
主要内容:
-
OMP算法介绍
-
OMP的MATLAB实现
- OMP中的数学知识
一、OMP算法介绍
来源:http://blog.csdn.net/scucj/article/details/7467955
1、信号的稀疏表示(sparse representation of signals)
给定一个过完备字典矩阵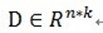 ,其中它的每列表示一种原型信号的原子。给定一个信号y,它可以被表示成这些原子的稀疏线性组合。信号 y 可以被表达为 y = Dx ,或者
,其中它的每列表示一种原型信号的原子。给定一个信号y,它可以被表示成这些原子的稀疏线性组合。信号 y 可以被表达为 y = Dx ,或者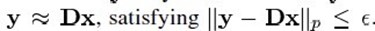 。字典矩阵中所谓过完备性,指的是原子的个数远远大于信号y的长度(其长度很显然是n),即n<<k。
。字典矩阵中所谓过完备性,指的是原子的个数远远大于信号y的长度(其长度很显然是n),即n<<k。
2、MP算法(匹配追踪算法)
2.1 算法描述
作为对信号进行稀疏分解的方法之一,将信号在完备字典库上进行分解。
假定被表示的信号为y,其长度为n。假定H表示Hilbert空间,在这个空间H里,由一组向量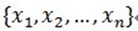 构成字典矩阵D,其中每个向量可以称为原子(atom),其长度与被表示信号 y 的长度n相同,而且这些向量已作为归一化处理,即|
构成字典矩阵D,其中每个向量可以称为原子(atom),其长度与被表示信号 y 的长度n相同,而且这些向量已作为归一化处理,即|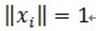 ,也就是单位向量长度为1。MP算法的基本思想:从字典矩阵D(也称为过完备原子库中),选择一个与信号 y 最匹配的原子(也就是某列),构建一个稀疏逼近,并求出信号残差,然后继续选择与信号残差最匹配的原子,反复迭代,信号y可以由这些原子来线性和,再加上最后的残差值来表示。很显然,如果残差值在可以忽略的范围内,则信号y就是这些原子的线性组合。如果选择与信号y最匹配的原子?如何构建稀疏逼近并求残差?如何进行迭代?我们来详细介绍使用MP进行信号分解的步骤:[1] 计算信号 y 与字典矩阵中每列(原子)的内积,选择绝对值最大的一个原子,它就是与信号 y 在本次迭代运算中最匹配的。用专业术语来描述:令信号
,也就是单位向量长度为1。MP算法的基本思想:从字典矩阵D(也称为过完备原子库中),选择一个与信号 y 最匹配的原子(也就是某列),构建一个稀疏逼近,并求出信号残差,然后继续选择与信号残差最匹配的原子,反复迭代,信号y可以由这些原子来线性和,再加上最后的残差值来表示。很显然,如果残差值在可以忽略的范围内,则信号y就是这些原子的线性组合。如果选择与信号y最匹配的原子?如何构建稀疏逼近并求残差?如何进行迭代?我们来详细介绍使用MP进行信号分解的步骤:[1] 计算信号 y 与字典矩阵中每列(原子)的内积,选择绝对值最大的一个原子,它就是与信号 y 在本次迭代运算中最匹配的。用专业术语来描述:令信号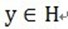 ,从字典矩阵中选择一个最为匹配的原子,满足
,从字典矩阵中选择一个最为匹配的原子,满足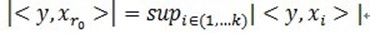 ,r0 表示一个字典矩阵的列索引。这样,信号 y 就被分解为在最匹配原子
,r0 表示一个字典矩阵的列索引。这样,信号 y 就被分解为在最匹配原子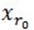 的垂直投影分量和残值两部分,即:
的垂直投影分量和残值两部分,即: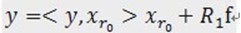 。[2]对残值R1f进行步骤[1]同样的分解,那么第K步可以得到:
。[2]对残值R1f进行步骤[1]同样的分解,那么第K步可以得到:
 , 其中
