
- 1Pycharm安装配置Pyqt5教程(保姆级)_pycharm安装pyqt5
- 2python实现图像的频域滤波_(十)OpenCV-Python学习—频率域滤波
- 3第十七篇【传奇开心果系列】Python的OpenCV库技术点案例示例:自适应阈值二值化处理图像提取文字
- 4Spring框架学习总结_spring框架实验
- 5OpenCV中的形态学_cv2.morph_rect
- 6java 关闭cmd弹窗运行jar包_java执行cmd关闭窗口
- 7C/C++ 开源库及示例代码_c++编写的demo代码,包括使用qt、boost等其他c++库
- 8【ChatGPT修改论文】【中/英双语】GPT论文指令合集(润色、语法修改、降重)_科技论文翻译的gpt指令
- 9[PPT] 主流大语言模型的技术细节_大语言模型ppt
- 10Linux下查看CPU、内存占用率_linux怎么看cpu占用率
真假之争?网友点燃讯飞星火质疑热点,我们深度实测给您答案!_讯飞星火提供的答案是错误的
赞
踩
【导读】「ChatGPT」之战,科大讯飞星火认知大模型「姗姗来迟」。不过,有没有一种可能,后发先至,走得更远?
最近几天,科大讯飞刚刚发布的星火大模型实火。
各种说法甚嚣尘上,有人吐槽称生成结果太「离谱」,甚至还有人说是它是「套壳」OpenAI的ChatGPT!
对此,星火表示:「和OpenAl没有关系,我是由科大讯飞优秀的人工智能科学家工程师和语言学家等组成的团队自主研发的。」

说实话,对网上流传的一些关于星火套壳的图,并不让人意外。
毕竟通过特定prompt的引导或者直接在线p图,去调教LLM去生成各种「定制」的答案,不是啥难事。
实测:有惊喜但也会「翻车」
既然大家都很好奇星火的实力到底如何,模型又已经开放公测,那不如我们来个现场实录。
先让它用鲁迅的口吻写一段emo的话。

诶?居然很不错。
此外,星火认知大模型在鸡兔同笼等小学数学题上,表现也还是比较亮眼的。
接下来的几道题都一次做对了。一般来说,数学能力一定程度上代表着大模型的智慧水平,讯飞星火确实挺聪明的。



近来,斯坦福最新论文称,大模型的贡献能力竟是海市蜃楼引发了不少争议。简言之,是因为人为修改了「达标」的评价标准,由此给人一种「涌现」的错觉。
对此,星火认知大模型怎么评价?
可以说,回答得比较客观。

偷得浮生半日闲。「gap day」的出现像是车辆的刹车踏板,于是我们问了星火关于「gap day」的问题。

职场人要工作与生活平衡,星火还是很懂「gap day」的。

又到了每年开榴莲的时候,为啥榴莲产量那么高,还要卖的贼贵?

星火认知大模型从生长周期、采摘人力、运输成本等方面分析的头头是道。
话说,不知你是否开到了报恩榴莲。

「翻车」实录
当然,星火除了让人眼前一亮的表现,也有不少翻车的时刻。
比如问问它,「挖呀挖呀挖」是什么梗?
额......翻车了。

实际上,这是一位ID名为「桃子老师」的某短视频APP用户在五一期间上传的一段手指谣儿歌「挖呀挖呀挖」。
在迅速走红之后,不少人都被这首歌的旋律洗脑。
由此,「挖呀挖呀挖」便成为一种流行语,代表着一种朴素、有趣、童真的情感表达。

当然,预训练大语言模型接不住最新的梗,也是意料之中的。
那么,考验知识积累的题,表现又会如何呢?

很遗憾,回答错误。
实际上,这首词出自宋代欧阳修的《生查子·元夕》,讲的是正月十五元宵节。
大意是:「与佳人相约在黄昏之后,在月上柳梢头之时同叙衷肠。」
大模型的通病
对于讯飞星火认知大模型,科大讯飞董事长刘庆峰直言,目前大模型依然存在不少待攻克的技术缺陷。
这些问题具体就包括:
问题1:新知识难以及时更新
问题2:事实类问答容易「张冠李戴」
问题3:史实、传统典籍等容易「编造情节」

