
- 1华为OD机试C、D卷 - 拼接URL(Java & JS & Python & C & C++)_org.springframework.amqp.amqpioexception: java.io.
- 2太原理工大学软件学院信息安全方向信息安全技术与应用复习_太原理工大学软件安全技术
- 32024-05-19 RabbitMq整合SpringBoot快速入门_rabbittemplate创建绑定队列
- 4HTML5---Canvas-画线,空心图,矩形,文字,三角形,旋转图片_canvas三角形绘制文字
- 5Qt制作程序启动界面类QSplashScreen实例测试详解
- 6AI大模型探索之路-实战篇:智能化IT领域搜索引擎之github网站在线搜索
- 7Flink中的分流合流操作_flink 分流操作
- 8P5018 [NOIP2018 普及组] 对称二叉树
- 9详解LinkedList与链表_listnode 与linkedlistnode
- 10基于K8s调度器实现自定义调度
AlphaFold3—转录因子预测(实操)_alphafold3使用教程
赞
踩
写在前面
我们上一次已经介绍了如何使用AlphaFold3:最新AlphaFold 3:预测所有生物分子结构、相互作用
AlphaFold3可以做什么?
1.AlphaFold服务器可以对以下生物分子类型进行建模,评价其相互结合:
-
蛋白质
-
DNA
-
RNA
-
生物常见配体:ATP、ADP、AMP、GTP、GDP、FAD、NADP、NADPH、NDP、血红素、血红素C、肌酸、油酸、棕榈酸、柠檬酸、叶绿素A和B、细菌叶绿素A和B
-
生物常见离子:Ca2+、Co2+、Cu2+、Fe3+、K+、Mg2+、Mn2+、Na+、Zn2+、Cl-
-
生物常见氨基酸残基的翻译后修饰(PTMs):
-
丝氨酸、苏氨酸、酪氨酸和组氨酸残基的磷酸化
-
赖氨酸残基的乙酰化
-
赖氨酸和精氨酸残基的甲基化
-
半胱氨酸残基的丙二酰化
-
脯氨酸、赖氨酸和天冬酰胺残基的羟基化
-
半胱氨酸残基的棕榈酰化
-
天冬酰胺残基的琥珀酰化
-
半胱氨酸残基的S-亚硝基化
-
色氨酸残基的甲酰化
-
赖氨酸残基的丁二酰化
-
赖氨酸和精氨酸残基的琥珀酰化
-
某些糖组成的糖链(包括支链):α/β-D-葡萄糖、α/β-D-甘露糖、α-L-岩藻糖、β-D-半乳糖、N-乙酰-β-D-葡萄糖胺
-
-
DNA的生物常见化学修饰:
-
胞嘧啶、鸟嘌呤和腺嘌呤的甲基化
-
胞嘧啶的羧化
-
鸟嘌呤的氧化
-
胞嘧啶的甲酰化
-
-
RNA的生物常见化学修饰:
-
胞嘧啶、鸟嘌呤、腺嘌呤和尿嘧啶的甲基化
-
尿嘧啶异构化为假尿嘧啶
-
胞嘧啶的甲酰化
-
注:
建模所选择的entity可以由多个蛋白质、核酸、配体和离子组成。每个蛋白质和核酸链可以具有任意数量的化学修饰。所以你想研究甲基化、磷酸化都不是问题!
2. AlphaFold输入要求
-
对于蛋白质,输入单字母氨基酸序列或粘贴包含注释行的FASTA文件内容。仅使用标准单字母代码(不支持非标准代码如B、J、O、U和X)。
-
对于DNA,输入标准符号表示的单字母核苷酸序列(5'-3')。仅使用标准单字母代码(A、C、T和G)。对于双链DNA,从DNA输入的选项中选择“+反向互补”选项以添加互补链。
-
对于RNA,同样输入标准符号表示的单字母核苷酸序列(5'-3')。仅使用RNA核苷酸的标准单字母代码(A、C、U和G)。
-
对于配体、离子和翻译后修饰,从支持的类型列表中选择所需的实体。UI中显示的三字母代码来自蛋白质数据银行的化学组分词典。
- 如果存在多个实体的副本(例如同源多聚蛋白),通过在相应字段中设置副本数来指示。
如何把AlphaFold3应用在我们的科研论文中呢?
仔细想想:只要是涉及到不同分子间的相互作用都可以使用AlphaFold3
所以,下面我们使用AlphaFold来预测基因的转录因子
转录因子相关概念
在开始之前,我们来复习一下什么是转录因子?什么又是转录因子结合的的特定的DNA序列(转录因子结合位点)?
