行
Ctrl+Z
命令退出。docker exec -it megatron-deepspeed bash cd Megatron-DeepSpeed tail -f nohup.out- 1
- 2
- 3
-
(可选)执行以下命令,查看生成的模型checkpoint路径。
本示例生成的模型checkpoint路径设置在
/workspace/Megatron-DeepSpeed/checkpoints/gpt2
。
ll ./checkpoints/gpt2
- 1
使用GPT-2模型生成文本
- 执行以下命令,安装相关依赖。
说明
由于网络原因,执行命令后可能会失败,建议您多次尝试。
pip install mpi4py
- 1
如果回显信息类似如下所示,表示依赖安装完成。

2. 创建文本生成脚本。
1. 执行以下命令,创建文本生成脚本。 ``` vim generate_text.sh ``` 2. 按 `i` 键,进入编辑模式,在文件中增加以下内容。 ``` #!/bin/bash CHECKPOINT_PATH=checkpoints/gpt2 VOCAB_FILE=data/gpt2-vocab.json MERGE_FILE=data/gpt2-merges.txt python tools/generate_samples_gpt.py \ --tensor-model-parallel-size 1 \ --num-layers 24 \ --hidden-size 1024 \ --load $CHECKPOINT_PATH \ --num-attention-heads 16 \ --max-position-embeddings 1024 \ --tokenizer-type GPT2BPETokenizer \ --fp16 \ --micro-batch-size 2 \ --seq-length 1024 \ --out-seq-length 1024 \ --temperature 1.0 \ --vocab-file $VOCAB_FILE \ --merge-file $MERGE_FILE \ --genfile unconditional_samples.json \ --num-samples 2 \ --top_p 0.9 \ --recompute ``` 3. 按 `Esc` 键,输入 `:wq` 后,按 `Enter` 键保存文件。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 执行以下命令,生成文本。
sh ./generate_text.sh
- 1
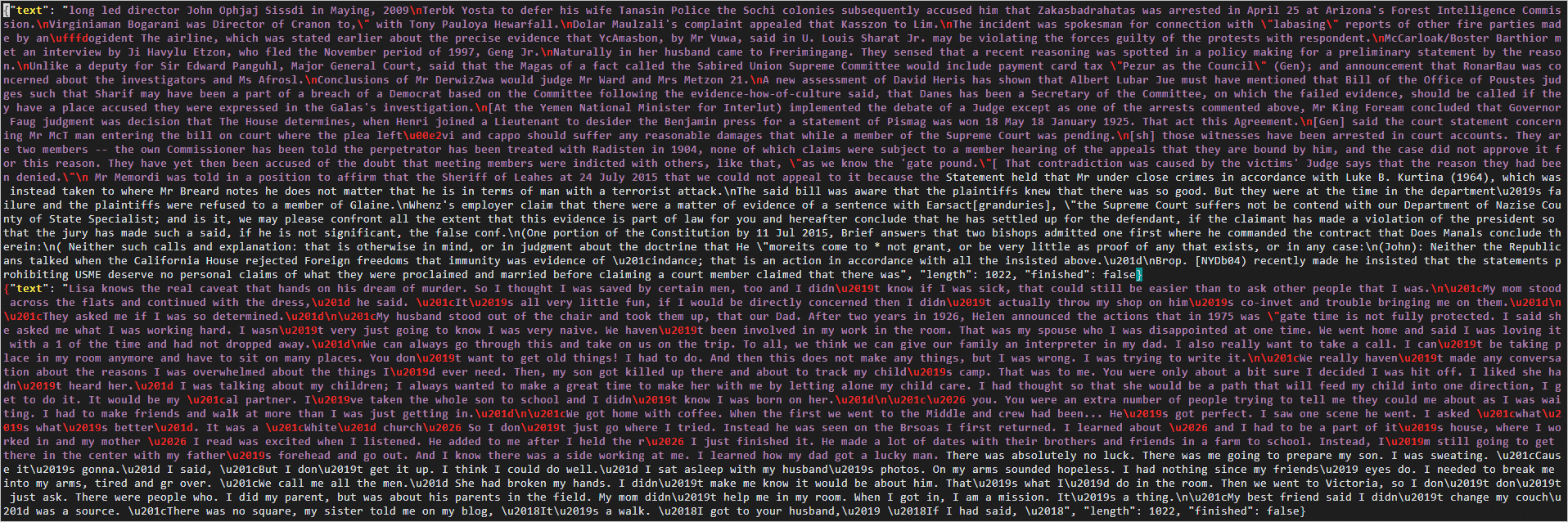
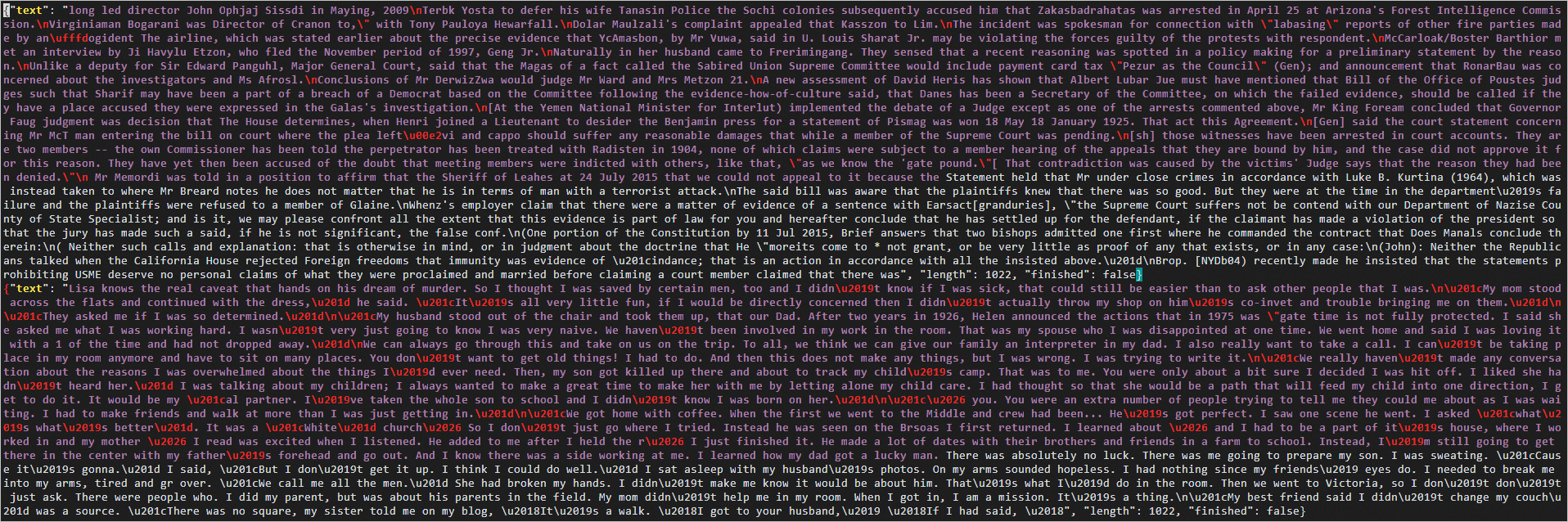
如果回显信息类似如下所示,表示生成文本完成。

4. 执行以下命令,查看生成的JSON格式的文本文件。
vim unconditional_samples.json
- 1
回显信息类似如下所示。