
- 1Python tkinter+pymysql 学生管理系统_python tkthine+mysql 学生管理系统
- 2Windows电脑快速搭建FTP服务教程_windows搭建ftp
- 3Python中进程和线程到底有什么区别?_python线程和进程的关系和区别_python中线程进程的区别
- 4毕业设计:python共享单车数据分析系统 可视化 Flask框架 骑行数据分析 (源码)✅_自行车骑行记录记录数据源代码
- 5【Flink】Flink常量UDF-TableFunction优化_flink udf函数优化
- 6保姆级教程!奶奶都能学会的Mac本地部署Stable Diffusion教程_stable diffusion mac电脑配置
- 7配置uniapp调试环境_uniapp 如何设置测试环境
- 8HDFS HA、YARN HA、Zookeeper、HBase HA、Mysql、Hive、Sqool、Flume-ng、storm、kafka、redis、mongodb、spark安装
- 9汉化版PSAI全面测评,探索国产AI绘画软件的创新力量_startai 好用吗
- 10Web框架开发-Django-模板继承和静态文件配置_djongo web 模板
元数据管理Datahub架构讲解_datahub元数据管理
赞
踩
1. 概述
Datahub的采用了model-first的架构理念,通过提供一个通用的元数据管理模型,再通过插件的方式集成各种数据平台,进行元数据的导入。整体的架构如下:
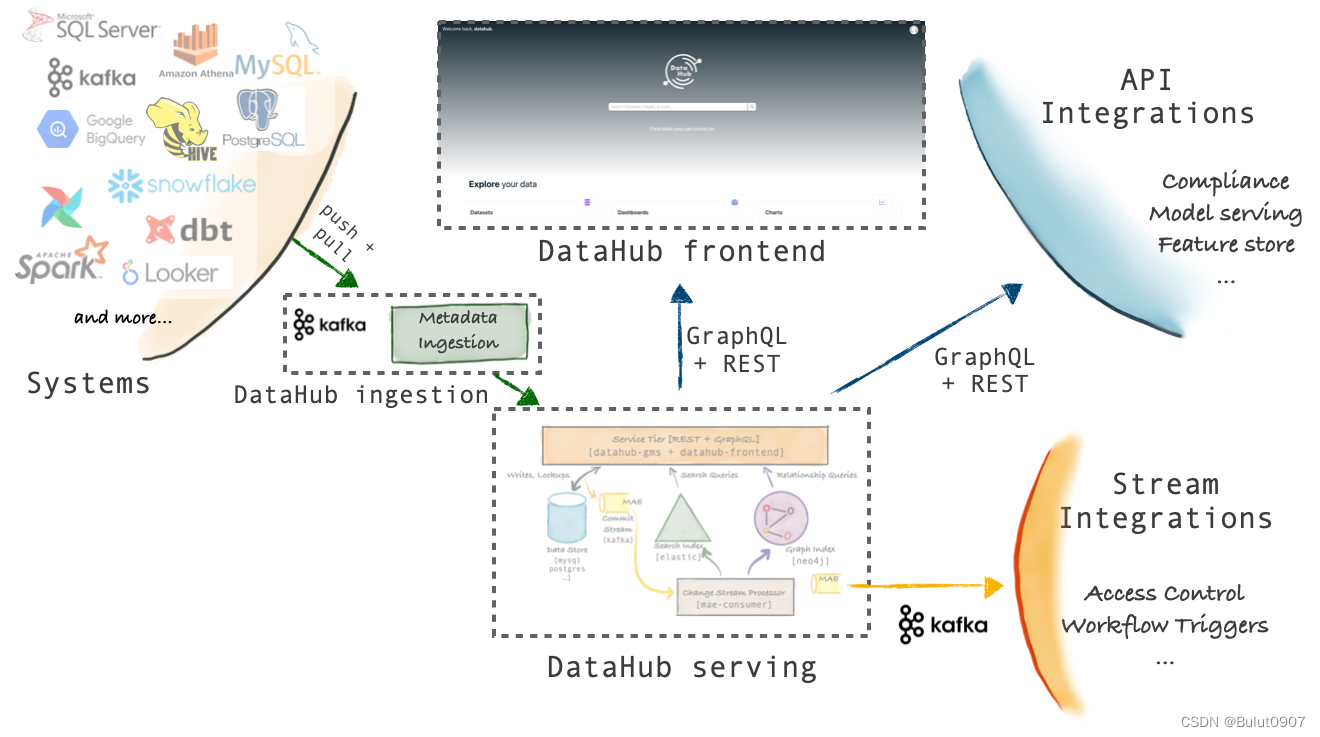
该架构的优点有2个:
- 元数据同步方式多样:可以使用Rest、GraphQL API-s、Avro API(从Kafka消费元数据)
- 数据平台的元数据更改可以实时的被同步到Datahub;在Datahub对元数据进行更改,可以实时的在数据平台进行更新
2. 各模块介绍
2.1 Metadata Store
用于储存Metadata Graph的Entities和Aspects(关系)。同时提供插入和查询API。其中储存由MySQL、Elasticsearch、Kafka负责。Rest API由Java Spring负责

2.2 Metadata Models
元数据模型采用PDL建模语言进行建模。分为Entity、Aspects、Relationships。其中Entity表示一个实体(如果数据库的一个表),每个实体实例都有一个唯一标识符;Aspects表示实体实例的描述、标签等;Relationships表示不同实体实例的关系

2.3 Ingestion Framework
元数据导入框架通过插件(python库)的方式,集成到Datahub系统。可以从不同的数据平台将元数据,以Rest API直接导入,或将元数据生产到Kafka,再从Kafka消费导入到Datahub
元数据导入只需定义一个YAML文件,并执行datahub元数据导入命令

