
- 1Spock的@Unroll:准确定位测试的失败点
- 2linux家族:debian和CentOS
- 32024年最新ChatGPT进军网络安全,安全从业者是否会被取代?_chatgpt最新进展
- 4Git和Github的区别_git与github
- 5【算法专题】二分查找_某班级n 位同学的学号为 0到n-1之间。点名结果记录于升序数组records 。假定仅有
- 6pytorch-word2vec的实例实现_word2vec 实例
- 7Agent开发框架:加速Agent开发的利器_agent 开发
- 8nltk.stem 词干提取(stemming)
- 9自动循迹小车_bts7960与stm32
- 10Rabbitmq消息顺序的问题以及解决方案_rabbitmq顺序消息
利用LDA主题模型提取京东评论并做情感分析_lda情感分析
赞
踩
网上购物已经成为大众生活的重要组成部分。人们在电商平台上浏览商品和购物,产生了海量的用户行为数据,其中用户对商品的评论数据对商家具有重要的意义。利用好这些碎片化、非结构化的数据,将有利于企业在电商平台上的持续发展,对这部分数据进行分析,依据评论数据来优化现有产品也是大数据在企业经营中的实际应用。
本章主要针对用户在电商平台上留下的评论数据,对其进行分词、词性标注和去除停用词等文本预处理。基于预处理后的数据进行情感分析,并使用LDA主题模型提取评论关键信息,了解用户的需求、意见、购买原因,以及产品的优缺点,最终提出改善产品的建议。
一、背景与挖掘目标
随着电子商务的迅速发展和网络购物的流行,人们对于网络购物的需求变得越来越高,也给电商企业带来巨大的发展机遇,与此同时,这种需求也推动了更多电商企业的崛起,引发了激烈的竞争。而在这种激烈竞争的大背景下,除了提高商品质量、压低价格外,了解更多消费者的心声对电商企业来说也变得越来越有必要。其中非常重要的方式就是对消费者的评论文本数据进行内在信息的分析。
评论信息中蕴含着消费者对特定产品和服务的主观感受,反应了人们的态度、立场和意见,具有非常宝贵的研究价值。一方面,对企业来说,企业需要根据海量的评论文本数据去更好的了解用户的个人喜好,从而提高产品质量,改善服务,获取市场上的竞争优势。另一方面,消费者需要在没有看到真正的产品实体、做出购买决策之前,根据其他购物者的评论了解产品的质量、性价比等信息,为购物抉择提供参考依据。
请根据提供的数据(链接: https://pan.baidu.com/s/1vR6esk9JRDZC9Gdwr8DOzA 提取码: jnkt)实现以下目标。
(1)对京东商城中美的电热水器的评论进行情感分析。
(2)从评论文本中挖掘出用户的需求、意见,购买原因以及产品的优缺点。
(3)根据模型结果给出改善产品的建议。
二、分析方法与过程
图1为电商产品评论数据情感分析流程,主要步骤如下:
(1)利用Python对京东商城中美的电热水器的评论进行爬取。
(2)利用Python爬取到的京东商城中美的电热水器的评论数据,对评论文本数据进行数据清洗、分词、停用词过滤等操作。
(3)对预处理后的数据进行情感分析,将评论文本数据按照情感倾向分为正面评论数据(好评)和负面评论数据(差评)。
(4)分别对正、负面评价数据进行LDA主题分析,从对应的结果分析文本评论数据中有价值的内容。
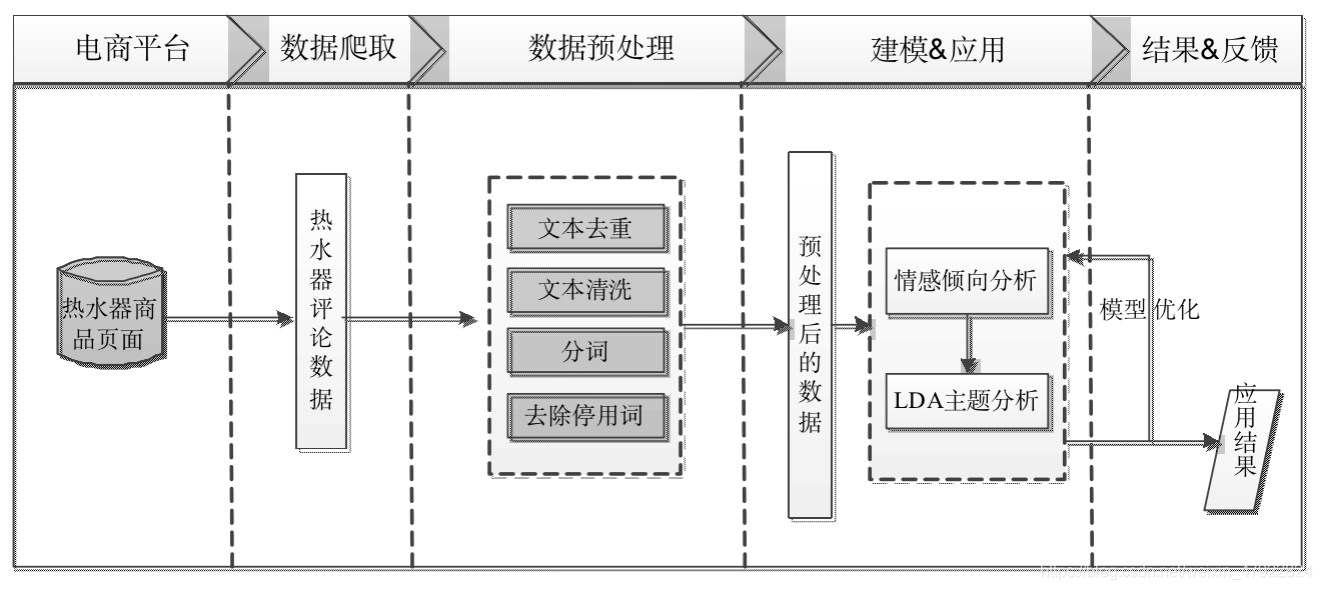
图1 电商产品评论数据情感分析流程
1. 评论预处理
对京东商城中美的热水器评论数据进行预处理前,需要先对评论数据进行采集。本案例利用Python网络爬虫技术对京东商城中美的热水器评论数据进行采集。由于本案例的重点是对电商产品评论数据情感分析,且网络数据的爬取具有时效性,因此,本案例不再详细介绍数据的采集过程。以下分析所使用的数据与分析结果,仅作为范例参考。
1)评论去重
一些电商平台往往为了避免一些客户长时间不进行评论,会设置一道程序,如果用户超过规定的时间仍然没有做出评论,系统会自动替客户做出评论,这类数据显然没有任何分析价值。
由语言的特点可知,在大多数情况下,不同购买者之间的有价值的评论都不会出现完全重复,如果出现了不同购物者的评论完全重复,这些评论一般都是毫无意义的。这种评论显然只有最早的评论才有意义(即只有第一条有作用)。
部分评论相似程度极高,可是在某些词语的运用上存在差异。此类评论可归为重复评论,若是删除文字相近评论,则会出现误删的情况。由于相近的评论也存在不少有用的信息,去除这类评论显然不合适。因此,为了存留更多的有用语料,本节针对完全重复的语料下手,仅删除完全重复部分,以确保尽可能保留有用的文本评论信息,评论去重的代码如以下所示。
- import pandas as pd
- import re
- import jieba.posseg as psg
- import numpy as np
- # 去重,去除完全重复的数据