, 其中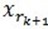 满足
满足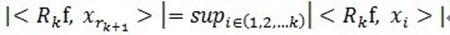 。可见,经过K步分解后,信号 y 被分解为:
。可见,经过K步分解后,信号 y 被分解为: ,其中
,其中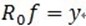 。
。
2.2 继续讨论
(1)为什么要假定在Hilbert空间中?Hilbert空间就是定义了完备的内积空。很显然,MP中的计算使用向量的内积运算,所以在在Hilbert空间中进行信号分解理所当然了。什么是完备的内积空间?篇幅有限就请自己搜索一下吧。
(2)为什么原子要事先被归一化处理了,即上面的描述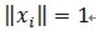 。内积常用于计算一个矢量在一个方向上的投影长度,这时方向的矢量必须是单位矢量。MP中选择最匹配的原子是,是选择内积最大的一个,也就是信号(或是残值)在原子(单位的)垂直投影长度最长的一个,比如第一次分解过程中,投影长度就是
。内积常用于计算一个矢量在一个方向上的投影长度,这时方向的矢量必须是单位矢量。MP中选择最匹配的原子是,是选择内积最大的一个,也就是信号(或是残值)在原子(单位的)垂直投影长度最长的一个,比如第一次分解过程中,投影长度就是 。
。 ,三个向量,构成一个三角形,且
,三个向量,构成一个三角形,且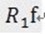 和
和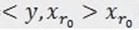 正交(不能说垂直,但是可以想象二维空间这两个矢量是垂直的)。
正交(不能说垂直,但是可以想象二维空间这两个矢量是垂直的)。
(3)MP算法是收敛的,因为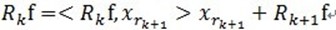 ,
,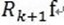 和
和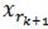 正交,由这两个可以得出
正交,由这两个可以得出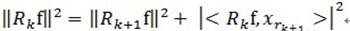 ,得出每一个残值比上一次的小,故而收敛。
,得出每一个残值比上一次的小,故而收敛。
2.3 MP算法的缺点
如上所述,如果信号(残值)在已选择的原子进行垂直投影是非正交性的,这会使得每次迭代的结果并不少最优的而是次最优的,收敛需要很多次迭代。举个例子说明一下:在二维空间上,有一个信号 y 被 D=[x1, x2]来表达,MP算法迭代会发现总是在x1和x2上反复迭代,即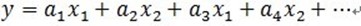 ,这个就是信号(残值)在已选择的原子进行垂直投影的非正交性导致的。再用严谨的方式描述[1]可能容易理解:在Hilbert空间H中,
,这个就是信号(残值)在已选择的原子进行垂直投影的非正交性导致的。再用严谨的方式描述[1]可能容易理解:在Hilbert空间H中,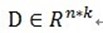 ,
, ,定义
,定义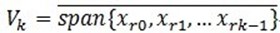 ,就是它是这些向量的张成中的一个,MP构造一种表达形式:
,就是它是这些向量的张成中的一个,MP构造一种表达形式: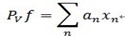 ;这里的Pvf表示 f在V上的一个正交投影操作,那么MP算法的第 k 次迭代的结果可以表示如下(前面描述时信号为y,这里变成f了,请注意):
;这里的Pvf表示 f在V上的一个正交投影操作,那么MP算法的第 k 次迭代的结果可以表示如下(前面描述时信号为y,这里变成f了,请注意):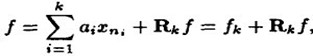
如果  是最优的k项近似值,当且仅当
是最优的k项近似值,当且仅当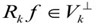 。由于MP仅能保证
。由于MP仅能保证 ,所以