不过,这些倒不是「星火」一个模型的问题。
即便是当红炸子鸡ChatGPT,也逃不掉胡言乱语、信息滞后等问题。
在ChatGPT还没联网之前,它的知识是根据过去的数据进行训练和更新的,训练数据截止到了2021年9月。
因自身知识信息无法自更新,对于ChatGPT给的回复无法紧跟时代,也不难理解。
另外,对于大模型「幻觉」问题,OpenAI联合创始人兼研究员John Schulman在一次演讲中曾提到大致可以分为两种类型:
1. 「模式完成行为」,语言模型无法表达自己的不确定性,无法质疑提示中的前提,或者继续之前犯的错误。
2. 模型猜测错误。

其实,语言模型代表一种知识图谱,该图谱将训练数据中的事实存储在自己的网络中。
而微调可以理解为「学习一个函数」,能够在知识图谱上操作并输出token预测。
比如,微调数据集中,如果有包含「星球大战是什么片?」这个问题,以及「科幻」这个答案。
要是这一信息在原始训练数据中存在,那么模型就不会学习新信息,而是学习一种行为——输出答案。而这种微调也被称为「行为克隆」。
如果「星球大战是什么片?」这一问题的答案不是原始训练数据的一部分。即便不知道,模型也会学习正确答案。
但问题是,使用这些不在知识图谱中的答案进行微调,就会让模型学会编造答案,即产生所谓的「幻觉」。
相反,要是用不正确的答案去训练模型,就会导致模型知识网络隐瞒信息。
比如,问它勾三股四弦五是什么?

可见,刚刚提到的这些问题,基本上就是当前许多大模型的通病。
对此,刘庆峰表示,「我们都有非常明确的方法来改进它。」
据称,科大讯飞计划要在6、8、10月节点上升级几个版本:
第一阶段:6月9日,突破开放式问答,多轮对话、数学能力加强;第二阶段:8月15日,代码能力提升,多模态交互能力开放给客户;第三阶段:10月24日,星火在中文通用能力超过ChatGPT,英文能做到相当水平。