- reviews = pd.read_csv("../tmp/reviews.csv")
- reviews = reviews[['content', 'content_type']].drop_duplicates()
- content = reviews['content']

运行代码清单可知,美的热水器的评论共2000条,经过文本去重,共删除重复评论26条,剩余评论1974条。
2)数据清洗
通过人工观察数据发现,评论中夹杂许多数字与字母,对于本案例挖掘目标而言,这类数据本身没有实质性帮助。另外,由于该评论文本数据主要围绕京东商城中美的电热水器进行评价,其中“京东”“京东商城”“美的”“热水器”“电热水器”等词出现的频数很大,但是对分析目标并没有什么作用,因此可以在分词之前将这些词去除,对数据进行清洗,如代码清单以下所示。
- # 去除去除英文、数字等
- # 由于评论主要为京东美的电热水器的评论,因此去除这些词语
- strinfo = re.compile('[0-9a-zA-Z]|京东|美的|电热水器|热水器|')
- content = content.apply(lambda x: strinfo.sub('', x))
2. 评论分词
1)分词、词性标注、去除停用词
jieba的几个分词接口:cut、lcut、posseg.cut、posseg.lcut
- # 自定义简单的分词函数
- worker = lambda s : [[x.word,x.flag] for x in psg.cut(s)] # 单词与词性
- seg_word = content.apply(worker)

- # 将词语转化为数据框形式,一列是词,一列是词语所在的句子id,最后一列是词语在该句子中的位置
- # 每一评论中词的个数
- n_word = seg_word.apply(lambda x: len(x))
- # 构造词语所在的句子id
- n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))]
- # 将嵌套的列表展开,作为词所在评论的id
- index_content = sum(n_content, [])
-
- seg_word = sum(seg_word,[])
- # 词
- word = [x[0] for x in seg_word]
- # 词性
- nature = [x[1] for x in seg_word]
- # content_type评论类型
- content_type = [[x]*y for x,y in zip(list(reviews['content_type']),list(n_word))]
- content_type = sum(content_type,[])
-
- # 构造数据框
- result = pd.DataFrame({'index_content': index_content,
- 'word' : word,
- 'nature': nature,
- 'content_type' : content_type})

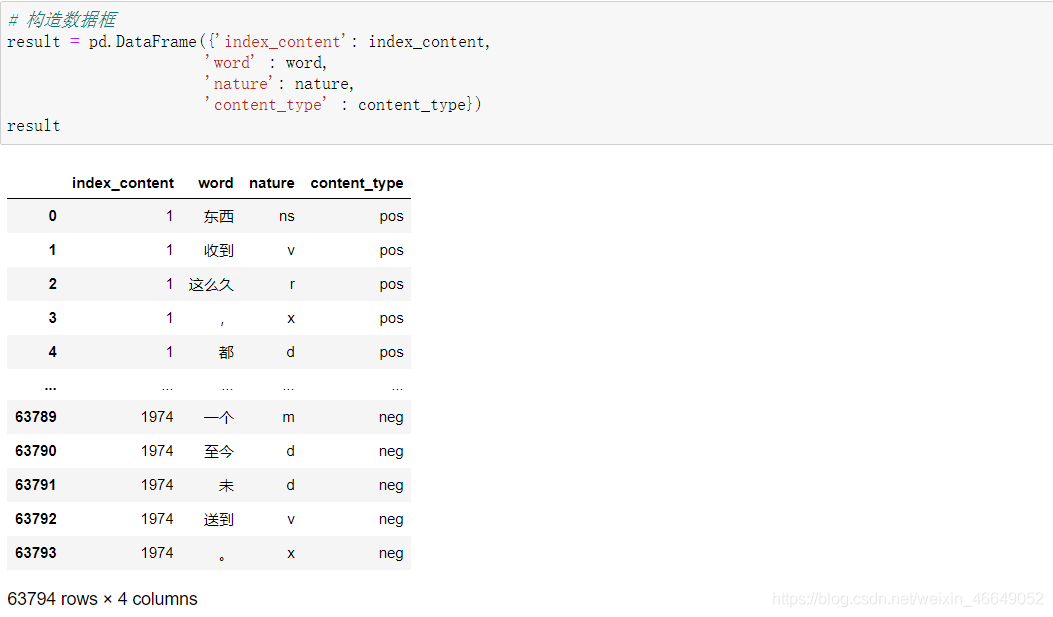
观察nature列得,x表示标点符号
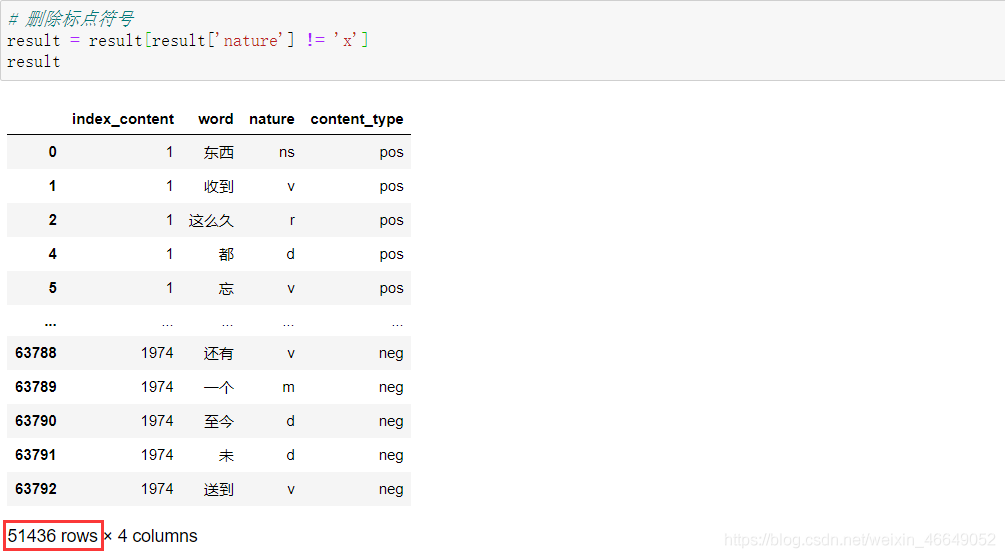
删除标点符号
- # 删除标点符号
- result = result[result['nature'] != 'x']
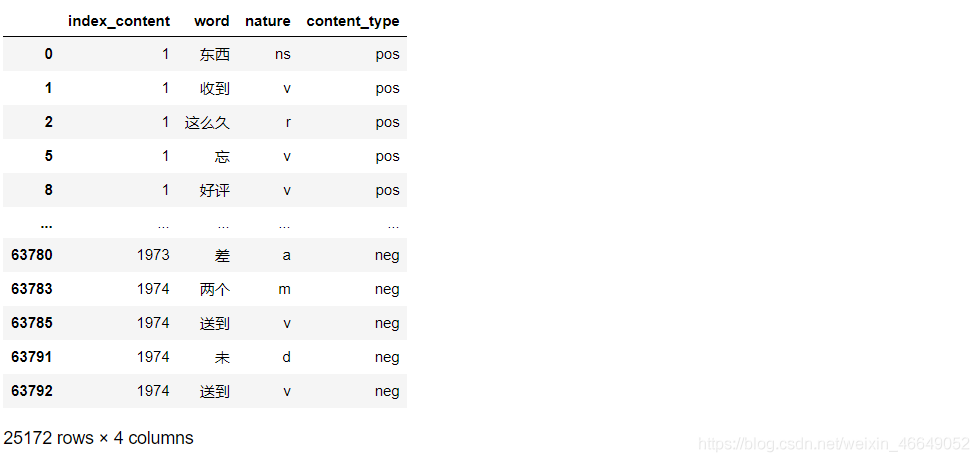
- # 删除停用词
- # 加载停用词
- stop_path = open('data/stoplist.txt','r',encoding='utf-8')
- stop = [x.replace('\n','') for x in stop_path.readlines()]
- # 得到非停用词序列
- word = list(set(word) - set(stop))
- # 判断表格中的单词列是否在非停用词列中
- result = result[result['word'].isin(word)]
- # 构造各词在评论中的位置列
- n_word = list(result.groupby(by=['index_content'])['index_content'].count())
- index_word = [list(np.arange(0,x)) for x in n_word]
- index_word = sum(index_word,[])
- result['index_word'] = index_word
- result.reset_index(drop=True,inplace=True)