,所以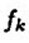 一般情况下是次优的。这是什么意思呢?
一般情况下是次优的。这是什么意思呢? 是k个项的线性表示,这个组合的值作为近似值,只有在第k个残差和
是k个项的线性表示,这个组合的值作为近似值,只有在第k个残差和 正交,才是最优的。如果第k个残值与
正交,才是最优的。如果第k个残值与 正交,意味这个残值与fk的任意一项都线性无关,那么第k个残值在后面的分解过程中,不可能出现fk中已经出现的项,这才是最优的。而一般情况下,不能满足这个条件,MP一般只能满足第k个残差和xk正交,这也就是前面为什么提到"信号(残值)在已选择的原子进行垂直投影是非正交性的"的原因。如果第k个残差和fk不正交,那么后面的迭代还会出现fk中已经出现的项,很显然fk就不是最优的,这也就是为什么说MP收敛就需要更多次迭代的原因。不是说MP一定得到不到最优解,而且其前面描述的特性导致一般得到不到最优解而是次优解。那么,有没有办法让第k个残差与
正交,意味这个残值与fk的任意一项都线性无关,那么第k个残值在后面的分解过程中,不可能出现fk中已经出现的项,这才是最优的。而一般情况下,不能满足这个条件,MP一般只能满足第k个残差和xk正交,这也就是前面为什么提到"信号(残值)在已选择的原子进行垂直投影是非正交性的"的原因。如果第k个残差和fk不正交,那么后面的迭代还会出现fk中已经出现的项,很显然fk就不是最优的,这也就是为什么说MP收敛就需要更多次迭代的原因。不是说MP一定得到不到最优解,而且其前面描述的特性导致一般得到不到最优解而是次优解。那么,有没有办法让第k个残差与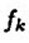 正交,方法是有的,这就是下面要谈到的OMP算法。
正交,方法是有的,这就是下面要谈到的OMP算法。
3、OMP算法
3.1 算法描述
OMP算法的改进之处在于:在分解的每一步对所选择的全部原子进行正交化处理,这使得在精度要求相同的情况下,OMP算法的收敛速度更快。
那么在每一步中如何对所选择的全部原子进行正交化处理呢?在正式描述OMP算法前,先看一点基础思想。
先看一个 k 阶模型,表示信号 f 经过 k 步分解后的情况,似乎很眼熟,但要注意它与MP算法不同之处,它的残值与前面每个分量正交,这就是为什么这个算法多了一个正交的原因,MP中仅与最近选出的的那一项正交。
 (1)
(1)
k + 1 阶模型如下:
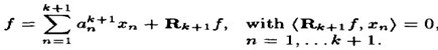 (2)
(2)
应用 k + 1阶模型减去k 阶模型,得到如下:
 (3)
(3)
我们知道,字典矩阵D的原子是非正交的,引入一个辅助模型,它是表示 对前k个项
对前k个项 的依赖,描述如下:
的依赖,描述如下:
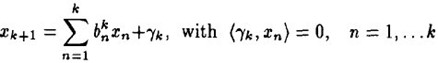 (4)
(4)
和前面描述类似,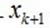 在span(x1, ...xk)之一上的正交投影操作,后面的项是残值。这个关系用数学符号描述:
在span(x1, ...xk)之一上的正交投影操作,后面的项是残值。这个关系用数学符号描述: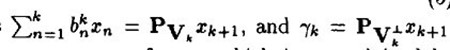
请注意,这里的 a 和 b 的上标表示第 k 步时的取值。
将(4)带入(3)中,有:
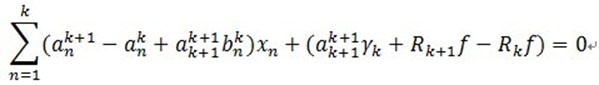 (5)
(5)
如果一下两个式子成立,(5)必然成立。
 (6)
(6)
 (7)
(7)
令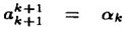 ,有
,有
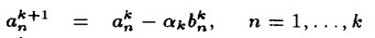
其中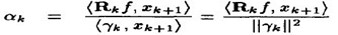 。
。
ak的值是由求法很简单,通过对(7)左右两边添加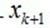 作内积消减得到:
作内积消减得到:

后边的第二项因为它们正交,所以为0,所以可以得出ak的第一部分。对于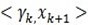 ,在(4)左右两边中与
,在(4)左右两边中与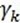 作内积,可以得到ak的第二部分。
作内积,可以得到ak的第二部分。
对于(4),可以求出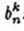 ,求的步骤请参见参考文件的计算细节部分。为什么这里不提,因为后面会介绍更简单的方法来计算。
,求的步骤请参见参考文件的计算细节部分。为什么这里不提,因为后面会介绍更简单的方法来计算。
3.2 收敛性证明
通过(7)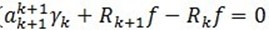 ,由于
,由于 与
与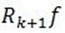 正交,将两个残值移到右边后求二范的平方,并将ak的值代入可以得到:
正交,将两个残值移到右边后求二范的平方,并将ak的值代入可以得到:
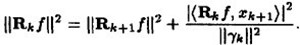
可见每一次残差比上一次残差小,可见是收敛的。
3.3 算法步骤
整个OMP算法的步骤如下:

由于有了上面的来龙去脉,这个算法就相当好理解了。
到这里还不算完,后来OMP的迭代运算用另外一种方法可以计算得知,有位同学的论文[2]描述就非常好,我就直接引用进来:


对比中英文描述,本质都是一样,只是有细微的差别。这里顺便贴出网一哥们写的OMP算法的代码,源出处不得而知,共享给大家。

二、OMP的MATLAB实现
1、一维信号重建
代码:

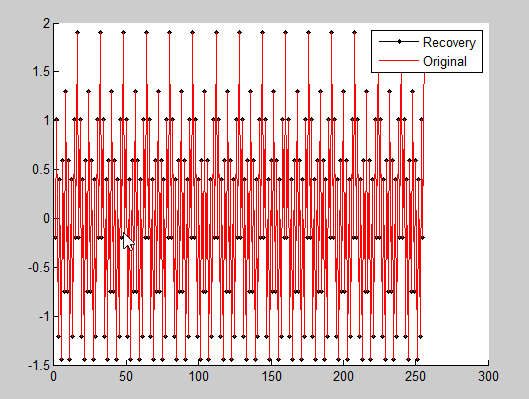
% 1-D信号压缩传感的实现(正交匹配追踪法Orthogonal Matching Pursuit) % 测量数M>=K*log(N/K),K是稀疏度,N信号长度,可以近乎完全重构 % 编程人--香港大学电子工程系 沙威 Email: wsha@eee.hku.hk % 编程时间:2008年11月18日 % 文档下载: http://www.eee.hku.hk/~wsha/Freecode/freecode.htm % 参考文献:Joel A. Tropp and Anna C. Gilbert % Signal Recovery From Random Measurements Via Orthogonal Matching % Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 53, NO. 12, % DECEMBER 2007. clc;clear %% 1. 时域测试信号生成 K=7; % 稀疏度(做FFT可以看出来) N=256; % 信号长度 M=64; % 测量数(M>=K*log(N/K),至少40,但有出错的概率) f1=50; % 信号频率1 f2=100; % 信号频率2 f3=200; % 信号频率3 f4=400; % 信号频率4 fs=800; % 采样频率 ts=1/fs; % 采样间隔 Ts=1:N; % 采样序列 x=0.3*cos(2*pi*f1*Ts*ts)+0.6*cos(2*pi*f2*Ts*ts)+0.1*cos(2*pi*f3*Ts*ts)+0.9*cos(2*pi*f4*Ts*ts); % 完整信号,由4个信号叠加而来 %% 2. 时域信号压缩传感 Phi=randn(M,N); % 测量矩阵(高斯分布白噪声)64*256的扁矩阵,Phi也就是文中说的D矩阵 s=Phi*x.'; % 获得线性测量 ,s相当于文中的y矩阵 %% 3. 正交匹配追踪法重构信号(本质上是L_1范数最优化问题) %匹配追踪:找到一个其标记看上去与收集到的数据相关的小波;在数据中去除这个标记的所有印迹;不断重复直到我们能用小波标记“解释”收集到的所有数据。 m=2*K; % 算法迭代次数(m>=K),设x是K-sparse的 Psi=fft(eye(N,N))/sqrt(N); % 傅里叶正变换矩阵 T=Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵) hat_y=zeros(1,N); % 待重构的谱域(变换域)向量 Aug_t=[]; % 增量矩阵(初始值为空矩阵) r_n=s; % 残差值 for times=1:m; % 迭代次数(有噪声的情况下,该迭代次数为K) for col=1:N; % 恢复矩阵的所有列向量 product(col)=abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值) end [val,pos]=max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波 Aug_t=[Aug_t,T(:,pos)]; % 矩阵扩充 T(:,pos)=zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹 aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; % 最小二乘,使残差最小 r_n=s-Aug_t*aug_y; % 残差 pos_array(times)=pos; % 纪录最大投影系数的位置 end hat_y(pos_array)=aug_y; % 重构的谱域向量 hat_x=real(Psi'*hat_y.'); % 做逆傅里叶变换重构得到时域信号 %% 4. 恢复信号和原始信号对比 figure(1); hold on; plot(hat_x,'k.-') % 重建信号 plot(x,'r') % 原始信号 legend('Recovery','Original') norm(hat_x.'-x)/norm(x) % 重构误差
结果:
2、二维信号重建
代码:
% 本程序实现图像LENA的压缩传感 % 程序作者:沙威,香港大学电气电子工程学系,wsha@eee.hku.hk % 算法采用正交匹配法,参考文献 Joel A. Tropp and Anna C. Gilbert % Signal Recovery From Random Measurements Via Orthogonal Matching % Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 53, NO. 12, % DECEMBER 2007. % 该程序没有经过任何优化 function Wavelet_OMP clc;clear % 读文件 X=imread('lena256.bmp'); X=double(X); [a,b]=size(X); % 小波变换矩阵生成 ww=DWT(a); % 小波变换让图像稀疏化(注意该步骤会耗费时间,但是会增大稀疏度) X1=ww*sparse(X)*ww'; % X1=X; X1=full(X1); % 随机矩阵生成 M=190; R=randn(M,a); % R=mapminmax(R,0,255); % R=round(R); % 测量值 Y=R*X1; % OMP算法 % 恢复矩阵 X2=zeros(a,b); % 按列循环 for i=1:b % 通过OMP,返回每一列信号对应的恢复值(小波域) rec=omp(Y(:,i),R,a); % 恢复值矩阵,用于反变换 X2(:,i)=rec; end % 原始图像 figure(1); imshow(uint8(X)); title('原始图像'); % 变换图像 figure(2); imshow(uint8(X1)); title('小波变换后的图像'); % 压缩传感恢复的图像 figure(3); % 小波反变换 X3=ww'*sparse(X2)*ww; % X3=X2; X3=full(X3); imshow(uint8(X3)); title('恢复的图像'); % 误差(PSNR) % MSE误差 errorx=sum(sum(abs(X3-X).^2)); % PSNR psnr=10*log10(255*255/(errorx/a/b)) % OMP的函数 % s-测量;T-观测矩阵;N-向量大小 function hat_y=omp(s,T,N) Size=size(T); % 观测矩阵大小 M=Size(1); % 测量 hat_y=zeros(1,N); % 待重构的谱域(变换域)向量 Aug_t=[]; % 增量矩阵(初始值为空矩阵) r_n=s; % 残差值 for times=1:M; % 迭代次数(稀疏度是测量的1/4) for col=1:N; % 恢复矩阵的所有列向量 product(col)=abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值) end [val,pos]=max(product); % 最大投影系数对应的位置 Aug_t=[Aug_t,T(:,pos)]; % 矩阵扩充 T(:,pos)=zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零) aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; % 最小二乘,使残差最小 r_n=s-Aug_t*aug_y; % 残差 pos_array(times)=pos; % 纪录最大投影系数的位置 if (norm(r_n)<0.9) % 残差足够小 break; end end hat_y(pos_array)=aug_y; % 重构的向量
结果:

三、OMP算法中的数学知识
算法会有一些线性代数中的概念和知识,主要是关于子空间、最小二乘、投影矩阵等,详情请参考
(数学)最小二乘的几何意义及投影矩阵
主要内容:
-
什么是最小二乘
-
最小二乘的几何意义
-
正交投影矩阵
什么是最小二乘?
假设我们手上有n组成对的数据,{(xi,yi):i=1…n},为了探究y变量与x变量的关系,我们希望用一个多项式来匹配它,可是多项式中的系数怎么确定呢?拿来拼凑肯定是不行的,最小二乘法告诉我们,这个多项式的系数应该让每个点的误差的平方之和最小。
(百度百科)最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。




最小二乘的几何意义
最小二乘的几何意义:最小二乘法中的几何意义是高维空间中的一个向量在低维子空间的投影。
从上面的定义中,我们很难想象到最小二乘的几何意义,那么我们通过一个简单的例子来推导一下:

我们根据定义中的误差平方之和最小化来拟合直线:
每个点的误差表示:
最小误差的平方和:
要求解上面的最小化问题,我们可以通过求导的方式得到,最好是转化为矩阵表达形式:AX=b (这里x表示上述的系数a)
求得结果为:

如果通过超定方程的解法 ,很容易就可以得到上面结果。
,很容易就可以得到上面结果。
先来说说向量表达形式:

小括号中表示:它是两个向量 [1, ... , 1]T 和 [x1, ... , xn]T 的线性组合,换句话说,它是这两个向量构成的二维子空间(想成一个平面就可以)的任意一点。
那么上面式子的几何含义:表示向量 [y1, ... , yn]T(表示空间中的一点) 到这个二维子空间任意一点的距离;(向量的长度)
最小化上面式子的平方(向量长度的最小化)的几何含义:寻找在 [1, ... , 1]T 和 [x1, ... , xn]T 构成的二维子空间上的一个点,使得向量 [y1, ... , yn]T 到这个点的距离最小。怎么找这个点呢?只要做一个几何投影就好了。(如下图)

如上图所示,在三维空间中给定一个向量 u,以及由向量 v1,v2 构成的一个二维平面,向量 p 为 u 到这个平面的投影,它是 v1,v2 的线性组合:
利用投影的垂直性质,我们可以得到关于系数C的两个方程:

令 V = [v1, v2], p = c1v1 + c2v2,将上述式子合并并转化为矩阵形式(更容易扩展到高维空间),得到:


因此系数c的表达式为:

有没有发现很熟悉?和式子  一模一样有木有!!!
一模一样有木有!!!
好了,我们回到原来的例子,看看几何关系中的投影点和被投影的空间分别代表什么。
把图中的 u 替换成 [y1, ... , yn]T ,把 v1,v2 分别替换成 [1, ... , 1]T 和 [x1, ... , xn]T, 系数 c1 和 c2 也就是我们要求的 a0,a1。
所以,最小二乘法的几何意义是高维空间的一个向量(由y数据决定)在低维子空间(由x数据以及多项式的次数决定)的投影。
正交投影矩阵
上面提到了最小二乘的几何意义就是空间中的投影,其实投影在线性代数中也是存在其数学公式的,可以联系以下数学知识来理解最小二乘的几何意义。
张成子空间:

张成子空间的投影矩阵:

最小二乘的投影解释:



