
- 1K8S 日志方案
- 2(附源码)springboot学生宿舍管理系统 毕业设计 211955_宿舍管理系统毕业设计
- 3【Linux】Linux之间如何互传文件(详细讲解)_linux把文件传到另一个linux
- 4JavaScript鼠标拖动事件监听使用方法及实例效果_监听鼠标移动
- 5【Elasticsearch篇】详解使用RestClient操作索引库的相关操作
- 6【Python】01快速上手爬虫案例一
- 7深度学习算法应用实战 | 利用 CLIP 模型进行“零样本图像分类”
- 8【C++进阶1--继承】面向对象三大特性之一(附菱形继承讲解
- 9qml学习----------------(progressBar)进度条的学习_qml progress bar 横向为纵向
- 10【Python】文件操作中的a,a+,w,w+几种方式的区别_转_python a+
【实战案例】商品推荐算法(1)_智能推荐算法案例
赞
踩
本篇分享适用于中小电商平台的商品推荐算法,理论与实践结合出发>>>
认真读完本篇,你会收获:
1. 为什么各个电商平台都热衷于做个性化商品推荐?
2. 常见的商品推荐场景有哪些?以及实践中的项目流程。
3. 一个完整的商品详情页实战案例,零基础也可以写推荐算法。
一、为什么各个电商平台都热衷于做个性化商品推荐?
一句话:能增加收入。

分析这个问题要从电商销售额构成来讲:GMV=流量*转化率
先来看图中这4款饮品,你喜欢蓝色清新A,还是抹茶口味B,或是焦糖浓郁D?也可以问一问身边的朋友更喜欢哪款?你们喜欢的是否是同一款?

这里我想表达的是:对于不同的顾客,偏好的饮品是不同的,如果来到店里的每位客人我们都推荐饮品A,那么喜欢饮品D的客人可能会认为这家店过于清淡不太适合自己。为了实现转化率/销售额的最大化,需要做好顾客与商品的匹配关系。
所幸电商的数据积累以及店铺商品呈现,给这个想法提供了极佳的实现条件。
二、商品推荐场景+实操流程
1. 商品推荐场景
1>按照购物流程划分,有四种常见推荐位置:首页瀑布流推荐、商品详情页推荐、购物车推荐、结算页满额加购推荐。
(用户搜索关键词的商品结果排序不在此处展开讨论)
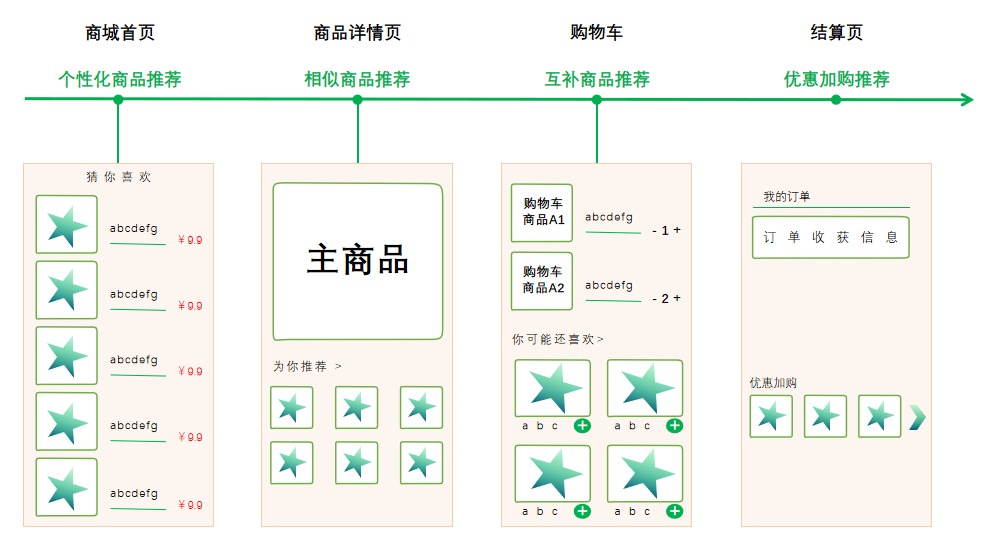
2>按照用户的购买场景划分:有明确购物需求的搜索、直奔某品类、随便逛逛、比价、送礼等。
ps:如有更好的场景划分方法,欢迎留言哦~
2. 常用商品推荐逻辑
1> 推荐的目标:根据用户已知的信息,推测出用户可能感兴趣的商品。
2> 分析达到目标的路径(解题):
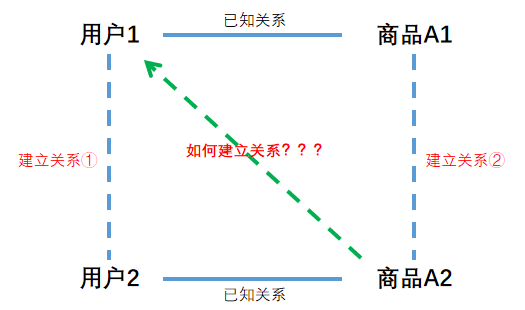
如下图:如何将商品A2与用户1建立联系?
两种途径:建立用户1与用户2之间的关系1,建立商品A1与商品A2之间的关系2
3> 寻找解题线索:
从数据源头出发,电商最常见的数据分为两类:
a)用户在商城内的行为数据,如浏览、访问、停留时长等;
b)用户的下单支付数据。
基于这两类数据,可以分析用户相似度、购物篮商品关联度...
4> 如何建立关系1 or 关系2?
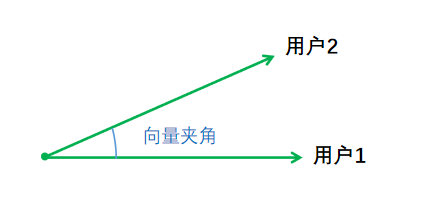
关系1:通过将用户在商品的行为数值化为一个N维向量,计算两两向量之间的夹角余弦值,来评估他们的相似度,又称为余弦相似性。
(余弦值区间[-1,1],0度角的余弦值是1,夹角越小用户行为越相似)
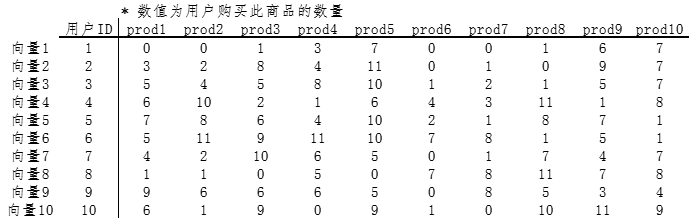
用户行为转化为N维向量数据结构示例:
两个向量的余弦相似性计算公式:

接下来以每个用户为中心,分别计算与其他n-1个用户的余弦相似度,需要n(n-1)次计算;
假设n=10000,计算99990000次,计算机每秒计算100次,更新一次全量用户的相似性需要11.6天;可以看出这个计算量非常大且耗时,以及无法满足商业环境中的实时反馈要求,因此在真实环境中几乎不采用这种推荐路径。
关系2:通过将每个用户在商品上的操作作为一个购物篮,计算每两件商品出现在用一个购物篮的几率,来判断商品A与商品B之间的相似性/关联度。在本篇第三部分实战案例中,会对此方法进行详细介绍。
3. 实践中的项目流程
很多情况下,数据分析是一个相对独立且单线程工作的岗位,接收需求处理需求。当涉及到影响商城业务时,需要多团队合作,流程上的合作方/环节越多,出错的几率也会越大,这时候需要承担起项目经理的角色,更加细致认真得排查可能出现的问题。(ps:遇事不抓狂,有话好好说)

流程这里不啰嗦啦,简单概括:
1>数据调研------>>>为什么要做这件事?
2>立项------>>>确定要做这件事,准备怎么做?(需要哪些人分别负责什么?)
3>算法准备------>>>确认商品推荐的逻辑
4>功能开发------>>>商城功能是否支持个性化推荐?
5>部署测试------>>>测试环境中是否逻辑流畅?显示正常?
6>功能上线------>>>上线前的数据监控准备
7>结果数据&结论------>>>项目的结果反馈
三、实战案例
以商品详情页推荐为例,介绍相对简单的中心商品推荐逻辑。
1. 提出可以提升转化率的“假设”
2. 验证假设的方法
3. AB测试的用户分组逻辑
4. 测试时长
5. 推荐算法:从数据源到商品关系的代码实现
6. 测试结果
【1. 提出假设】
假设在商品详情页推荐用户数据归类出的相似商品,可以比运营人员根据经验设置热销品,更符合用户兴趣,推荐商品的点击率更高(从而提高加车转化率)。