2.4 GraphQL API
GraphQL API提供了一个强类型的、面向Entiry的API,通过GraphQL API与储存的元数据进行交互

2.5 User Interface
DataHub提供一个React UI,方便用户进行元数据的管理

3. Ingestion Framework的架构
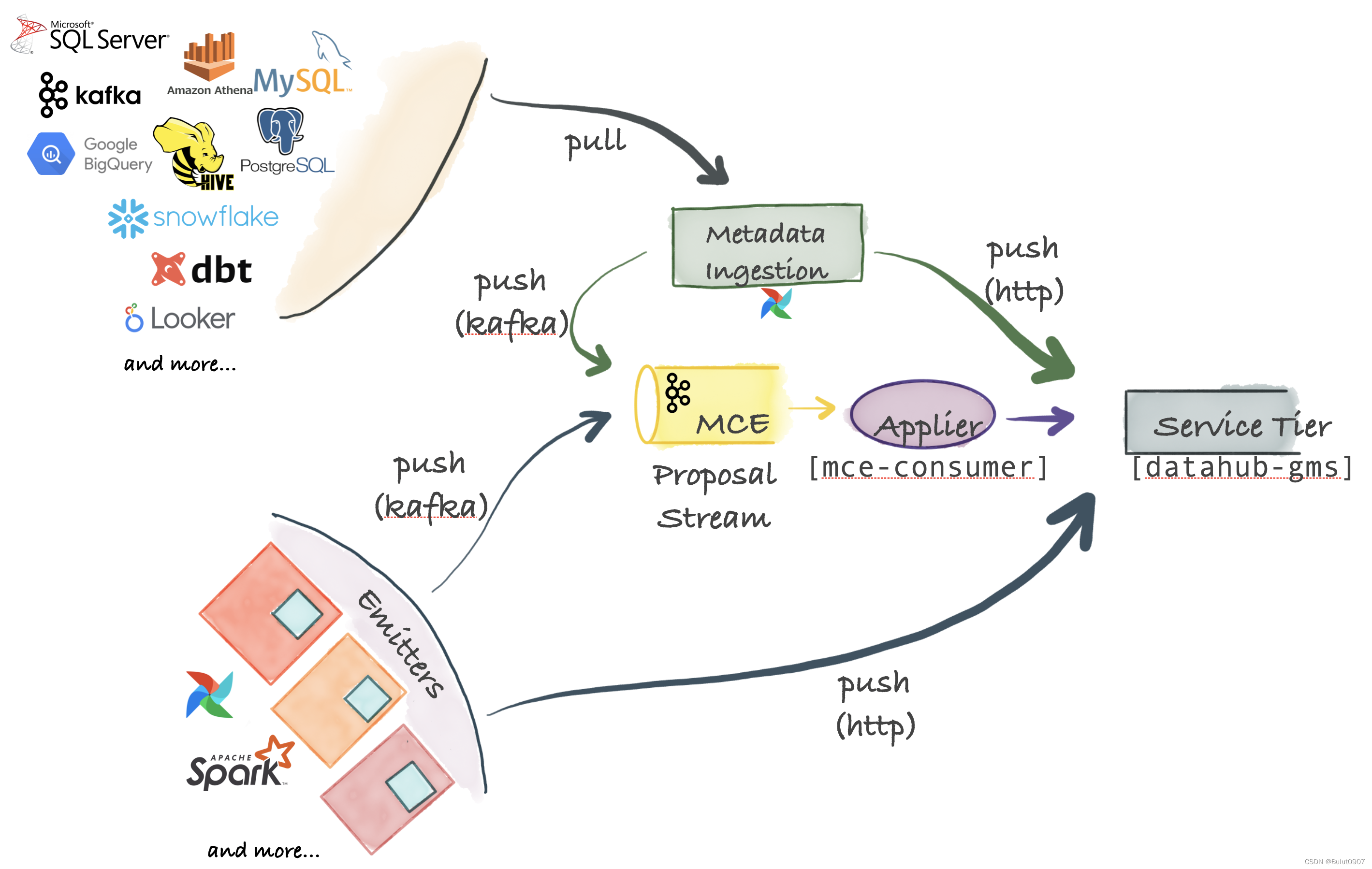
DataHub支持Push、Pull、同步和异步的元数据导入
3.1 Metadata Change Event(MCE)
MCE是元数据导入的中心。各种数据平台的元数据的实时变更,发送到MCE(由Kafka负责),这是一种异步元数据同步。也可以直接将数据平台的元数据通过HTTP方式发送到Datahub,这是一种同步元数据导入
3.2 Pull-based Integration
Datahub通过基于Python的metadata-ingestion系统,从不同的数据平台Pull元数据。然后将元数据Push到Kafka(MCE)或直接Push到Datahub。还可以从Airflow调度系统同步元数据和血缘关系
3.3 Push-based Integration
可以向Kafka Push一个元数据变更事件(MCE),或通过HTTP Push数据到Datahub。DataHub还提供了一些简单的Python emitters ,将其集成到我们自己的系统中,以便获取我们自己的系统元数据