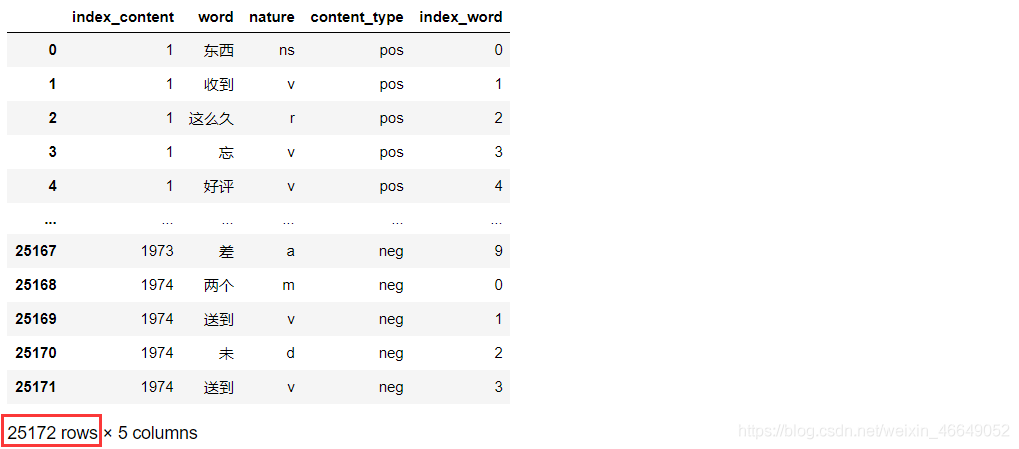
提取含名词的评论
由于本案例的目标是对产品特征的优缺点进行分析,类似“不错,很好的产品”“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。评论中只有出现明确的名词,如机构团体及其他专有名词时,才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。根据得出的词性,提取评论中词性含有“n”的评论。
- # 提取含名词的评论的句子id
- ind = result[[x == 'n' for x in result['nature']]]['index_content'].unique()
- # 提取评论
- result = result[result['index_content'].isin(ind)]
- # 重置索引
- result.reset_index(drop=True,inplace=True)
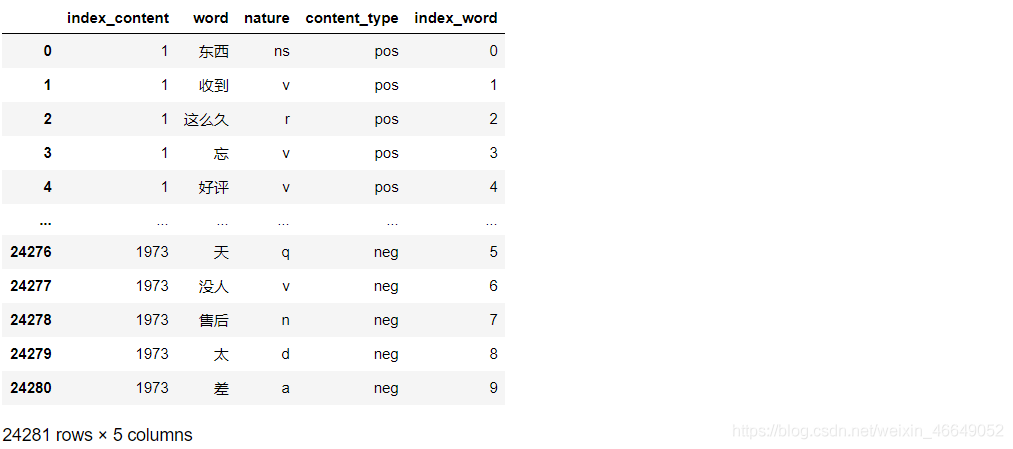
绘制词云查看分词效果
进行数据预处理后,可绘制词云查看分词效果,词云会将文本中出现频率较高的‘关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果:
- from wordcloud import WordCloud
- import matplotlib.pyplot as plt
-
- # 按word分组统计数目
- frequencies = result.groupby(by = ['word'])['word'].count()
- # 按数目降序排序
- frequencies = frequencies.sort_values(ascending = False)
- # 从文件中将图像读取为数组
- backgroud_Image=plt.imread('data/pl.jpg')
- wordcloud = WordCloud(font_path="C:\Windows\Fonts\STZHONGS.ttf",# 这里的字体要与自己电脑中的对应
- max_words=100, # 选择前100词
- background_color='white', # 背景颜色为白色
- mask=backgroud_Image)
- my_wordcloud = wordcloud.fit_words(frequencies)
- # 将数据展示到二维图像上
- plt.imshow(my_wordcloud)
- # 关掉x,y轴
- plt.axis('off')
- plt.show()
-
- # 将结果写出
- result.to_csv("word.csv", index = False, encoding = 'utf-8')

对评论数据进行预处理后,分词效果较为符合预期。其中“安装”“师傅”“售后”“物流”“服务”等词出现频率较高,因此可以初步判断用户对产品的这几个方面比较重视。
三、构建模型
1.评论数据情感倾向分析
1)匹配情感词
情感倾向也称为情感极性。在某商品评论中,可以理解为用户对该商品表达自身观点所持的态度是支持、反对还是中立,即通常所指的正面情感、负面情感、中性情感。由于本案例主要是对产品的优缺点进行分析,因此只要确定用户评论信息中的情感倾向方向分析即可,不需要分析每一评论的情感程度。对评论情感倾向进行分析首先要对情感词进行匹配,主要采用词典匹配的方法,本案例使用的情感词表是2007年10月22日知网发布的“情感分析用词语集 ( beta版)”,主要使用“中文正面评价”词表、“中文负面评价”“中文正面情感”“中文负面情感"词表等。将“中文正面评价”“中文正面情感”两个词表合并,并给每个词语赋予初始权重1,作为本案例的正面评论情感词表。将“中文负面评价”“中文负面情感”两个词表合并,并给每个词语赋予初始权重-1,作为本案例的负面评论情感词表。
一般基于词表的情感分析方法,分析的效果往往与情感词表内的词语有较强的相关性,如果情感词表内的词语足够全面,并且词语符合该案例场景下所表达的情感,那么情感分析的效果会更好。针对本案例场景,需要在知网提供的词表基础上进行优化.例如“好评”“超值”“差评”“五分”等词只有在网络购物评论上出现,就可以根据词语的情感倾向添加至对应的情感词表内。将“满意”“好评”“很快”“还好”“还行”“超值”“给力”“支持”“超好”“感谢”“太棒了”“厉害”“挺舒服”“辛苦”“完美”“喜欢”“值得”“省心”等词添加进正面情感词表。将“差评”“贵”“高”“漏水”等词加入负面情感词表。
读入正负面评论情感词表,正面词语赋予初始权重1,负面词语赋予初始权重-1。
- # 读入评论词表
