
- 1Joplin Typora 粘贴图片 | 当使用Typora作为Joplin编辑器时,如何粘贴图片并上传到Joplin服务器,替换链接
- 22024年最全Redis配置项汇总(超级详细)_配置库及配置项列表示例,2024年抓住金三银四涨薪好时机_redis参数配置
- 3实验七:定时/计数器8253、8254_8253定时器计数器实验
- 4LORA技术学习 一_lora 空中波特率
- 5XXE外部实体引入漏洞原理及复现_xml外部实体注入漏洞怎么修复
- 6忆龙2009:详解SSH的工作流程_简述ssh协议在整个通信中,服务器端和客户端需要经历的五个阶段
- 7Hadoop实验——熟悉常用的HDFS操作_hdfs的基本操作实验报告
- 8Keil在线或使用调试器调试仿真教程_keil在线调试
- 9SQL Server 查询处理过程_sql server怎么把调试改成查询
- 10企业跨境文件传输的核心痛点,怎样保证稳定可靠的传输性能?
【机器学习】朴素贝叶斯算法:多项式、高斯、伯努利,实例应用(心脏病预测)_机器学习朴素贝叶斯的案例
赞
踩
1. 朴素贝叶斯模型
对于不同的数据,我们有不同的朴素贝叶斯模型进行分类。
1.1 多项式模型
(1)如果特征是离散型数据,比如文本这些,推荐使用多项式模型来实现。该模型常用于文本分类,特别是单词,统计单词出现的次数。
调用方法: from sklearn.naive_bayes import MultinomialNB
1.2 高斯模型
(2)如果特征是连续型数据,比如具体的数字,推荐使用高斯模型来实现,高斯模型即正态分布。当特征是连续变量的时候,运用多项式模型就会导致很多误差,此时即使做平滑,所得到的条件概率也难以描述真实情况。所以处理连续的特征变量,应该采用高斯模型。
调用方法: from sklearn.naive_bayes import GaussianNB
1.3 伯努利模型
(3)如果特征是离散性数据并且值只有0和1两种情况,推荐使用伯努利模型。在伯努利模型中,每个特征的取值是布尔型的,即True和False,或者1和0。在文本分类中,表示一个特征有没有在一个文档中出现。
调用方法: from sklearn.naive_bayes import BernoulliNB
2. 心脏病预测
2.1 数据获取
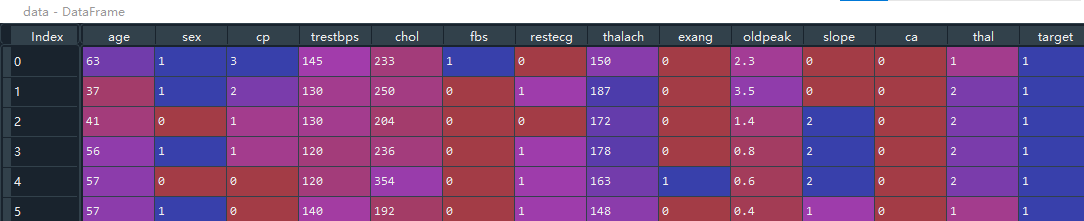
获取心脏病的病例数据,共13项特征值,300多条数据。文末提供数据链接。
#(1)导入心脏病数据
import pandas as pd
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\心脏病\\heart.csv'
data = pd.read_csv(filepath)
- 1
- 2
- 3
- 4
2.2 数据处理
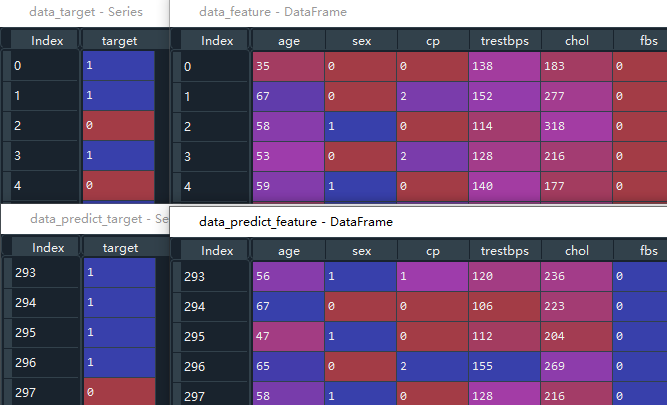
首先将导入的数据重新洗牌,行数据之间随机交换。然后将原始数据拆分成特征值和目标值,特征参数是:胆固醇、年龄等13项数据,目标为target这一列,即是否得了心脏病。为了验证最后预测结果的正确性,取最后10行数据用于模型验证,验证集的特征值数据用于输入最终的预测函数.predict()中,验证集的目标值来检验预测结果是否正确。提取出验证集之后,将用于建模的特征值和目标值删除最后10行即可。
#(2)数据处理
# 重新洗牌,行互换后,让索引从0开始
data = data.sample(frac=1).reset_index(drop=True)
# 提取目标值target一列
data_target = data['target']
# 提取目标值
data_feature = data.drop('target',axis=1)
# 取出最后10行作为验证集
data_predict_feature = data_feature[-10:] #作为最后预测函数的输入
data_predict_target = data_target[-10:] #用来验证预测输出结果的正确性
# 建模用的特征值和目标值删去最后10行
data_feature = data_feature[:-10] #x数据
data_target = data_target[:-10] #y数据
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.3 划分训练集和测试集
一般采用75%的数据用于训练,25%用于测试,因此把数据进行训练之前,先要对数据划分。
划分方式:
x_train,x_test,y_train,y_test = train_test_split(x数据,y数据,test_size=数据占比)
有关划分划分训练集和测试集的具体操作,包括参数、返回值等
#(3)划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(data_feature,data_target,test_size=0.25)
- 1
- 2
- 3
2.4 使用朴素贝叶斯高斯模型
心脏病数据中大多是连续型数据,少数是0、1离散型数据,因此先采用高斯模型进行训练,然后再采用多项式模型训练,对比这两种方法的准确率。
#(4)高斯模型训练
# 导入朴素贝叶斯--高斯模型方法
from sklearn.naive_bayes import GaussianNB
# gauss_nb接收高斯方法
gauss_nb = GaussianNB()
# 模型训练,输入训练集
gauss_nb.fit(x_train,y_train)
# 计算准确率--评分法
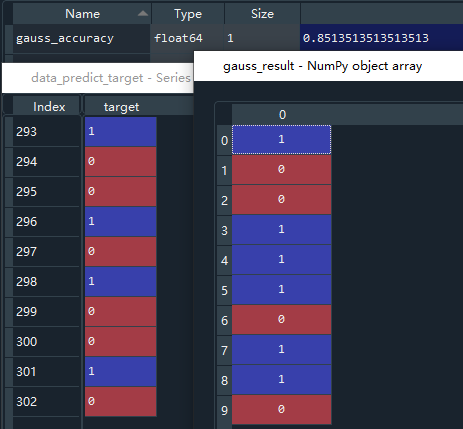
gauss_accuracy = gauss_nb.score(x_test,y_test)
# 预测
gauss_result = gauss_nb.predict(data_predict_feature)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
导入高斯模型方法,gauss_nb接收该方法;使用.fit()函数进模型训练;采用.score()函数用评分法查看模型准确率,根据x_test预测结果,把结果和真实的y_test比较,计算准确率;最终将验证集的特征值传入.predict()函数预测是否得了心脏病,将最终预测结果与真实值比较,发现有少许偏差,模型准确率在0.83左右。
2.5 使用朴素贝叶斯多项式模型
心脏病数据中存在少量的离散数据,实际操作中多项式模型不适用于该案例,我使用多项式模型和高斯模型进行比较,让大家优个直观感受。操作方法和高斯模型类似
#(5)多项式模型训练
# 导入朴素贝叶斯--多项式方法
from sklearn.naive_bayes import MultinomialNB
# multi_nb接收多项式方法
multi_nb = MultinomialNB()
# 多项式方法进行训练,输入训练集
multi_nb.fit(x_train,y_train)
# 评分法计算准确率
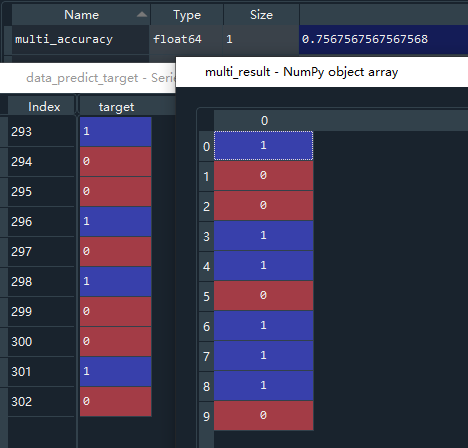
multi_accuracy = multi_nb.score(x_test,y_test)
# 预测
multi_result = multi_nb.predict(data_predict_feature)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
最终的结果为,多项式模型的准确率在0.75左右,预测结果和实际结果相比偏差较大,因此在使用朴素贝叶斯方法,对有较多连续型数据进行分类预测时,高斯模型的准确度明显高于多项式模型。
心脏病数据集自取:
链接:百度网盘 请输入提取码 提取码:a9wl
完整代码展示:
# 朴素贝叶斯高斯模型心脏病预测 #(1)导入心脏病数据 import pandas as pd filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\心脏病\\heart.csv' data = pd.read_csv(filepath) #(2)数据处理 # 重新洗牌,行互换后,让索引从0开始 data = data.sample(frac=1).reset_index(drop=True) # 提取目标值target一列 data_target = data['target'] # 提取目标值 data_feature = data.drop('target',axis=1) # 取出最后10行作为验证集 data_predict_feature = data_feature[-10:] #作为最后预测函数的输入 data_predict_target = data_target[-10:] #用来验证预测输出结果的正确性 # 建模用的特征值和目标值删去最后10行 data_feature = data_feature[:-10] #x数据 data_target = data_target[:-10] #y数据 #(3)划分训练集和测试集 from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(data_feature,data_target,test_size=0.25) #(4)高斯模型训练 # 导入朴素贝叶斯--高斯模型方法 from sklearn.naive_bayes import GaussianNB # gauss_nb接收高斯方法 gauss_nb = GaussianNB() # 模型训练,输入训练集 gauss_nb.fit(x_train,y_train) # 计算准确率--评分法 gauss_accuracy = gauss_nb.score(x_test,y_test) # 预测 gauss_result = gauss_nb.predict(data_predict_feature) #(5)多项式模型训练 # 导入朴素贝叶斯--多项式方法 from sklearn.naive_bayes import MultinomialNB # multi_nb接收多项式方法 multi_nb = MultinomialNB() # 多项式方法进行训练,输入训练集 multi_nb.fit(x_train,y_train) # 评分法计算准确率 multi_accuracy = multi_nb.score(x_test,y_test) # 预测 multi_result = multi_nb.predict(data_predict_feature)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48