转录因子(Transcription Factors,TFs),是指能够以特定序列与基因专一性结合,从而保证目的基因以特定的强度在特定的时间与空间表达的蛋白质分子。转录因子通过识别特定的DNA序列来控制染色质和转录,以形成指导基因组表达的复杂系统。
转录因子(transcription factor)是一群能与基因5`端上有特定序列专一性结合,从而保证目的基因以特定的强度在特定的时间与空间表达的蛋白质分子。
转录因子是一类能够与特异DNA序列结合并调节基因表达的蛋白质。转录因子通过DNA结合结构域识别基因附近的DNA序列,如启动子中的TATA盒、CAAT盒、GC盒等元件。这些DNA序列被称为转录因子结合位点(TFBS),通常很短,但具有序列多样性和变异性。转录因子结合位点的鉴定是揭示转录调控机制的重要步骤
也就是说,转录因子发挥作用时,涉及到两个主要的entity:蛋白质分子和特定的DNA序列
转录因子预测实操
应用情景
已知靶基因,如何预测转录因子?
预测转录因子首先要获得靶基因的启动子序列,再采用相应的网站来预测其转录因子。但是这种方法经常存在一些问题:
-
1 不同网站由于算法不同,预测的转录因子结果可能存在差异
-
2 转录因子的作用受到许多生物学因素的影响,如组织特异性、信号通路调控等。因此,预测转录因子时需要考虑这些复杂性。
-
3 预测转录因子基于启动子序列的生信分析,仅作参考,还需要通过实验进行验证。