- word = pd.read_csv('word.csv',header=0)
- # 读入正面、负面情感评价词
- pos_comment = pd.read_csv("data/正面评价词语(中文).txt", header=None,sep="\n",
- encoding = 'utf-8', engine='python')
- neg_comment = pd.read_csv("data/负面评价词语(中文).txt", header=None,sep="\n",
- encoding = 'utf-8', engine='python')
- pos_emotion = pd.read_csv("data/正面情感词语(中文).txt", header=None,sep="\n",
- encoding = 'utf-8', engine='python')
- neg_emotion = pd.read_csv("data/负面情感词语(中文).txt", header=None,sep="\n",
- encoding = 'utf-8', engine='python')
-
- # 合并情感词与评价词
- positive = set(pos_comment.iloc[:,0])|set(pos_emotion.iloc[:,0])
- negative = set(neg_comment.iloc[:,0])|set(neg_emotion.iloc[:,0])
- # 正负面情感词表中相同的词语
- intersection = positive & negative
- # 去掉相同的词
- positive = list(positive - intersection)
- negative = list(negative - intersection)
-
- # 正面词语赋予初始权重1,负面词语赋予初始权重-1
- positive = pd.DataFrame({"word":positive,
- "weight":[1]*len(positive)})
- negative = pd.DataFrame({"word":negative,
- "weight":[-1]*len(negative)})
- posneg = positive.append(negative)
- # 将分词结果与正负面情感词表合并,定位情感词
- data_posneg = pd.merge(left=word,right=posneg,on='word',how='left')
- # 先按评论id排序,再按在评论中的位置排序
- data_posneg = data_posneg.sort_values(by = ['index_content','index_word'])

2) 修正情感倾向
情感倾向修正主要根据情感词前面两个位置的词语是否存在否定词而去判断情感值的正确与否,由于汉语中存在多重否定现象,即当否定词出现奇数次时,表示否定意思;当否定词出现偶数次时,表示肯定意思。按照汉语习惯,搜索每个情感词前两个词语,若出现奇数否定词,则调整为相反的情感极性。本案例使用的否定词表共有19个否定词,分别为:不、没、无、非、莫、弗、毋、未、否、别、六、休、不是、不能、不可、没有、不用、不要、从没、不太。读入否定词表,对情感值的方向进行修正。计算每条评论的情感得分,将评论分为正面评论和负面评论,并计算情感分析的准确率。
- # 根据情感词前面两个位置的词语是否存在否定词或双层否定词对情感值进行修正
- # 载入否定词表
- notdict = pd.read_csv("data/not.csv")
- # 处理否定修饰词
- # 构造新列,作为经过否定词修正后的情感值
- data_posneg['amend_weight'] = data_posneg['weight']
- data_posneg['id'] = np.arange(0, len(data_posneg))
- # 只保留有情感值的词语
- only_inclination = data_posneg.dropna()
- # 修改索引
- only_inclination.index = np.arange(0, len(only_inclination))
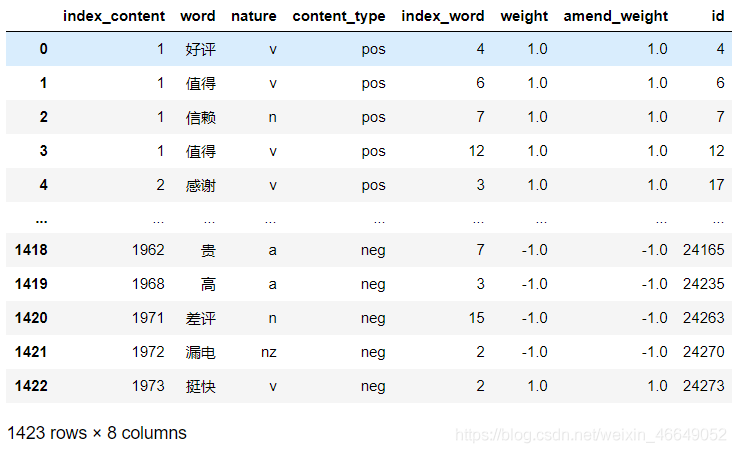
- index = only_inclination['id']
- for i in np.arange(0, len(only_inclination)):
- # 提取第i个情感词所在的评论
- review = data_posneg[data_posneg['index_content'] == only_inclination['index_content'][i]]