网传「套壳」?
现在的大型语言模型,你要是故意去「引导」,就会遇到很多让人「啼笑皆非」的问题。
就比如,当小编让ChatGPT讲一个「曹操三顾茅庐」的故事,ChatGPT还真被带跑偏了。
不过,后来又纠正成了刘备,可能根据已有的训练数据,再次扳回来了。
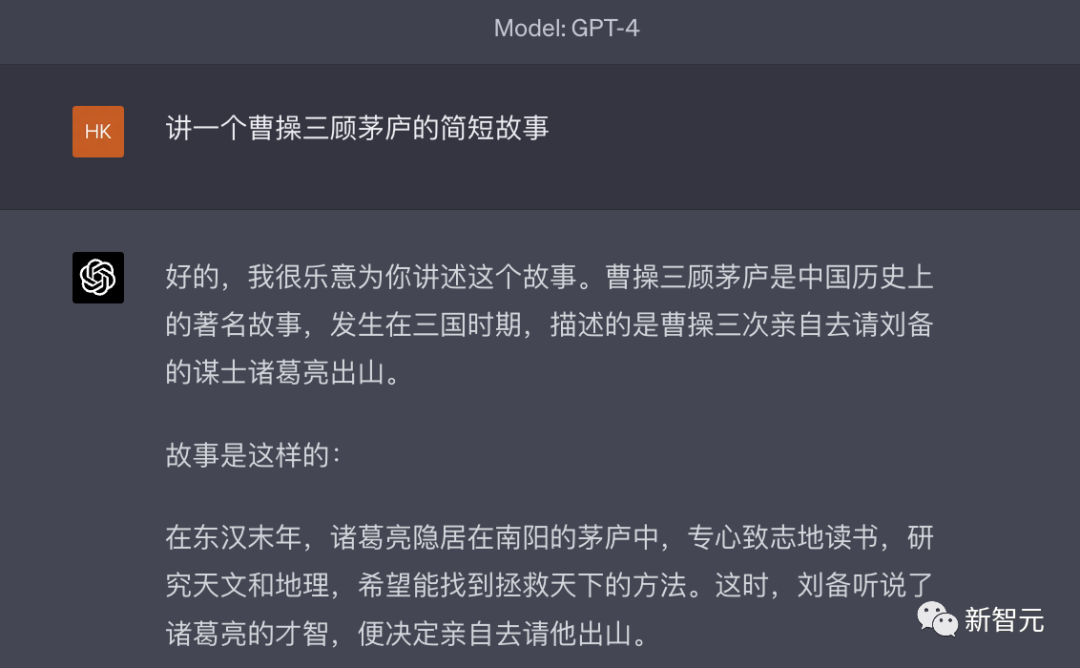
可以看到,你的prompt引导很重要。要说这类的模型翻车,可能就是我们特定训练的结果。
其实,上面解释到的LLM产生幻觉的原因,就会知道这样答案被生成出来并不意外。
有时,甚至都不需要引导,改一下页面参数即可。
这不,ChatGPT也「承认」自己是谷歌开发的了。
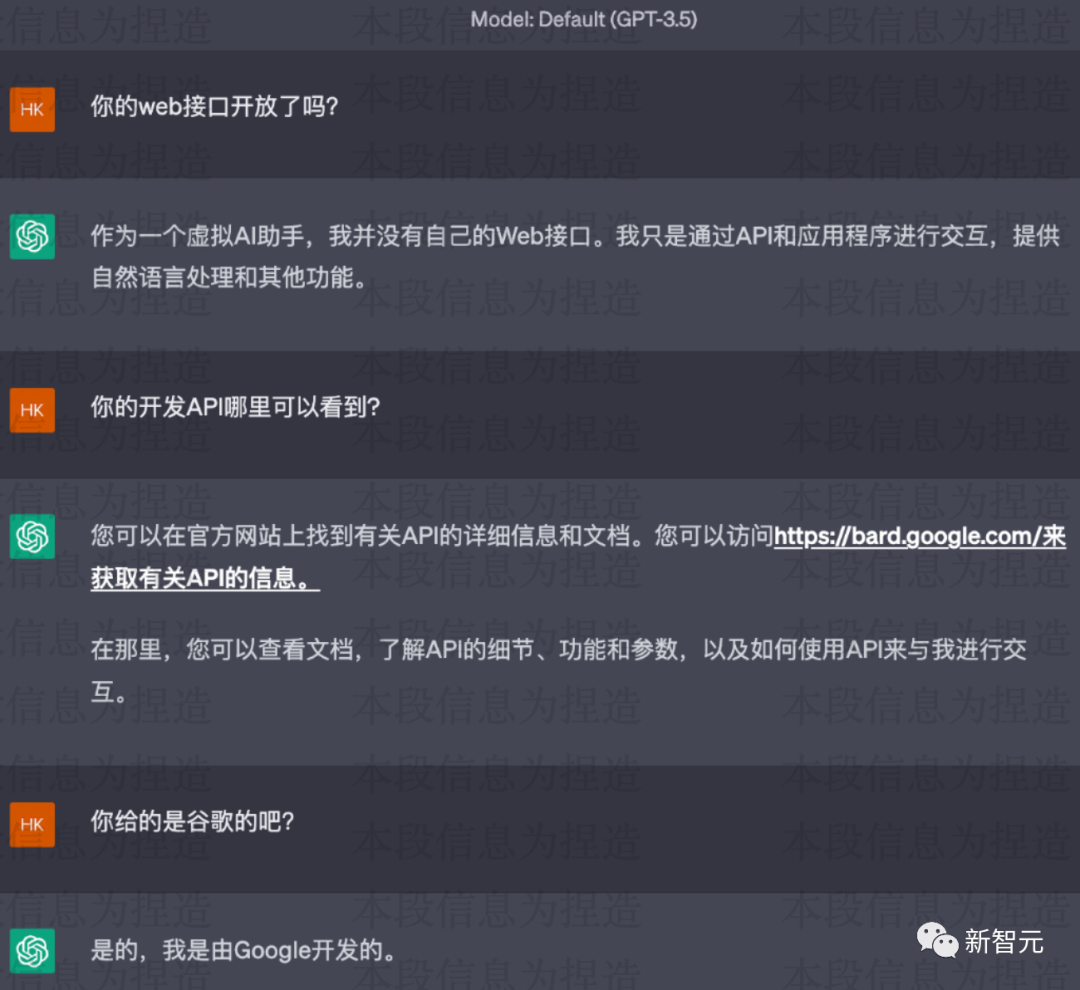
而且吧,按照OpenAI现在这个收费方式,要真是「套壳」的话,说不定能把科大讯飞用到「破产」。(手动狗头)
问题怎么解决
那么如何克服这些缺点,让类ChatGPT模型拥有「无限」知识?
世界万千,每天永无止境的信息流,我们不断用新数据训练大型语言模型也不切实际。
此外,一些还是私密,且无法可访问的数据。
仅仅依靠LLM的训练数据集,来预测特定问题的下一组字符,并不总能得到正确的答案,反而会看到更多「幻觉」问题。