针对第3个问题,我们可以通过Alhpafold3来验证预测的转录因子与把基因是否有结合。也是本篇推文的想要解决的痛点。
因此,我们假设读者已经获取了自己的靶基因的TFBS序列和预测的转录因子蛋白序列。为了演示,假设我们的靶基因是INMT
第一步1. 获取靶基因的转录因子结合位点(TFBS)序列
1 获取目的基因的启动子系列
打开NCBI(https://www.ncbi.nlm.nih.gov/),下拉选择Gene,输入目的基因(如INMT),点击search

结果部分注意种属(以第一个人为例),点击进入
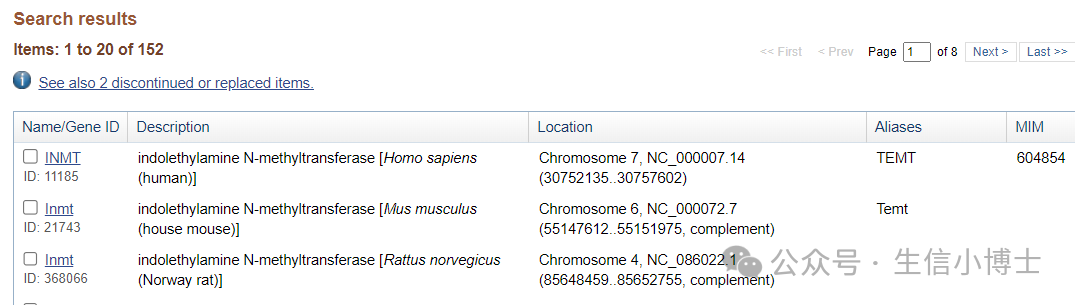
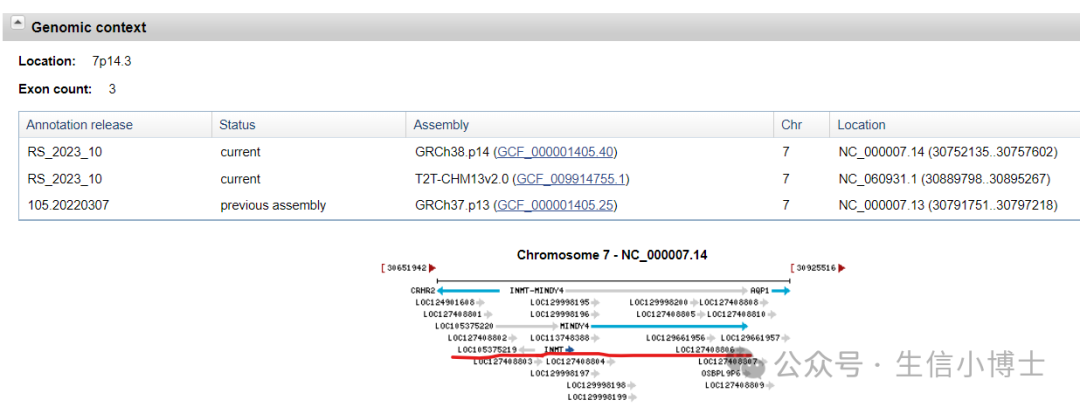
默认启动子区域位于转录起始位点上游2kb左右,
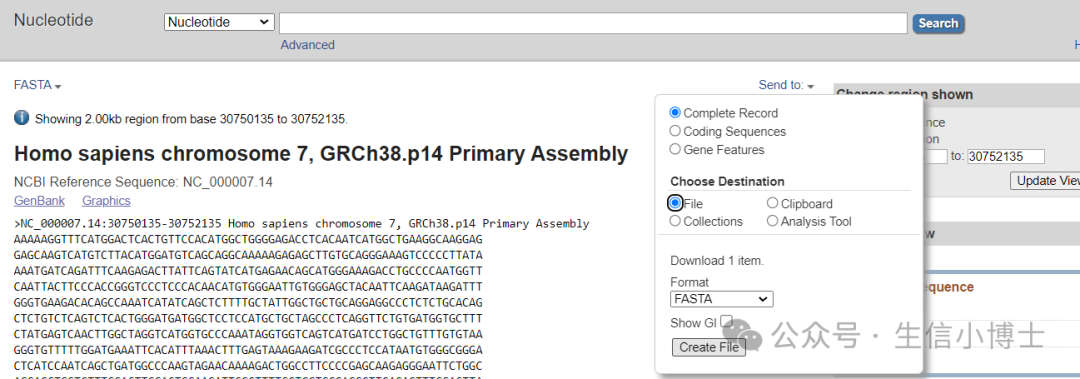
因此INMT的启动子区域:chr7:30752135-2000 —— 30752135

copy结合位点的DNA序列到AlphaFold3中
第二步 2. 我们可以使用hTFtarget网站获取INMT的转录因子名称
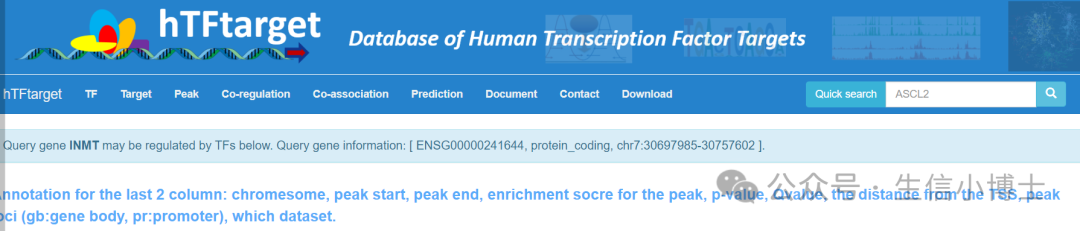
这里我选择BRD4
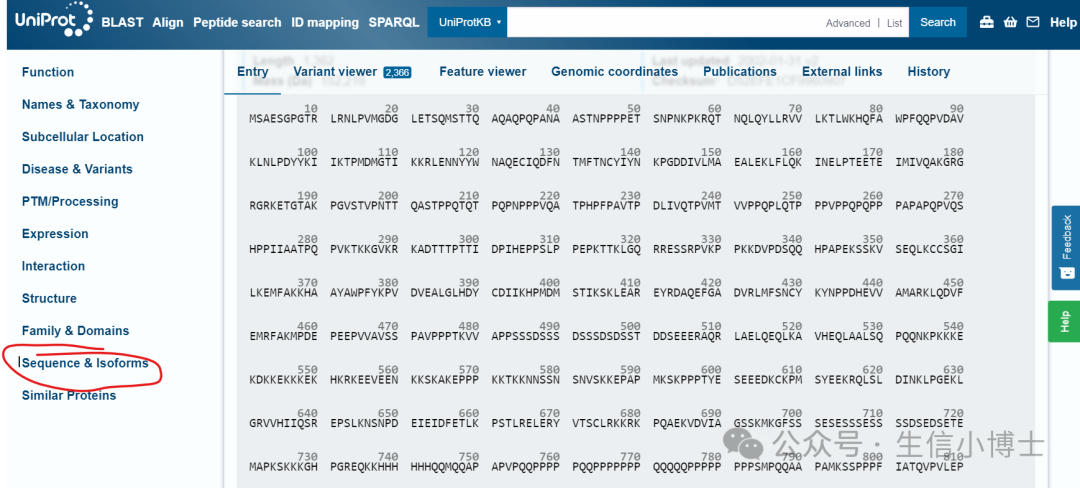