- # 修改索引
- review.index = np.arange(0, len(review))
- # 第i个情感值在该文档的位置
- affective = only_inclination['index_word'][i]
- if affective == 1:
- # 情感词前面的单词是否在否定词表
- ne = sum([i in notdict['term'] for i in review['word'][affective - 1]])
- if ne == 1:
- data_posneg['amend_weight'][index[i]] = -data_posneg['weight'][index[i]]
- elif affective > 1:
- # 情感词前面两个位置的词语是否在否定词,存在一个调整成相反的情感权重,存在两个就不调整
- ne = sum([i in notdict['term'] for i in review['word'][[affective - 1, affective - 2]]])
- if ne == 1:
- data_posneg['amend_weight'][index[i]] = -data_posneg['weight'][index[i]]
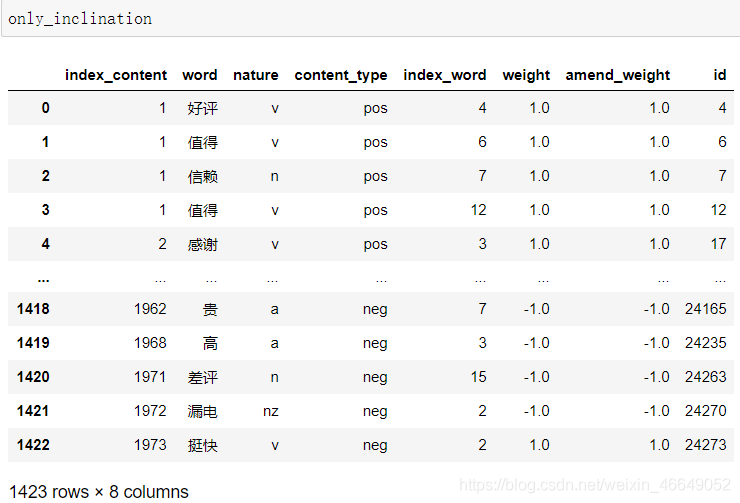
- # 计算每条评论的情感值
- emotional_value = only_inclination.groupby(['index_content'],as_index=False)['amend_weight'].sum()
- # 去除情感值为0的评论
- emotional_value = emotional_value[emotional_value['amend_weight'] != 0]
- emotional_value.reset_index(drop=True,inplace=True)
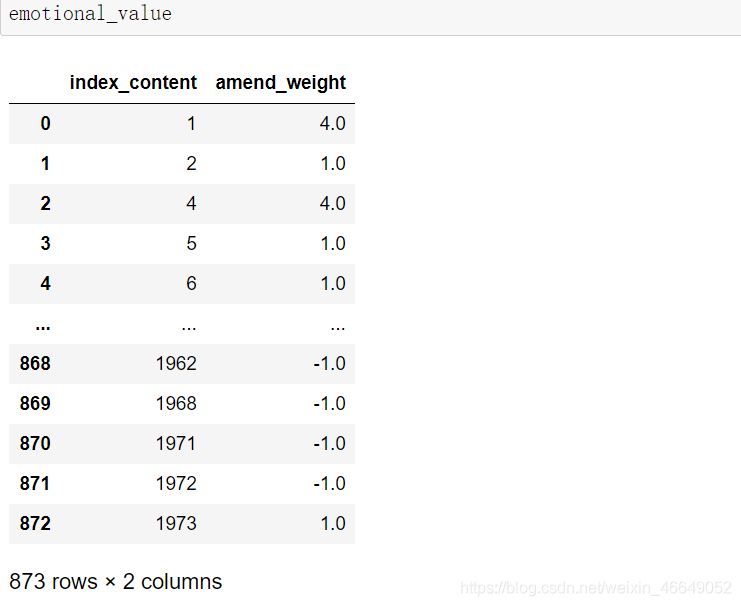 3)查看情感分析效果
3)查看情感分析效果
提取正面评论与负面评论,然后分别绘制词云,来查看情感分析效果。
- # 给情感值大于0的赋予评论类型pos,小于0的赋予neg
- emotional_value['a_type'] = ''
- emotional_value['a_type'][emotional_value['amend_weight'] > 0] = 'pos'
- emotional_value['a_type'][emotional_value['amend_weight'] < 0] = 'neg'
- # 查看情感分析的结果
- result = pd.merge(left=word,right=emotional_value,on='index_content',how='right')
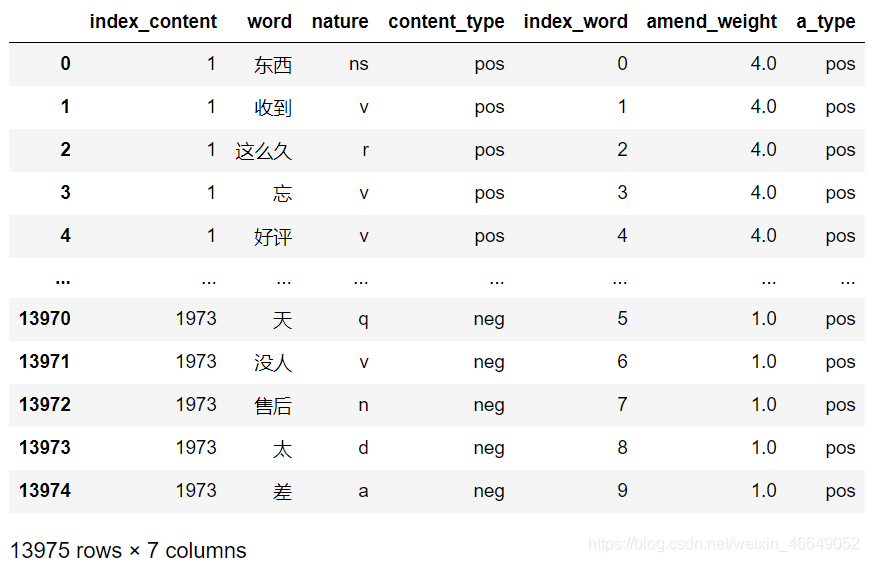
- # 去重
- result = result[['index_content','content_type', 'a_type']].drop_duplicates()

- # 混淆矩阵-交叉表
- confusion_matrix = pd.crosstab(result['content_type'],result['a_type'],margins=True)

- # 准确率
- (confusion_matrix.iloc[0,0] + confusion_matrix.iloc[1,1])/confusion_matrix.iloc[2,2]

- # 提取正负面评论信息
- # 得到正面评论与负面评论对应的索引
- ind_pos = list(emotional_value[emotional_value['a_type'] == 'pos']['index_content'])
- ind_neg = list(emotional_value[emotional_value['a_type'] == 'neg']['index_content'])
- # 得到正面评论与负面评论
- posdata = word[[i in ind_pos for i in word['index_content']]]
- negdata = word[[i in ind_neg for i in word['index_content']]]
- # 绘制正面情感词云
- # 正面情感词词云
- freq_pos = posdata.groupby(by = ['word'])['word'].count()
- freq_pos = freq_pos.sort_values(ascending = False)