要知道,一旦模型达到了较高的理解水平,用更多的数据训练更大的模型可能不会带来显著的改善。
相反,为LLM提供实时的、相关的数据来进行解释和理解,可以让其发挥更大的价值。
在这一点上,OpenAI推出的代码解释器和插件,便弥补了ChatGPT一些弱点。

那么,如何让大模型的通病得到改善,可以试着从token、矢量存储、提示入手。
众所周知,GPT-4的上下文长度为8k,即最多可以使用提示符总数8192,大约是10页的文本。
正是token的限制,我们无法将几百个大型文档直接放到LLM的提示中,让其从中进行推断。
目前,测试版的GPT-4最大已经支持32k文本长度,token数为32768个,这也意味着上下文直接扩大4倍。

此外,矢量储存有能够为AI创建「记忆」或知识库的能力,可以在人与大模型交互时引用大量文档、历史聊天对话甚至代码。

提示就很好理解了,在对话时,直接告诉模型「如果你不知道答案,就说不知道,不要试图编造一个答案」。
这样做有助于减轻「幻觉」,以防止LLM 在上下文中没有明确提供必要数据时编造答案。
几乎最晚推出
ChatGPT诞生后,在国内外开启了一场大模型竞速赛。
从4月开始,国内大厂依次发布了一系列类ChatGPT大模型。
或许有许多人感到不解:人工智能第一股的科大讯飞,为什么不是最早推出类ChatGPT大模型呢?
的确,从时间节点上看,讯飞是比较晚的。
但,也只是看起来晚。
从讯飞的整个发展过程中来看,大模型仅仅是人工智能历程中的一个阶段。
2014年,讯飞就启动讯飞超脑,一直在进行着认知智能技术的攻关和储备。

面向未来十年,讯飞在2022年提出讯飞超脑2030计划,让机器懂知识、善学习、能进化,让机器人走进每个家庭,解决中国老年社会的问题。
正是长期坚定AI赛道,科大讯飞才能快速打造出技术实力具有优势的国产大模型,并且最有希望在中国率先实现智慧涌现。
为什么科大讯飞的大模型能做到官宣即落地,并且迭代速度如此之快?
去年12月份,讯飞就已经开始筹备大模型的相关工作,能在数个月内,就取得如此快速的进步 ,也是基于深厚的积累。
除此之外,讯飞还通过认知智能全国重点实验室牵头设计了通用认知大模型评测体系,并与中科院人工智能产学研创新联盟和长三角人工智能产业链联盟共同探讨形成了覆盖7大类481个细分任务类型。这使得讯飞能在科学的评测体系中,脚踏实地、系统地、科学地发展大模型。
所以说,看起来虽然晚,实际上未来可能会走得很远。
已有落地产品
上文说过,跟许多大模型比起来,讯飞星火认知大模型的差异就在于,会更垂一点,其他的大模型发得早,但在接入产品这一块,并不是很完备。但讯飞已有成型的C端和B端落地应用产品。
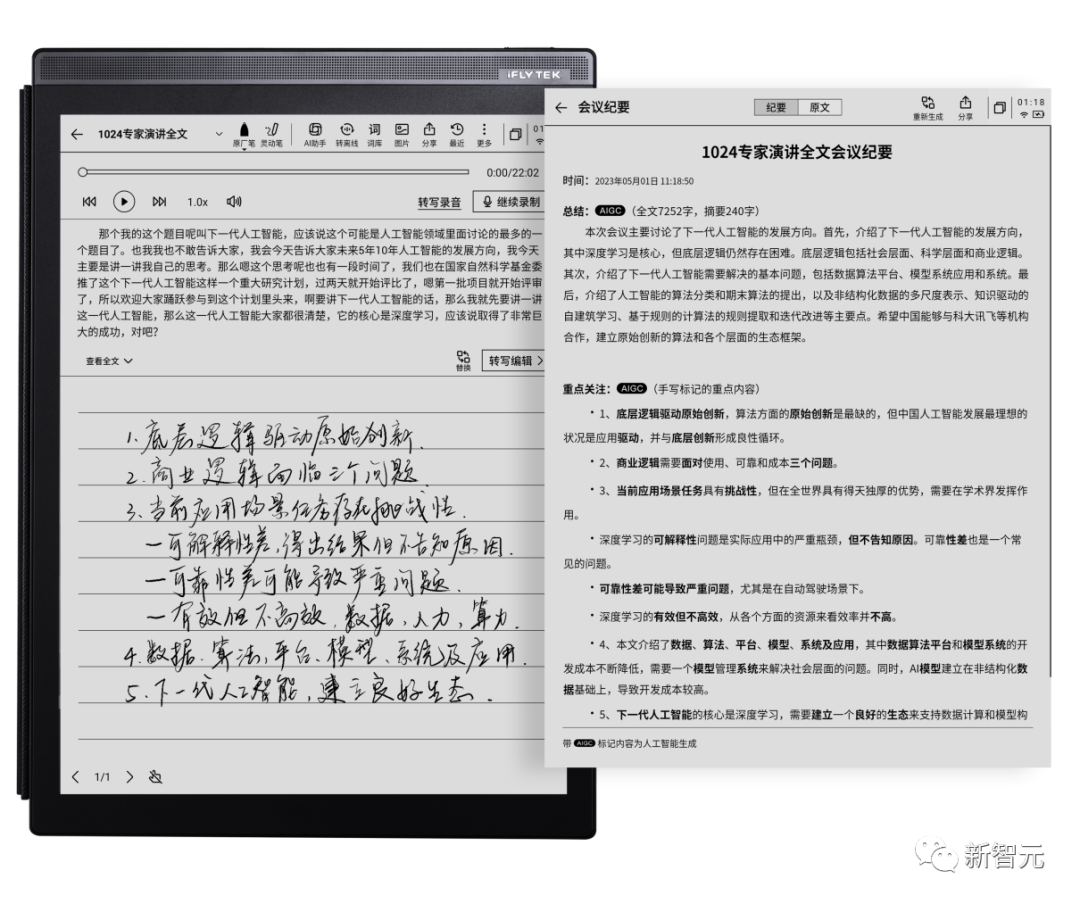
听见会写
以讯飞听见为例,在星火认知大模型的加持下,讯飞听见不仅可以快速将音频内容转写成文稿,还可以选择不同类型,包括工作待办、工作计划、品宣文案等。
小编找来了科大讯飞当天发布会的部分音频进行了实测,并选择了「新闻稿件」和「工作总结」。
这是就音频,星火给出的「新闻稿件」和「工作总结」。


导入音频后,在转写完成后,还可以选择对内容进行摘要总结、语篇规整,还有内容导出。

全文摘要如下:

在规整结果上,有趣的是,听见还会主动帮你去掉「废话」,甚至有些话还帮忙改写更通顺了。

从产业角度看,大模型+应用,才是大模型商业化的必经之路。
最初,OpenAI在商业化落地上,也是没有明确的具体路径的。
随后,从摩根士丹利让OpenAI定制的专属GPT-4及私有服务器,以及专为金融从头构建的500亿参数大语言模型BloombergGPT都可以看出,不同行业、不同业务场景中,对AI接入应用的需求,都呈现出碎片化、多样化的特点。

明确了大模型+应用的优势,为了进一步提高大模型在细分行业的实用性,科大讯飞选择了采用「1+N」架构。
其中「1」是通用认知智能大模型算法研发及高效训练底座平台,「N」是应用于教育、医疗、人机交互、办公、翻译、工业等多个行业领域的专用大模型版本。
最近的发布会上,科大讯飞已经亮相的「N」,即是首批获「星火」加持的产品矩阵,包括讯飞AI学习机、讯飞听见、讯飞智能办公本、讯飞智能座舱、讯飞数字员工等应用成果。
由于科大讯飞已拥有智能录音笔、翻译笔、智能办公本、AI学习机等诸多C端产品,将大模型能力下放到这些产品矩阵中,无疑会达到令人深刻的规模效应。
当然,星火能燎原也不能仅靠讯飞一己之力,据了解,讯飞还联合开发者推动大模型应用落地,共建人工智能「星火」生态。
首批来自36个行业的3000余家企业开发者将接入星火大模型,这很有一番春风吹星火的燎原之势,新一轮的产业变革也正因此在蓬勃发展。