第三步 3. 获取转录因子BRD4的蛋白序列,使用Uniport网站
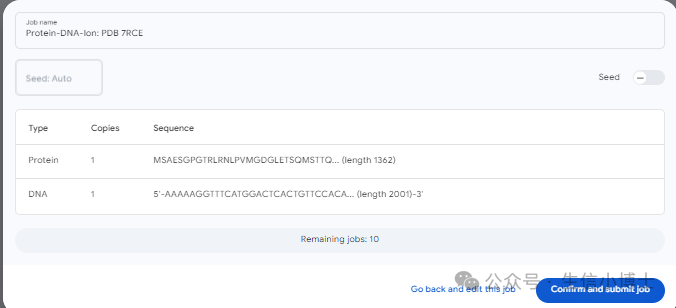
第四步 4. 把DNA序列和BRD4的氨基酸序列输入AlphaFold3进行预测
结果
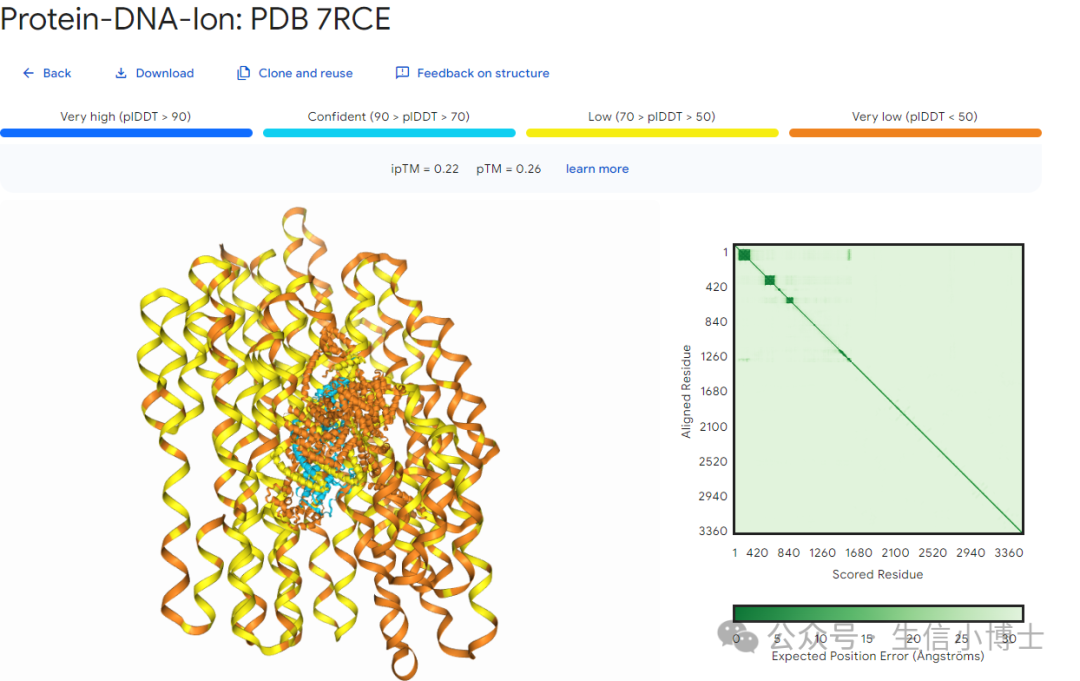
从图像上来看,有一些序列结合还是挺紧密的,但是使用哪些指标来评价相互作用的强度呢?如何获取互作的具体序列呢?
由于我也是刚使用AlphaFold,这个问题留到下次我们再来分享
如有不足之处,欢迎指正——生信小博士
生信小博士
【生物信息学】R语言开始,学习生信。Seurat,单细胞测序,空间转录组。 Python,scanpy,cell2location。资料分享
公众号
参考:https://www.zhihu.com/question/570561753/answers/updatedhttps://golgi.sandbox.google.com/fold/6dc7596c17dec8adhttps://golgi.sandbox.google.com/faq#how-can-i-interpret-confidence-metrics-to-check-the-accuracy-of-structures?- 父pom
17[详细] 赞
踩