- backgroud_Image=plt.imread('data/pl.jpg')
- wordcloud = WordCloud(font_path="C:/Windows/Fonts/STZHONGS.ttf",
- max_words=100,
- background_color='white',
- mask=backgroud_Image)
- pos_wordcloud = wordcloud.fit_words(freq_pos)
- plt.imshow(pos_wordcloud)
- plt.axis('off')
- plt.show()

由正面情感评论词云可知,“不错”“满意”“好评”等正面情感词出现的频数较高,并且没有掺杂负面情感词语,可以看出情感分析能较好地将正面情感评论抽取出来。
- # 绘制负面评论词云
- freq_neg = negdata.groupby(by = ['word'])['word'].count()
- freq_neg = freq_neg.sort_values(ascending = False)
- neg_wordcloud = wordcloud.fit_words(freq_neg)
- plt.imshow(neg_wordcloud)
- plt.axis('off')
- plt.show()

由负面情感评论词云可知,“贵”“垃圾”“不好”“太坑人”等负面情感词出现的频数较高,并且没有掺杂正面情感词语,可以看出情感分析能较好地将负面情感评论抽取出来。
- # 将结果写出,每条评论作为一行
- posdata.to_csv("posdata.csv", index = False, encoding = 'utf-8')
- negdata.to_csv("negdata.csv", index = False, encoding = 'utf-8')
为了进一步查看情感分析效果,假定用户在评论时不存在“选了好评的标签,而写了差评内容”的情况,比较原评论的评论类型与情感分析得出的评论类型,绘制情感倾向分析混淆矩阵,查看词表的情感分析的准确率。

通过比较原评论的评论类型与情感分析得出的评论类型,基于词表的情感分析的准确率达到了89.34%,证明通过词表的情感分析去判断某文本的情感程度是有效的。
2.使用LDA主题模型进行主题分析
1)建立词典及语料库
- import pandas as pd
- import numpy as np
- import re
- import itertools
- import matplotlib.pyplot as plt
-
- # 载入情感分析后的数据
- posdata = pd.read_csv("../data/posdata.csv", encoding = 'utf-8')
- negdata = pd.read_csv("../data/negdata.csv", encoding = 'utf-8')
-
- from gensim import corpora, models
- # 建立词典
- pos_dict = corpora.Dictionary([[i] for i in posdata['word']]) # 正面
- neg_dict = corpora.Dictionary([[i] for i in negdata['word']]) # 负面
-
- # 建立语料库
- pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in posdata['word']]] # 正面
- neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in negdata['word']]] # 负面
2)寻找最优主题数
基于相似度的自适应最优LDA模型选择方法,确定主题数并进行主题分析。实验证明该方法可以在不需要人工调试主题数目的情况下,用相对少的迭代找到最优的主题结构。具体步骤如下:
取初始主题数k值,得到初始模型,计算各主题之间的相似度(平均余弦距离)
增加或减少k值,重新训练模型,再次计算各主题之间的相似度。
重复步骤2,直到得到最优k值。
利用各主题间的余弦相似度来度量主题间的相似程度。从词频入手,计算它们的相似度,用词越相似,则内容越相近。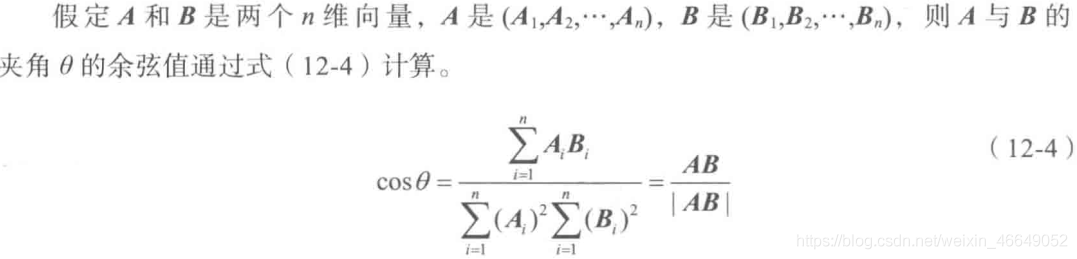
使用LDA主题模型,找出不同主题数下的主题词,每个模型各取出若干个主题词(比如前100个),合并成一个集合。生成任何两个主题间的词频向量,计算两个向量的余弦相似度,值越大就表示越相似;计算各个主题数的平均余弦相似度,寻找最优主题数。
- def cos(vector1, vector2):