【2. 验证假设的方法】
采用AB测试(控制变量法),将用户随机分为AB两组,仅在商品推荐区域有差异(如下图),对比推荐商品的点击率,验证是否B组的点击率更高。
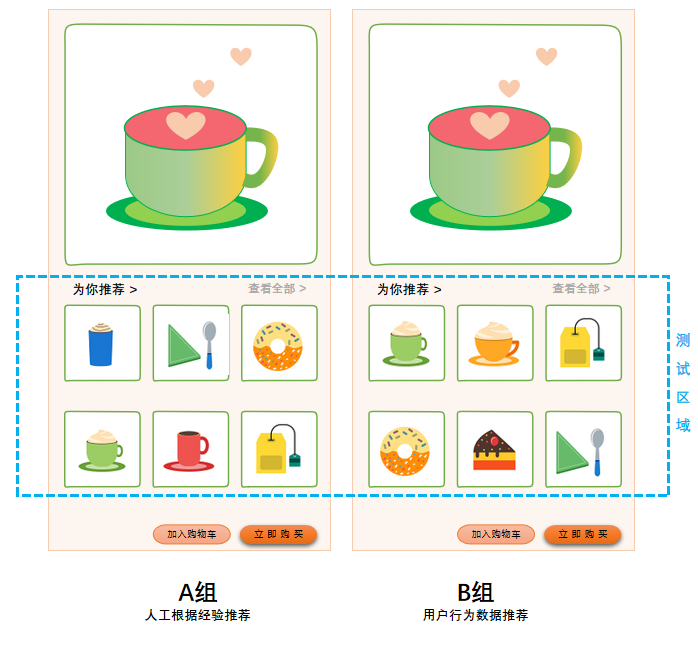
【3. AB测试的用户分组逻辑】
一般情况下用户ID为数值格式,可以将customer_id除以2取余数即可实现分组,余数=0为A组(人工根据经验推荐),余数=1为B组(用户行为数据推荐)。(若分3组,余数分别为0-1-2,以此类推)
【4. 测试时长】
我们的业务属于饮品类,1-7天为一个购买周期,因此实验周期选择了2天。(可以根据业务的属性灵活调整)
【5. 推荐算法:从数据源到商品关系的代码实现】
1> 数据源示例(选取每个用户近期点击的商品数据,表名:data_click)
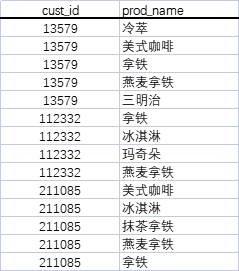
2> 计算商品之间的关联度
# 这里给出的是R语言code,使用Python/SQL的同学可以参考逻辑(代码逻辑都是类似的)
# 目标:计算每两个商品被多少个用户同时购买
data01<-sqldf('select d1.cust_id,d1.prod_name as prod01,d2.prod_name as prod02
from data_click as d1 join data_click as d2
on d1.cust_id=d2.cust_id
where d1.prod_name<>d2.prod_name',drv = 'SQLite')
data02<-sqldf('select prod01,prod02,count(distinct cust_id) as custs_union
from data01
group by prod01,prod02',drv = 'SQLite')
data02数据示例:

3> 商品关联度排序
在实际数据中会遇到热销商品与几乎每一个商品的关联度都在排前几位;
如果每个商品的推荐列表都是热销的饮品,就会畅销商品更加畅销,滞销商品更加没有曝光机会,顾客可能会认为店里就这样几款商品,导致购买商品数减少,频次降低,因此我们需要做一个降低主商品与热门物品相似的计算步骤,给长尾商品更多的曝光机会。
# 每个商品点击的用户总数
data03<-sqldf('select prod_name,count(distinct cust_id) as cust_all from data_click group by prod_name',drv = 'SQLite')
# 匹配每个商品的点击用户总数到商品关联关系表data02
res<-merge(data02,data03,by.x = 'prod01',by.y = 'prod_name',all.x = TRUE)
res<-merge(res,data03,by.x = 'prod02',by.y = 'prod_name',all.x = TRUE)
res<-subset(res,select = c('prod01','prod02','custs_union','cust_all.x','cust_all.y'))
# 降低主商品与热门物品相似,计算关联系数rate_cust
res$cust_all<-sqrt(res$cust_all.x*res$cust_all.y)
res$rate_cust<-res$custs_union/res$cust_all
# 筛选两两商品关联人数≥100(表示是强关联,可以根据业务来灵活调整参数)
res<-subset(res,custs_union>=100)
# 以中心商品prod01,降序排名关联系数rate_cust
res<-res%>%group_by(prod01)%>%mutate(rn=rank(-rate_cust))
res数据示例:
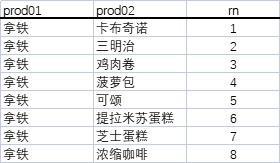
得到上图所示的商品关联关系后,就可以在每个中心商品(prod01)的推荐位展示Top6(rn≤6)的关联商品(prod02)啦!~
【6. 测试结果】

测试6.3上线,立即有显著变化:人均点击商品数从1.5个提升到1.7个,点击率从10.6%提升到12.6%;
再观测一天,数据较为稳定,从6.5开始全部调整为数据推荐。
(ps:有些业务场景会要求提前估算最小样本量以及测试结果的显著性检验,个人认为是有些概念学术化,在实际项目操作中较少遇到。)
以上就是本篇的全部内容啦,如果有任何疑问,欢迎私信小编~

基于用户的商品推荐,请关注>>>【实战案例9】商品推荐算法(2)