3.4 Applier(mce-consumer)
消费Kafka的元数据消息,并转换成Datahub的元数据储存格式,再同步到Datahub
4. Datahub Serivce Tier架构
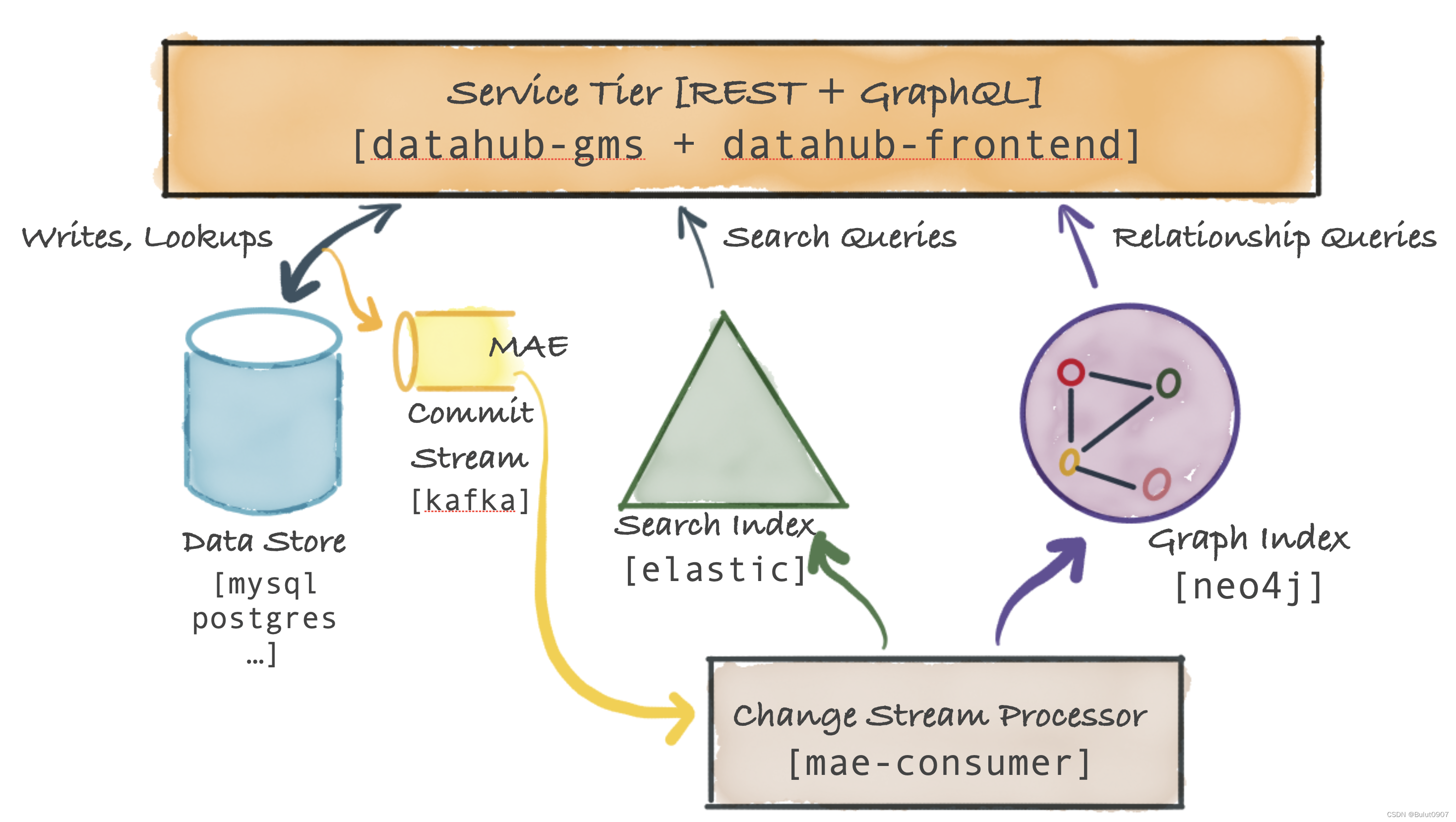
主要的服务是datahub-gms,它提供了一个REST API和一个GraphQL API对元数据进行CRUD操作,还提供支持二级索引、全文搜索的搜索查询,和血缘关系的图数据库查询API
4.1 Metadata Storage
储存元数据的数据库,如Mysql、Postgresql、Couchbase
4.2 Metadata Commit Log Stream(MAE)
当将元数据更改更新到Metadata Storage中,Datahub Service Tier还会将该更改事件发送到Kafka
4.3 Metadata Index Applier (mae-consumer-job)
mae-consumer-job消费MAE(Kafka)中的数据,然后将更改事件流更新打elastic和neo4j,并生成相应的search index和graph index
4.4 Metadata Query Serving
基于主键的元数据读取,是从Data store数据库读取的。基于二级索引的元数据读取和全文搜索的元数据读取,是从elastic数据库读取的。基于血缘关系的图查询是从neo4j数据库读取的