- """
- 计算两个向量的余弦相似度函数
- :param vector1:
- :param vector2:
- :return: 返回两个向量的余弦相似度
- """
- dot_product = 0.0
- normA = 0.0
- normB = 0.0
- for a, b in zip(vector1, vector2):
- dot_product += a * b
- normA += a ** 2
- normB += b ** 2
- if normA == 0.0 or normB == 0.0:
- return (None)
- else:
- return (dot_product / ((normA * normB) ** 0.5))
-
-
-
- def lda_k(x_corpus, x_dict):
- """
- 主题数寻优
- :param x_corpus: 语料库
- :param x_dict: 词典
- :return:
- """
- # 初始化平均余弦相似度
- mean_similarity = []
- mean_similarity.append(1)
-
- # 循环生成主题并计算主题间相似度
- for i in np.arange(2, 11):
- lda = models.LdaModel(x_corpus, num_topics=i, id2word=x_dict) # LDA模型训练
- for j in np.arange(i):
- term = lda.show_topics(num_words=50)
-
- # 提取各主题词
- top_word = []
- for k in np.arange(i):
- top_word.append([''.join(re.findall('"(.*)"', i)) for i in term[k][1].split('+')]) # 列出所有词
-
- # 构造词频向量
- word = sum(top_word, []) # 列出所有的词
- unique_word = set(word) # 去除重复的词
-
- # 构造主题词列表,行表示主题号,列表示各主题词
- mat = []
- for j in np.arange(i):
- top_w = top_word[j]
- mat.append(tuple([top_w.count(k) for k in unique_word]))
-
- p = list(itertools.permutations(list(np.arange(i)), 2))
- l = len(p)
- top_similarity = [0]
- for w in np.arange(l):
- vector1 = mat[p[w][0]]
- vector2 = mat[p[w][1]]
- top_similarity.append(cos(vector1, vector2))
-
- # 计算平均余弦相似度
- mean_similarity.append(sum(top_similarity) / l)
- return (mean_similarity)
- # 计算主题平均余弦相似度
- pos_k = lda_k(pos_corpus, pos_dict)
- neg_k = lda_k(neg_corpus, neg_dict)
- print('正面评论主题的平均相似度',pos_k)
- print('负面评论主题的平均相似度',neg_k)
-
- # 绘制主题平均余弦相似度图形
- # 解决中文显示问题
- plt.rcParams['font.sans-serif']=['SimHei']
- # 解决负号显示问题
- plt.rcParams['axes.unicode_minus'] = False
- fig = plt.figure(figsize=(10,8))
- ax1 = fig.add_subplot(211)
- ax1.plot(pos_k)
- ax1.set_xlabel('正面评论LDA主题数寻优',fontsize=14)
-
- ax2 = fig.add_subplot(212)
- ax2.plot(neg_k)
- ax2.set_xlabel('负面评论LDA主题数寻优', fontsize=14)
- 正面评论主题的平均相似度 [1, 0.06, 0.0, 0.013333333333333334, 0.024, 0.013333333333333334, 0.013333333333333334, 0.02642857142857144, 0.03888888888888891, 0.0631111111111111]
- 负面评论主题的平均相似度 [1, 0.06, 0.0, 0.0033333333333333335, 0.0, 0.0, 0.0038095238095238095, 0.011428571428571432, 0.012777777777777784, 0.021777777777777788]
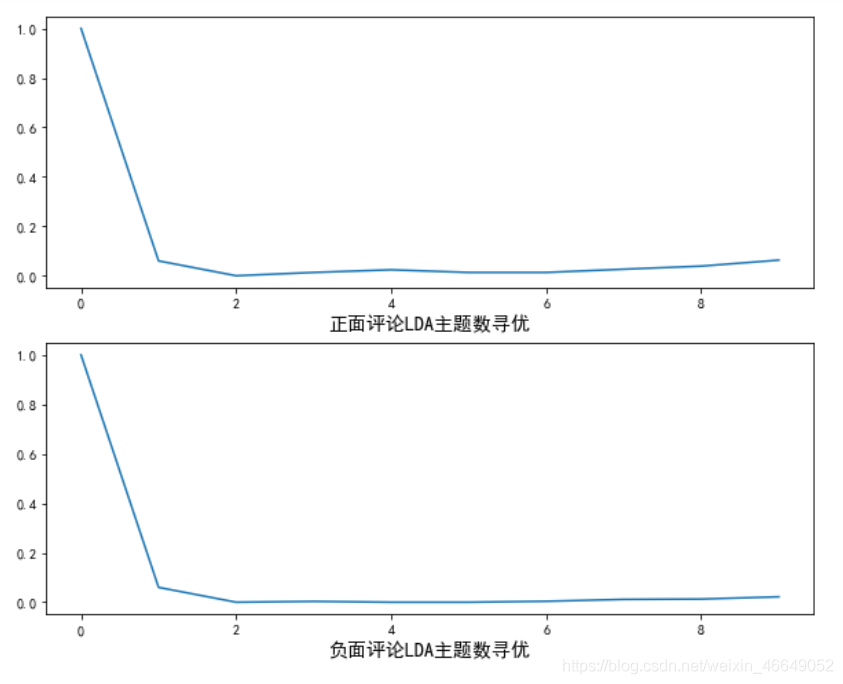
由图可知,对于正面评论数据,当主题数为2或3时,主题间的平均余弦相似度就达到了最低。因此,对正面评论数据做LDA,可以选择主题数为3;对于负面评论数据,当主题数为3时,主题间的平均余弦相似度也达到了最低。因此,对负面评论数据做LDA,也可以选择主题数为3。
3)评价主题分析结果
根据主题数寻优结果,使用Python的 Gensim模块对正面评论数据和负面评论数据分别构建LDA 主题模型,设置主题数为3,经过LDA主题分析后,每个主题下生成10个最有可能出现的词语以及相应的概率。
- pos_lda = models.LdaModel(pos_corpus, num_topics = 3, id2word = pos_dict)
- neg_lda = models.LdaModel(neg_corpus, num_topics = 3, id2word = neg_dict)
- pos_lda.print_topics(num_words = 10)
- [(0,
- '0.028*"送货" + 0.024*"服务" + 0.020*"好评" + 0.016*"太" + 0.012*"速度" + 0.011*"告诉" + 0.011*"质量" + 0.011*"活动" + 0.010*"收到" + 0.010*"服务态度"'),
- (1,
- '0.128*"安装" + 0.060*"满意" + 0.045*"师傅" + 0.027*"客服" + 0.026*"不错" + 0.016*"购物" + 0.016*"人员" + 0.011*"真心" + 0.011*"态度" + 0.010*"装"'),
- (2,
- '0.029*"值得" + 0.028*"很快" + 0.023*"东西" + 0.022*"售后" + 0.021*"差" + 0.020*"信赖" + 0.016*"电话" + 0.016*"物流" + 0.015*"真的" + 0.014*"品牌"')]
结果反映了美的电热水器正面评价文本中的潜在主题,主题1中的高频特征词,关注点主要是质量、服务态度、送货速度等,主要反映美的电热水器质量好,服务好等;主题2中的高频特征词,即关注点主要是师傅、安装等,主要反映美的电热水器的安装师傅服务好等;主题3中的高频特征词,即物流、很快等,主要反映京东美的电热水器产品物流快
neg_lda.print_topics(num_words = 10)
- [(0,
- '0.032*"垃圾" + 0.031*"售后" + 0.030*"太" + 0.025*"安装费" + 0.022*"东西" + 0.019*"装" + 0.019*"小时" + 0.018*"收" + 0.018*"打电话" + 0.016*"烧水"'),
- (1,
- '0.142*"安装" + 0.034*"师傅" + 0.021*"客服" + 0.019*"收费" + 0.019*"不好" + 0.018*"贵" + 0.017*"慢" + 0.017*"太慢" + 0.014*"人员" + 0.012*"坑"'),
- (2,
- '0.026*"差" + 0.016*"加热" + 0.014*"漏水" + 0.011*"材料" + 0.009*"材料费" + 0.008*"只能" + 0.007*"做" + 0.007*"找" + 0.006*"实体店" + 0.006*"度"')]
结果反映了美的电热水器负面评价文本中的潜在主题,主题1中的高频特征词主要关注点在安装、安装费、收费这几方面,说明可能存在安装师傅收费过高等问题;主题2中的高频特征词主要与售后、服务这几方面有关,主要反映该产品售后服务差等问题;主题3中的高频特征词主要与加热功能有关,主要反映的是美的电热水器加热性能存在问题等。
综合以上对主题及其中的高频特征词的分析得出,美的电热水器有价格实惠、性价比高、外观好看、服务好等优势。相对而言,用户对美的电热水器的抱怨点主要体现在安装的费用高及售后服务差等方面。
总结
根据对京东平台上美的电热水器的用户评价情况进行LDA主题模型分析,对美的品牌提出以下两点建议:
①在保持热水器使用方便、价格实惠等优点的基础上,对热水器进行加热功能上的改进,从整体上提升热水器的质量。
②提升安装人员及客服人员的整体素质,提高服务质量,注重售后服务。建立安装费用收取的明文细则,并进行公布,以减少安装过程中乱收费的现象。适度降低安装费用和材料费用,以此在大品牌的竞争中凸显优势。

